Command Palette
Search for a command to run...
B. Y. Yan Chaofan Li Hongjin Qian Shuqi Lu Zheng Liu
Zusammenfassung
Hier ist die Übersetzung des Textes ins Deutsche, unter Berücksichtigung des akademischen und technologischen Fachjargons:Gedächtnis ist für KI-Agenten von entscheidender Bedeutung; das weit verbreitete statische Gedächtnis, das darauf abzielt, im Voraus sofort verfügbare Erinnerungen zu schaffen, unterliegt jedoch zwangsläufig schwerwiegenden Informationsverlusten. Um diese Einschränkung zu beheben, schlagen wir ein neuartiges Framework namens General Agentic Memory (GAM) vor. GAM folgt dem Prinzip der „Just-in-Time (JIT)-Kompilierung“, wobei es sich darauf konzentriert, zur Laufzeit optimierte Kontexte für seinen Client zu erstellen, während in der Offline-Phase nur ein einfaches, aber zweckdienliches Gedächtnis vorgehalten wird. Zu diesem Zweck setzt GAM ein duales Design mit folgenden Komponenten ein: 1) Dem Memorizer, der wichtige historische Informationen mithilfe eines leichtgewichtigen Gedächtnisses hervorhebt und gleichzeitig die vollständigen historischen Daten in einem universellen Page-Store (Seitenspeicher) bewahrt. 2) Dem Researcher, der nützliche Informationen aus dem Page-Store für seine Online-Anfrage abruft und integriert, geleitet durch das vorkonstruierte Gedächtnis. Dieses Design ermöglicht es GAM, die agentischen Fähigkeiten und die Skalierbarkeit zur Testzeit (Test-Time Scalability) von führenden großen Sprachmodellen (LLMs) effektiv zu nutzen und gleichzeitig eine End-to-End-Leistungsoptimierung durch Reinforcement Learning (bestärkendes Lernen) zu ermöglichen. In unserer experimentellen Studie zeigen wir, dass GAM in verschiedenen speicherbasierten Aufgabenerfüllungsszenarien wesentliche Verbesserungen gegenüber bestehenden Gedächtnissystemen erzielt.
Summarization
Researchers from the Beijing Academy of Artificial Intelligence, Peking University, and Hong Kong Polytechnic University introduce General Agentic Memory (GAM), a framework that overcomes static memory limitations by applying a just-in-time compilation principle where a dual Memorizer-Researcher architecture dynamically constructs optimized contexts from a universal page-store for enhanced memory-grounded task completion.
Introduction
AI agents are increasingly deployed in complex fields like software engineering and scientific research, creating an urgent need to manage rapidly expanding contexts. As these agents integrate internal reasoning with external feedback, effective memory systems are essential for maintaining continuity and accuracy without overwhelming the model's context window.
Prior approaches typically rely on "Ahead-of-Time" compilation, where data is compressed into static memory offline. This method suffers from inevitable information loss during compression, struggles with ad-hoc requests due to rigid structures, and depends heavily on manual heuristics that hinder cross-domain generalization.
The authors propose General Agentic Memory (GAM), a framework based on "Just-in-Time" compilation that preserves complete historical data while generating customized contexts on demand. By treating memory retrieval as a dynamic search process rather than a static lookup, GAM ensures lossless information access tailored to specific queries through a dual-agent system.
Key innovations include:
- Dual-Agent Architecture: The system employs a "Memorizer" to index historical sessions and a "Researcher" to perform iterative deep research and reflection to satisfy complex client needs.
- High-Fidelity Adaptability: By maintaining full history in a database and retrieving only what is necessary at runtime, the framework avoids compression loss and adapts dynamically to specific tasks.
- Self-Optimizing Generalization: The approach eliminates the need for domain-specific rules, allowing the system to operate across diverse scenarios and improve continuously through reinforcement learning.
Method
The authors leverage a dual-module architecture for their General Agentic Memory (GAM) system, designed to manage long agent trajectories efficiently while maintaining task performance. The framework operates in two distinct phases: an offline memorization stage and an online research stage. As shown in the figure below, the overall system consists of a memorizer and a researcher, both of which are large language model (LLM)-based agents. The memorizer processes the agent's historical trajectory during the offline phase, generating a compact memory representation and preserving the complete trajectory in a page-store. The researcher, in contrast, operates online to address client requests by retrieving and integrating relevant information from the page-store, ultimately producing an optimized context for downstream task completion.
