Command Palette
Search for a command to run...
Training Von YOLOv8 Mit Benutzerdefinierten Daten
In diesem Tutorial erkunden wir die neuen Funktionen des neuen Modells YOLOv8 von Ultralytics, gehen detailliert auf die architektonischen Änderungen im Vergleich zu YOLOv5 ein und demonstrieren das neue Modell anhand der Python-API-Erkennungsmöglichkeiten unseres Basketball-Datensatzes. Es behandelt hauptsächlich die Prinzipien von YOLOv8, zeigt, wie man einen Datensatz erstellt und beschriftet, das Modell trainiert und es auf eingehende Videodateien oder Streams anwendet.
Die Objekterkennung bleibt einer der beliebtesten und einfachsten Anwendungsfälle für KI-Technologie. Seit der Veröffentlichung der ersten Version in der bahnbrechenden Arbeit von Joseph Redman et al. Im Jahr 2016 führte die YOLO-Modellfamilie mit „You Only Look Once: Unified, Real-Time Object Detection“ den Trend an. Diese Objekterkennungsmodelle ebneten den Weg für die Untersuchung der Verwendung von DL-Modellen zur Echtzeiterkennung von Entitäten, Subjekten und Standorten in Bildern.
In diesem Artikel werden wir die Grundlagen dieser Techniken noch einmal durchgehen, die neuen Funktionen der neuesten Version von Ultralytics, YOLOv8, besprechen und die Schritte zur Feinabstimmung eines benutzerdefinierten YOLOv8-Modells mit RoboFlow und Paperspace Gradient und der neuen Ultralytics-API durchgehen. Am Ende dieses Tutorials sollten Benutzer in der Lage sein, schnell und einfach ein YOLOv8-Modell an jeden Satz beschrifteter Bilder anzupassen.
Wie funktioniert YOLO?
Lassen Sie uns zunächst die Grundlagen der Funktionsweise von YOLO besprechen. Hier ist ein kurzes Zitat aus dem Originalpapier von YOLO, in dem die Gesamtheit der Fähigkeiten des Modells aufgeschlüsselt wird:
Ein einzelnes Faltungsnetzwerk prognostiziert gleichzeitig mehrere Begrenzungsrahmen und deren Klassenwahrscheinlichkeiten. YOLO wird anhand vollständiger Bilder trainiert und optimiert die Erkennungsleistung direkt. Dieses einheitliche Modell bietet gegenüber herkömmlichen Methoden zur Objekterkennung mehrere Vorteile.
Wie oben erwähnt, kann das Modell die Position mehrerer Objekte in einem Bild vorhersagen und deren Motiv identifizieren, sofern es auf diese Merkmale trainiert wurde. Dies geschieht in einem einzigen Schritt, indem das Bild in N Raster mit der Größe s*s unterteilt wird. Diese Regionen werden gleichzeitig analysiert, um darin enthaltene Objekte zu erkennen und zu lokalisieren. Das Modell prognostiziert dann die Koordinaten B des Begrenzungsrahmens in jeder Gitterzelle und prognostiziert die Beschriftungen und Vorhersagewerte für die darin enthaltenen Objekte.
Zusammengenommen erhalten wir eine Technik, die Objektklassifizierung, Objekterkennung und Bildsegmentierung ermöglicht. Da die zugrunde liegende Technologie von YOLO unverändert bleibt, können wir davon ausgehen, dass dies auch mit YOLOv8 funktioniert. Eine umfassendere Beschreibung der Funktionsweise von YOLO finden Sie in unseren früheren Beiträgen zu YOLOv5 und YOLOv7, unseren Benchmarks mit YOLOv6 und YOLOv7 sowie im Original-YOLO-Artikel.
Was ist neu in YOLOv8?
Da YOLOv8 gerade erst veröffentlicht wurde, gibt es noch kein veröffentlichtes Dokument zu diesem Modell. Die Autoren beabsichtigen, es bald zu veröffentlichen, aber im Moment können wir nur dem offiziellen Veröffentlichungsbeitrag folgen, die Änderungen aus dem Commit-Verlauf ableiten und versuchen, das Ausmaß der Änderungen zwischen YOLOv5 und YOLOv8 selbst zu bestimmen.
entsprechendOffizielle Veröffentlichung, YOLOv8 verwendet ein neues Backbone-Netzwerk, einen ankerfreien Erkennungskopf und eine Verlustfunktion. Der Github-Benutzer RangeKing hat einen Überblick über die YOLOv8-Modellinfrastruktur freigegeben und das aktualisierte Modell-Backbone und die Kopfstruktur gezeigt. Vergleicht man diese Zahl mit YOLOv5 Im Vergleich zu ähnlichen Prüfungen von RangeKing in ihremBeiträgeFolgende Änderungen wurden festgestellt in:

