Command Palette
Search for a command to run...
vLLM-Tutorial: Eine Schritt-für-Schritt-Anleitung Für Anfänger

Inhaltsverzeichnis
- 1. Einführung in das Tutorial
- 2. Installation von vLLM
- 3. Erste Schritte
- 4. Starten des vLLM-Servers
- 5. Anfragen senden
1. Einführung in das Tutorial
vLLM (Virtual Large Language Model) ist ein Framework, das speziell für die Beschleunigung der Argumentation großer Sprachmodelle entwickelt wurde. Aufgrund seiner hervorragenden Argumentationseffizienz und Ressourcenoptimierungsfähigkeiten hat es weltweit große Aufmerksamkeit erregt. Im Jahr 2023 schlug ein Forschungsteam der University of California, Berkeley (UC Berkeley) einen bahnbrechenden Aufmerksamkeitsalgorithmus namens PagedAttention vor, der Aufmerksamkeitsschlüssel und -werte effektiv verwalten kann. Auf dieser Grundlage erstellten die Forscher eine verteilte LLM-Service-Engine (vLLM) mit hohem Durchsatz, erreichten eine nahezu null Verschwendung von KV-Cache-Speicher und lösten das Engpassproblem bei der Speicherverwaltung im Zusammenhang mit großen Sprachmodellen. Im Vergleich zu Hugging Face Transformers wird ein 24-mal höherer Durchsatz erreicht, und diese Leistungsverbesserung erfordert keine Änderungen an der Modellarchitektur. Die relevanten Papierergebnisse sindEffizientes Speichermanagement für die Bereitstellung großer Sprachmodelle mit PagedAttention".
In diesem Tutorial zeigen wir Ihnen Schritt für Schritt, wie Sie vLLM konfigurieren und ausführen, und bieten eine vollständige Anleitung von der Installation bis zum Start.
Dieses Tutorial verwendet Qwen3-0.6B Zur Demonstration werden auch Modelle mit anderen Parametergrößen bereitgestellt.
2. vLLM installieren
Diese Plattform wurde fertiggestellt vllm==0.8.5 Installation. Wenn Sie auf einer Plattform arbeiten, überspringen Sie diesen Schritt bitte. Wenn Sie die Bereitstellung lokal durchführen, befolgen Sie zur Installation die nachstehenden Schritte.
Die Installation von vLLM ist sehr einfach:
pip install vllmBeachten Sie, dass vLLM mit CUDA 12.4 kompiliert wird. Sie müssen daher sicherstellen, dass auf Ihrem Computer diese Version von CUDA ausgeführt wird.
Um die CUDA-Version zu überprüfen, führen Sie Folgendes aus:
nvcc --versionWenn Ihre CUDA-Version nicht 12.4 ist, können Sie entweder eine Version von vLLM installieren, die mit Ihrer aktuellen CUDA-Version kompatibel ist (weitere Informationen finden Sie in den Installationsanweisungen), oder CUDA 12.4 installieren.
3. Beginnen Sie mit der Nutzung
3.1 Modellvorbereitung
Methode 1: Verwenden des öffentlichen Plattformmodells
Zunächst können wir prüfen, ob das öffentliche Modell der Plattform bereits existiert. Wenn das Modell in ein öffentliches Repository hochgeladen wurde, können Sie es direkt verwenden. Falls nicht gefunden, verwenden Sie zum Herunterladen bitte Methode 2.
Die Plattform hat beispielsweise gespeichert Qwen3 Serienmodell. Im Folgenden sind die Schritte zum Binden des Modells aufgeführt (in diesem Tutorial wurde das Modell bereits gebunden).
