Command Palette
Search for a command to run...
Extraktion interaktionsbewusster monosemantischer Konzepte in Empfehlungssystemen
Extraktion interaktionsbewusster monosemantischer Konzepte in Empfehlungssystemen
Dor Arviv Yehonatan Elisha Oren Barkan Noam Koenigstein
Zusammenfassung
Hier ist die Übersetzung des Textes ins Deutsche unter Berücksichtigung des fachsprachlichen und akademischen Stils:Wir stellen eine Methode zur Extraktion monosemantischer Neuronen aus Nutzer- und Item-Embeddings in Empfehlungssystemen vor. Diese Neuronen werden als latente Dimensionen definiert, die mit kohärenten und interpretierbaren Konzepten korrespondieren. Unser Ansatz verwendet einen Sparse Autoencoder (SAE), um semantische Strukturen innerhalb vortrainierter Repräsentationen offenzulegen. Im Gegensatz zu Arbeiten im Bereich der Sprachmodelle muss die Monosemantizität in Empfehlungssystemen die Interaktionen zwischen getrennten Nutzer- und Item-Embeddings bewahren. Um dies zu erreichen, führen wir ein vorhersagebasiertes Trainingsziel (Prediction Aware Training Objective) ein, das mittels Backpropagation ein eingefrorenes Empfehlungssystem durchläuft und die erlernte latente Struktur an den Vorhersagen des Modells zur Nutzer-Item-Affinität ausrichtet. Die resultierenden Neuronen erfassen Eigenschaften wie Genre, Popularität sowie zeitliche Trends und unterstützen Post-hoc-Steuerungsoperationen, einschließlich gezielter Filterung und der Promotion von Inhalten, ohne das Basismodell zu modifizieren. Unsere Methode ist über verschiedene Empfehlungsmodelle und Datensätze hinweg generalisierbar und stellt ein praktisches Werkzeug für eine interpretierbare und steuerbare Personalisierung bereit. Code und Evaluierungsressourcen sind unter https://github.com/DeltaLabTLV/Monosemanticity4Rec verfügbar.
Summarization
Researchers from Tel Aviv University and The Open University, Israel, introduce a method employing Sparse Autoencoders with a novel prediction-aware training objective to extract interpretable monosemantic neurons from recommender system embeddings, enabling precise post hoc control operations such as targeted filtering and content promotion without modifying the base model.
Introduction
Modern recommender systems rely on latent embeddings to generate personalized suggestions at scale, but these representations often lack semantic meaning, making the models opaque and difficult to audit for fairness or reliability. While Sparse Autoencoders (SAEs) have successfully extracted interpretable features from Large Language Models, existing methods fail to capture the distinct user-item interaction logic fundamental to recommendation architectures. The authors address this by introducing a novel SAE framework specifically designed to extract "monosemantic neurons" from recommender embeddings, revealing interpretable concepts like genre and popularity within the latent space.
Key innovations in this approach include:
- Prediction-aware reconstruction loss: Unlike standard geometric reconstruction, this mechanism backpropagates gradients through the frozen recommender to ensure the extracted features preserve actual recommendation behavior and affinity patterns.
- KL-divergence regularization: The framework replaces the Top-K sparsity objective common in LLM research with KL-divergence, which improves stability and prevents the issue of dead neurons during training.
- Intervention capabilities: The extracted neurons enable precise, post-hoc control over model output, allowing developers to suppress specific content types or boost target items without retraining the base model.
Method
The authors leverage a sparse autoencoder (SAE) framework designed to extract monosemantic concepts from user and item embeddings within a two-tower recommender architecture. The overall system operates by first encoding user and item inputs into embeddings through independent encoders, followed by a scoring function that predicts user-item affinity. The SAE is applied post hoc to these embeddings, encoding them into a sparse latent representation and reconstructing the original embeddings. The framework incorporates a Matryoshka SAE structure, which trains multiple nested autoencoders with increasing dictionary sizes, enabling a hierarchical representation where early latent dimensions capture general features and later ones specialize in finer-grained concepts.