C2f Modul, Bildquelle: RoboFlow (Quelle)- Sie verwenden
C2fModul ersetztC3Modul. existierenC2fIn, vonBottleneck(zwei 3×3 mit Restverbindungenconvs) sind miteinander verbunden, aber inC3Nur der letzte wird verwendetBottleneckAusgabe. (Quelle)

- Sie sind
BackboneVerwenden Sie eine3x3 ConvDer Block ersetzt den ersten6x6 Conv - Sie löschten zwei
Conv(10. und 14. in der YOLOv5-Konfiguration)

- Sie sind
BottleneckVerwenden Sie eine3x3 ConvErsetzte den ersten1x1 Conv - Sie wechselten zu entkoppelten Headern und entfernten
objectnessFilialen
Bitte schauen Sie noch einmal vorbei, sobald das YOLOv8-Dokument veröffentlicht ist. Wir werden diesen Abschnitt mit weiteren Informationen aktualisieren. Eine detaillierte Analyse der oben genannten Änderungen finden Sie im RoboFlow-Artikel, der Folgendes vorstellt: YOLOv8 Freigeben.
Zugänglichkeit
Zusätzlich zur alten Methode, das Github-Repository zu klonen und die Umgebung manuell einzurichten, können Benutzer jetzt mithilfe der neuen Ultralytics-API auf YOLOv8 zugreifen, um es zu trainieren und Inferenzen durchzuführen. Siehe unten Trainieren des Modells Weitere Informationen zum Einrichten der API finden Sie im Abschnitt „API einrichten“.
Kein Anker-Begrenzungsrahmen
Laut einem Blogbeitrag des Ultralytics-Partners RoboFlow YOLOv8, YOLOv8 verfügt jetzt über ankerfreie Begrenzungsrahmen. In der ersten Version von YOLO mussten Benutzer diese Ankerboxen manuell identifizieren, um den Objekterkennungsprozess zu erleichtern. Diese vordefinierten Begrenzungsrahmen haben eine vorgegebene Größe und Höhe und erfassen den Maßstab und das Seitenverhältnis bestimmter Objektkategorien im Datensatz. Die Abstände dieser Grenzen zu den vorhergesagten Objekten helfen dem Modell, die Position der Objekte besser zu identifizieren.
In YOLOv8 werden diese Ankerboxen automatisch in der Mitte des Objekts vorhergesagt.
Stoppen Sie die Mosaikerweiterung, bevor das Training abgeschlossen ist
Während jeder Trainingsepoche sieht YOLOv8 eine leicht unterschiedliche Version des bereitgestellten Bildes. Diese Änderungen werden als Verbesserungen bezeichnet. Einer von ihnen,Mosaikverbesserungist der Prozess, bei dem vier Bilder miteinander kombiniert werden, wodurch das Modell gezwungen wird, die Identität von Objekten an neuen Positionen zu erlernen, an denen sie durch Okklusion teilweise voneinander verdeckt sind und bei denen die Variation der umgebenden Pixel größer ist. Es hat sich gezeigt, dass die Verwendung dieser Erweiterung während des Trainings einen nachteiligen Effekt auf die Vorhersagegenauigkeit haben kann, sodass YOLOv8 diesen Prozess während der letzten Trainingsepochen stoppen kann. Dadurch kann das beste Trainingsmodell ausgeführt werden, ohne dass eine Skalierung auf den gesamten Lauf erforderlich ist.
Effizienz und Genauigkeit
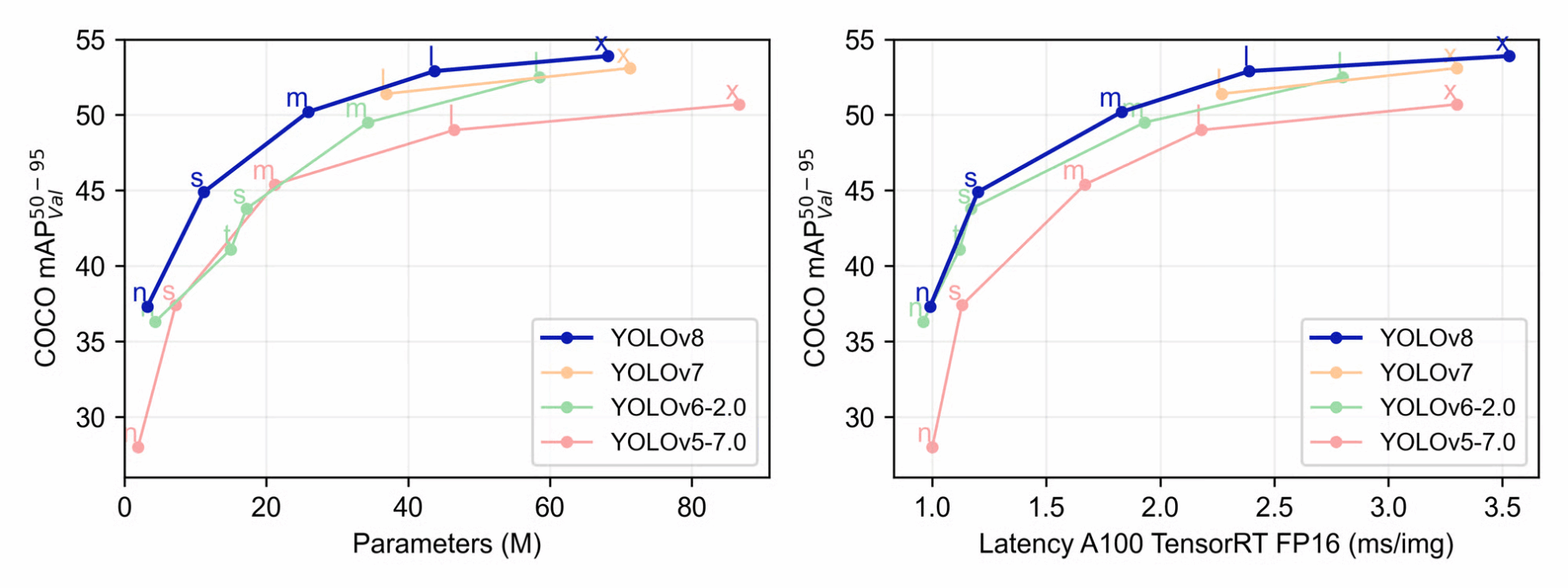
Unser Hauptgrund hierfür ist die Verbesserung der Leistungsgenauigkeit und Effizienz während der Inferenz und des Trainings. Die Autoren von Ultralytics haben uns einige nützliche Beispieldaten zur Verfügung gestellt, die wir verwenden können, um die neue Version von YOLO mit anderen Versionen zu vergleichen. Wie aus den obigen Diagrammen ersichtlich ist, übertrifft YOLOv8 während des Trainings YOLOv7, YOLOv6-2.0 und YOLOv5-7.0 in Bezug auf durchschnittliche Präzision, Größe und Latenz.

