Command Palette
Search for a command to run...
Quantisierung Von Vision Transformers (Vit) Für Eine Effiziente Bereitstellung: Strategien Und Bewährte Methoden
Dieses Tutorial empfiehlt die Verwendung von PyTorch Version 2.0 und einer einzelnen 4090-GPU. Zur einfacheren Verwendung wurden die verwendeten Modelle in das Tutorial heruntergeladen. Bitte führen Sie sie einzeln aus.
1. Einleitung
Da die Nachfrage nach fortschrittlichen Computer-Vision-Systemen branchenübergreifend weiter steigt, ist der Einsatz von Vision Transformers in den Fokus von Forschern und Praktikern gerückt. Um das volle Potenzial dieser Modelle auszuschöpfen, ist jedoch ein tiefes Verständnis ihrer Architektur erforderlich. Darüber hinaus ist es ebenso wichtig, Optimierungsstrategien für den effektiven Einsatz dieser Modelle zu entwickeln.
Dieser Artikel soll einen Überblick über den Vision Transformer geben und seine Architektur, Schlüsselkomponenten und die Grundlagen, die ihn einzigartig machen, umfassend untersuchen. Am Ende des Artikels werden wir einige Optimierungsstrategien mit Codedemonstrationen besprechen, um das Modell kompakter zu machen und so die Bereitstellung zu erleichtern.
2. Überblick über Vit
ViT ist ein spezieller Typ neuronaler Netzwerke, das hauptsächlich zur Bildklassifizierung und Objekterkennung verwendet wird. Die Genauigkeit von ViT hat die herkömmlicher CNNs übertroffen. Der Hauptfaktor hierfür ist, dass sie auf der Transformer-Architektur basieren. Was ist das nun für eine Architektur?
Im Jahr 2017 haben Vaswani et al. „Aufmerksamkeit ist alles, was Sie brauchen“Die Transformer-Architektur neuronaler Netzwerke wird in eingeführt. Das Netzwerk verwendet eine Encoder- und Decoderstruktur, die einem Recurrent Neural Network (RNN) sehr ähnlich ist. In diesem Modell gibt es kein Konzept von Zeitstempeln auf der Eingabe; Alle Wörter werden gleichzeitig durchlaufen und ihre Wort-Einbettungen werden gleichzeitig bestimmt.
