Command Palette
Search for a command to run...
HuMo-17B: Trimodale Kollaborative Kreation
1. Einführung in das Tutorial

HuMo ist ein multimodales Videogenerierungs-Framework, das im September 2025 von der Tsinghua-Universität und dem Intelligent Creation Lab von ByteDance veröffentlicht wurde und sich auf die nutzerzentrierte Videogenerierung konzentriert. Es kann aus verschiedenen Eingabemodalitäten wie Text, Bildern und Audio hochwertige, detailreiche und steuerbare, menschenähnliche Videos generieren. HuMo unterstützt leistungsstarke Funktionen zur Textverfolgung, konsistente Personenerhaltung und audiogesteuerte Bewegungssynchronisation. Es unterstützt die Videogenerierung aus Text-Bild (VideoGen from Text-Image), Text-Audio (VideoGen from Text-Audio) und Text-Bild-Audio (VideoGen from Text-Image-Audio). Zugehörige Forschungsarbeiten sind verfügbar. HuMo: Menschzentrierte Videogenerierung durch kollaborative multimodale Konditionierung .
Das HuMo-Projekt bietet die Modellbereitstellung in zwei Spezifikationen: 1.7B und 17B. Dieses Tutorial verwendet ein 17B-Modell und eine einzelne RTX Pro 6000-Karte als Ressource.
→ Klicken Sie hier, um zum Erlebnis zu springenHuMo 1.7B: Ein Framework für die multimodale Videogenerierung".
2. Projektbeispiele
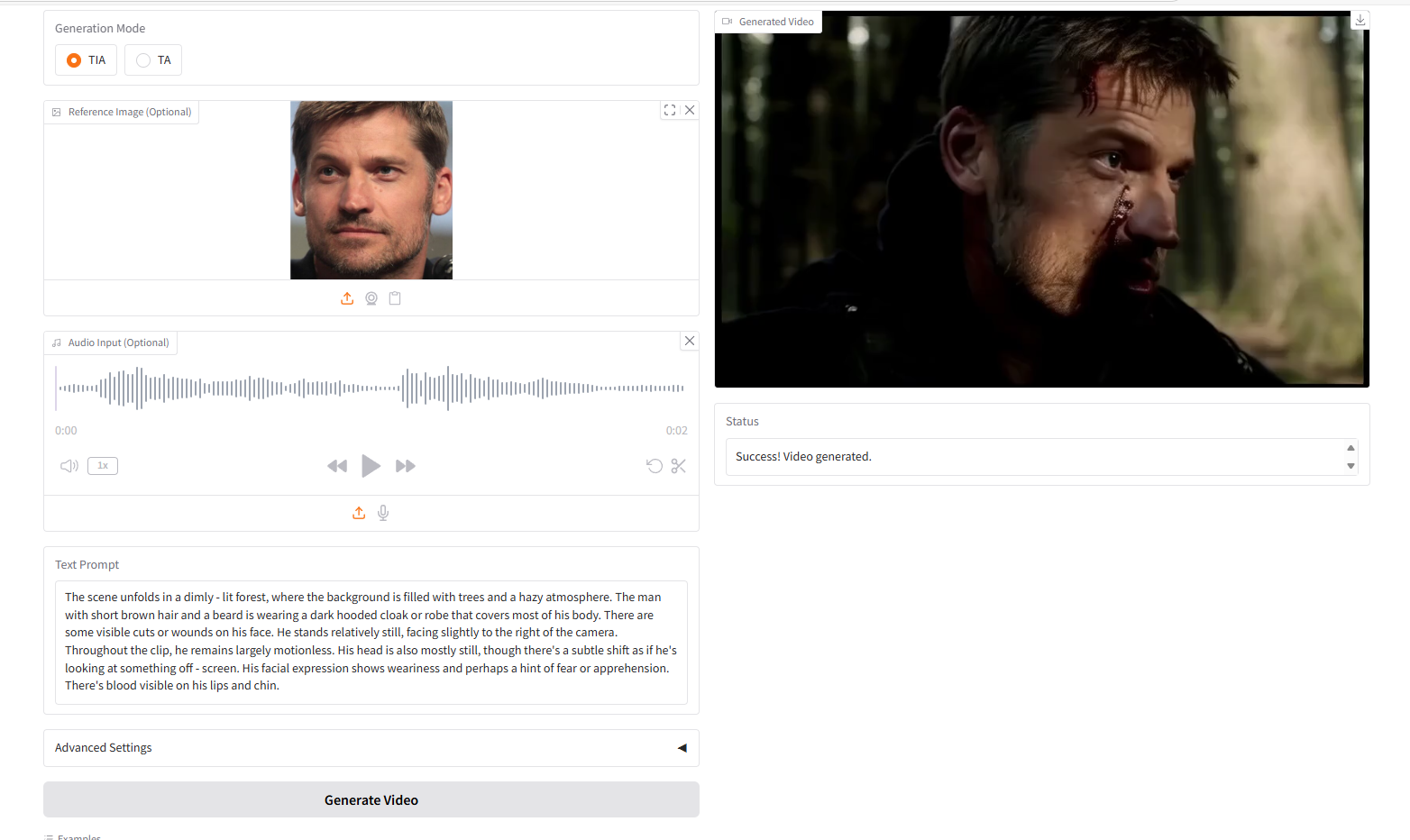
VideoGen von Text-Bild-Audio, TIA
