Command Palette
Search for a command to run...
Ein-Klick-Bereitstellung Von DeepSeek-R1-70B
Datum
Größe
890.53 MB
Tags
Lizenz
MIT
GitHub
Paper-URL
1. Einführung in das Tutorial

DeepSeek-R1-Distill-Llama-70B ist ein Open-Source-Sprachmodell für große Sprachsysteme, das 2025 von DeepSeek veröffentlicht wurde und über 70 Milliarden Parameter verfügt. Es wurde mit Llama3.3-70B-Instruct trainiert und nutzt Reinforcement Learning sowie Destillationstechniken zur Verbesserung der Inferenzleistung. Es übernimmt nicht nur die Vorteile der Llama-Modelle, sondern optimiert auch die Inferenzfähigkeiten und zeichnet sich insbesondere durch seine Leistungsfähigkeit bei mathematischen, Code- und logischen Schlussfolgerungsaufgaben aus. Als Hochleistungsversion der DeepSeek-Serie erzielt es in zahlreichen Benchmark-Tests hervorragende Ergebnisse. Darüber hinaus ist dieses von DeepSeek AI bereitgestellte, inferenzoptimierte Modell für verschiedene Anwendungsszenarien wie mobile Geräte, Edge Computing und Online-Inferenzdienste geeignet, um die Reaktionsgeschwindigkeit zu verbessern und die Betriebskosten zu senken. Es verfügt über sehr leistungsstarke Inferenz- und Entscheidungsfähigkeiten und liefert in Bereichen wie fortschrittlichen KI-Assistenten und wissenschaftlicher Forschungsanalyse äußerst professionelle und tiefgreifende Analyseergebnisse. Beispielsweise kann die Version 70B in der medizinischen Forschung große Mengen medizinischer Daten analysieren und so wertvolle Referenzen für die Krankheitsforschung liefern.
本教程使用 Ollama + Open WebUI 部署 DeepSeek-R1-Distill-Qwen-70B 作为演示,算力资源采用「单卡 A6000」。
2. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen (wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 5 Minuten und versuchen Sie es erneut.) 2. Nachdem Sie die Webseite aufgerufen haben, können Sie eine Konversation mit dem Modell beginnen!
