Command Palette
Search for a command to run...
GLM-4-Voice End-to-End-Konversationsmodell Chinesisch-Englisch
Datum
Größe
1.91 GB
1. Einführung in das Tutorial
GLM-4-Voice ist ein End-to-End-Sprachmodell, das 2024 von Zhipu AI eingeführt wurde. GLM-4-Voice kann chinesische und englische Sprache direkt verstehen und generieren, Sprachgespräche in Echtzeit führen und den Anweisungen des Benutzers folgen, um Emotion, Intonation, Sprechgeschwindigkeit, Dialekt und andere Attribute der Sprache zu ändern.
Diese Tutorial-Demo enthält zwei funktionale Implementierungen des Modells: „Sprachkonversation“ und „Textkonversation“.
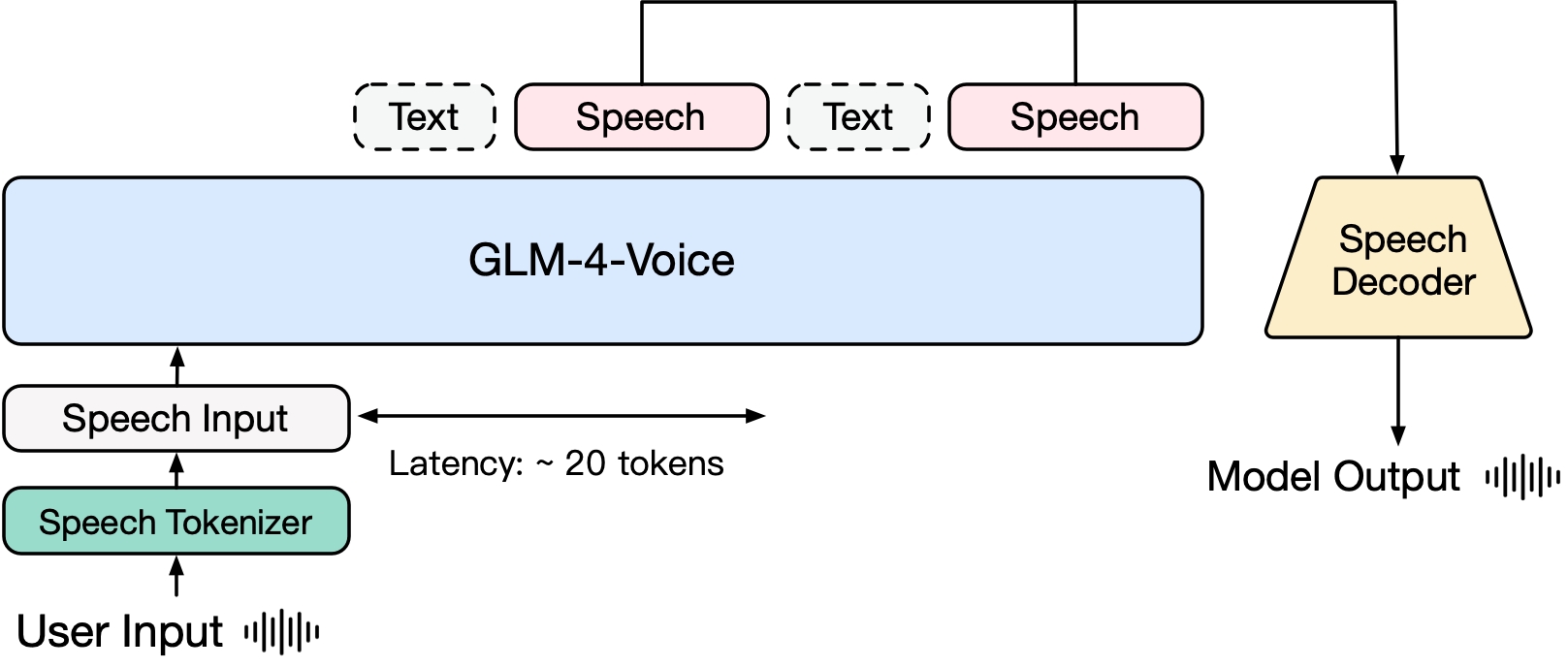
GLM-4-Voice besteht aus drei Teilen:
- GLM-4-Voice-Tokenizer: Wandelt kontinuierliche Spracheingaben in diskrete Token um, indem dem Encoder-Teil von Whisper eine Vektorquantisierung und ein überwachtes Training mit ASR-Daten hinzugefügt werden. Im Durchschnitt werden nur 12,5 einzelne Token benötigt, um jede Sekunde Audio darzustellen.
