Command Palette
Search for a command to run...
AICC: HTML feiner parsen, Modelle optimieren – Ein 7,3T AI-Ready-Korpus, erstellt durch einen modellbasierten HTML-Parser
AICC: HTML feiner parsen, Modelle optimieren – Ein 7,3T AI-Ready-Korpus, erstellt durch einen modellbasierten HTML-Parser
Zusammenfassung
Hier ist die Übersetzung des Textes ins Deutsche, unter Berücksichtigung Ihrer Anforderungen an Fachsprache, Genauigkeit und Stil:Während die Qualität von Webdaten für große Sprachmodelle (Large Language Models) von entscheidender Bedeutung ist, konzentrieren sich die meisten Kuratierungsbemühungen auf Filterung und Deduplizierung und behandeln die Extraktion von HTML zu Text als feststehenden Vorverarbeitungsschritt. Bestehende Web-Korpora stützen sich auf heuristikbasierte Extraktoren wie Trafilatura, die jedoch Schwierigkeiten haben, die Dokumentenstruktur zu bewahren, und häufig strukturierte Elemente wie Formeln, Code und Tabellen beschädigen. Wir stellen die Hypothese auf, dass die Verbesserung der Extraktionsqualität ebenso signifikante Auswirkungen auf die Downstream-Leistung haben kann wie aggressive Filterstrategien.Wir stellen MinerU-HTML vor, eine neuartige Extraktionspipeline, die die Inhaltsextraktion als Sequenz-Labeling-Problem (Sequence Labeling) neu formuliert, welches von einem Sprachmodell mit 0,6 Milliarden Parametern gelöst wird. Im Gegensatz zu Heuristiken, die auf Textdichte basieren, nutzt MinerU-HTML semantisches Verständnis und verwendet eine zweistufige Formatierungspipeline, die semantische Elemente explizit kategorisiert, bevor sie in Markdown konvertiert werden. Entscheidend ist, dass dieser modellbasierte Ansatz inhärent skalierbar ist, während heuristische Methoden nur begrenzte Verbesserungspfade bieten.Auf MainWebBench, unserem Benchmark aus 7.887 annotierten Webseiten, erreicht MinerU-HTML einen ROUGE-N F1-Score von 81,8 % im Vergleich zu 63,6 % bei Trafilatura, wobei strukturierte Elemente hervorragend erhalten bleiben (90,9 % bei Codeblöcken, 94,0 % bei Formeln). Unter Verwendung von MinerU-HTML erstellen wir AICC (AI-ready Common Crawl), einen mehrsprachigen Korpus mit 7,3 Billionen Token aus zwei Common-Crawl-Snapshots. In kontrollierten Pretraining-Experimenten, bei denen AICC und der mittels Trafilatura extrahierte TfCC einer identischen Filterung unterzogen werden, erreichen die auf AICC trainierten Modelle (62 Mrd. Token) eine durchschnittliche Genauigkeit von 50,8 % über 13 Benchmarks hinweg. Damit übertreffen sie TfCC um 1,08 Prozentpunkte – ein direkter Beweis dafür, dass die Extraktionsqualität die Modellfähigkeiten signifikant beeinflusst. AICC lässt zudem RefinedWeb und FineWeb in wichtigen Benchmarks hinter sich. Wir veröffentlichen MainWebBench, MinerU-HTML und AICC und demonstrieren damit, dass die HTML-Extraktion eine kritische, oft unterschätzte Komponente bei der Erstellung von Web-Korpora ist.
Summarization
Researchers from Shanghai Artificial Intelligence Laboratory propose MinerU-HTML, which treats HTML extraction as a sequence labeling problem via a 0.6B-parameter model to better preserve structure, and use it to build AICC, a 7.3-trillion token corpus that outperforms existing heuristic-based datasets in large language model pretraining benchmarks.
Introduction
Large Language Models (LLMs) rely heavily on massive web datasets like Common Crawl, where the quality of data curation is a primary driver of performance. While recent efforts have optimized filtering and deduplication, the foundational step of converting raw HTML into structured text is often treated as a fixed preprocessing task, despite being a critical bottleneck for data fidelity.
Current extraction tools depend on rigid heuristics and hand-crafted rules that struggle with the visual complexity of modern web pages. These methods frequently fail to distinguish main content from boilerplate elements like ads and navigation menus. Furthermore, they often corrupt or strip away structured data such as mathematical formulas, code blocks, and tables, resulting in a significant loss of semantic context required for technical training.
The authors address this oversight by introducing AICC (AI-ready Common Crawl), a pretraining corpus generated via a novel extraction pipeline called MinerU-HTML. Rather than relying on static rules, this system reformulates content extraction as a sequence labeling problem solved by a compact language model, ensuring that the structural and narrative coherence of the original web content is preserved.