Auf den jeweiligen Github-Seiten finden wir eine statistische Vergleichstabelle von YOLOv8-Modellen unterschiedlicher Größe. Aus der obigen Tabelle können wir ersehen, dass mit zunehmender Größe der Parameter, der Geschwindigkeit und der FLOPs auch der mAP zunimmt. Das größte YOLOv5-Modell, YOLOv5x, hat einen maximalen mAP-Wert von 50,7. Die Erhöhung des mAP-Werts um 2,2 Einheiten stellt eine erhebliche Leistungssteigerung dar. Dies gilt für alle Modellgrößen, wobei das neue YOLOv8-Modell YOLOv5 durchweg übertrifft, wie unten gezeigt.

Insgesamt können wir feststellen, dass YOLOv8 im Vergleich zu YOLOv5 und anderen konkurrierenden Frameworks einen bedeutenden Fortschritt darstellt.
Feinabstimmung von YOLOv8
So führen Sie das Lernprogramm aus:Starten Sie mit OpenBayes
Der Prozess der Feinabstimmung eines YOLOv8-Modells kann in drei Schritte unterteilt werden: Erstellen und Beschriften eines Datensatzes, Trainieren des Modells und Bereitstellen des Modells. In diesem Tutorial gehen wir die ersten beiden Schritte im Detail durch und zeigen, wie Sie unser neues Modell auf jede eingehende Videodatei oder jeden eingehenden Stream anwenden.
Einrichten des Datensatzes
Wir werden das YOLOv7-Experiment, das wir zum Vergleich der beiden Modelle verwendet haben, nachbilden und daher zum Basketball-Datensatz auf Roboflow zurückkehren. Im Abschnitt „Einrichten eines benutzerdefinierten Datensatzes“ des vorherigen Artikels finden Sie detaillierte Anweisungen zum Einrichten des Datensatzes, seiner Beschriftung und zum Übertragen aus RoboFlow in unser Notebook.
Da wir einen zuvor erstellten Datensatz verwenden, müssen wir jetzt nur noch die Daten abrufen. Unten finden Sie die Befehle zum Abrufen der Daten in die Notebook-Umgebung. Verwenden Sie für Ihren eigenen beschrifteten Datensatz denselben Vorgang, ersetzen Sie jedoch die Arbeitsbereichs- und Projektwerte durch Ihre eigenen, um auf dieselbe Weise auf Ihren Datensatz zuzugreifen.
Bitte ändern Sie den API-Schlüssel unbedingt in Ihren eigenen, wenn Sie die Demonstration im Notebook mithilfe des folgenden Skripts nachvollziehen möchten.
!pip install roboflow
from roboflow import Roboflow
rf = Roboflow(api_key="")
project = rf.workspace("james-skelton").project("ballhandler-basketball")
dataset = project.version(11).download("yolov8")
!mkdir datasets
!mv ballhandler-basketball-11/ datasets/Trainieren des Modells
Mit der neuen Python-API können wir ultralytics Die Bibliothek erledigt die gesamte Arbeit problemlos in der Gradient Notebook-Umgebung. Wir werden von Grund auf neu erstellen, indem wir die bereitgestellte Konfiguration und Gewichte verwenden YOLOv8n Modell. Wir verwenden dann den Datensatz, den wir gerade in unsere Umgebung geladen haben, mit model.train() Optimieren Sie die Methode.
from ultralytics import YOLO
# 加载模型
model = YOLO("yolov8n.yaml") # 从头构建新模型
model = YOLO("yolov8n.pt") # 加载预训练模型(建议用于训练)
# 使用模型
results = model.train(data="datasets/ballhandler-basketball-11/data.yaml", epochs=10) # 训练模型Testen des Modells
results = model.val() # 在验证集上评估模型性能Wir können model.val() 方法 Legen Sie das neue Modell fest, das anhand des Validierungssatzes ausgewertet werden soll. Dadurch wird im Ausgabefenster eine übersichtliche Tabelle ausgegeben, die die Leistung unseres Modells zeigt. Da wir hier nur zehn Epochen lang trainiert haben, ist dieser relativ niedrige mAP von 50-95 zu erwarten.

