Command Palette
Search for a command to run...
Depth Anything 3: Wiederherstellung des visuellen Raums aus beliebigen Ansichten
Depth Anything 3: Wiederherstellung des visuellen Raums aus beliebigen Ansichten
Haotong Lin Sili Chen Junhao Liew Donny Y. Chen Zhenyu Li Guang Shi Jiashi Feng Bingyi Kang
Zusammenfassung
Wir präsentieren Depth Anything 3 (DA3), ein Modell, das räumlich konsistente Geometrie aus einer beliebigen Anzahl visueller Eingaben vorhersagt, unabhängig davon, ob die Kameraposen bekannt sind oder nicht. In der Bemühung um ein minimales Modell ergeben sich zwei zentrale Erkenntnisse: Ein einziger, einfacher Transformer (z. B. ein vanilla DINO-Encoder) genügt als Backbone ohne architektonische Spezialisierung, und ein einziges Tiefen-Strahl-Vorhersageziel macht eine komplizierte Multi-Task-Lernstrategie überflüssig. Durch unser Lehrer-Schüler-Trainingsparadigma erreicht das Modell ein Niveau an Detailgenauigkeit und Generalisierbarkeit, das dem von Depth Anything 2 (DA2) entspricht. Wir etablieren eine neue Benchmark für visuelle Geometrie, die die Schätzung von Kameraposen, die beliebige Ansichtsgeometrie und die visuelle Darstellung abdeckt. Auf dieser Benchmark erreicht DA3 eine neue State-of-the-Art-Leistung in allen Aufgaben und übertrifft die vorherige SOTA-Modellierung VGGT im Durchschnitt um 44,3 % bei der Kameraposenpräzision und um 25,1 % bei der geometrischen Genauigkeit. Zudem übertrifft DA3 DA2 bei der monokularen Tiefenschätzung. Alle Modelle wurden ausschließlich auf öffentlichen akademischen Datensätzen trainiert.
One-sentence Summary
The authors, affiliated with ByteDance Seed, propose Depth Anything 3 (DA3), a minimal yet powerful transformer-based model that predicts consistent geometry from arbitrary inputs using a single depth-ray prediction target, eliminating the need for specialized architectures or multi-task learning; it achieves state-of-the-art performance on a new benchmark for camera pose estimation, any-view geometry, and rendering, outperforming prior methods like VGGT and DA2 by significant margins across all tasks.
Key Contributions
- Depth Anything 3 introduces a minimal modeling approach for visual geometry reconstruction, demonstrating that a single plain transformer backbone and a unified depth-ray prediction target are sufficient to handle arbitrary numbers of input images—either with or without known camera poses—without requiring task-specific architectural specialization.
- The model leverages a teacher-student training paradigm with pseudo-labeling to unify diverse datasets, enabling high-fidelity depth and pose estimation across real-world and synthetic data, and achieves state-of-the-art performance on a new comprehensive visual geometry benchmark, surpassing prior SOTA VGGT by 35.7% in pose accuracy and 23.6% in geometric accuracy on average.
- It outperforms Depth Anything 2 in monocular depth estimation and enables superior feed-forward 3D Gaussian splatting, showing that enhanced geometric reconstruction directly improves novel view synthesis, establishing it as a strong foundation model for downstream 3D vision tasks.
Introduction
The authors tackle the challenge of unified 3D visual geometry reconstruction from arbitrary input views—single images, multiple views, or video—without relying on task-specific architectures. Prior work in multi-view geometry and monocular depth estimation has typically employed complex, specialized models that struggle with scalability, generalization, and variable input counts, while recent unified approaches often require intricate designs and joint training from scratch, limiting their ability to leverage large-scale pretrained vision models. To address these limitations, the authors introduce Depth Anything 3, a minimal yet powerful framework built around a single plain vision transformer (e.g., DINOv2) with no architectural modifications. The model jointly predicts depth and ray maps for any number of input images using a novel input-adaptive cross-view self-attention mechanism and a dual DPT head, enabling efficient cross-view reasoning and consistent geometric reconstruction. Training is conducted via a teacher-student paradigm, where a high-quality monocular teacher model generates pseudo-depth labels for diverse real-world data, ensuring geometric fidelity even with noisy or sparse ground truth. The approach achieves state-of-the-art performance on a new comprehensive visual geometry benchmark across 18 of 20 settings and enables superior feed-forward 3D Gaussian splatting, demonstrating that a simple, scalable foundation model can outperform specialized systems in downstream 3D vision tasks.