Key innovations and advantages include:
- Model-Based Extraction: The system utilizes a 0.6B-parameter model to understand semantic context, allowing it to accurately separate main content from noise without relying on brittle text density heuristics.
- High-Fidelity Structure Preservation: The pipeline significantly outperforms existing tools in retaining complex elements, achieving high edit similarity scores for code blocks and mathematical formulas that are often lost during standard extraction.
- Superior Downstream Performance: Models pretrained on the AICC corpus demonstrate higher accuracy across diverse benchmarks compared to those trained on leading datasets like FineWeb and RefinedWeb, proving that extraction quality directly impacts model capabilities.
Dataset
The authors construct three distinct data resources to train the model, generate a large-scale corpus, and benchmark performance.
-
Training Dataset
- Composition: 870,945 annotated samples designed to capture diverse web layouts and formats.
- Sourcing: Derived from Common Crawl, the authors initially clustered pages based on DOM tree features to identify 40 million layout-distinct candidates.
- Processing: This pool was filtered to a balanced subset of 1 million pages covering multiple languages. Final block-level annotations were generated using a simplification algorithm combined with Large Language Model (LLM) labeling.
-
AICC (AI-Centric Corpus)
- Composition: A large-scale multilingual web corpus containing 372 billion tokens.
- Sourcing: Extracted from two Common Crawl snapshots (CC-2023-06 and CC-2023-14) using the MinerU-HTML tool.
- Filtering: The pipeline applies exact deduplication (SHA-256), FastText language identification, Gopher-based quality heuristics, safety filtering via blocklists, and fuzzy deduplication using MinHash.
-
MainWebBench (Evaluation Benchmark)
- Composition: 7,887 carefully annotated web pages containing raw HTML, ground-truth DOM subtrees, and Markdown representations.
- Sourcing: Uses a hybrid strategy where 90% of pages are sampled from Common Crawl to cover long-tail content, and 10% are drawn from high-traffic websites (Chinaz Alexa) to represent professionally designed pages.
- WebMainBench-Structured Subset: A focused collection of 545 pages selected from the main benchmark. These pages specifically contain high densities of mathematical formulas, code blocks, and tables to evaluate the preservation of structured elements.
-
Annotation and Metadata Strategy
- Annotation Principles: Human annotators followed a three-stage review process based on "Contextual Integrity" (including essential context like abstracts) and "Human-Generated Content" (excluding auto-generated metadata).
- Metadata Construction: The benchmark includes rich metadata such as language and style classifications generated by GPT-5.
- Difficulty Scoring: The authors calculated a quantitative "Difficulty Level" for each page based on DOM structural complexity, text distribution sparsity, content-type diversity, and link density.
Method
The authors leverage a two-stage pipeline, MinerU-HTML, to extract high-quality content from raw HTML and convert it into AI-ready formats. The first stage focuses on extracting a cleaned subset of the original document, termed Main-HTML, which contains only content-bearing elements. The second stage transforms this Main-HTML into structured, AI-ready formats such as Markdown for downstream language model training.
The core of the first stage is a three-stage pipeline for Main-HTML extraction, designed to address the computational burden of processing lengthy HTML and to ensure faithful content extraction without hallucination. As shown in the figure below, the pipeline begins with pre-processing, where the input HTML is partitioned into semantic blocks, generating two synchronized representations: Simplified HTML, which strips away rendering-oriented markup to create a compact input for the language model, and Mapping HTML, which preserves the original block structure to enable faithful reconstruction. 
The pre-processing stage applies four sequential transformations to reduce sequence length while preserving semantic information. These include non-content tag removal (e.g., <style>, <script>), attribute simplification (retaining only class and id), block-level chunking at elements that induce line breaks during rendering, and partial content truncation for excessively long blocks. The output of this stage is a sequence of simplified blocks, denoted as x=[x1,x2,…,xn], and a Mapping HTML that maintains the original DOM structure.
In the classification stage, the pipeline employs MinerU-HTML-Classifier, a compact 0.6B-parameter language model, to process the Simplified HTML and classify each block as either main content or boilerplate. This task is formulated as a sequence labeling problem, where the model maps the input sequence X=[x1,x2,…,xn] to a predicted label sequence Ypred=fθ(X). To ensure valid output formatting and eliminate hallucination, a custom logits processor implements constrained decoding. This processor acts as a deterministic finite state machine, enforcing a strict JSON-like output format and restricting the model's vocabulary to only two tokens: "main" and "other", thereby guaranteeing syntactically valid output.
The final stage is post-processing, where the predicted labels are projected back onto the Mapping HTML. Non-content blocks are pruned, and the remaining content-bearing blocks are assembled into the final Main-HTML, which constitutes a valid subtree of the original DOM.