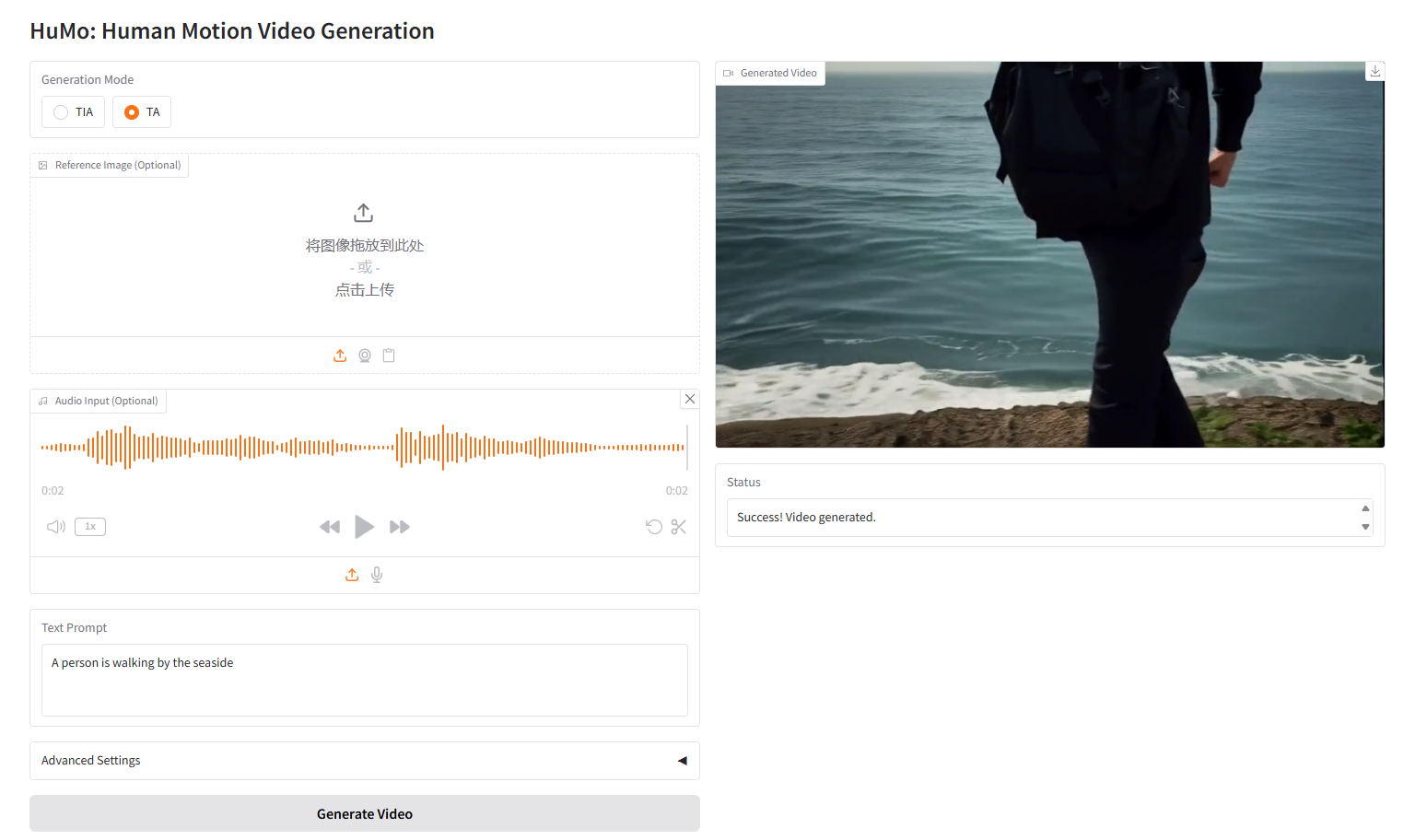
VideoGen von Text-Audio, TA
3. Bedienungsschritte
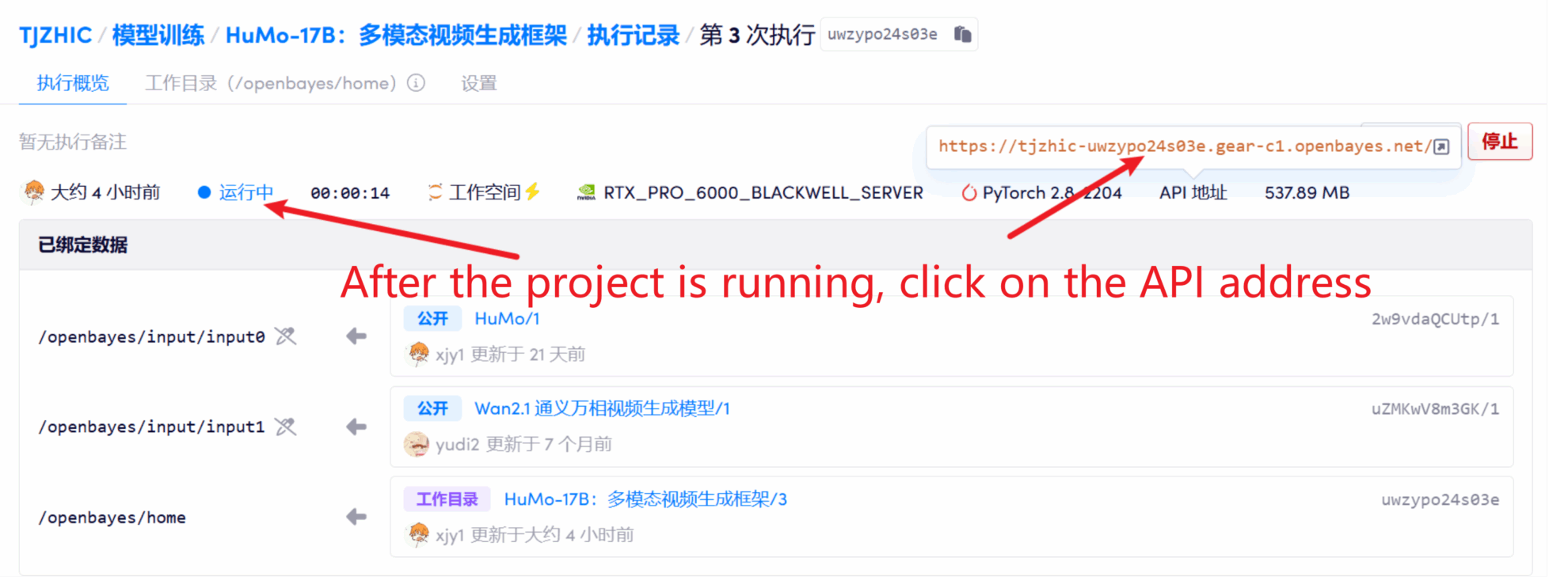
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
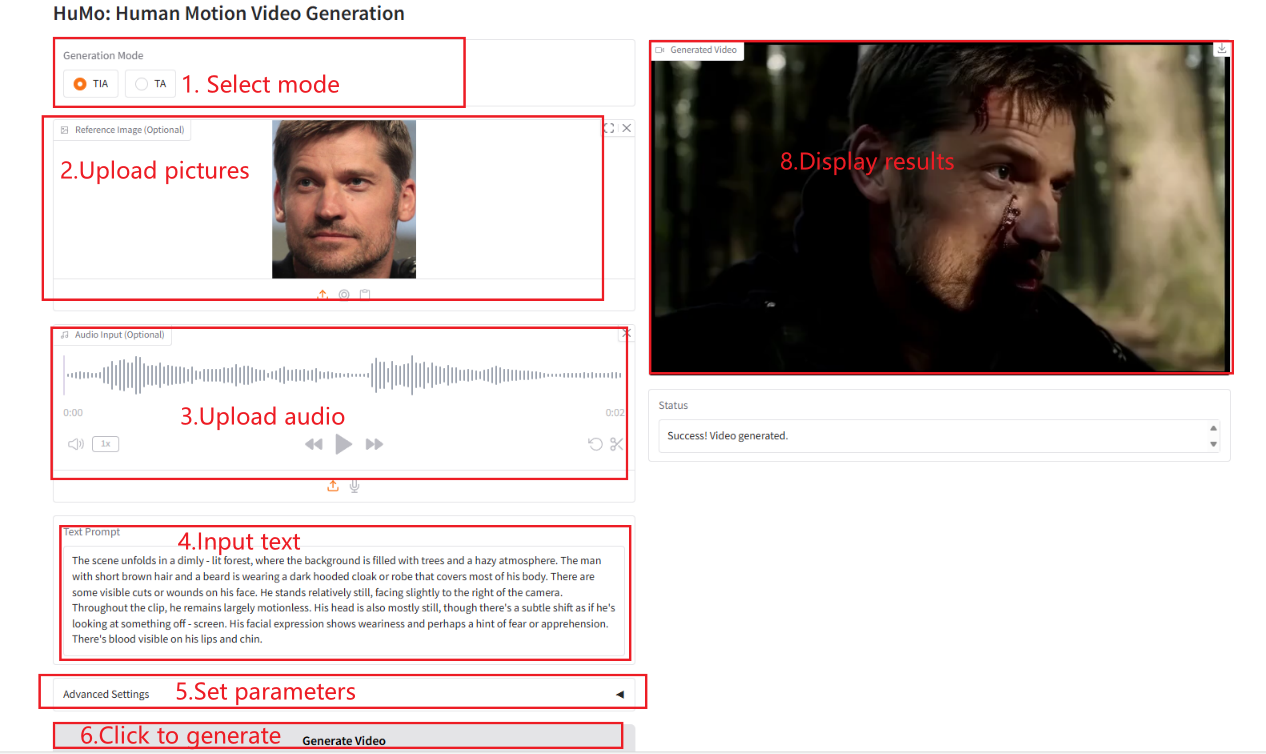
2. Anwendungsschritte
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite. Hinweis: Wenn die Stichprobenschritte auf 10 eingestellt sind, dauert es ungefähr 3–5 Minuten, bis Ergebnisse generiert werden.