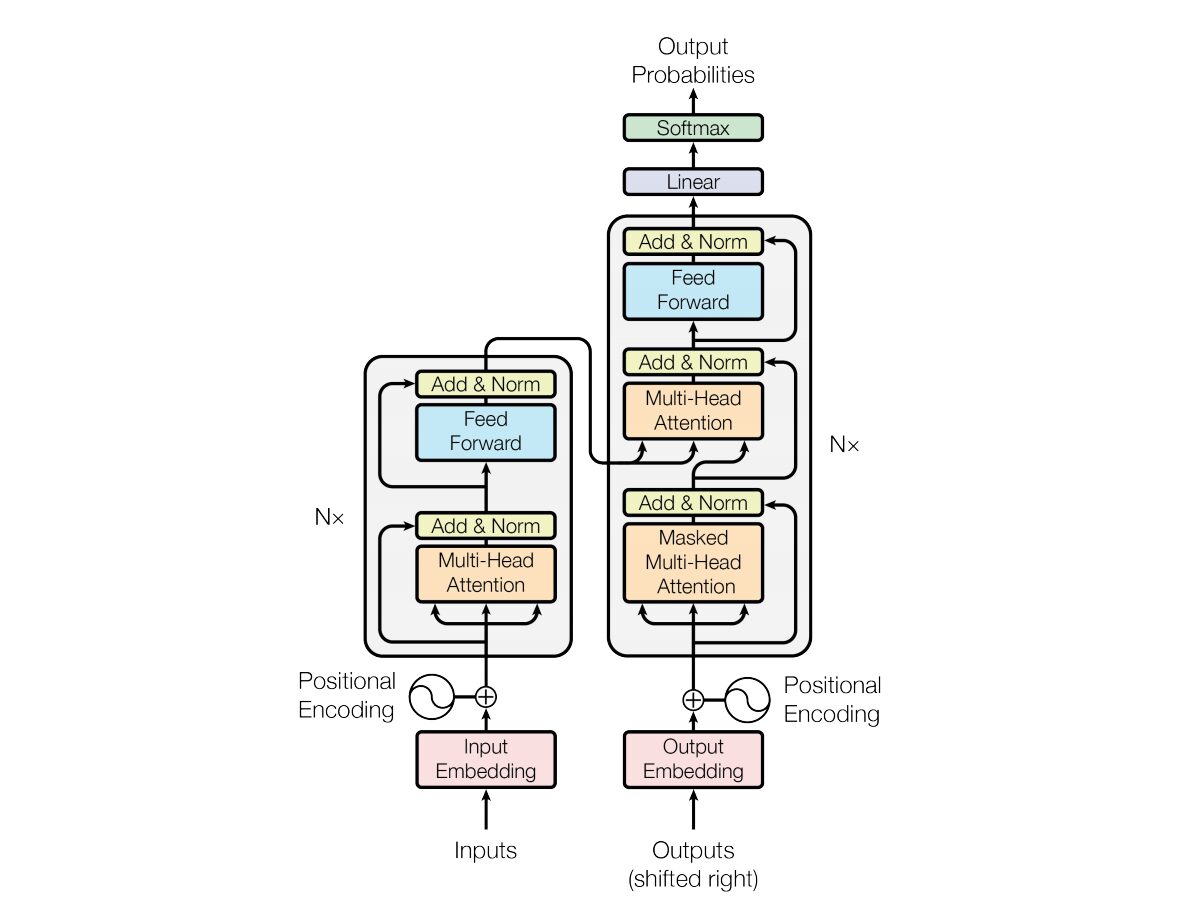
Diese Art der neuronalen Netzwerkarchitektur basiert auf einem Mechanismus namens „Selbstaufmerksamkeit“.
Hier ist eine allgemeine Erklärung der Hauptkomponenten der Transformer-Architektur:
- Eingabeeinbettung: Die Eingabeeinbettung ist der erste Schritt beim Übergeben der Eingabe an den Transformator. Unter Eingabeeinbettung versteht man den Prozess der Konvertierung von Eingabetoken oder -wörtern in einen Vektor fester Größe, der in das Modell eingespeist werden kann. Dieser Einbettungsschritt ist entscheidend, da er die diskrete Token-Darstellung in eine kontinuierliche Vektordarstellung umwandelt, und zwar auf eine Weise, die die semantischen Beziehungen zwischen Wörtern erfasst. Dieser Einbettungsschritt ordnet ein Wort einem Vektor zu, aber dasselbe Wort kann in verschiedenen Sätzen unterschiedliche Bedeutungen haben. Hier kommen Positionsgeber ins Spiel.
- Positionskodierungen: Da der Transformer selbst die Reihenfolge der Elemente in einer Sequenz nicht versteht, werden den Eingabeeinbettungen Positionskodierungen hinzugefügt, um dem Modell Informationen über die Position des Elements in der Sequenz bereitzustellen. Kurz gesagt, Positionseinbettungen ergeben einen Vektor, der kontextuell auf der Position eines Wortes in einem Satz basiert. Im Originalpapier wurden Sinus- und Cosinusfunktionen zur Generierung dieses Vektors verwendet. Diese Informationen werden an den Encoderblock weitergegeben.
- Encoder-Decoder-Struktur: Transformer wird hauptsächlich für Sequenz-zu-Sequenz-Aufgaben wie maschinelle Übersetzung verwendet. Es besteht aus einem Encoder und einem Decoder. Der Encoder verarbeitet die Eingabesequenz und der Decoder generiert die Ausgabesequenz.