Dataset
-
The dataset used for training consists of multiple sources: DL3DV, TartanAir, IRS, UnrealStereo4K, GTA-SfM, Kenburns, PointOdyssey, TRELLIS, and OmniObject3D. These are combined to train a teacher model and a feed-forward 3DGS model, with strict scene-level separation between training and testing to prevent data leakage.
-
For training the NVS model, 10,015 scenes from DL3DV are used, with 140 benchmark scenes kept entirely disjoint from the training set. The benchmark evaluates on five datasets: HiRoom (30 synthetic indoor scenes), ETH3D (11 high-resolution indoor/outdoor scenes), DTU (22 evaluation scans of 124 objects), 7Scenes (low-resolution, motion-blurred indoor scenes), and ScanNet++ (20 indoor scenes with iPhone LiDAR and laser-scan-derived depth).
-
Each dataset undergoes specific preprocessing: HiRoom, 7Scenes, and ScanNet++ use a depth threshold of 0.05m for F1 metric calculation; ETH3D uses 0.25m. TSDF fusion parameters vary by dataset—voxel sizes range from 0.007m to 0.039m. For evaluation, frames are downsampled in 7Scenes (by factor 11) and ScanNet++ (by factor 5) to reduce computational load.
-
The training process uses a dynamic batch size to maintain consistent token count per step. Image resolution is randomly sampled from eight options, including 504×504 and its aspect ratio variants. The base resolution of 504×504 is divisible by 2, 3, 4, 6, 9, and 14, supporting common photo aspect ratios. For 504×504, the number of views per scene is uniformly sampled between 2 and 18.
-
Training runs for 200k steps on 128 H100 GPUs with an 8k-step warm-up and a peak learning rate of 2×10⁻⁴. Supervision shifts from ground-truth depth to teacher-model labels at step 120k. Pose conditioning is applied randomly with 20% probability during training.
-
Data preprocessing includes filtering invalid or misaligned samples: TartanAir removes the amusement scene and clips depth in specific scenes; IRS uses Canny edge-based alignment checks to filter misaligned image-depth pairs; UnrealStereo4K removes problematic scenes and frames with missing depth; GTA-SfM and OmniObject3D clip maximum depth values; PointOdyssey removes two scenes with incorrect ground depth; TRELLIS excludes non-textured files; Kenburns clips depth at 50,000.
-
For visual rendering quality evaluation, a new NVS benchmark is built from DL3DV (140 scenes), Tanks and Temples (6 scenes), and MegaDepth (19 scenes), each with ~300 sampled frames. Ground-truth poses from COLMAP are used for fair comparison, and metrics include PSNR, SSIM, and LPIPS.
Method
The authors leverage a unified transformer-based architecture for Depth Anything 3 (DA3), designed to predict spatially consistent geometry from an arbitrary number of visual inputs, whether or not camera poses are known. The core of the model is a single transformer backbone, specifically a vanilla DINO encoder, which serves as a universal feature extractor without architectural specialization. This backbone is structured to enable cross-view reasoning through an input-adaptive self-attention mechanism. The transformer is divided into two distinct groups of layers: the first Ls layers perform self-attention within each individual image, while the subsequent Lg layers alternate between cross-view and within-view attention by jointly processing all image tokens through a tensor reordering scheme. This design allows the model to naturally handle both monocular and multi-view inputs without additional computational overhead, as demonstrated in the framework diagram.

To accommodate both posed and unposed inputs, the model incorporates a camera condition injection mechanism. When camera parameters are available, a lightweight MLP projects the camera's field of view, rotation quaternion, and translation into a learnable camera token, which is prepended to the image patch tokens. If camera parameters are absent, a shared, learnable camera token is used instead. These camera tokens are integrated into the transformer's attention mechanism, providing either explicit geometric context or a consistent learned placeholder, thereby enabling the model to adapt to different input conditions.