- GLM-4-Voice-Decoder: Ein Sprachdecoder, der Streaming-Reasoning unterstützt und basierend auf der Flow-Matching-Modellstruktur von CosyVoice trainiert wird, indem er diskrete Sprachtoken in kontinuierliche Sprachausgabe umwandelt. Zum Starten der Generierung sind nur 10 Sprachtoken erforderlich, wodurch die Latenzzeit zwischen den Gesprächen reduziert wird.
- GLM-4-Voice-9B: Führt ein Vortraining und eine Ausrichtung der Sprachmodalität basierend auf GLM-4-9B durch, sodass diese diskrete Sprachtoken verstehen und generieren kann.
Um die beiden Schwierigkeiten der Intelligenz des Modells und der synthetischen Ausdruckskraft in der Sprachmodalität zu überwinden, hat das Forschungsteam im Hinblick auf das Vortraining die Speech2Speech-Aufgabe in zwei Aufgaben aufgeteilt: „Erstellen von Textantworten basierend auf Benutzeraudio“ und „Synthetisieren von Antwortsprache basierend auf Textantworten und Benutzerstimme“. Außerdem wurden zwei Vortrainingsziele entworfen: Synthetisieren von Sprach-Text-verschachtelten Daten basierend auf Textvortrainingsdaten und unüberwachten Audiodaten, um sich an diese beiden Aufgabenformen anzupassen. GLM-4-Voice-9B basiert auf dem Basismodell von GLM-4-9B. Es wurde mit Millionen von Stunden Audiomaterial und Hunderten von Milliarden Tokens mit verschachtelten Audiotextdaten vortrainiert und verfügt über ausgeprägte Fähigkeiten zum Verständnis und zur Modellierung von Audiodaten.
Um qualitativ hochwertige Sprachgespräche zu unterstützen, hat das Forschungsteam eine Streaming-Thinking-Architektur entwickelt: Basierend auf der Stimme des Benutzers kann GLM-4-Voice den Inhalt abwechselnd im Text- und Sprachmodus streamen und ausgeben. Der Sprachmodus verwendet Text als Referenz, um die hohe Qualität des Antwortinhalts sicherzustellen, und nimmt entsprechende Tonänderungen entsprechend den Sprachbefehlsanforderungen des Benutzers vor. Es verfügt weiterhin über die Fähigkeit zur End-to-End-Modellierung, behält dabei aber den IQ des Sprachmodells weitgehend bei und weist eine geringe Latenz auf. Zur Sprachsynthese müssen lediglich mindestens 20 Token ausgegeben werden.
