Command Palette
Search for a command to run...
Long-VITA: Eine Multimodale Verständnisdemo Mit Millionen Von Token
1. Einführung in das Tutorial

Long-VITA ist ein Forschungsergebnis des Tencent YouTu Lab, der Universität Nanjing und der Universität Xiamen, das im Februar 2025 veröffentlicht wurde und multimodale Daten in großem Umfang mit langen Kontexten verarbeitet. Dieses Modell erzielt auch bei kurzen Kontexten eine hohe Genauigkeit und erweitert die Kontextlänge auf bis zu 1 Million Token, wodurch die effiziente Verarbeitung multimodaler Eingaben wie Text und Bilder ermöglicht wird. Die zugehörige Publikation trägt den Titel „…“.Long-VITA: Skalierung großer multimodaler Modelle auf 1 Million Token mit führender Kurzkontextgenauigkeit".
Dieses Tutorial verwendet eine einzelne RTX 4090 Grafikkarte und setzt ein Long-VITA-16K_HF-Modell ein.
2. Effektbeispiele
Textkonversation
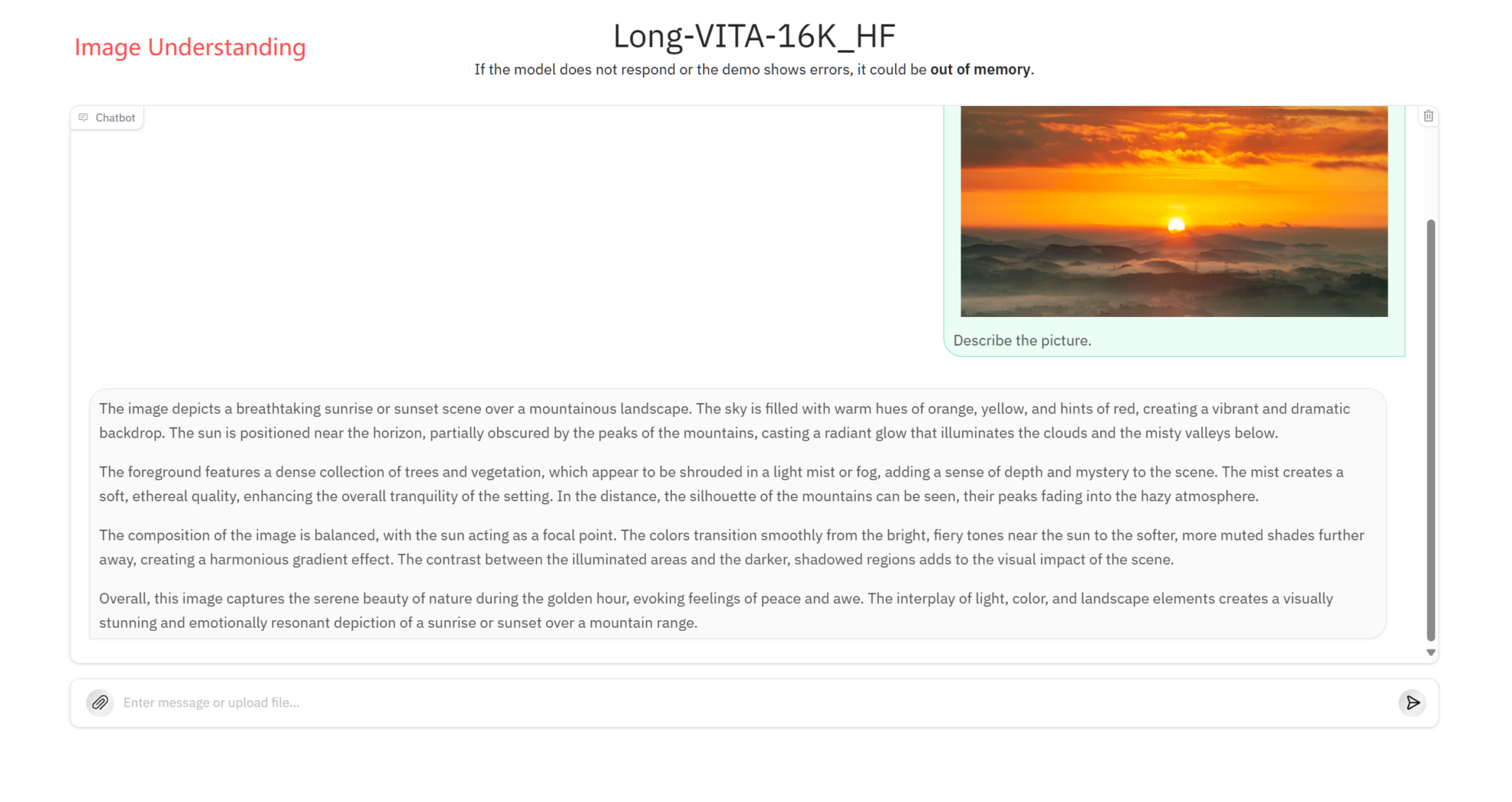
Bildverständnis
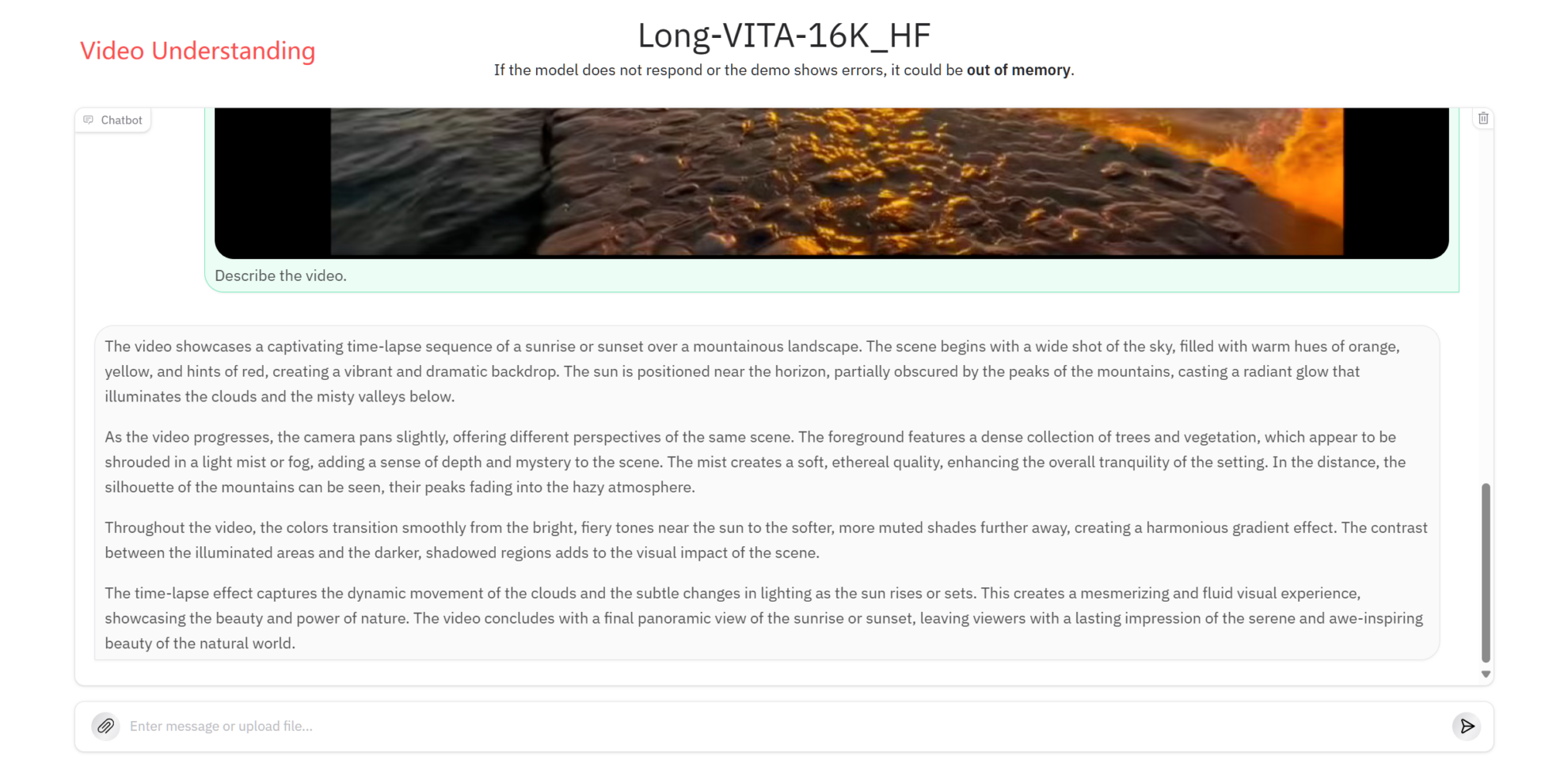
Videoverständnis
3. Bedienungsschritte
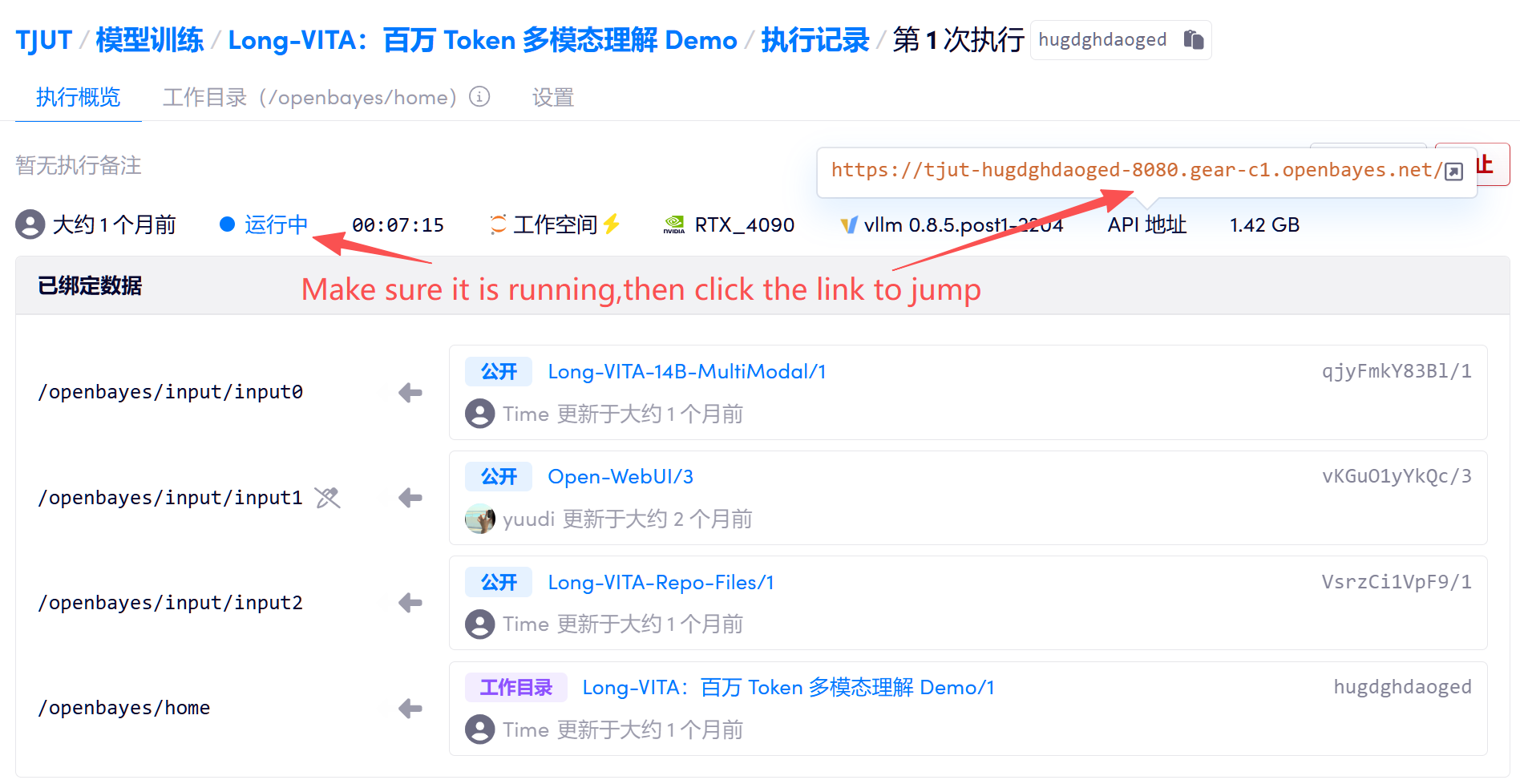
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die interaktive Gradio-Oberfläche aufzurufen
2. Sobald Sie die Webseite betreten, können Sie das Modell verwenden
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
Vorsichtsmaßnahmen
- Bei längeren Eingabetexten ist ausreichend Videospeicher erforderlich; es wird empfohlen, sehr große Texte in Stapeln zu laden.
- Es wird empfohlen, dass das Bildeingabebild eine Seitenlänge von ≤ 2048 Pixeln aufweist, um die Latenz der Inferenz zu reduzieren.
- Falls die Inferenz fehlschlägt, überprüfen Sie bitte das Eingabeformat oder verkürzen Sie die Eingabelänge und versuchen Sie es erneut.
Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@misc{shen2025longvitascalinglargemultimodal,
title={Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuracy},
author={Yunhang Shen and Chaoyou Fu and Shaoqi Dong and Xiong Wang and Yi-Fan Zhang and Peixian Chen and Mengdan Zhang and Haoyu Cao and Ke Li and Xiawu Zheng and Yan Zhang and Yiyi Zhou and Ran He and Caifeng Shan and Rongrong Ji and Xing Sun},
year={2025},
eprint={2502.05177},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2502.05177},
}KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.