Command Palette
Search for a command to run...
Ein-Klick-Bereitstellung Des Puke-Chemikalien-Großmodells ChemLLM-7B-Chat-Demo
Einführung in das Tutorial
Dieses Tutorial ist eine Ein-Klick-Bereitstellungsdemo von ChemLLM-7B-Chat. Sie müssen nur den Container klonen und starten und die generierte API-Adresse direkt kopieren, um die Inferenz des Modells zu erleben.
ChemLLM-7B-Chat ist das erste Open-Source-Sprachmodell für Chemie und Molekularwissenschaften im großen Maßstab, „ChemLLM“, das 2024 vom Shanghai Artificial Intelligence Laboratory (Shanghai AI Lab) veröffentlicht wurde und auf InternLM-2 basiert. Zugehörige Forschungsarbeiten umfassen… ChemLLM: Ein großes chemisches Sprachmodell .
Puke Chemistry stützt sich auf die hervorragenden mehrsprachigen Fähigkeiten des Shusheng·PuYu 2.0-Basismodells und verfügt nach einer professionellen Schulung in chemischen Kenntnissen auch über hervorragende Chinesisch-Englisch-Übersetzungsfunktionen im Bereich Chemie. Dies kann Chemieforschern helfen, Sprachbarrieren zu überwinden, die Fachbegriffe in der chemischen Literatur genau zu übersetzen und mehr chemisches Wissen zu erwerben.
Darüber hinaus hat das Forschungsteam auch Open Source ChemData700K-Datensatz, chinesische und englische Versionen des ChemPref-10K-Datensatzes, C-MHChem-DatensatzUnd ChemBench4K Benchmark-Datensatz zur Bewertung der chemischen Fähigkeiten.
Die folgende Abbildung zeigt die Zusammenfassung eines von Pu Ke Chemistry übersetzten und am 16. Januar 2024 in der Zeitschrift Nature Chemistry veröffentlichten Artikels.

Neben der Vermittlung von Fachwissen in Chemie bietet Puke Chemistry auch die Vermittlung von Wissen für die Mittel- und Oberstufe an. Bei der Beantwortung von Chemiefragen für die Mittel- und Oberstufe können Sie nicht nur die Antwort angeben, sondern auch eine konkrete Erklärung liefern. Die folgende Abbildung zeigt ein Beispiel:

Bereitstellen des Inferenzschritts
In diesem Tutorial wurden das Modell und die Umgebung bereitgestellt. Sie können das große Modell direkt für den Denkdialog gemäß den Anweisungen im Tutorial verwenden. Das spezifische Tutorial lautet wie folgt:
1. Modellkonfiguration
Nachdem die Ressourcen konfiguriert wurden, starten Sie den Container und klicken Sie auf den Link an der API-Adresse, um die Demo-Oberfläche aufzurufen (da das Modell nach dem erfolgreichen Start des Containers geladen werden muss, dauert das Öffnen der Webseite etwa eine halbe Minute).