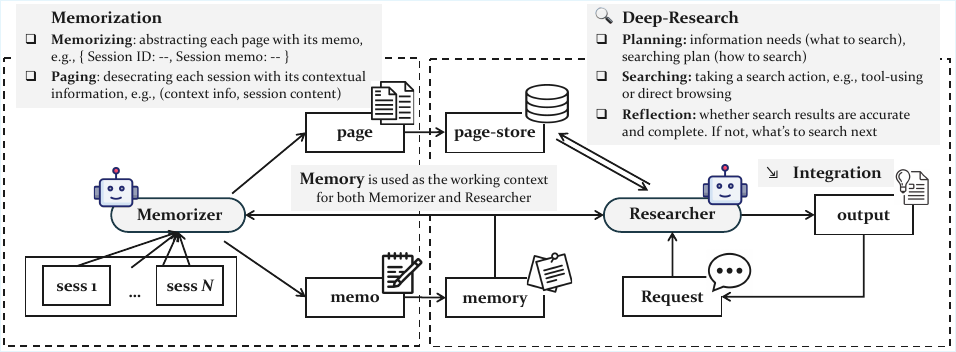
During the offline stage, the memorizer performs two key operations for each incoming session si. First, it executes a memorizing step, which generates a concise and well-structured memo μi that captures the crucial information of the new session. This memo is produced based on both the current session and the existing memory mi, and the memory is incrementally updated by adding the new memo to form mi+1. Second, the memorizer performs a paging operation, which creates a complete page for the session. This process begins by generating a header hi that contains essential contextual information from the preceding trajectory. The header is then used to decorate the session content, forming a new page that is appended to the page-store p. This two-step process ensures that the system maintains both a lightweight, optimized memory and a comprehensive, semantically consistent record of the agent's history.

In the online stage, the researcher is tasked with addressing a client's request. It begins by performing a planning step, which involves chain-of-thought reasoning to analyze the information needs of the request r. Based on this analysis, the researcher generates a concrete search plan using a provided search toolkit T, which includes an embedding model for vector search, a BM25 retriever for keyword-based search, and an ID-based retriever for direct page exploration. The planning process is guided by a specific prompt, as illustrated in the figure below, which instructs the model to generate a JSON object specifying the required tools and their parameters.

Upon receiving the search plan, the researcher executes the search actions in parallel, retrieving relevant pages pt from the page-store. It then integrates the information from the retrieved pages with the last integration result I for the request r, updating the integration result. This process is repeated iteratively. After each integration, the researcher performs a reflection step to determine if the information needed to answer the request has been fully collected. This is done using a binary indicator y. If the reflection indicates that information is still missing (y=No), the researcher generates a new, more focused request r′ to drive another round of deep research. If the information is deemed complete (y=Yes), the research process concludes, and the final integration result is returned as the optimized context. The reflection process is guided by a prompt that instructs the model to identify missing information and generate targeted follow-up retrieval questions.

Experiment
- Evaluated GAM against memory-free methods (Long-LLM, RAG) and memory-based baselines (e.g., Mem0, LightMem) using LoCoMo, HotpotQA, RULER, and NarrativeQA benchmarks.
- GAM consistently outperformed all baselines across every dataset, notably achieving over 90% accuracy on RULER multi-hop tracing tasks where other methods failed.
- Demonstrated robustness to varying context lengths, maintaining high performance on HotpotQA contexts ranging from 56K to 448K tokens.
- Model scaling analysis indicated that larger backbone models improve results, with the research module showing significantly higher sensitivity to model size than the memorization module.
- Ablation studies confirmed that combining search tools (Page-id, Embedding, BM25) yields the best results and that removing the memory module causes substantial performance degradation.
- Increasing test-time computation, specifically through higher reflection depth and more retrieved pages, resulted in steady performance gains.
- Efficiency evaluations showed GAM incurs time costs comparable to Mem0 and MemoryOS while delivering superior cost-effectiveness.
The authors use GAM to achieve the best performance across all benchmarks, consistently outperforming both memory-free and memory-based baselines on LoCoMo, HotpotQA, RULER, and NarrativeQA. Results show that GAM significantly improves over existing methods, particularly in complex tasks requiring multi-hop reasoning and long-context understanding, while maintaining competitive efficiency.