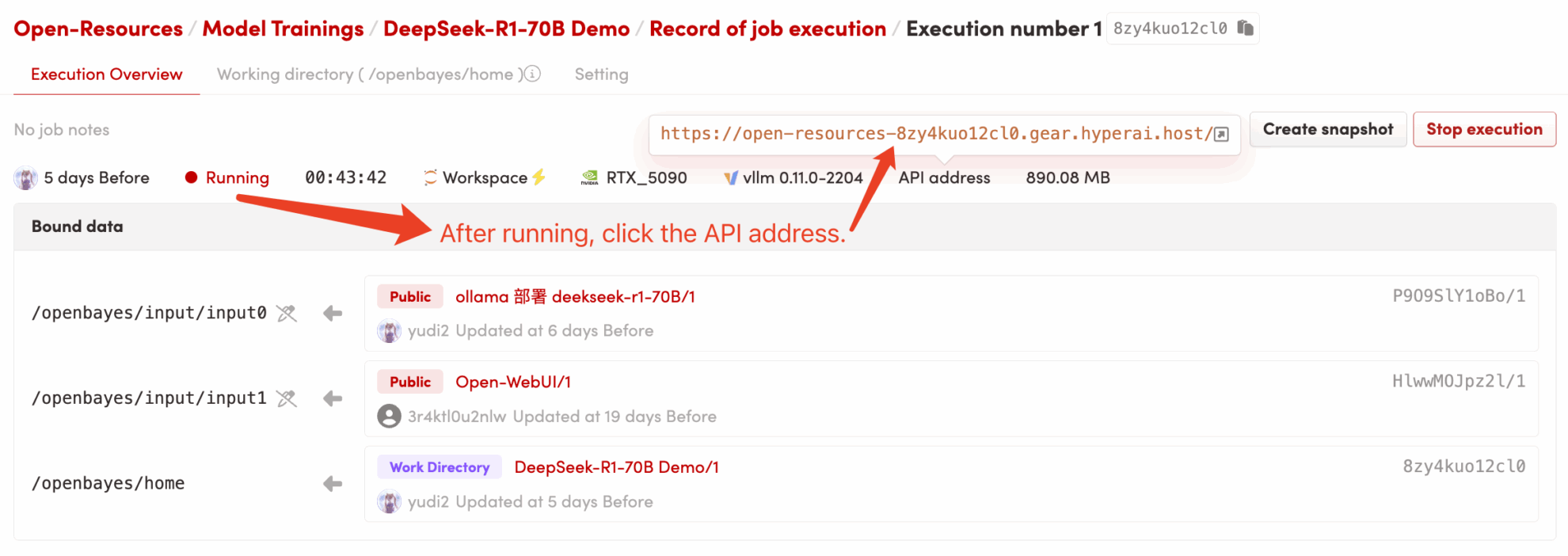
2. Nachdem Sie die Webseite aufgerufen haben, können Sie ein Gespräch mit dem Modell beginnen
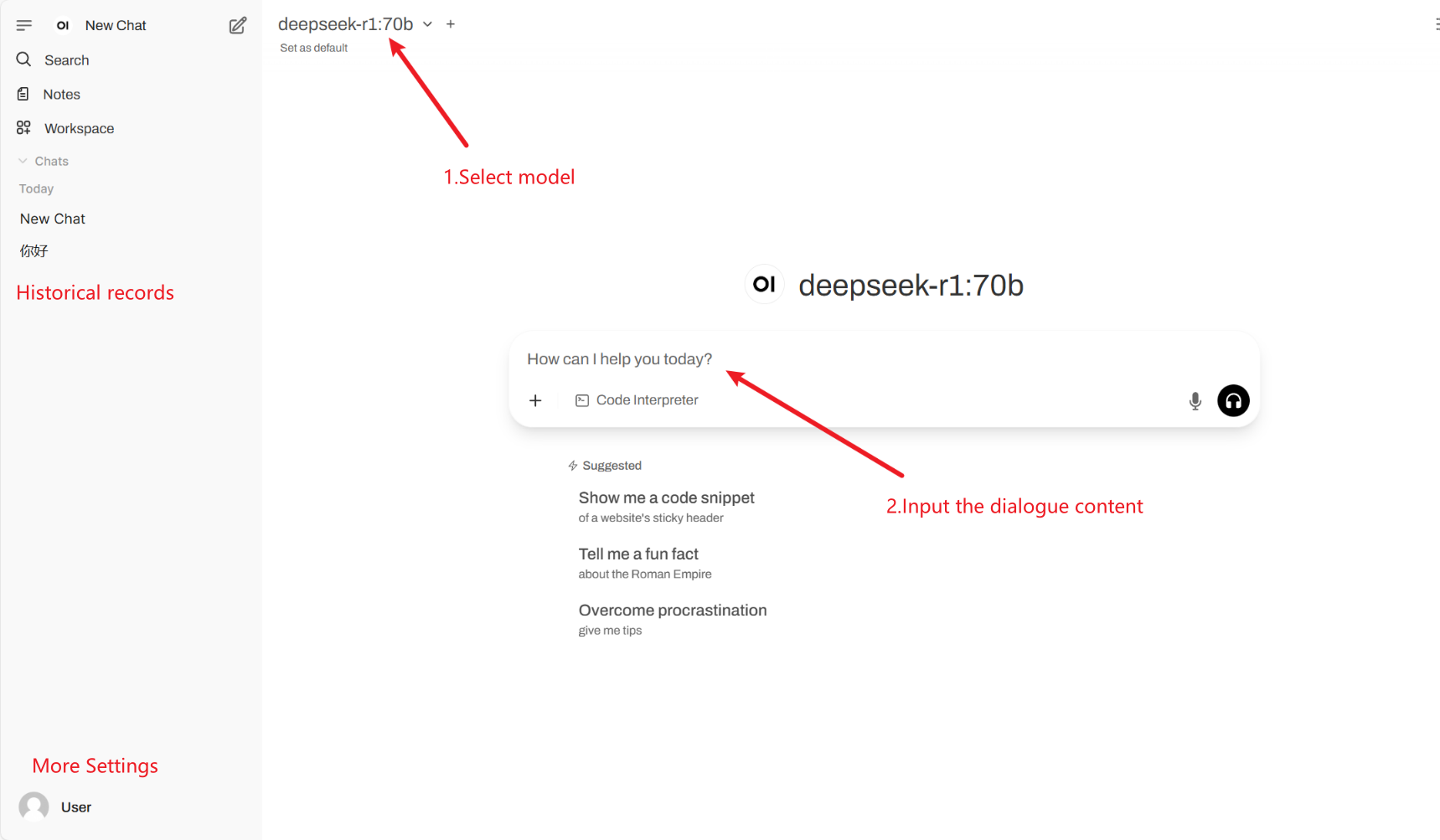
Gängige Gesprächseinstellungen
1. Temperatur
- Steuert die Zufälligkeit der Ausgabe, normalerweise im Bereich von 0,0–2,0.
- Niedriger Wert (z. B. 0,1): Sicherer, tendiert zu gebräuchlichen Wörtern.
- Hoher Wert (z. B. 1,5): Zufälligerer, möglicherweise kreativerer, aber unregelmäßiger Inhalt.
2. Top-k-Stichprobenverfahren
- Es werden nur die k Wörter mit der höchsten Wahrscheinlichkeit ausgewählt, Wörter mit niedriger Wahrscheinlichkeit werden ausgeschlossen.
- k ist klein (z. B. 10): Mehr Sicherheit, weniger Zufälligkeit.
- k ist groß (z. B. 50): Mehr Vielfalt, mehr Innovation.
3. Top-p-Sampling (Nucleus-Sampling, Top-p-Sampling)
- Wählen Sie den Wortsatz aus, dessen kumulative Wahrscheinlichkeit p erreicht, und legen Sie den Wert von k nicht fest.
- Niedriger Wert (z. B. 0,3): Mehr Sicherheit, weniger Zufälligkeit.
- Hoher Wert (z. B. 0,9): Mehr Vielfalt, verbesserte Flüssigkeit.
4. Wiederholungsstrafe
- Steuert die Textwiederholungsrate, normalerweise zwischen 1,0 und 2,0.
- Hoher Wert (z. B. 1,5): Reduzieren Sie Wiederholungen und verbessern Sie die Lesbarkeit.
- Niedriger Wert (z. B. 1,0): Keine Strafe, kann dazu führen, dass das Modell Wörter und Sätze wiederholt.
5. Max Tokens (maximale Generierungslänge)
- Begrenzen Sie die maximale Anzahl der vom Modell generierten Token, um eine übermäßig lange Ausgabe zu vermeiden.
- Typischer Bereich: 50-4096 (abhängig vom jeweiligen Modell).
Zitat
@misc{deepseekai2025deepseekr1incentivizingreasoningcapability,
title={DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning},
author={DeepSeek-AI},
year={2025},
eprint={2501.12948},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.12948},
}KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.