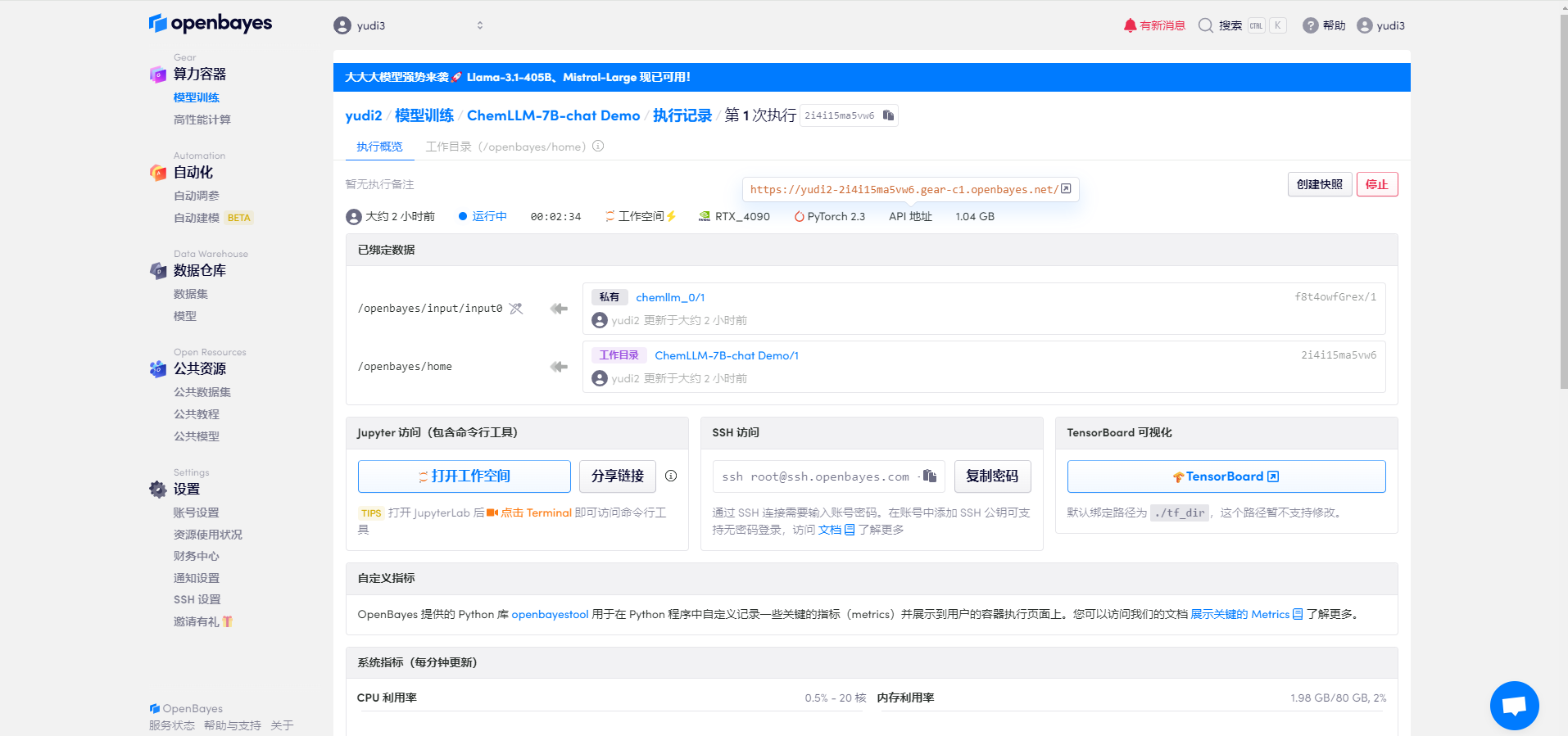
2. Öffnen Sie die Schnittstelle
Nach einer kurzen Wartezeit können Sie die Benutzeroberfläche des Modells sehen und dann mit der Kommunikation mit dem Modell beginnen. Sie können eine Beispielfrage oder eine eigene Frage eingeben.
