Command Palette
Search for a command to run...
Bereitstellen Von DeepSeek R1 Mit Ollama Und Open WebUI
1. Einführung in das Tutorial
DeepSeek-R1 ist die erste Version der von DeepSeek im Jahr 2025 eingeführten Sprachmodellreihe, die sich auf effiziente und leichte Aufgaben der natürlichen Sprachverarbeitung konzentriert. Diese Modellfamilie wird durch fortschrittliche Techniken wie Wissensdestillation optimiert, mit dem Ziel, den Bedarf an Rechenressourcen zu reduzieren und gleichzeitig eine hohe Leistung aufrechtzuerhalten. DeepSeek-R1 wurde mit Fokus auf praktische Anwendungsszenarien entwickelt, unterstützt eine schnelle Bereitstellung und Integration und eignet sich für eine Vielzahl von Aufgaben, darunter Textgenerierung, Dialogsysteme, Übersetzung und Zusammenfassungsgenerierung.
Auf technischer Ebene verwendet DeepSeek-R1 die Technologie der Wissensdestillation, um Wissen aus großen Modellen zu extrahieren und kleinere Modelle mit ähnlicher Leistung zu trainieren. Gleichzeitig verkürzen effiziente verteilte Trainings- und Optimierungsalgorithmen die Trainingszeit weiter und verbessern die Effizienz der Modellentwicklung. Diese technischen Highlights ermöglichen DeepSeek-R1 eine gute Leistung in praktischen Anwendungen.
