Command Palette
Search for a command to run...
VIRES: Video-Instanznachmalen mittels skizzen- und textgesteuerter Generierung
VIRES: Video-Instanznachmalen mittels skizzen- und textgesteuerter Generierung
Shuchen Weng Haojie Zheng Peixuan Zhang Yuchen Hong Han Jiang Si Li Boxin Shi
Zusammenfassung
Wir stellen VIRES vor, eine Video-Instance-Repainting-Methode mit Skizzen- und Textführung, die Video-Instance-Repainting, -Ersetzung, -Generierung und -Entfernung ermöglicht. Bestehende Ansätze leiden unter mangelnder zeitlicher Konsistenz und ungenauer Ausrichtung auf die bereitgestellte Skizzensequenz. VIRES nutzt die generativen Vorwissen von Text-zu-Video-Modellen, um zeitliche Konsistenz zu gewährleisten und visuell ansprechende Ergebnisse zu erzeugen. Wir schlagen den Sequential ControlNet mit standardisierter Selbstskalierung vor, der strukturelle Layouts effektiv extrahiert und hochkontrastige Skizzenmerkmale adaptiv erfasst. Zudem erweitern wir den Diffusions-Transformer-Backbone um einen Skizzen-Attention-Mechanismus, um feinkörnige Skizzen-Semantik zu interpretieren und einzubetten. Ein skizzenbewusster Encoder sorgt dafür, dass die nachbearbeiteten Ergebnisse mit der bereitgestellten Skizzensequenz korrekt ausgerichtet sind. Zusätzlich präsentieren wir das VireSet, eine Datensammlung mit detaillierten Annotationen, die speziell für das Training und die Evaluierung von Video-Instance-Editing-Methoden entwickelt wurde. Experimentelle Ergebnisse belegen die Wirksamkeit von VIRES, das sowohl hinsichtlich visueller Qualität, zeitlicher Konsistenz, Bedingungsalignment als auch menschlicher Bewertungen die derzeit besten Ansätze übertrifft. Projektseite: https://hjzheng.net/projects/VIRES/
One-sentence Summary
The authors from Peking University, OpenBayes, and Beijing University of Posts and Telecommunications propose VIRES, a sketch- and text-guided video instance editing model that achieves high-fidelity repainting, replacement, generation, and removal by integrating a Sequential ControlNet with self-scaling and sketch attention into a diffusion transformer, ensuring temporal consistency and precise condition alignment, outperforming prior methods on the newly introduced VIRESSET dataset.
Key Contributions
- VIRES addresses the challenge of temporal inconsistency and inaccurate sketch alignment in video instance editing by introducing a diffusion transformer (DiT)-based framework that leverages pre-trained text-to-video generative priors for consistent, high-quality video editing with sketch and text guidance.
- The method proposes a Sequential ControlNet with standardized self-scaling to extract structure layouts and adaptively capture high-contrast sketch details, along with sketch attention and a sketch-aware encoder to inject fine-grained sketch semantics and ensure alignment during generation.
- VIRES is evaluated on the newly introduced VIRESSET dataset, which contains 85K training and 1K evaluation videos with LLM-generated text and HED-based sketch sequences, demonstrating superior performance over state-of-the-art methods in visual quality, temporal consistency, condition alignment, and human preference.
Introduction
Video instance editing enables precise, content-aware modifications to specific objects in videos, with applications in filmmaking, content creation, and visual effects. However, prior methods face challenges in maintaining temporal consistency and accurately aligning edits with user-provided guidance—especially when using sketches for fine-grained control. Existing approaches either rely on zero-shot text-to-image models, leading to flickering and inconsistent results, or fine-tune models with limited ability to preserve detailed sketch alignment. The authors introduce VIRES, a diffusion transformer-based framework that leverages the generative priors of text-to-video models to achieve high temporal consistency. They propose a Sequential ControlNet with standardized self-scaling for robust structure extraction, sketch attention to inject fine-grained sketch semantics into the latent space, and a sketch-aware encoder to ensure alignment with multi-level texture features. Additionally, they release VIRESSET, a large-scale dataset with 85K training and 1K evaluation videos annotated with text and sketch sequences, enabling more effective training and evaluation of video instance editing methods.
Dataset
- The dataset, named VIRESSET, is designed for training and evaluating video instance editing methods, addressing limitations in existing datasets such as temporal inconsistencies and visual appearance variations.
- Data is initially sourced from SA-V, a diverse video collection featuring indoor (54%) and outdoor (46%) scenes recorded across 47 countries by various contributors, with original videos averaging 14 seconds in duration and a resolution of 1401 × 1037 pixels.
- Instance masks are originally provided at 6 FPS with manual and automatic annotations, and the authors enhance temporal consistency by using the pre-trained SAM-2 model to generate masks for intermediate frames, increasing the annotation rate to 24 FPS.