- Multi-Head-Self-Attention: Durch Self-Attention kann das Modell bei Vorhersagen verschiedene Teile der Eingabesequenz unterschiedlich gewichten. Die wichtigste Neuerung des Transformers ist die Verwendung mehrerer Aufmerksamkeitsköpfe, wodurch sich das Modell gleichzeitig auf verschiedene Aspekte der Eingabe konzentrieren kann. Jeder Aufmerksamkeitskopf wird darauf trainiert, sich auf ein anderes Muster zu konzentrieren.
- Skaliertes Skalarprodukt der Aufmerksamkeit: Der Aufmerksamkeitsmechanismus berechnet eine Reihe von Aufmerksamkeitsbewertungen, indem er das Skalarprodukt der Eingabesequenz und einen lernbaren Gewichtsvektor nimmt. Diese Werte werden skaliert und durch eine Softmax-Funktion geleitet, um Aufmerksamkeitsgewichte zu erhalten. Die gewichtete Summe der Eingabesequenz unter Verwendung dieser Aufmerksamkeitsgewichte ist die Ausgabe des Aufmerksamkeitsmechanismus.
- Feedforward-Neuralnetzwerk: Nach der Aufmerksamkeitsschicht enthält jeder Encoder- und Decoderblock normalerweise ein Feedforward-Neuralnetzwerk mit einer Aktivierungsfunktion wie ReLu. Das Netzwerk wird unabhängig auf jede Position in der Sequenz angewendet.
- Schichtnormalisierung und Restverbindungen: Schichtnormalisierung und Restverbindungen werden verwendet, um das Training zu stabilisieren. Jede Unterschicht (Aufmerksamkeit oder Feedforward) sowohl im Encoder als auch im Decoder verfügt über eine Schichtnormalisierung, und die Ausgabe jeder Unterschicht wird über eine Restverbindung geleitet.
- Encoder- und Decoder-Stapel: Encoder und Decoder bestehen aus mehreren identischen, übereinander gestapelten Schichten. Die Anzahl der Schichten ist ein Hyperparameter.
- Maskierte Selbstaufmerksamkeit im Decoder: Während des Trainings wird im Decoder der Selbstaufmerksamkeitsmechanismus geändert, um die Beachtung zukünftiger Token zu verhindern. Dies geschieht durch Maskierungstechniken, um sicherzustellen, dass jede Position nur die Position davor verarbeiten kann.
- Abschließende lineare und Softmax-Schichten: Die Ausgabe des Decoder-Stacks wird in abschließende Vorhersagewahrscheinlichkeiten umgewandelt (z. B. mithilfe einer linearen Schicht, gefolgt von einer Softmax-Aktivierung), um die Ausgabesequenz zu erzeugen.
3. Die Vision Transformer-Architektur verstehen
CNN gilt als die beste Lösung für Bildklassifizierungsaufgaben. Wenn der vor dem Training erstellte Datensatz groß genug ist, schlägt ViT CNN bei solchen Aufgaben durchweg. ViT erzielte bedeutende Erfolge durch das erfolgreiche Trainieren eines Transformer-Encoders auf ImageNet und zeigte beeindruckende Ergebnisse im Vergleich zu bekannten Faltungsarchitekturen.