本教程预设 DeepSeek-R1-Distill-Qwen-1.5B 、 DeepSeek-R1-Distill-Qwen-7B 、 DeepSeek-R1-Distill-Qwen-8B 、 DeepSeek-R1-Distill-Qwen-32B 四种模型作为演示,算力资源采用「单卡 RTX4090」。
2. Bedienungsschritte
- Klicken Sie nach dem Klonen und Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen (wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 5 Minuten und versuchen Sie es erneut.)
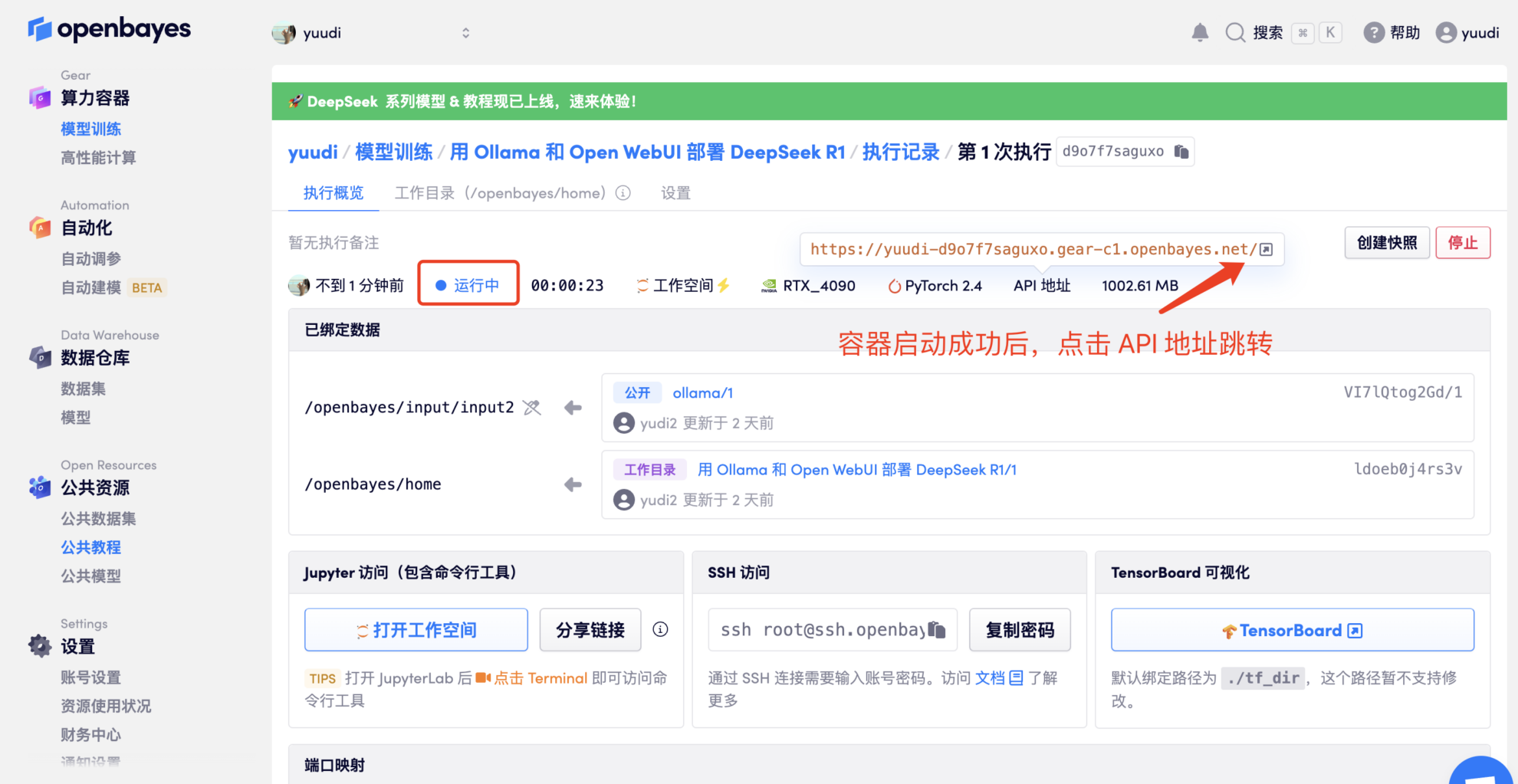
2. Nachdem Sie die Webseite aufgerufen haben, können Sie ein Gespräch mit dem Modell beginnen
Beachten:
- Dieses Tutorial unterstützt die „Online-Suche“. Nachdem diese Funktion aktiviert wurde, verlangsamt sich die Inferenzgeschwindigkeit, was normal ist.
- Sie können die Modelle in der oberen linken Ecke der Benutzeroberfläche wechseln.
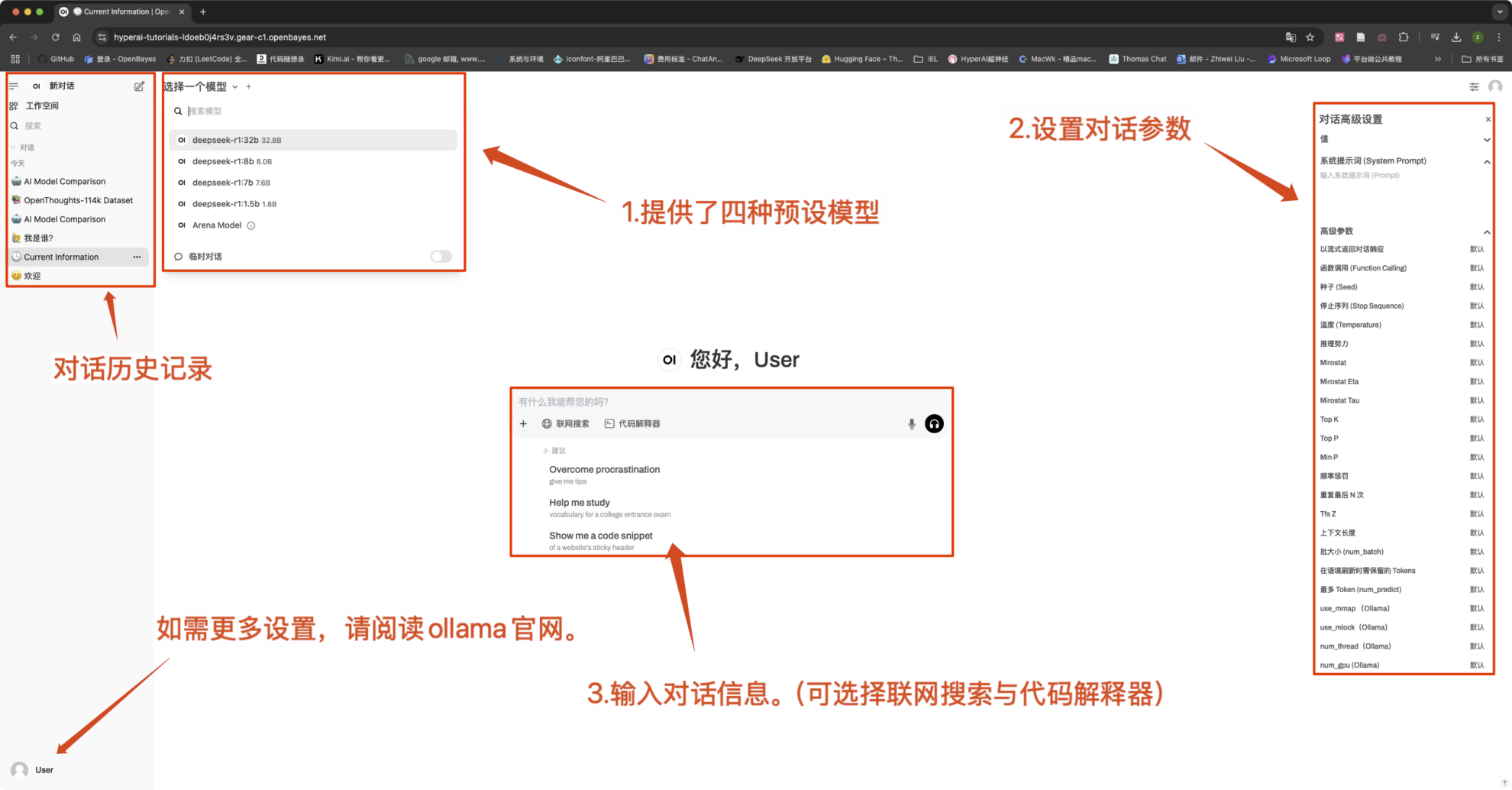
Gängige Gesprächseinstellungen
1. Temperatur
- Steuert die Zufälligkeit der Ausgabe, im Allgemeinen im Bereich von 0.0-2.0 zwischen.
- Niedriger Wert (z. B. 0,1): Sicherer, tendiert zu gebräuchlichen Wörtern.
- Hoher Wert (z. B. 1,5): Zufälligerer, möglicherweise kreativerer, aber unregelmäßiger Inhalt.