- Instances are filtered to include only those covering at least 10% of the frame area and present for a minimum of 51 consecutive frames; from these, 51-frame clips are randomly sampled.
- Each selected instance is cropped with a small margin around its bounding box and resized to 512 × 512 resolution to standardize input for model training.
- Additional annotations are generated: text descriptions for visual appearance are produced using the pre-trained PLLaVa model, and sketch sequences are extracted via HED edge detection to provide structural guidance.
- A quality check is performed by 10 volunteers reviewing 1% of the samples, achieving a 91% acceptance rate.
- The final dataset comprises 85,000 training clips and 1,000 evaluation clips, each consisting of 51 frames at 24 FPS, with corresponding 512 × 512 resolution images, sketch sequences, and text descriptions.
Method
The VIRES framework operates as a conditional video generation system that repainted specific instances within a video clip using sketch and text guidance. The overall pipeline begins with input encoding, where the original video clip x is compressed into a latent representation z via a pre-trained spatial-temporal VAE encoder Ex. Concurrently, the sketch sequence s is processed by the Sequential ControlNet Fs to extract structural layouts, and the text description y is transformed into word embeddings fy using a pre-trained text encoder Fy. These conditioned features are then injected into the denoising network to guide the generation process.
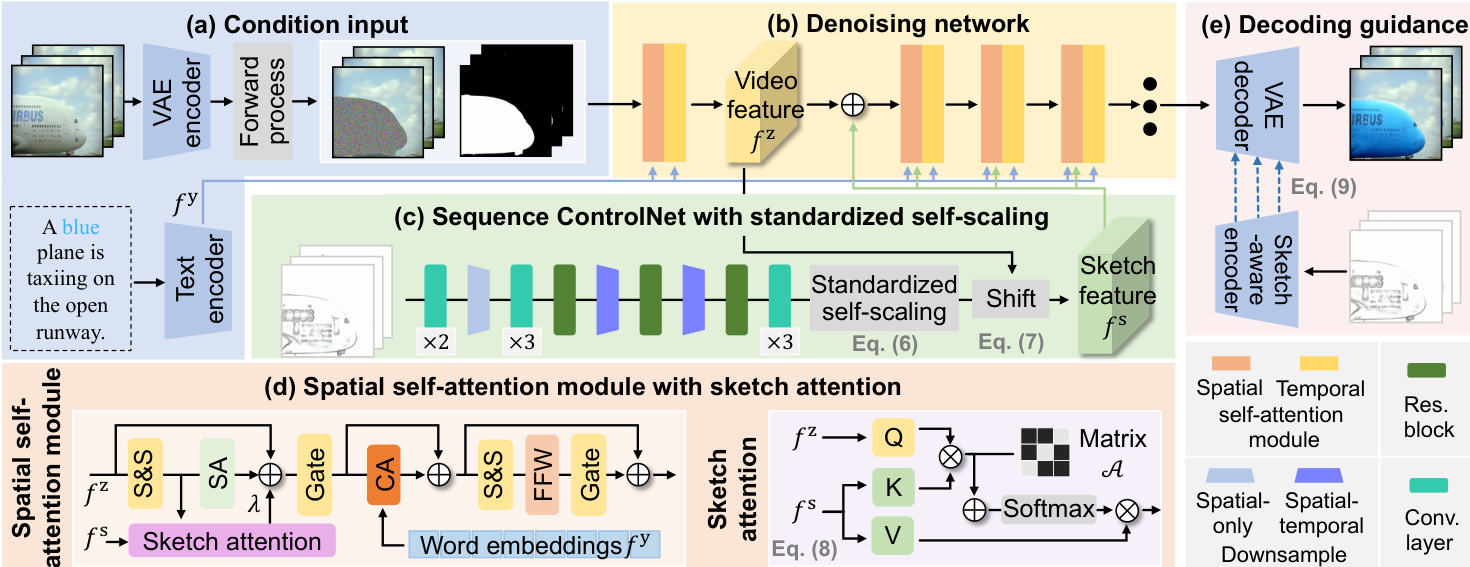
The denoising network is built upon a DiT backbone, which consists of stacked transformer blocks incorporating spatial and temporal self-attention modules to model intra-frame and inter-frame dependencies. The forward diffusion process follows a linear path between the latent code z and Gaussian noise ϵ, defined as z^t=tz+(1−t)ϵ, where t∈[0,1]. To enable instance-specific repainting, a latent masking step is applied: zt=z^t⊙m^+z⊙(1−m^), where m^ is the downsampled instance mask. The reverse diffusion process is governed by an Ordinary Differential Equation (ODE): dz/dt=vθ(zt,t,s,m,y), where vθ is the estimated vector field. The model is trained using a flow matching objective, minimizing the loss Lfm=Et,z,ϵ[∥vt(zt)−vθ(zt,t,s,m,y)∥2], with the target velocity vt=z−ϵ.