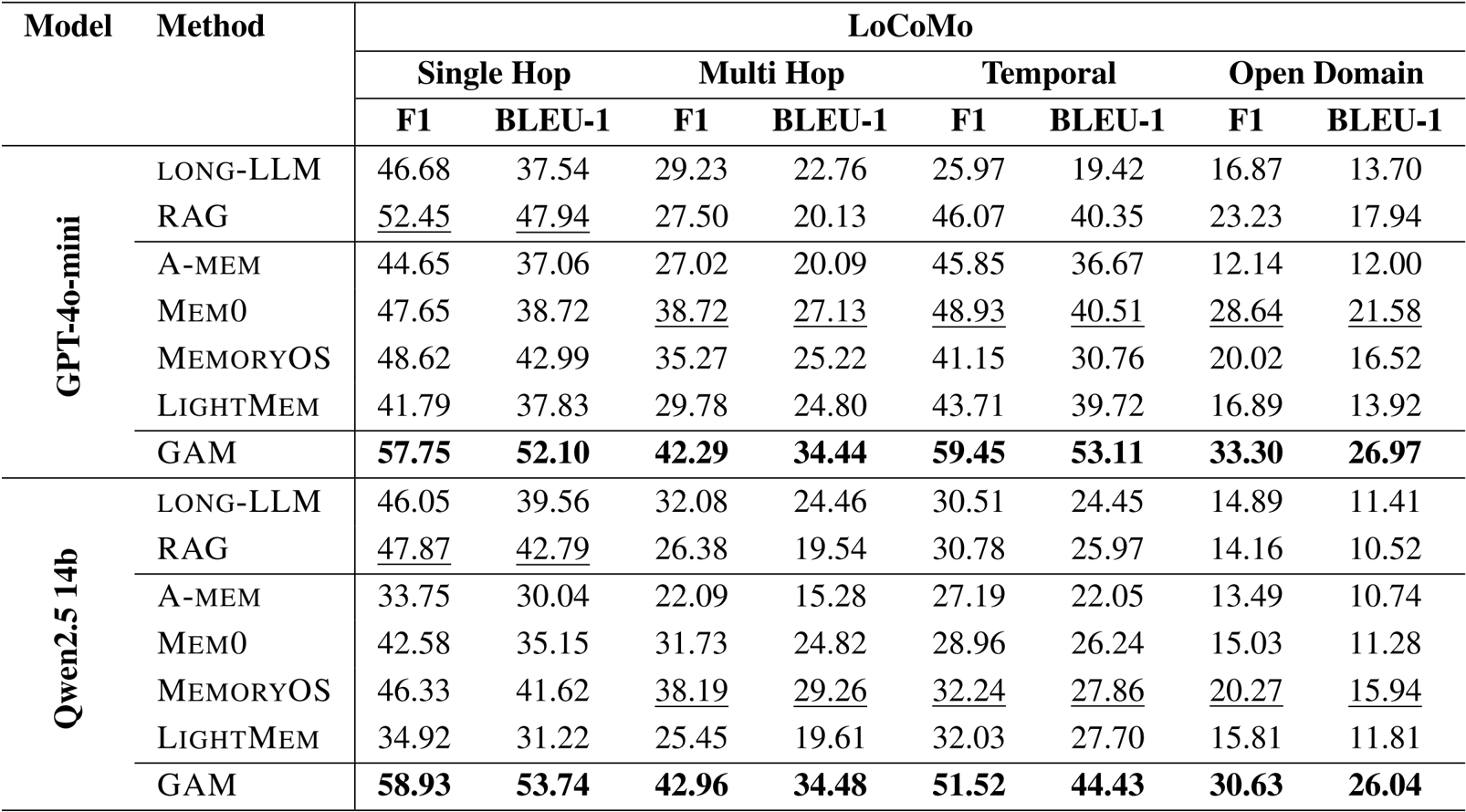
The authors use GAM to achieve state-of-the-art performance across multiple long-context benchmarks, consistently outperforming both memory-free and memory-based baselines. Results show that GAM significantly improves accuracy on complex tasks requiring multi-hop reasoning and retrieval, particularly on HotpotQA and RULER, where it achieves over 90% accuracy on multi-hop tracing tasks, while also maintaining stable performance across varying context lengths.
