Command Palette
Search for a command to run...
vLLM+Open WebUI-Bereitstellung KernelLLM-8B
1. Einführung in das Tutorial
Die in diesem Tutorial verwendeten Rechenressourcen sind eine einzelne RTX 4090-Karte.
KernelLLM ist ein umfangreiches Sprachmodell für die GPU-Kernel-Entwicklung von Meta AI. Es übersetzt PyTorch-Module automatisch in effizienten Triton-Kernel-Code und vereinfacht und beschleunigt so die leistungsstarke GPU-Programmierung. Das Modell basiert auf der Llama 3.1 Instruct-Architektur, verfügt über 8 Milliarden Parameter und konzentriert sich auf die Generierung effizienter Triton-Kernel-Implementierungen.
2. Projektbeispiele
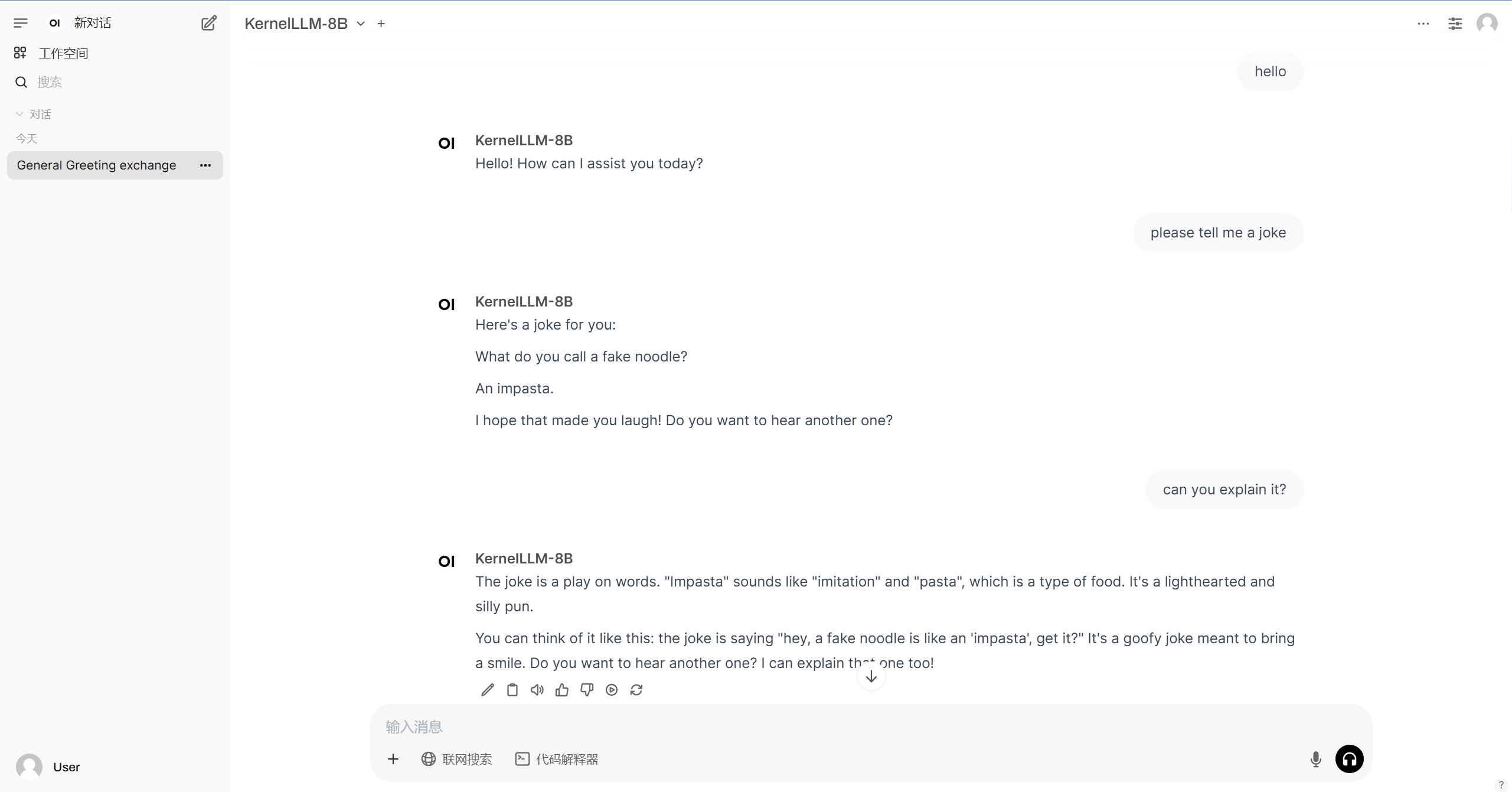
3. Bedienungsschritte
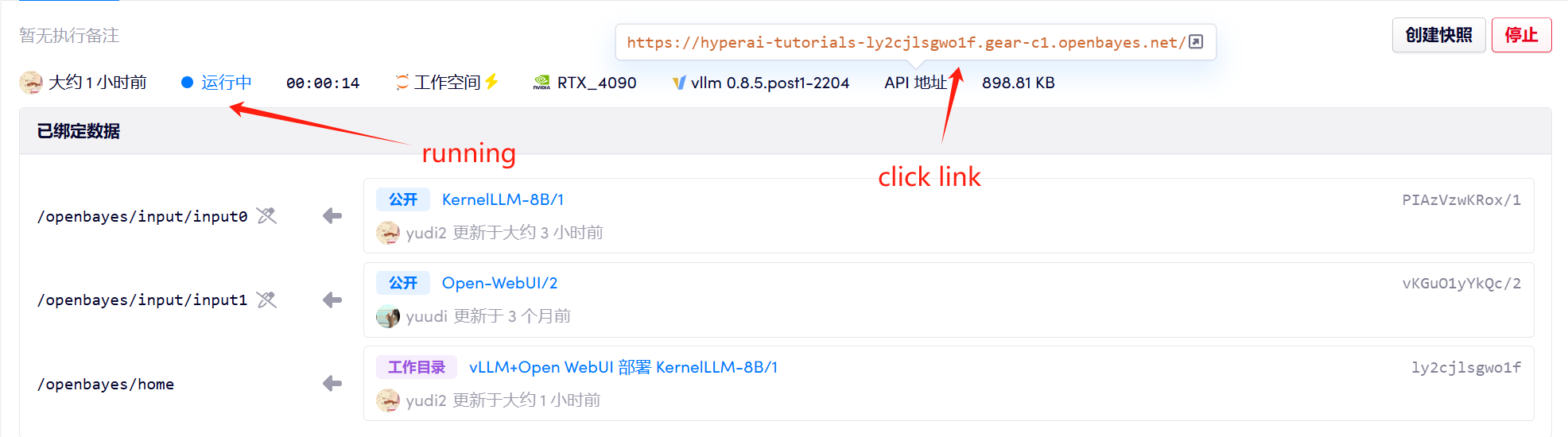
1. Starten Sie den Container
Wenn „Modell“ nicht angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
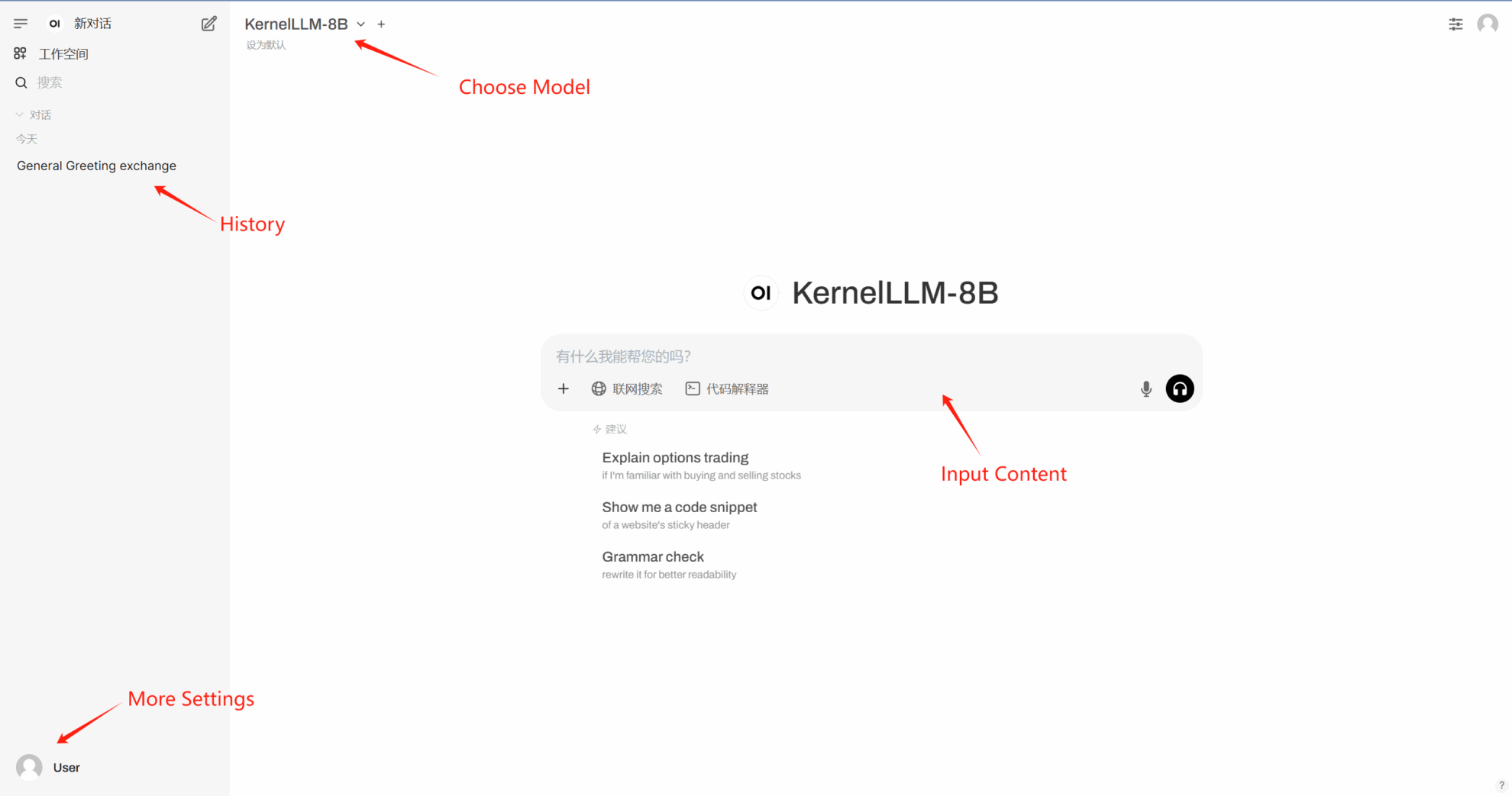
2. Nachdem Sie die Webseite aufgerufen haben, können Sie ein Gespräch mit dem Modell beginnen
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

Notebook-Übersicht
Stufe
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.