The Sequential ControlNet is designed to extract structure layouts from the sketch sequence while ensuring temporal consistency. It employs 3D causal convolutions, residual blocks, and downsampling layers to capture spatial-temporal dependencies. The network progressively increases the number of channels to match the DiT backbone's feature dimensions, with the final layers maintaining a high channel count to preserve structural details. To adaptively capture high-contrast sketch features, the standardized self-scaling module is applied. This process first standardizes the sketch features fs as f^s=((fs−μ(fs))/σ(fs))⊙fs, then aligns their mean with the video features fz via fˉs=f^s−μ(f^s)+μ(fz). This modulation is applied only to the first transformer block of the DiT backbone to reduce computational overhead.
To further inject fine-grained sketch semantics into the latent space, the sketch attention mechanism is integrated into the spatial self-attention module of each transformer block (except the first). This is implemented as a parallel branch that computes attention scores using a predefined binary matrix A to indicate correspondences between the latent code and sketch features. The attention mechanism is defined as fˉz=Softmax((QK⊤+A)/C)V, where Q, K, and V are transformed features from the video and sketch sequences. The output of the sketch attention is scaled by a learnable parameter λ and added to the main attention output.
During the decoding phase, the sketch-aware encoder is introduced to provide multi-level texture features that guide the spatial-temporal VAE decoder. This encoder, which shares the same architecture as the VAE encoder, extracts texture features from the sketch sequence at each downsampling level. These features are then added to the decoder's output at the corresponding level: D(z′,Es(s))i=Es(s)i+D(z′)i. The sketch-aware encoder is trained using a combined loss function Lvae=∑iLsm+λ1L1+λ2Lpc+λ3Lkl, which includes SSIM, L1, perceptual, and KL losses to ensure structural alignment, reconstruction fidelity, sharpness, and regularization.
Experiment
- Trained VIRES with pre-trained spatial-temporal VAE and DiT backbone on 8 H100 GPUs, using a three-stage training process: sketch-aware encoder training (22K steps), Sequential ControlNet and self-scaling training (35K steps), and full model fine-tuning (45K steps) with Adam optimizer and 1×10−5 learning rate.
- Validated on VIRESET and DAVIS datasets, with 50 videos randomly selected from each for evaluation.
- Achieved state-of-the-art performance across five metrics: PSNR, SSIM, Warp Error (WE), Frame Consistency (FC), and Text Consistency (TC), outperforming VideoComposer, Text2Video-Zero, Rerender, VidToMe, and RAVE on both datasets.
- User studies on Amazon Mechanical Turk showed VIRES ranked highest in visual quality and text alignment preference.
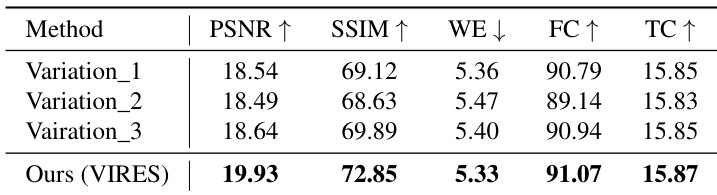
- Ablation studies confirmed the necessity of key components: Standardized Self-Scaling (SSS), Self-Scaling (SS), Sketch Attention (SA), and Sketch-aware Encoder (SE), with removal leading to texture distortion, loss of detail, or misalignment.
- Extended applications include sketch-to-video generation from scratch, sparse sketch guidance (effective with as few as one sketch frame), and long-duration video repainting via iterative frame processing.
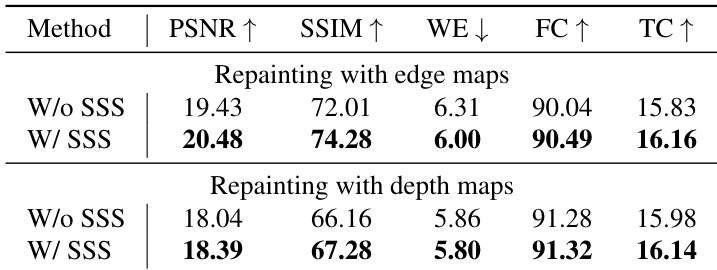
- Demonstrated generalization to edge maps and depth maps: SSS significantly improved performance with edge maps due to high-contrast transitions, but offered marginal gains with smoother depth maps.