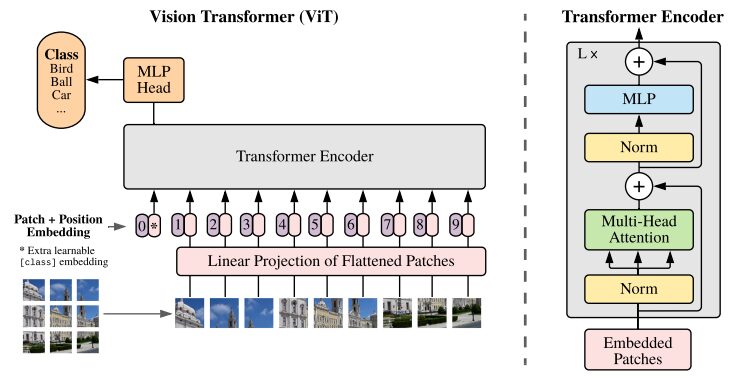
Abbildung der ViT-Architektur aus dem ursprünglichen Forschungspapier
Transformer-Modelle verarbeiten normalerweise Bilder und Wörter, die sequenziell an einen Encoder-Decoder übergeben werden. Hier ist eine vereinfachte Übersicht über ViT:
- Patch-Extraktion: Ein Bild wird dem Transformer-Encoder als Patch-Sequenz zugeführt. Ein Patch ist ein kleiner rechteckiger Teil eines Bildes, normalerweise 16 x 16 Pixel groß.

- Nachdem das Bild in nicht überlappende Blöcke unterteilt wurde (normalerweise ein 16×16-Raster), wird jeder Block in einen Vektor umgewandelt, der seine Merkmale darstellt. Diese Merkmale werden normalerweise mithilfe eines Convolutional Neural Network (CNN) extrahiert, das darauf trainiert ist, wichtige Merkmale zu identifizieren, die für die Bildklassifizierung erforderlich sind.
- Lineare Einbettung: Diese extrahierten Patches werden linear in planare Vektoren eingebettet. Diese Vektoren werden dann als Eingabesequenz für den Transformer behandelt, auch bekannt als lineare Projektion des abgeflachten Patches.
- Transformer Encoder: Der eingebettete Patch-Vektor wird durch den Transformer Encoder-Layer-Stapel geleitet. Jede Encoderschicht besteht aus einem Self-Attention-Mechanismus und einem Feedforward-Neuralnetzwerk.
- Selbstaufmerksamkeitsmechanismus: Der Selbstaufmerksamkeitsmechanismus ermöglicht es dem Modell, die Beziehung zwischen verschiedenen Patches im Bild zu erfassen und so Abhängigkeiten und Beziehungen über große Entfernungen zu erlernen. Der Aufmerksamkeitsmechanismus im Transformer ermöglicht es dem Modell, sowohl lokale als auch globale Kontextinformationen zu erfassen, sodass es verschiedene Sichtaufgaben effektiv ausführen kann.
- Positionskodierung: Da der Transformer selbst die räumliche Beziehung zwischen Patches nicht versteht, wird der Eingabeeinbettung eine Positionskodierung hinzugefügt, um Informationen über die Position des Patches im Originalbild bereitzustellen.
- Mehrere Encoder-Ebenen: ViT verwendet normalerweise mehrere Transformer-Encoder-Ebenen, um hierarchische und abstrakte Merkmale aus dem Eingabebild zu erfassen.
- Globales Durchschnittspooling: Die Ausgabe des Transformer-Encoders wird normalerweise einem globalen Durchschnittspooling unterzogen, bei dem Informationen aus verschiedenen Patches in einer Darstellung mit fester Größe zusammengefasst werden.
- Klassifizierungskopf: Die zusammengeführte Darstellung wird dann in einen Klassifizierungskopf (der normalerweise aus einer oder mehreren vollständig verbundenen Schichten besteht) eingespeist, um die endgültige Ausgabe für eine bestimmte Computer Vision-Aufgabe (z. B. Bildklassifizierung) zu generieren.
Wir empfehlen Ihnen dringend, das Original anzusehenForschungsarbeiten, für ein tieferes Verständnis der ViT-Architektur.
4. Wie zu verwenden
Auf die folgenden Codes kann in pre_ViT.ipynb zugegriffen und sie können dort ausgeführt werden! ! ! !
4.1 Bilder mit dem vortrainierten ViT-Modell klassifizieren
Vortrainierte ViT-Modelle werden mit dem bekannten ImageNet-21k, einem Datensatz mit 14 Millionen Bildern und 21.000 Kategorien, vortrainiert und auf dem ImageNet-Datensatz mit 1 Million Bildern und 1.000 Kategorien feinabgestimmt.