2. Bedienungsschritte
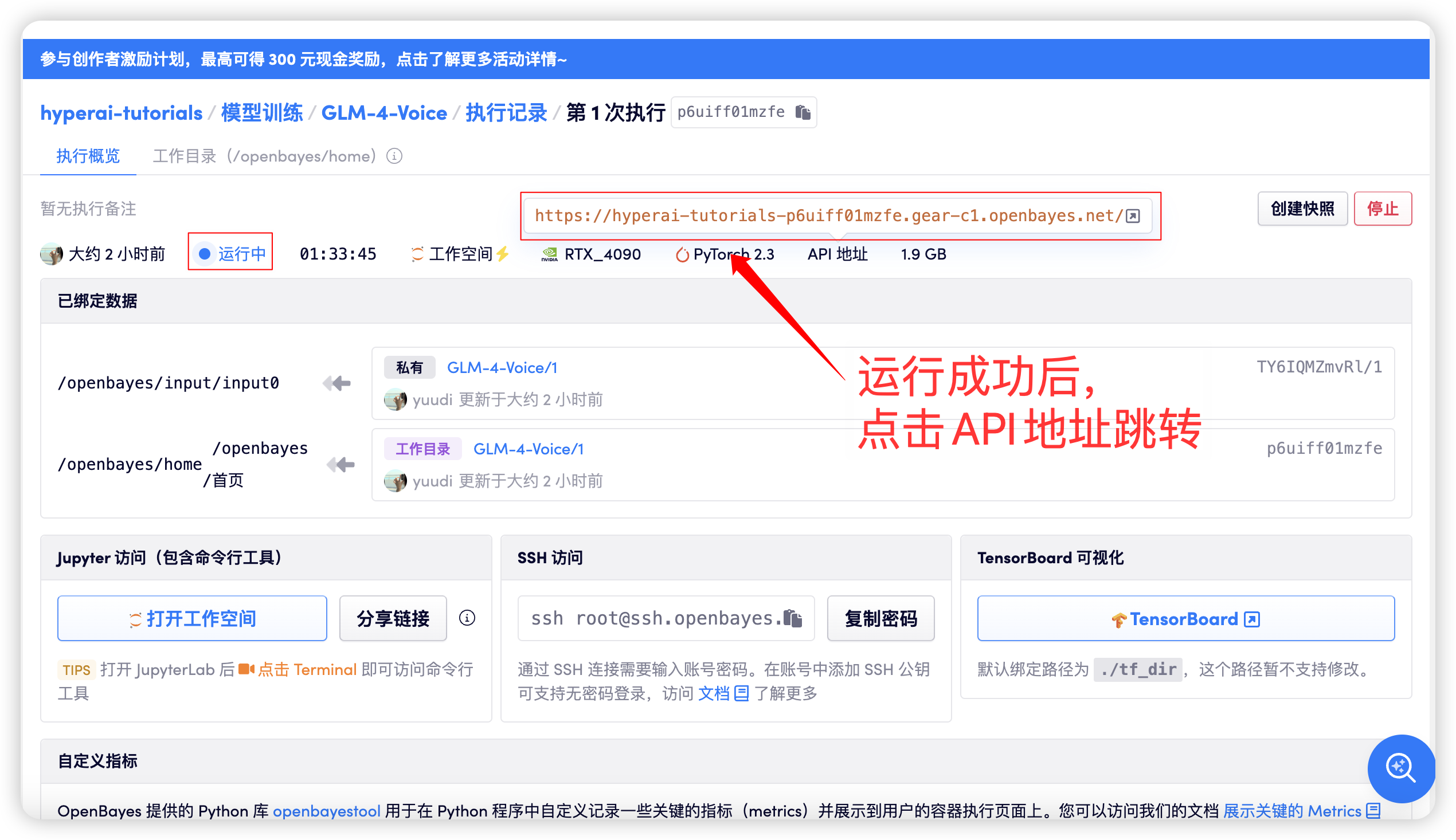
Klicken Sie nach dem Starten des Containers auf die API-Adresse, um zur Weboberfläche zu gelangen
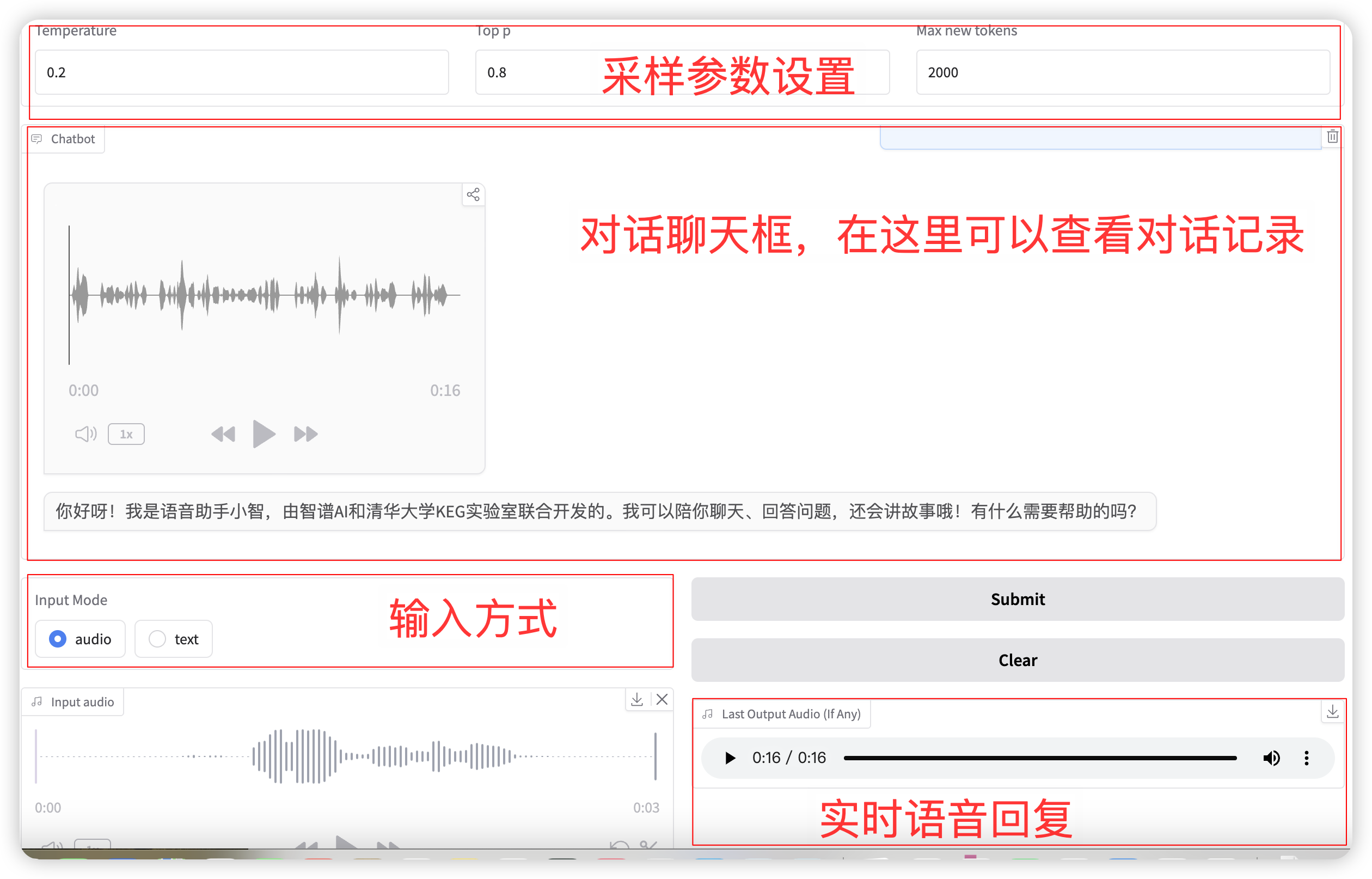
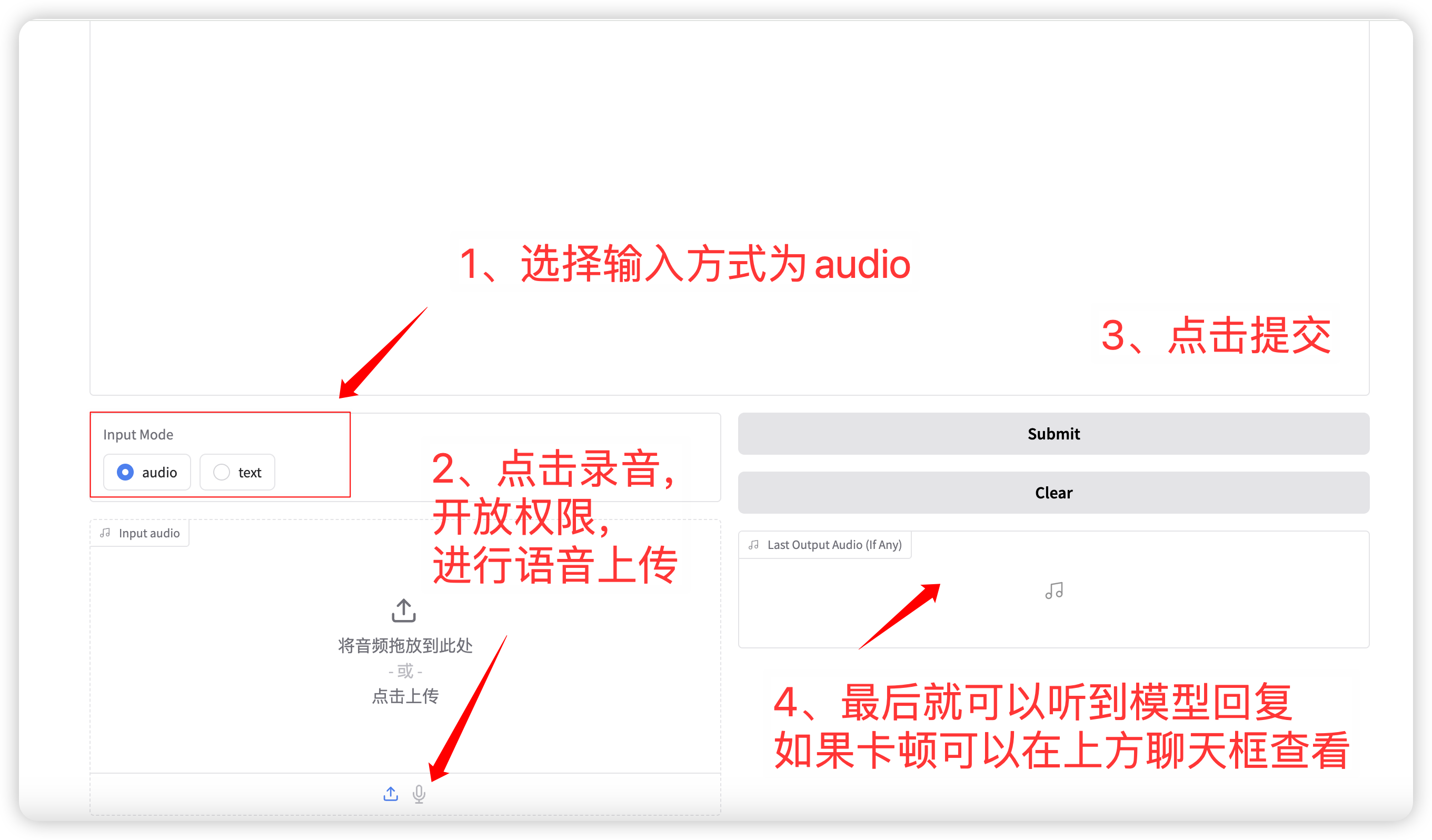
1. Sprachdialog
Auswahl des Eingabemodus Audio- Funktion: Klicken Sie, um eine Sprachdatei aufzunehmen oder hochzuladen. Die relevanten Probenahmeparameter sind:
- Temperatur: Bereich 0-1, je höher die Temperatur, desto zufallsabhängiger ist die Generierung!
- Top p: Wird verwendet, um anzugeben, dass bei der Auswahl des nächsten Wortes während des Generierungsprozesses nur die Top-p-Optionen mit der höchsten Wahrscheinlichkeit berücksichtigt werden. Dadurch bleibt die Vielfalt bei der Textgenerierung erhalten und es wird vermieden, dass immer die Vorhersageergebnisse mit der höchsten Wahrscheinlichkeit ausgewählt werden. Der generierte Text wird dadurch reicher und vielfältiger.
- Max. neue Token: Die maximale Anzahl generierter Token.