To scale this approach to the web-scale Common Crawl, the authors introduce a template-aware optimization strategy. This strategy exploits the structural regularity of web pages, clustering pages generated from similar templates. For each cluster, a representative page is selected, and the full three-stage pipeline is executed. The model's classification decisions are then analyzed to derive generalized XPath or CSS selectors, which are propagated to all other pages in the cluster using efficient CPU-based processing. This approach dramatically reduces the number of pages requiring GPU-based language model inference, enabling web-scale processing while preserving the quality of the core extraction pipeline.
The second stage of the pipeline transforms the extracted Main-HTML into AI-ready formats. This is achieved through a two-stage conversion strategy. First, Main-HTML is parsed into a structured content list, a JSON-based representation that explicitly categorizes each semantic unit by type (e.g., title, paragraph, code block, table, formula). This intermediate representation enables flexible filtering and format-specific rendering. Second, the content list is converted into the target format, with Markdown being the primary output for language model training. The conversion process iterates over the content list elements and applies type-specific rendering rules to map each semantic type to its corresponding Markdown syntax.
Experiment
- Main Content Extraction: Evaluated using ROUGE-N F1 on the MainWebBench dataset. MinerU-HTML achieved a state-of-the-art score of 0.8182, significantly surpassing the best baseline, Trafilatura (0.6358), with notable gains in conversational content, tables, and mathematical equations.
- Structured Element Preservation: Assessed fidelity for code, formulas, and tables using edit similarity and TEDS metrics. The method demonstrated superior performance, achieving 0.9093 for code blocks (vs. 0.1305 for Trafilatura), 0.9399 for mathematical formulas, and 0.7388 for table structure.
- Generalization Capabilities: Tested on the Web Content Extraction Benchmark (WCEB) to verify robustness across diverse sources. MinerU-HTML attained an overall score of 0.8002, outperforming the strongest baseline (0.7833).
- Efficiency Analysis: Validated the pre-processing pipeline's impact on computational feasibility. The approach reduced input tokens by approximately 87% (from 44,706 to 5,735) compared to raw HTML processing, enabling efficient inference.
- Quality Assessment: Conducted a pairwise evaluation on 10,000 documents using an LLM-as-a-judge protocol. MinerU-HTML extractions were preferred 72.0% of the time over Trafilatura extractions, indicating higher retention of valuable main content.
- Downstream Pretraining Performance: Compared 1.5B parameter models trained on 62B tokens from various corpora. The model trained on MinerU-HTML data (AICC) achieved 50.82% average accuracy across 13 benchmarks, outperforming FineWeb (49.61%), RefinedWeb (49.13%), and TfCC (49.74%).
The authors use ROUGE-N F1 to evaluate main content extraction, and results show that MinerU-HTML achieves a significant improvement over baseline methods, with an overall score of 0.8182 compared to 0.6233 for Resiliparse and 0.6237 for Trafilatura. MinerU-HTML demonstrates particularly strong performance on challenging content types, including conversational content, tables, and mathematical equations, where it outperforms the baselines by substantial margins.

Results show that MinerU-HTML significantly outperforms both Trafilatura and Resiliparse in preserving structured elements, achieving edit similarity scores of 0.9093 for code blocks and 0.9399 for mathematical formulas, while also attaining a TEDS score of 0.7388 for table structure preservation. These results demonstrate that MinerU-HTML effectively maintains the integrity of complex content structures that are often lost in heuristic-based extraction methods.
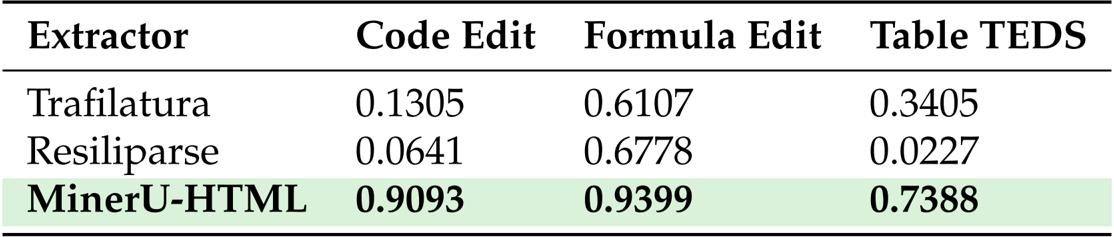
The authors use ROUGE-N F1 to evaluate main content extraction, with MinerU-HTML achieving an overall score of 0.8002, outperforming Trafilatura (0.7833) and Resiliparse (0.7225). Results show that MinerU-HTML maintains strong performance across difficulty levels, particularly excelling on simple and mid-difficulty content, where it achieves scores of 0.8293 and 0.8005 respectively.