Demo:
- Die folgenden zwei Bibliotheken fehlen, wenn Sie die Plattform zum ersten Mal starten. Verwenden Sie pip, um Abhängigkeiten zu installieren. Fügen Sie den zusätzlichen Parameter --user hinzu, wenn Sie Abhängigkeiten mit pip installieren. Dann werden die installierten Abhängigkeiten im Arbeitsbereich des Containers gespeichert und beim nächsten Neustart nicht ungültig.
!pip install --user -q transformers timm- Importieren Sie die erforderlichen Klassen aus der Transformer-Bibliothek. ViTFeatureExtractor wird zum Extrahieren von Merkmalen aus Bildern verwendet und ViTForImageClassification ist ein vortrainiertes ViT-Modell zur Bildklassifizierung.
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image as img
from IPython.display import Image, display
FILE_NAME = '/notebooks/football-1419954_640.jpg'
display(Image(FILE_NAME, width = 700, height = 400))
#预测图片的地址
image_path = "./pic/football.jpg"
image_array = img.open(image_path)
#Vit 模型地址
vision_encoder_decoder_model_name_or_path = "./my_model/"
#加载 ViT 特征转化 and 预训练模型
#feature_extractor = ViTFeatureExtractor.from_pretrained(vision_encoder_decoder_model_name_or_path)
#model = ViTForImageClassification.from_pretrained(vision_encoder_decoder_model_name_or_path)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
#使用 Vit 特征提取器处理输入图像,专为 ViT 模型的格式
inputs = feature_extractor(images = image_array,
return_tensors="pt")
#预训练模型处理输入并生成输出 logits,代表模型对不同类别的预测。
outputs = model(**inputs)
#创建一个变量来存储预测类的索引。
logits = outputs.logits
# 查找具有最高 Logit 分数的类的索引
predicted_class_idx = logits.argmax(-1).item()
print(predicted_class_idx)
#805
print("Predicted class:", model.config.id2label[predicted_class_idx])
#预测种类:足球Codeaufschlüsselung:
- ViTFeatureExtractor.from_pretrained: Verantwortlich für die Konvertierung des Eingabebilds in ein für das ViT-Modell geeignetes Format.
- ViTForImageClassification.from_pretrained: Lädt ein vortrainiertes ViT-Modell zur Bildklassifizierung.
- feature_extractor: Verarbeitet das Eingabebild mithilfe des ViT-Feature-Extraktors und konvertiert es in ein für das ViT-Modell geeignetes Format.
- Modell: Das vortrainierte Modell verarbeitet die Eingabe und generiert Ausgabe-Logits, die die Vorhersagen des Modells für verschiedene Kategorien darstellen. Der nächste Schritt besteht darin, den Index der Klasse mit dem höchsten Logit-Score zu finden. Erstellen Sie eine Variable zum Speichern des Index der vorhergesagten Klasse.
- model.config.id2label[predicted_class_idx]: Ordnet vorhergesagte Klassenindizes ihren entsprechenden Labels zu.
4.2 Klassifizieren von Bildern mit DeiT
DeiT demonstriert die erfolgreiche Anwendung von Transformers auf Computer Vision-Aufgaben, selbst bei begrenzter Datenverfügbarkeit und begrenzten Ressourcen.