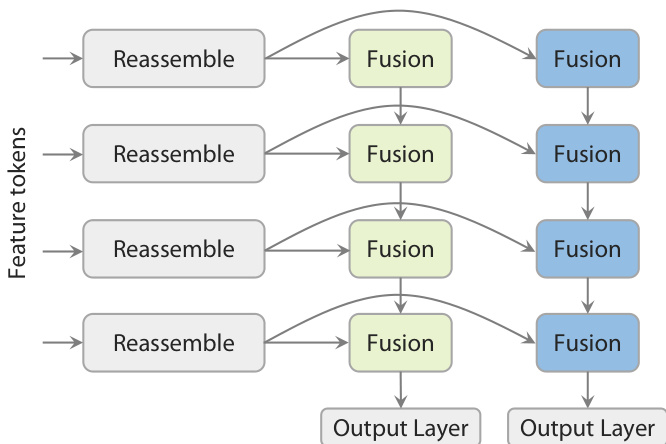
The final prediction stage employs a novel Dual-DPT head, which jointly generates dense depth and ray maps. As shown in the figure below, this head first processes the backbone features through a shared set of reassembly modules. The processed features are then fused using two distinct sets of fusion layers—one for the depth branch and one for the ray branch—before being passed to separate output layers. This architecture ensures that both prediction tasks operate on the same set of processed features, promoting strong interaction between them while avoiding redundant intermediate representations.
The model's training process is based on a teacher-student paradigm to overcome the limitations of noisy and incomplete real-world depth data. A monocular relative depth estimation teacher model is trained exclusively on a large-scale synthetic corpus to generate high-quality pseudo-labels. These pseudo-depth maps are aligned with the available noisy ground truth using a robust RANSAC least squares procedure to ensure scale and shift consistency. The student model, DA3, is trained on real-world data using these aligned pseudo-labels as supervision. The overall training objective is a weighted sum of several terms, including a depth loss, a ray map loss, a point cloud consistency loss, a camera pose loss, and a gradient loss. The depth and ray map predictions are normalized by a common scale factor defined as the mean ℓ2 norm of the valid reprojected point maps to stabilize training. This approach enables the model to achieve high levels of detail and generalization, surpassing prior state-of-the-art methods.
Experiment
- Trained a metric depth estimation model using a teacher model's predictions as supervision, achieving state-of-the-art results on ETH3D (δ₁ = 0.917, AbsRel = 0.104) and SUN-RGBD (AbsRel = 0.105), surpassing UniDepthv2 and other SOTA methods.
- Introduced a visual geometry benchmark evaluating pose accuracy, reconstruction quality, and novel view synthesis, using AUC, Chamfer Distance, F1-score, and rendering fidelity as metrics.
- Demonstrated that the depth-ray representation is sufficient for high-quality geometry prediction, outperforming depth+cam and depth+pcd combinations by up to 100% in Auc3.
- Showed that a single plain Transformer with partial attention alternation outperforms multi-stage VGGT-style architectures, confirming the effectiveness of the proposed design.
- Achieved strong monocular depth performance with the student model, improving over DA2 by over 10% on ETH3D and +5.1% on SINTEL, attributed to enhanced teacher supervision and scaled training data.
- Validated that teacher model supervision significantly improves depth sharpness and fine detail, especially on synthetic and high-structure scenes like HiRoom, despite minor metric gains on NYUv2 and KITTI.
- Achieved top performance in feed-forward novel view synthesis, with DA3-based models outperforming specialized 3DGS frameworks (e.g., pixelSplat, MVsplat) across diverse scenes, demonstrating the power of large-scale pretraining and robust geometry backbones.
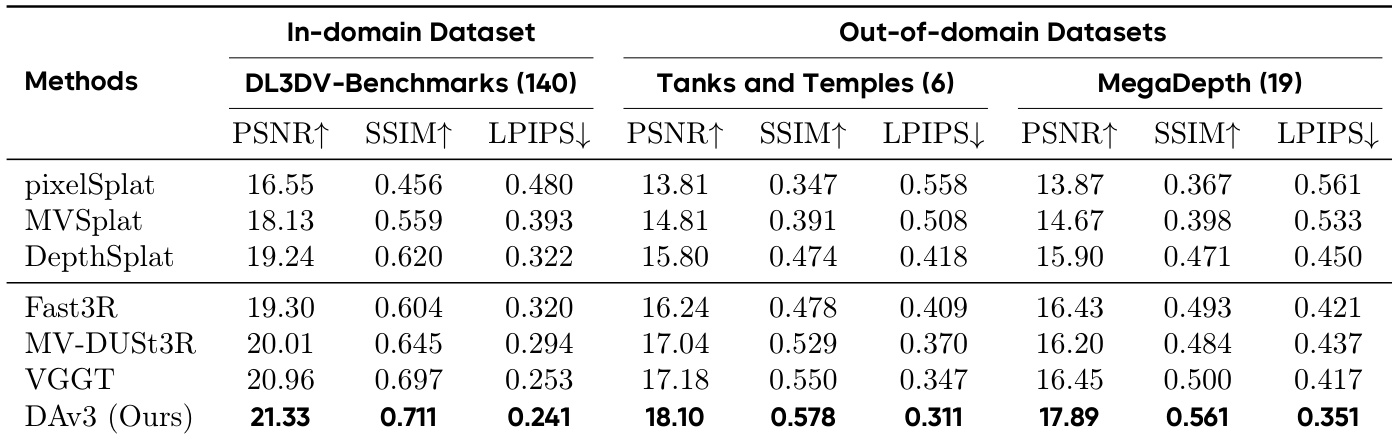
Results show that the proposed DA3 model achieves the best performance across all metrics and datasets, outperforming all baselines in both in-domain and out-of-domain benchmarks. On the DL3DV-Benchmarks, DA3 achieves the highest PSNR, SSIM, and LPIPS scores, and it also leads in all three metrics on Tanks and Temples and MegaDepth, demonstrating superior novel view synthesis quality.