TIA
TA
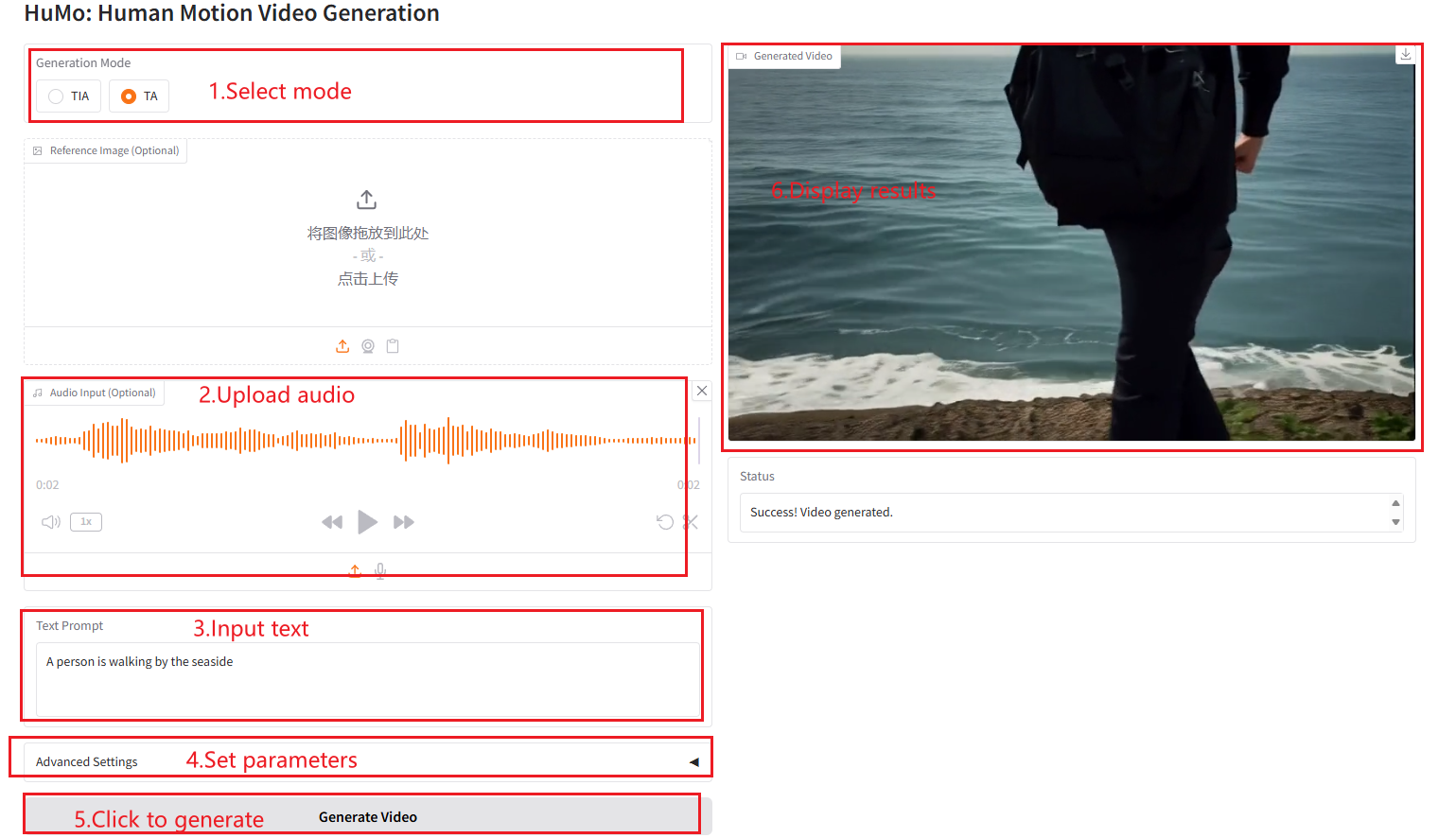
Parameterbeschreibung
- Höhe: Legen Sie die Höhe des Videos fest.
- Breite: Legen Sie die Breite des Videos fest.
- Frames: Legen Sie die Anzahl der Videoframes fest.
- Textführungsskala: Skalierung der Textführung, die verwendet wird, um die Auswirkung von Textaufforderungen auf die Videogenerierung zu steuern.
- Bildführungsskala: Bildführungsskalierung, die verwendet wird, um den Einfluss von Bildhinweisen auf die Videogenerierung zu steuern.
- Audio-Anleitungsskala: Skalierung der Audio-Anleitung, die verwendet wird, um den Einfluss von Audiohinweisen auf die Videogenerierung zu steuern.
- Sampling-Schritte: Die Anzahl der Sampling-Schritte, die zur Steuerung der Qualität und Details des generierten Videos verwendet werden.
- Zufallsstartwert: Zufallsstartwert, der zur Steuerung der Zufälligkeit der Videogenerierung verwendet wird.
Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@misc{chen2025humo,
title={HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning},
author={Liyang Chen and Tianxiang Ma and Jiawei Liu and Bingchuan Li and Zhuowei Chen and Lijie Liu and Xu He and Gen Li and Qian He and Zhiyong Wu},
year={2025},
eprint={2509.08519},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.08519},
}Notebook-Übersicht
Stufe
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.