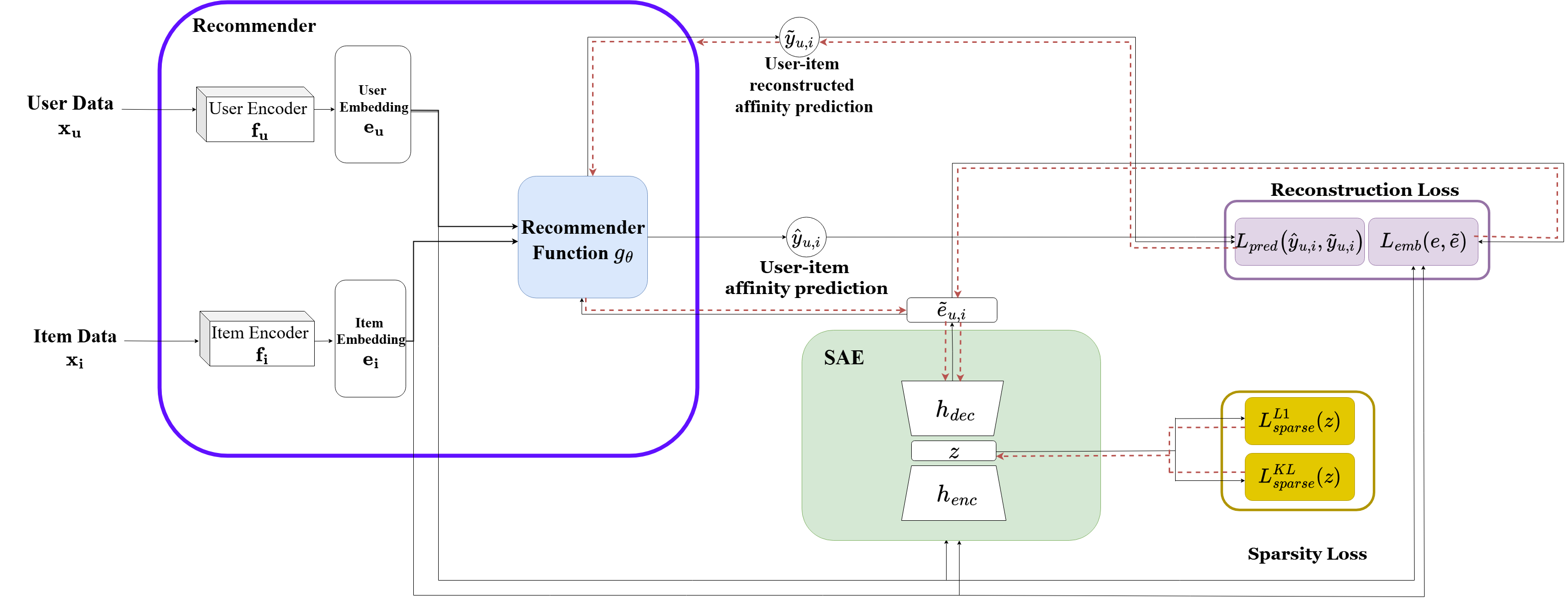
The SAE is trained with a total loss composed of reconstruction and sparsity objectives. The reconstruction loss includes two components: an embedding-level loss that ensures geometric fidelity between the original and reconstructed embeddings, and a novel prediction-level loss tailored for recommender systems. The prediction-level loss measures the mean squared difference between the original affinity prediction and the prediction computed using the reconstructed embeddings, with the scoring function kept frozen during training. This term encourages the SAE to preserve interaction semantics and ranking consistency, which are critical for recommendation quality. The final reconstruction loss is a weighted sum of the embedding-level and prediction-level losses. The sparsity loss combines ℓ1 regularization and a KL divergence penalty on the activation rates of the latent neurons, promoting compact and disentangled representations. The training procedure involves sampling user-item pairs, computing the total loss, and backpropagating gradients through the frozen recommender to align the latent representation with the recommender’s behavioral outputs.
Experiment
- Experiments evaluated Matrix Factorization and Neural Collaborative Filtering models on MovieLens 1M and Last.FM datasets to assess the interpretability of Sparse Autoencoders.
- Qualitative analysis confirmed that monosemantic neurons emerge naturally without supervision, effectively encoding concepts such as specific genres, stylistic eras, and item popularity.
- Quantitative assessments using a semantic purity metric demonstrated high precision; notably, Matrix Factorization neurons for Comedy and Horror achieved 100% purity across all top K thresholds, with near perfect alignment for music genres like Country and Metal.
- Ablation studies revealed that increasing the prediction level loss weight improves recommendation fidelity, measured by Rank Biased Overlap and Kendall Tau, though optimal monosemanticity requires balancing this weight against bottleneck sparsity.
- Intervention experiments validated the ability to modify model behavior post hoc, such as successfully promoting specific artists to users with unrelated preferences by adjusting latent neuron activations.
- Hierarchical analysis using Matryoshka SAEs showed that early neurons capture broad mainstream preferences while later neurons specialize in niche micro genres, a pattern particularly evident in the Last.FM dataset.
Results show that monosemantic neurons extracted from recommender models achieve high semantic purity for genre concepts, with many achieving 100% purity at K=10 for both MF and NCF on MovieLens. The table also reveals that a "popularity neuron" consistently activates for high-ranking items, indicating a latent dimension capturing mainstream appeal across both datasets.

Results show that monosemantic neurons extracted from recommender models achieve high semantic purity for music genres such as Electronic, Metal, and Folk, with purity values often reaching 1.00 at K=10. The table also reveals that the popularity neuron consistently activates for high-ranking items across both datasets, indicating a strong bias toward widely consumed content.