The authors evaluate the impact of different training data and loss configurations on monocular depth estimation. Results show that using V3 data with multi-resolution training (V3 + mr) achieves the best performance across all metrics, with a δ₁ of 0.938, AbsRel of 0.072, and SqRel of 0.452. The full loss, which includes the proposed normal-loss term, further improves performance compared to the MAE-Loss baseline, achieving a δ₁ of 0.919, AbsRel of 0.087, and SqRel of 0.596.

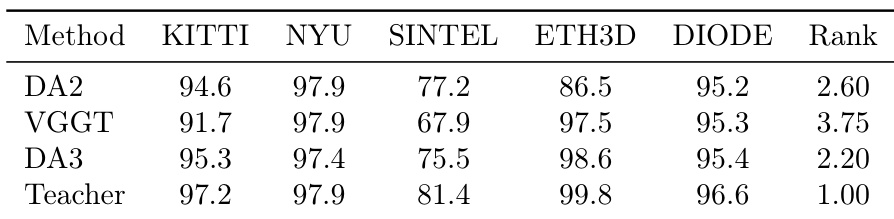
The authors compare their DA3 model with DA2 and VGGT on monocular depth estimation benchmarks, showing that DA3 achieves the best overall performance across all datasets, with a rank of 2.20, outperforming DA2 (rank 2.60) and VGGT (rank 3.75). The teacher model achieves the highest rank of 1.00, indicating superior performance on the evaluated datasets.
The authors compare their monocular student model against DA2 on multiple benchmarks, showing that the new student model outperforms DA2 across all datasets. On ETH3D, the monocular student achieves a significant improvement of over 10% compared to DA2, while also demonstrating strong gains on challenging datasets like Sintel.

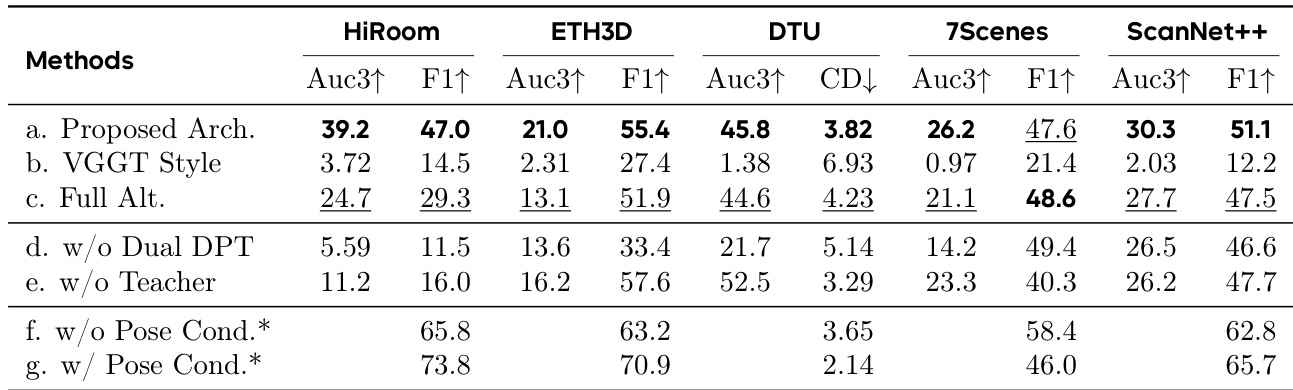
The authors evaluate the impact of different architectural and training components on geometry estimation performance. Results show that the proposed architecture significantly outperforms the VGGT-style and full alternation baselines across all datasets, with the best results achieved by the full model. Removing the dual-DPT head or teacher supervision leads to substantial performance drops, while adding pose conditioning further improves results, especially on datasets like HiRoom and ScanNet++.