from PIL import Image
import torch
import timm
import requests
import torchvision.transforms as transforms
from timm.data.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
print(torch.__version__)
# should be 1.8.0
#从 DeiT 存储库加载名为 “deit_base_patch16_224” 的预训练 DeiT 模型。
model = torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True)
#将模型设置为评估模式,这在使用预训练模型进行推理时非常重要。
model.eval()
#定义一系列应用于图像的变换。例如调整大小、中心裁剪、将图像转换为 PyTorch 张量、使用 ImageNet 数据常用的平均值和标准差值对图像进行归一化。
transform = transforms.Compose([
transforms.Resize(256, interpolation=3),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD),
])
#从 URL 下载图像并对其进行转换。或者直接从本地上传
#Image.open(requests.get("https://images.rawpixel.com/image_png_800/czNmcy1wcml2YXRlL3Jhd3BpeGVsX2ltYWdlcy93ZWJzaXRlX2NvbnRlbnQvcHUyMzMxNjM2LWltYWdlLTAxLXJtNTAzXzMtbDBqOXFrNnEucG5n.png", stream=True).raw)
img = Image.open("./pic/football.jpg")
#None 模拟大小为 1 的批次
img = transform(img)[None,]
#模型的推理、预测
out = model(img)
clsidx = torch.argmax(out)
#打印预测类别的索引。
print(clsidx.item())Codeaufschlüsselung:
- Installieren von Bibliotheken: Der erste notwendige Schritt besteht darin, die erforderlichen Bibliotheken zu installieren. Wir empfehlen Benutzern dringend, diese Bibliotheken zum besseren Verständnis zu studieren.
- Vortrainiertes Modell laden:: model=torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True) lädt das vortrainierte DeiT-Modell mit dem Namen 'deit_base_patch16_224' aus dem DeiT-Repository.
- Setzen Sie das Modell in den Auswertungsmodus: model.eval(): Setzt das Modell in den Auswertungsmodus, was sehr wichtig ist, wenn Sie ein vortrainiertes Modell für die Inferenz verwenden.
- Bildtransformationen: Definiert eine Reihe von Transformationen, die auf ein Bild angewendet werden sollen. Beispiele hierfür sind Größenänderung, zentriertes Zuschneiden, Konvertieren von Bildern in PyTorch-Tensoren und Normalisieren von Bildern mithilfe der von ImageNet-Daten üblicherweise verwendeten Mittelwert- und Standardabweichungswerte. Bild herunterladen und konvertieren: Im nächsten Schritt wird das Bild von der URL heruntergeladen und konvertiert. Durch Hinzufügen des Arguments [None,] wird eine zusätzliche Dimension hinzugefügt, um Stapel der Größe 1 zu simulieren.
- Modellinferenz und -vorhersage: out = model(img) ermöglicht die Inferenz des vorverarbeiteten Bildes durch das DeiT-Modell. clsidx = torch.argmax(out) findet den Index der Klasse mit der höchsten Wahrscheinlichkeit. Drucken Sie als Nächstes den Index der vorhergesagten Klasse.
4.3 Quantisierungsmodell
Um die Modellgröße zu reduzieren, wird eine Quantisierung angewendet. Dieser Prozess reduziert die Größe, ohne die Genauigkeit des Modells zu beeinträchtigen.
#将量化后端指定为 “qnnpack” 。 QNNPACK(Quantized Neural Network PACKage)是 Facebook 开发的低精度量化神经网络推理库
backend = "qnnpack"
model.qconfig = torch.quantization.get_default_qconfig(backend)
torch.backends.quantized.engine = backend
#推理过程中量化模型的权重,并 qconfig_spec 指定量化应仅应用于线性(全连接)层。使用的量化数据类型是 torch.qint8(8 位整数量化)
quantized_model = torch.quantization.quantize_dynamic(model, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)
scripted_quantized_model = torch.jit.script(quantized_model)
#模型保存到名为 “fbdeit_scripted_quantized.pt” 的文件
scripted_quantized_model.save("fbdeit_scripted_quantized.pt")Codeaufschlüsselung:
- torch.quantization.quantize_dynamic(Modell, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)
- qconfig_spec gibt an, dass die Quantisierung nur auf lineare (vollständig verbundene) Ebenen angewendet werden soll. Der verwendete Quantisierungsdatentyp ist torch.qint8 (8-Bit-Ganzzahlquantisierung).