Nach Abschluss der Einrichtung gibt das Modell Sprache und Text in Echtzeit aus, es kann jedoch aufgrund der Netzwerklatenz zu Unterbrechungen kommen. Sie können der Stimme im Chatfenster zuhören. Das allgemeine Seitenlayout ist wie folgt:
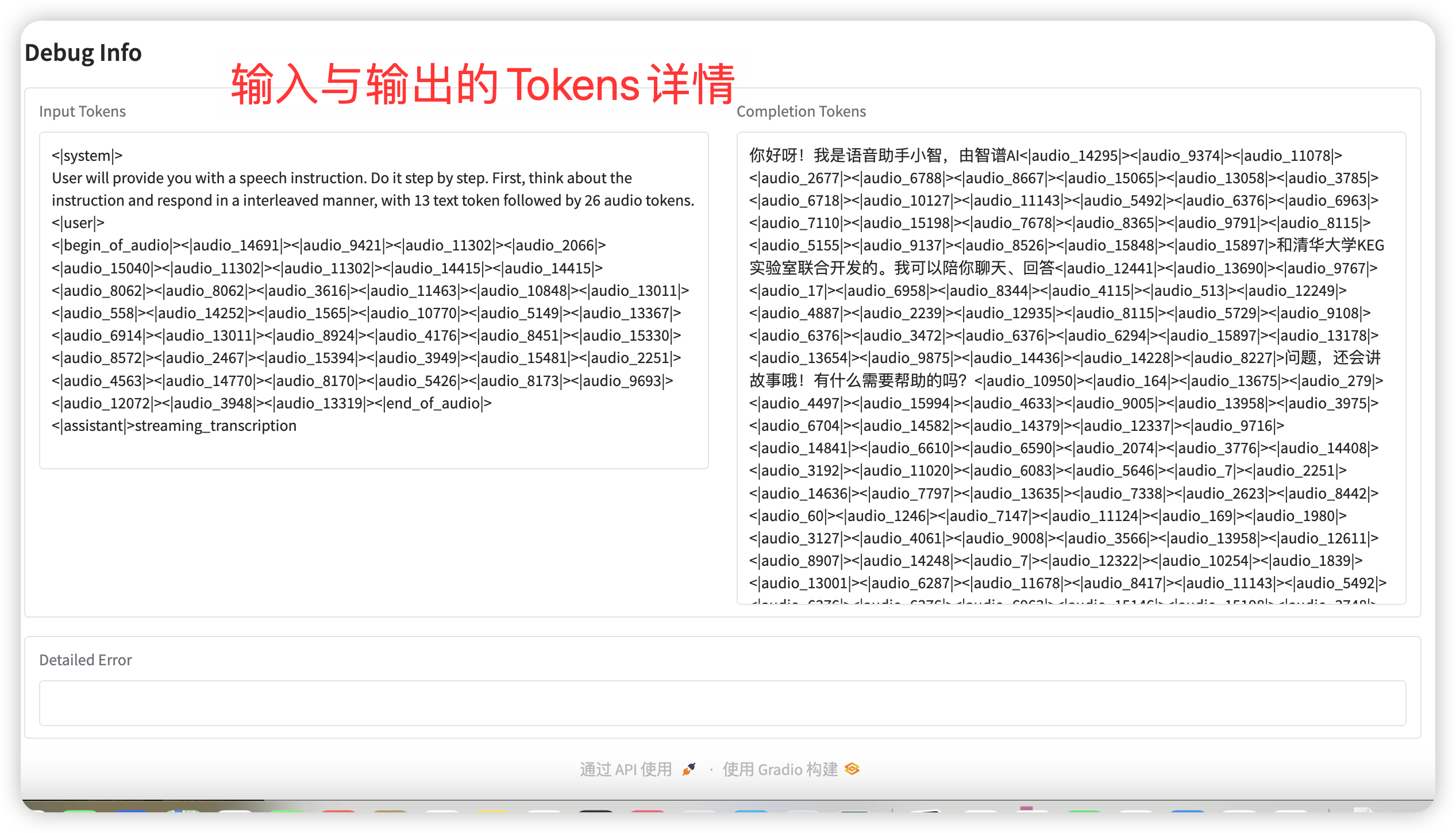
语音对话流程
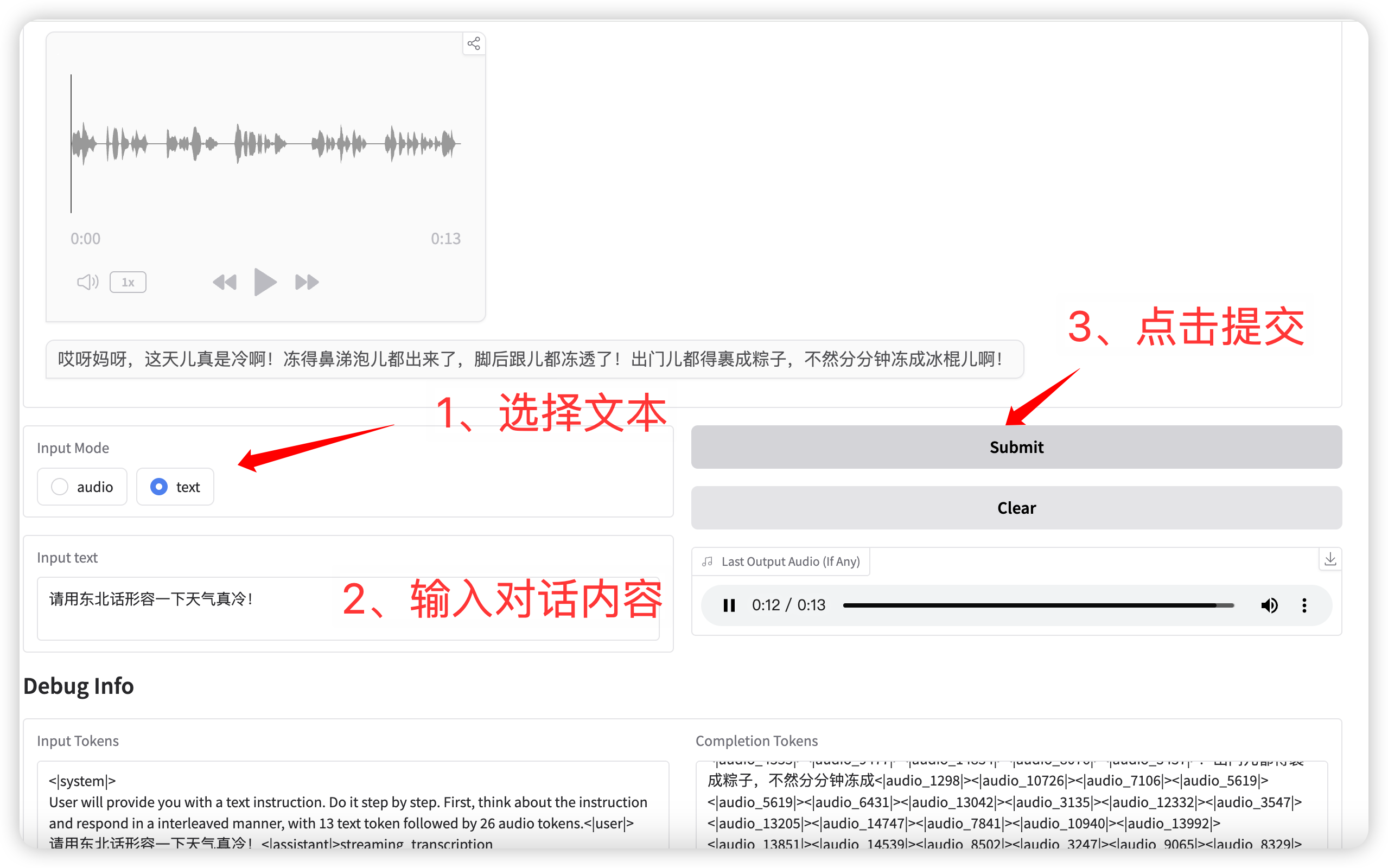
2. Textkonversation
输入模式选择 **text** 功能,输入对话文本。
点击提交后,模型同时输出文本和语音。
语音对话(输入为文本)
Austausch und Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.