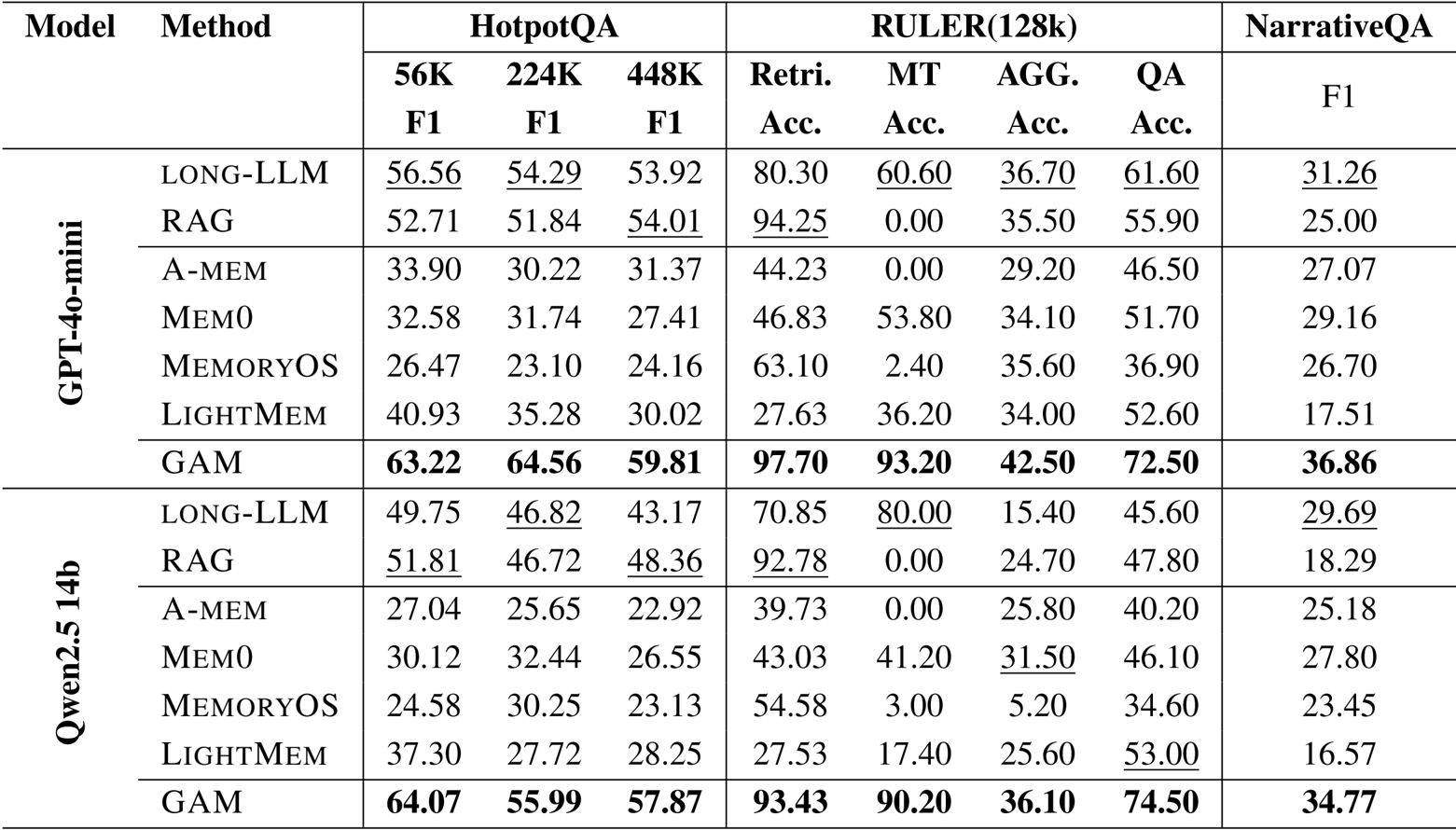
The authors use GAM with different LLM backbones to evaluate its performance on HotpotQA and NarrativeQA, showing that larger models generally improve results. GAM achieves the highest average F1 score with GPT-4o-mini, outperforming all Qwen2.5 variants, and demonstrates consistent gains as model size increases, particularly on longer contexts.
The authors use GAM with different LLM backbones to evaluate the impact of model size on performance. Results show that larger models consistently improve performance, with GPT-4o-mini achieving the highest average F1 score of 55.45, while the smallest Qwen2.5-0.5B model achieves the lowest at 9.08.
Results show that GAM achieves the highest performance across all benchmarks, with its effectiveness enhanced by combining multiple search tools and both memory and research modules. The ablation study indicates that using the full system with all tools and modules yields the best results, while removing either component significantly reduces performance.