4.4 Optimierungsmodell
Die Funktion optimize_for_mobile optimiert es speziell für den mobilen Einsatz und speichert das resultierende optimierte Modell in einer Datei.
from torch.utils.mobile_optimizer import optimize_for_mobile
optimized_scripted_quantized_model = optimize_for_mobile(scripted_quantized_model)
optimized_scripted_quantized_model.save("fbdeit_optimized_scripted_quantized.pt")
# 使用优化模型进行预测
out = optimized_scripted_quantized_model(img)
clsidx = torch.argmax(out)
print(clsidx.item())4.5 Lite-Version
Dies ist wichtig für die Bereitstellung von Modellen auf mobilen oder Edge-Geräten, die PyTorch Lite unterstützen, um die Kompatibilität und Effizienz der Laufzeitumgebung solcher Geräte sicherzustellen.
optimized_scripted_quantized_model._save_for_lite_interpreter("fbdeit_optimized_scripted_quantized_lite.ptl")
ptl = torch.jit.load("fbdeit_optimized_scripted_quantized_lite.ptl")4.6 Vergleich der Inferenzgeschwindigkeit
Um die Inferenzgeschwindigkeit verschiedener Modellvarianten zu vergleichen, führen Sie den bereitgestellten Code aus:
with torch.autograd.profiler.profile(use_cuda=False) as prof1:
out = model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof2:
out = scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof3:
out = optimized_scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof4:
out = ptl(img)
print("original model: {:.2f}ms".format(prof1.self_cpu_time_total/1000))
print("scripted & quantized model: {:.2f}ms".format(prof2.self_cpu_time_total/1000))
print("scripted & quantized & optimized model: {:.2f}ms".format(prof3.self_cpu_time_total/1000))
print("lite model: {:.2f}ms".format(prof4.self_cpu_time_total/1000))
Auf alle oben genannten Codes kann in pre_ViT.ipynb zugegriffen und sie können dort ausgeführt werden! ! ! !
Fazit und Gedanken
In diesem Artikel haben wir alles behandelt, was Sie für den Einstieg in den Visual Converter und zum Erkunden des Modells mithilfe der Paperspace-Konsole benötigen. Wir haben eine der wichtigsten Anwendungen dieses Modells untersucht: die Bilderkennung. Zum Vergleich und zur einfacheren Interpretation von ViT beziehen wir auch die Transformer-Architektur mit ein.
Das Vision Transformer-Papier stellt ein vielversprechendes und einfaches Modell als Alternative zu CNNs vor. Nach dem Vortraining mit ImageNet von ILSVRC und dessen Obermenge ImageNet-21M erreicht das Modell modernste Benchmarks bei beliebten Bildklassifizierungsdatensätzen, darunter Oxford-IIIT Pets, Oxford Flowers und JFT-300M von Google Brain.
Zusammenfassend stellen Vision Transformers (ViTs) und DeiT bedeutende Fortschritte im Bereich der Computer Vision dar. ViT demonstrierte die Wirksamkeit des Transformer-Modells für das Bildverständnis mit seiner aufmerksamkeitsbasierten Architektur und stellte traditionelle Faltungsansätze in Frage.
Insbesondere DeiT geht die Herausforderungen, vor denen ViT steht, durch die Einführung der Wissensdestillation weiter an. Durch die Nutzung eines Lehrer-Schüler-Trainingsparadigmas zeigt DeiT das Potenzial, mit deutlich weniger gekennzeichneten Daten wettbewerbsfähige Leistungen zu erzielen, was es zu einer wertvollen Lösung in Szenarien macht, in denen große Datensätze nicht ohne Weiteres verfügbar sind.
Da die Forschung auf diesem Gebiet immer weiter voranschreitet, ebnen diese Innovationen den Weg für effizientere und leistungsfähigere Modelle und eröffnen spannende Möglichkeiten für die Zukunft von Computer Vision-Anwendungen.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.