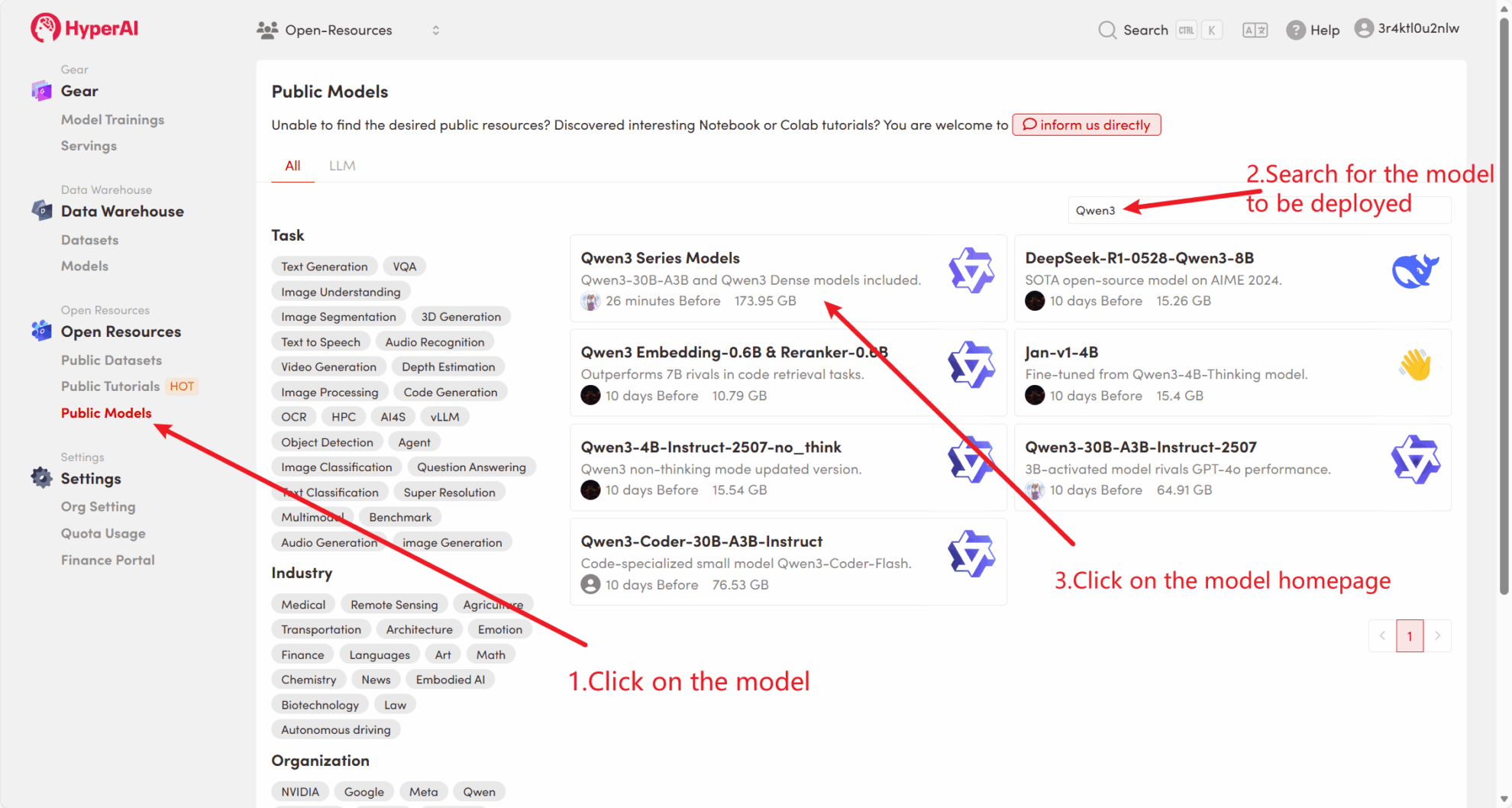
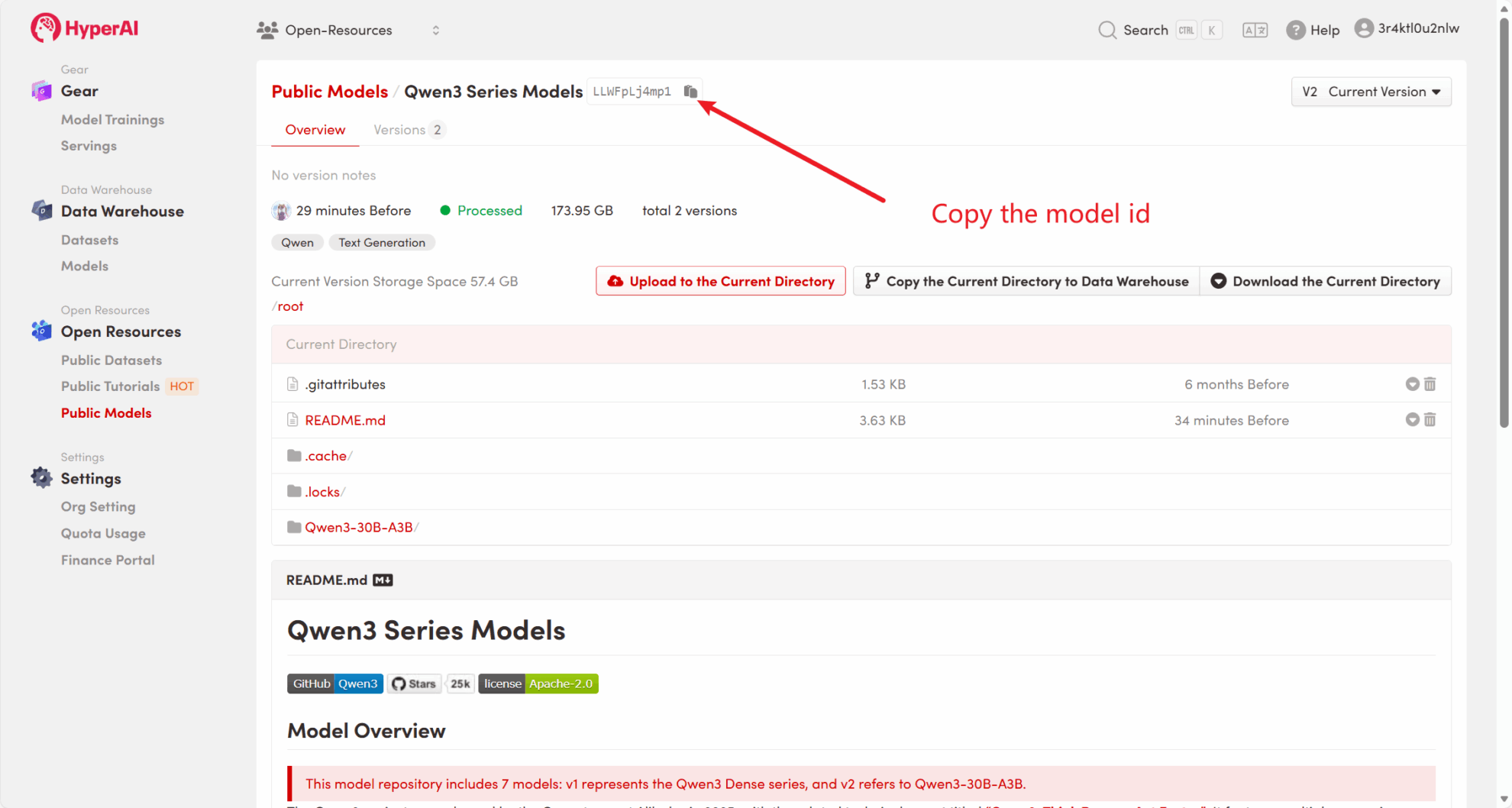
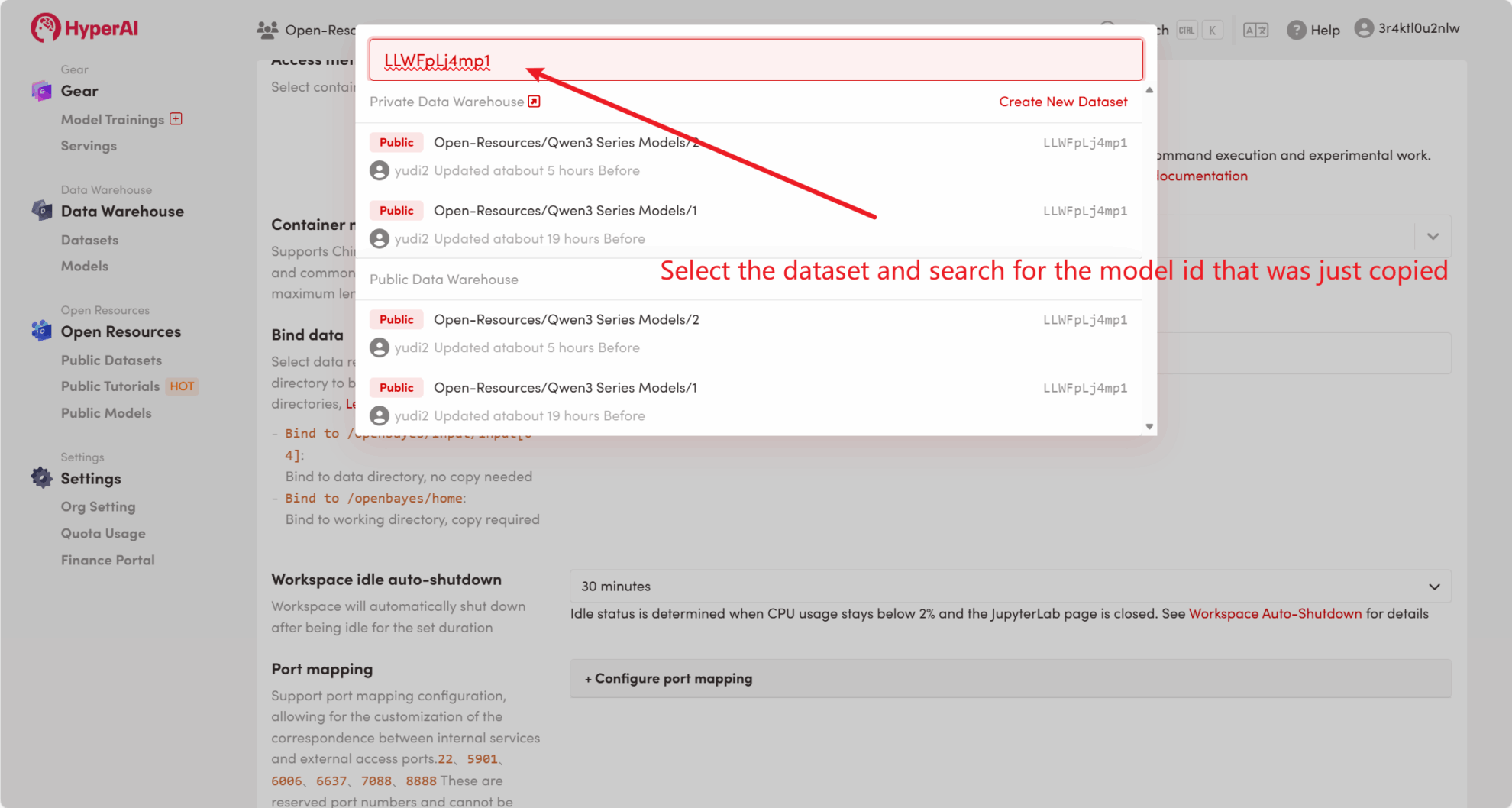
Methode 2: Laden Sie die Datei von HuggingFace herunter oder wenden Sie sich an den Kundendienst, um Unterstützung beim Hochladen auf die Plattform zu erhalten.
Die meisten Mainstream-Modelle sind auf HuggingFace zu finden. Eine Liste der von vLLM unterstützten Modelle finden Sie in der offiziellen Dokumentation: vllm-unterstützte-Modelle .
Bitte befolgen Sie die folgenden Schritte, um das Modell mit huggingface-cli herunterzuladen:
huggingface-cli download --resume-download Qwen/Qwen3-0.6B --local-dir ./input03.2 Offline-Schlussfolgerung
Als Open-Source-Projekt kann vLLM LLM-Argumentation über seine Python-API durchführen. Das Folgende ist ein einfaches Beispiel. Bitte speichern Sie den Code als offline_infer.py dokumentieren:
from vllm import LLM, SamplingParams
# 输入几个问题
prompts = [
"Hallo, wer sind Sie?", "Wo liegt die Hauptstadt von Frankreich?",]
# 设置初始化采样参数
sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=100)
# 加载模型,确保路径正确
llm = LLM(model="/input1/Qwen3-0.6B/", trust_remote_code=True, max_model_len=4096)
# 展示输出结果
outputs = llm.generate(prompts, sampling_params)
# 打印输出结果
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
Führen Sie dann das Skript aus:
python offline_infer.pySobald das Modell geladen ist, sehen Sie die folgende Ausgabe:

4. Starten Sie den vLLM-Server
Um Onlinedienste mit vLLM bereitzustellen, können Sie einen Server starten, der mit der OpenAI-API kompatibel ist. Nach einem erfolgreichen Start können Sie das bereitgestellte Modell genauso verwenden wie mit GPT.