Von dort aus ist das Einreichen eines Fotos ganz einfach. Es gibt Vorhersagen für Begrenzungsrahmen aus, überlagert das Bild mit diesen Rahmen und lädt sie in den Ordner „runs/detect/predict“ hoch.
from ultralytics import YOLO
from PIL import Image
import cv2
# from PIL
im1 = Image.open("assets/samp.jpeg")
results = model.predict(source=im1, save=True) # 保存绘制的图像
print(results)
display(Image.open('runs/detect/predict/image0.jpg'))Wir erhalten die Vorhersagen für Begrenzungsrahmen und ihre Beschriftungen wie folgt:
[Ultralytics YOLO <class 'ultralytics.yolo.engine.results.Boxes'> masks
type: <class 'torch.Tensor'>
shape: torch.Size([6, 6])
dtype: torch.float32
+ tensor([[3.42000e+02, 2.00000e+01, 6.17000e+02, 8.38000e+02, 5.46525e-01, 1.00000e+00],
[1.18900e+03, 5.44000e+02, 1.32000e+03, 8.72000e+02, 5.41202e-01, 1.00000e+00],
[6.84000e+02, 2.70000e+01, 1.04400e+03, 8.55000e+02, 5.14879e-01, 0.00000e+00],
[3.59000e+02, 2.20000e+01, 6.16000e+02, 8.35000e+02, 4.31905e-01, 0.00000e+00],
[7.16000e+02, 2.90000e+01, 1.04400e+03, 8.58000e+02, 2.85891e-01, 1.00000e+00],
[3.88000e+02, 1.90000e+01, 6.06000e+02, 6.58000e+02, 2.53705e-01, 0.00000e+00]], device='cuda:0')]Wenden Sie sie dann auf das Bild an, wie im folgenden Beispiel gezeigt:

Wie wir sehen können, zeigt unser leichtgewichtiges trainiertes Modell, dass es die Spieler auf dem Feld von den Spielern auf dem Feld und den Spielern und Zuschauern an der Seitenlinie unterscheiden kann, mit Ausnahme einer Ecke. Es ist mit ziemlicher Sicherheit mehr Training erforderlich, aber es ist leicht zu erkennen, dass das Modell die Aufgabe sehr schnell versteht.
Wenn wir mit dem Modelltraining zufrieden sind, können wir das Modell in das gewünschte Format exportieren. In diesem Fall exportieren wir eine ONNX-Version.
success = model.export(format="onnx") # 将模型导出为 ONNX 格式Zusammenfassen
In diesem Tutorial haben wir die neuen Funktionen des leistungsstarken neuen Modells YOLOv8 von Ultralytics erkundet, uns eingehend mit den Architekturänderungen im Vergleich zu YOLOv5 befasst und die Python-API-Funktionalität des neuen Modells anhand unseres Ballhandler-Datensatzes getestet. Wir konnten zeigen, dass dies einen erheblichen Fortschritt bei der Vereinfachung des Prozesses der Feinabstimmung des YOLO-Objekterkennungsmodells darstellt, und die Fähigkeit des Modells demonstrieren, Ballbesitz in NBA-Spielen anhand von In-Game-Fotos zu unterscheiden.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.