Command Palette
Search for a command to run...
MuseTalk-Demo Für Hochwertige Lippensynchronisationsmodelle
Datum
Größe
2.41 GB
Zu den Funktionen von MuseTalk gehören:
- Echtzeit: Kann in einer Echtzeitumgebung ausgeführt werden und erreicht eine Verarbeitungsgeschwindigkeit von mehr als 30 Bildern pro Sekunde, um eine reibungslose Lippensynchronisation zu gewährleisten.
- Hochwertige Synchronisierung: Mithilfe einer Latent Space Inpainting-Methode wird die Mundform basierend auf dem Eingangsaudio angepasst, während die Gesichtszüge erhalten bleiben, wodurch eine hochwertige Lippensynchronisation erreicht wird.
- Funktioniert mit MuseV: MuseTalk kann mit dem MuseV-Modell verwendet werden, einem Videogenerierungsframework, das virtuelle menschliche Videos generieren kann.
- Open Source: Der Code von MuseTalk wurde als Open Source freigegeben, um Beiträge der Community und die Weiterentwicklung zu erleichtern.
MuseTalk zeichnet sich durch die Generierung von Lippensynchronisationen aus und kann eine genaue Lippensynchronisation mit guter Bildkonsistenz erzeugen, insbesondere für die Generierung von Videos mit echten Personen. Es bietet auch Vorteile im Vergleich zu anderen Produkten wie EMO, AniPortrait, Vlogger und Microsofts VASA-1.
Effektbeispiele
Modellrahmen
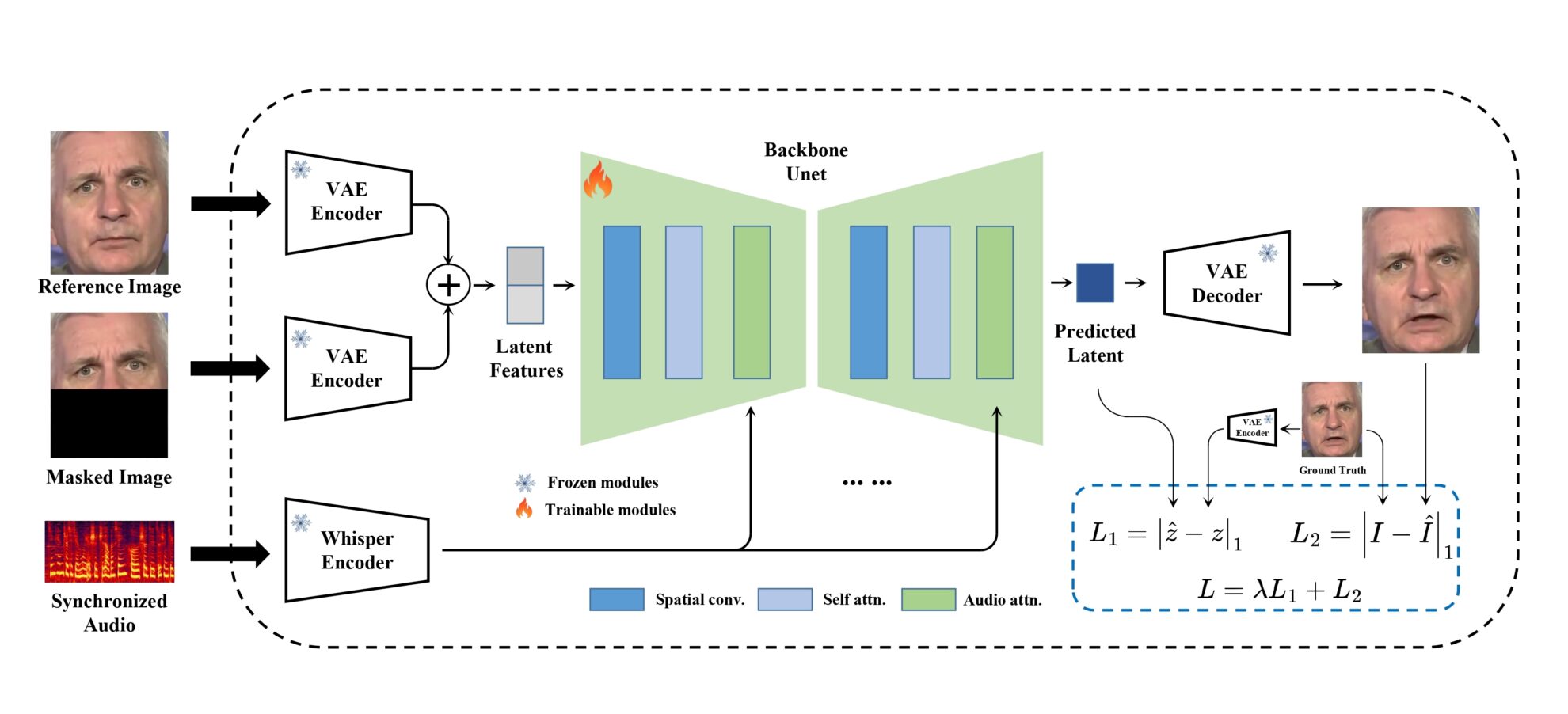
MuseTalk Das Training wird in einem latenten Raum durchgeführt, in dem Bilder durch ein eingefrorenes VAE kodiert werden. Der Ton wird durch ein eingefrorenes Whisper-Tiny-Modell kodiert. Die Architektur des generativen Netzwerks ist von UNet in stable-diffusion-v1-4 übernommen, wo Audio-Einbettungen über Cross-Attention mit Bild-Einbettungen verschmolzen werden.