4.1 Hauptparametereinstellungen
Im Folgenden sind einige allgemeine Parameter beim Starten eines vLLM-Servers aufgeführt:
--model: Zu verwendender HuggingFace-Modellname oder -Pfad (Standard:facebook/opt-125m).--hostUnd--port: Geben Sie die Serveradresse und den Port an.--dtype: Der Präzisionstyp der Modellgewichte und -aktivierungen. Mögliche Werte:auto,half,float16,bfloat16,float,float32. Standardwert:auto.--tokenizer: Zu verwendender Name oder Pfad des HuggingFace-Tokenizers. Wenn nicht angegeben, wird standardmäßig der Modellname oder Pfad verwendet.--max-num-seqs: Maximale Anzahl von Sequenzen pro Iteration.--max-model-len: Die Kontextlänge des Modells. Der Standardwert wird automatisch aus der Modellkonfiguration übernommen.--tensor-parallel-size,-tp: Anzahl der parallelen Kopien des Tensors (für GPU). Standardwert:1.--distributed-executor-backend=ray: Gibt das Backend des verteilten Dienstes an. Mögliche Werte:ray,mp. Standardwert:ray(Bei Verwendung mehrerer GPUs wird automatisch eingestellt aufray).
4.2 Starten Sie die Kommandozeile
Erstellen Sie einen Server, der mit der OpenAI-API-Schnittstelle kompatibel ist. Führen Sie den folgenden Befehl aus, um den Server zu starten:
python3 -m vllm.entrypoints.openai.api_server --model /input1/Qwen3-0.6B/ --host 0.0.0.0 --port 8080 --dtype auto --max-num-seqs 32 --max-model-len 4096 --tensor-parallel-size 1 --trust-remote-codeNach dem erfolgreichen Start wird eine Ausgabe ähnlich der folgenden angezeigt:

vLLM kann nun als Server eingesetzt werden, der das OpenAI API-Protokoll implementiert. Standardmäßig ist es verfügbar in http://localhost:8080 Starten Sie den Server. Du kannst --host Und --port Der Parameter gibt eine andere Adresse an.
5. Stellen Sie eine Anfrage
Die in diesem Tutorial verwendete API-Adresse lautet http://localhost:8080, Sie können die API verwenden, indem Sie diese Adresse besuchen. localhost Bezieht sich auf die Plattform selbst,8080 Ist die Portnummer, auf der der API-Dienst lauscht.