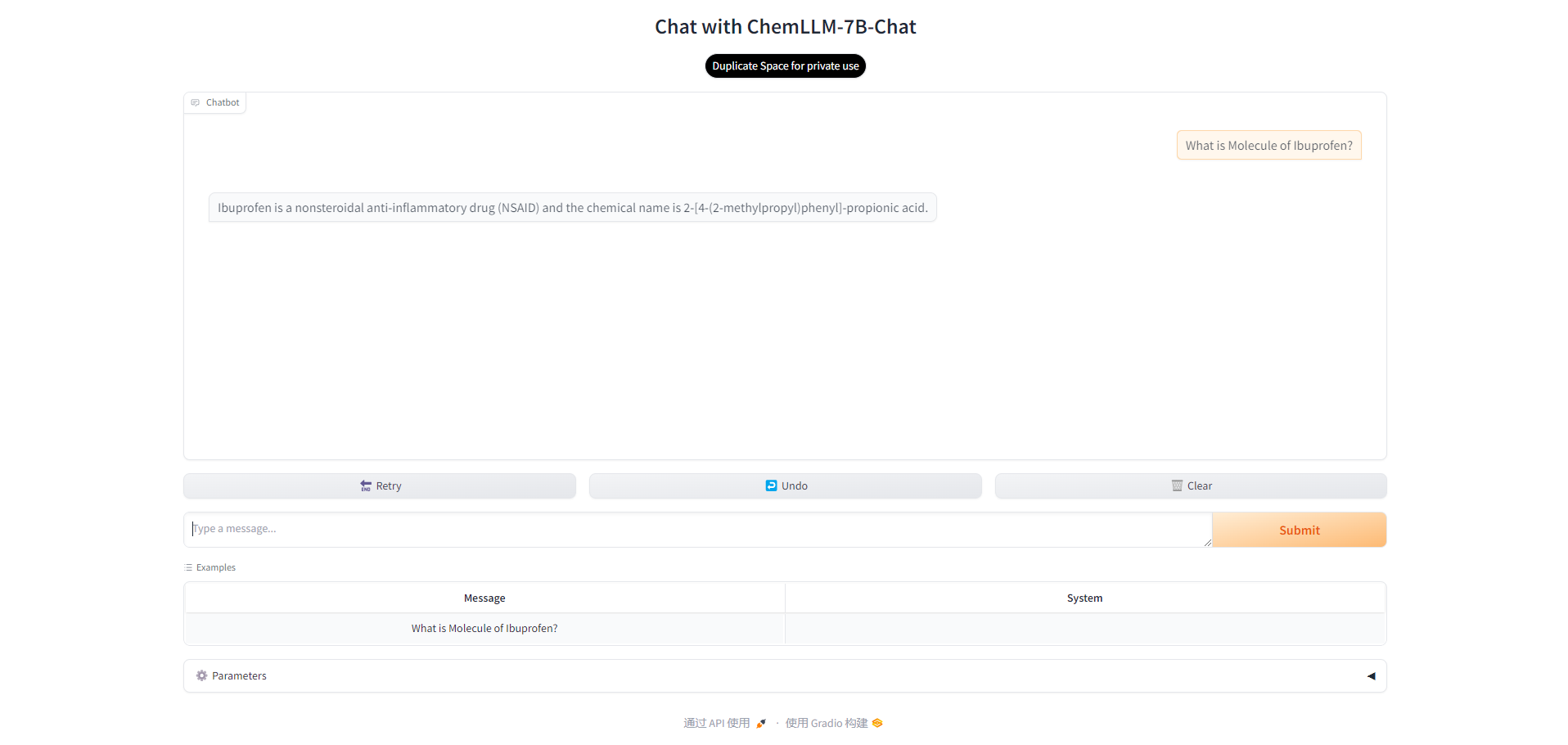
3. Parametereinstellung
Es gibt auch mehrere Parameter im Modell, die angepasst werden können. In:
- Temperatur: Wird verwendet, um die Zufälligkeit des generierten Textes anzupassen. Je niedriger der Wert, desto wahrscheinlicher ist es, dass das Modell die Wörter mit der höchsten Wahrscheinlichkeit auswählt, was zu einem vorhersehbareren Text führt. Je höher der Wert, desto wahrscheinlicher ist es, dass das Modell Wörter mit geringerer Wahrscheinlichkeit untersucht, was zu einem vielfältigeren Text, aber möglicherweise auch zu mehr Fehlern führt.
- Max. neue Token: Gibt die maximale Anzahl von Wörtern an, die das Modell beim Generieren von Text generieren kann. Durch die Begrenzung der Anzahl der generierten Wörter können Sie die Länge der Ausgabe steuern und die Generierung von zu langem oder zu kurzem Text verhindern.
Sie können die Parameter Ihren Bedürfnissen entsprechend anpassen.

KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.