Schritte ausführen
1. Klicken Sie oben rechts im Projekt auf „Klonen“ und dann auf „Weiter“, um die folgenden Schritte abzuschließen: Grundlegende Informationen > Rechenleistung auswählen > Überprüfen. Klicken Sie abschließend auf „Weiter“, um dieses Projekt im persönlichen Container zu öffnen.
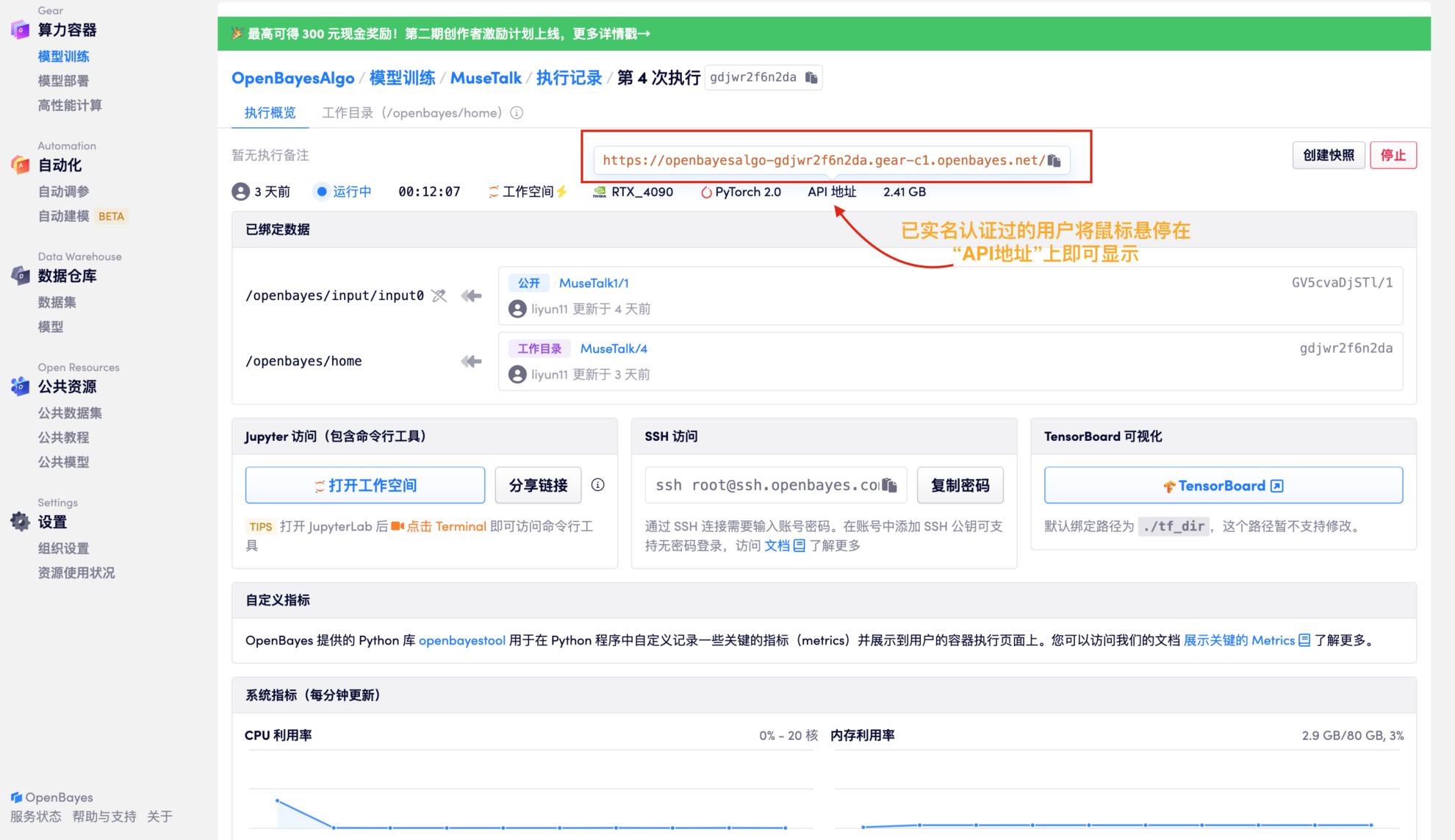
2. Nachdem die Ressourcenzuweisung abgeschlossen ist, kopieren Sie die API-Adresse direkt und fügen Sie sie in eine beliebige URL ein (die Echtnamenauthentifizierung muss abgeschlossen sein, und für diesen Schritt ist es nicht erforderlich, den Arbeitsbereich zu öffnen).