Auf der rechten Seite des Arbeitsbereichs wird die API-Adresse an den lokalen 8080-Dienst weitergeleitet, und Anforderungen können über den realen Host gestellt werden, wie in der folgenden Abbildung dargestellt:
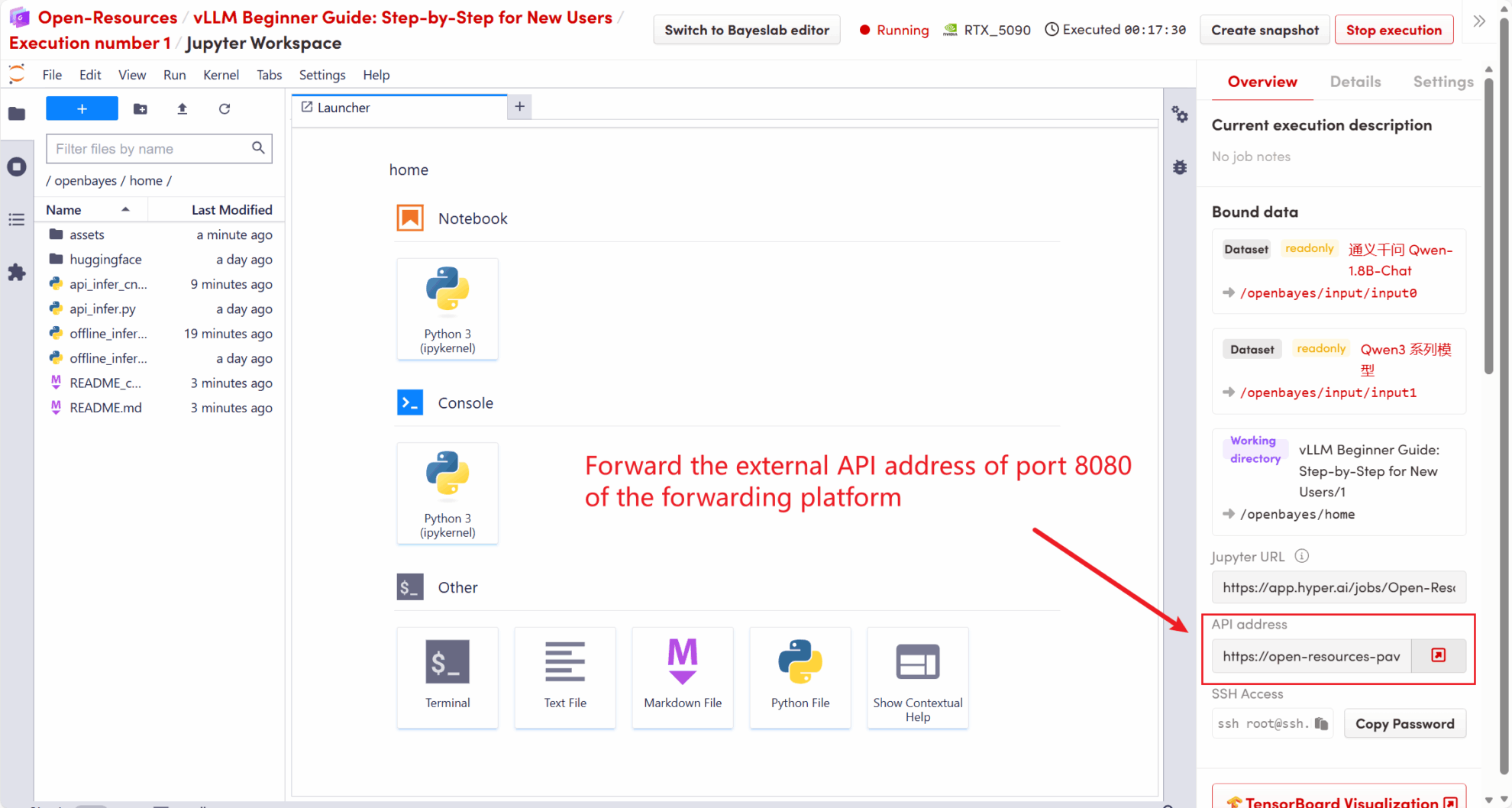
5.1 Verwenden des OpenAI-Clients
Nachdem Sie den vLLM-Dienst in Schritt 4 gestartet haben, können Sie die API über den OpenAI-Client aufrufen. Hier ist ein einfaches Beispiel:
# 注意:请先安装 openai
# pip install openai
from openai import OpenAI
# 设置 OpenAI API 密钥和 API 基础地址
openai_api_key = "EMPTY" # 请替换为您的 API 密钥
openai_api_base = "http://localhost:8080/v1" # 本地服务地址
client = OpenAI(api_key=openai_api_key, base_url=openai_api_base)
models = client.models.list()
model = models.data[0].id
prompt = "Describe the autumn in Beijing"
# Completion API 调用
completion
= client.completions.create(model=model, prompt=prompt)
res = completion.choices[0].text.strip()
print(f"Prompt: {prompt}\nResponse: {res}")Führen Sie den folgenden Befehl aus:
python api_infer.pySie erhalten eine Ausgabe ähnlich der folgenden:

5.2 Verwenden der Curl-Befehlsanforderung
Sie können die Anfrage auch direkt mit dem folgenden Befehl senden. Geben Sie beim Zugriff auf die Plattform den folgenden Befehl ein:
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/input1/Qwen3-0.6B/",
"prompt": "Describe the autumn in Beijing", "max_tokens": 512
}'Sie erhalten eine Antwort wie diese:

Wenn Sie die OpenBayes-Plattform verwenden, geben Sie den folgenden Befehl ein:
curl https://hyperai-tutorials-8tozg9y9ref9.gear-c1.openbayes.net/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/input1/Qwen3-0.6B/",
"prompt": "Describe the autumn in Beijing", "max_tokens": 128
}'Das Antwortergebnis lautet wie folgt:

KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.