2. Top-k-Stichprobenverfahren
- Nur von Das k mit der höchsten Wahrscheinlichkeit Stichprobenziehung in Wörtern, unter Ausschluss von Wörtern mit geringer Wahrscheinlichkeit.
- k ist klein (z. B. 10): Mehr Sicherheit, weniger Zufälligkeit.
- k ist groß (z. B. 50): Mehr Vielfalt, mehr Innovation.
3. Top-p-Sampling (Nucleus-Sampling, Top-p-Sampling)
- wählenDer Wortsatz mit der kumulativen Wahrscheinlichkeit, die p erreicht, der k-Wert ist nicht festgelegt.
- Niedriger Wert (z. B. 0,3): Mehr Sicherheit, weniger Zufälligkeit.
- Hoher Wert (z. B. 0,9): Mehr Vielfalt, verbesserte Flüssigkeit.
4. Wiederholungsstrafe
- Steuert Textwiederholungen, normalerweise in 1.0-2.0 zwischen.
- Hoher Wert (z. B. 1,5): Reduzieren Sie Wiederholungen und verbessern Sie die Lesbarkeit.
- Niedriger Wert (z. B. 1,0): Keine Strafe, kann dazu führen, dass das Modell Wörter und Sätze wiederholt.
5. Max Tokens (maximale Generierungslänge)
- RestriktionsmodellMaximale Anzahl generierter Token, um eine übermäßig lange Ausgabe zu vermeiden.
- Typischer Bereich:50-4096(Hängt vom jeweiligen Modell ab).
Austausch und Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.