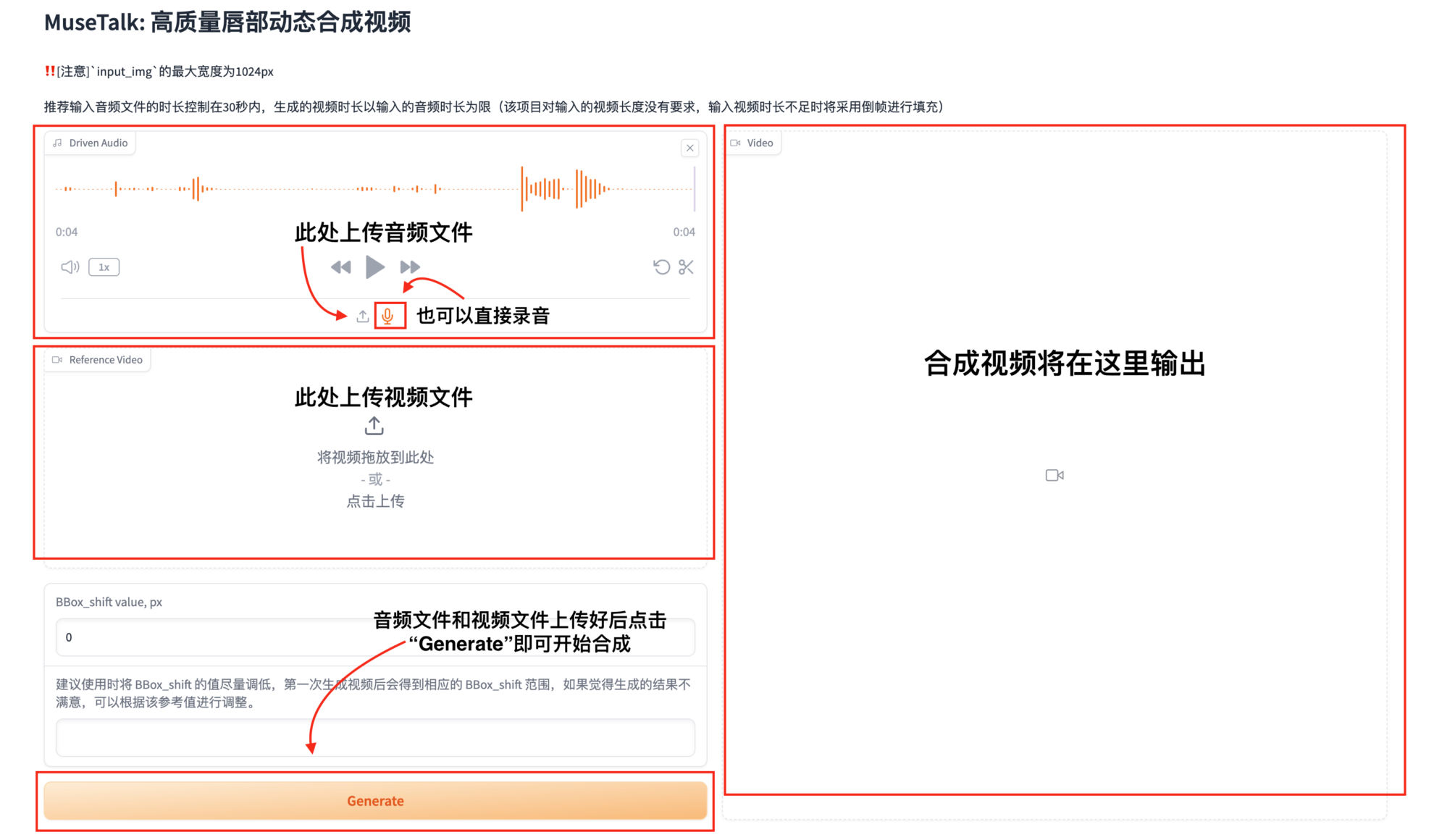
3. Audio- und Videodateien zur Synthese hochladen
Nach dem Testen: Es dauert etwa 3 Minuten, um eine Audiodatei mit einer Dauer von 17 Sekunden zu generieren; Das Generieren einer Audiodatei mit einer Dauer von etwa einer Minute dauert etwa 6 Minuten.
-|MuseTalk Die Gesichts- und Mundform kann entsprechend dem Eingangsaudio verändert werden. Die Größe der Gesichtsfläche beträgt vorzugsweise 256 x 256. Gleichzeitig MuseTalk Es unterstützt auch die Änderung der Vorschläge für den Mittelpunkt der Gesichtsregion, was die generierten Ergebnisse erheblich beeinflusst.
-|Derzeit MuseTalk Unterstützt Audioeingabe in mehreren Sprachen, darunter Chinesisch, Englisch, Japanisch usw.
-|Die endgültige generierte Videodauer basiert auf der Audiodauer.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.