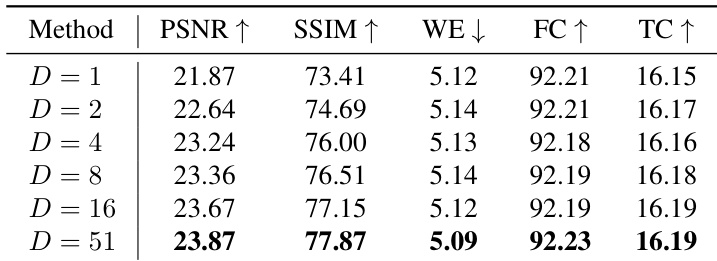
- Sparse sketch guidance with varying interval indices d∈{0,…,4} showed robust performance even with a single sketch frame, maintaining high PSNR, SSIM, and temporal consistency.
Results show that VIRES outperforms state-of-the-art methods across all five quantitative metrics on both VIRESET and DAVIS datasets, achieving the highest scores in visual perceptual quality, structural consistency, motion accuracy, frame consistency, and text alignment. The ablation study demonstrates that removing any of the key components—standardized self-scaling, self-scaling, sketch attention, or sketch-aware encoder—leads to significant performance degradation, highlighting the importance of each module for effective video repainting.
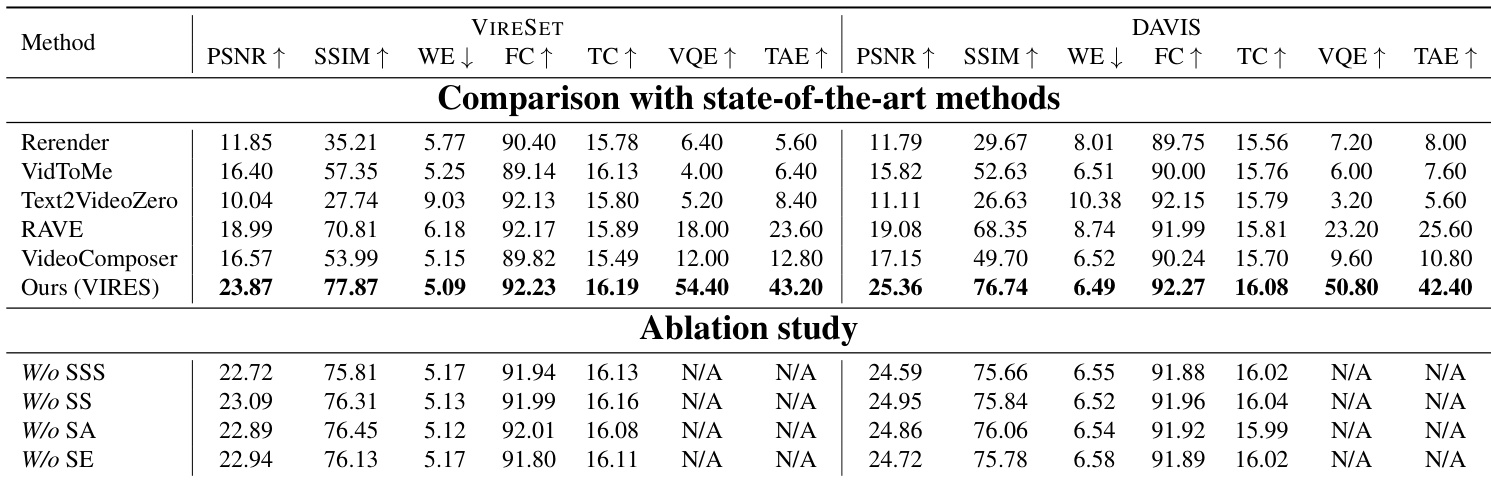
The authors use a spatial-temporal VAE and DiT backbone with pre-trained weights, training the VIRES model in three stages to repaint videos at 512×512 resolution. The model is trained on 8 H100 GPUs using the Adam optimizer with a learning rate of 1×10−5, and the experiment details include the use of a sketch-aware encoder, Sequential ControlNet, and sketch attention to improve video editing performance.
Results show that the standardized self-scaling (SSS) module significantly improves performance in repainting videos with both edge and depth maps. For edge maps, the model with SSS achieves higher PSNR, SSIM, FC, and TC scores compared to the variant without SSS, while for depth maps, the improvement is more modest but still consistent across all metrics.
Results show that VIRES achieves the highest scores across all five metrics compared to the baseline variations, with the best performance in PSNR, SSIM, WE, FC, and TC. The authors use a standardized self-scaling method to extract condition features, and the results demonstrate that this approach significantly improves video editing quality over simpler alternatives.
Results show that VIRES maintains high performance across all metrics even with sparse sketch guidance, achieving near-optimal results with as few as one sketch frame. The model demonstrates robust temporal consistency and visual quality, with PSNR, SSIM, and FC scores remaining stable or improving as the number of sketch frames increases.