Command Palette
Search for a command to run...
Diese Entscheidung Half Fei-Fei Li, Ihren Status Als Königin Der KI Zu etablieren.

Als klassischster Datensatz hat ImageNet zur rasanten Entwicklung der Computervision geführt. Welchen Herausforderungen begegnete man also bei der Erstellung dieses Datensatzes? Welchen Einfluss hatte es auf die Entwicklung des Deep Learning? Welche Inspiration kann es uns heute bringen, wo maschinelles Lernen so beliebt ist?
Der berühmte Informatiker Fei-Fei Li hat bei vielen Gelegenheiten gesagt:Künstliche Intelligenz wird die Welt verändern, aber wer wird die künstliche Intelligenz verändern?
Dass Fei-Fei Li in der Branche eine wichtige Rolle spielt und jedes ihrer Worte für Aufsehen in der Branche sorgen kann, liegt nicht nur an ihren vielen wichtigen Forschungsergebnissen. Ein ganz wichtiger Punkt ist, dass sie die Gründung des ImageNet-Projekts initiiert hat, das eine wichtige Rolle bei der Förderung der gesamten Branche spielte.
ImageNet: Der Datensatz, der die Entwicklung der KI verändert hat
Computer Vision ist derzeit eine der besten Richtungen für die KI-Entwicklung. ImageNet ist ein klassischer Datensatz in diesem Bereich. Es ist keine Übertreibung zu sagen, dass Gesichtserkennung ohne ImageNet heute ein Luxus wäre.
ImageNet wurde von Fei-Fei Li et al. eingeführt. in einem Artikel auf der CVPR 2009. Die Anzahl und Qualität von ImageNet sind beispiellos.Es enthält 15 Millionen kommentierte Bilder aus 22.000 Kategorien und soll Computern beibringen, die Vielfalt der Welt zu erkennen..

Im letzten Jahrzehnt wurden Einführungsartikel von ImageNet veröffentlicht. 《ImageNet: Eine groß angelegte hierarchische Bilddatenbank》Die Auswirkungen sind enorm. Auf Google Scholar ist das Papier derzeit11914 mal zitiert.
Ein weiteres Papier beschreibt die ImageNet-Datenherausforderung und den Forschungsfortschritt im Bereich der Objekterkennung. 《ImageNet – Herausforderung zur groß angelegten visuellen Erkennung》hat auch die Zahl der Zitate einen erstaunlichen Wert erreicht 11056 mal.

ImageNet ist zu einem Maßstab im Bereich der Computer-Vision-Erkennung geworden und hat die Branche in eine Ära hochwertiger Datensätze geführt: Nach 2010 haben große Unternehmen wie Google, Microsoft und zahlreiche Forschungsinstitute begonnen, hochwertige Datensätze auf den Markt zu bringen.
Auch ImageNet hat den Test der Zeit bestanden. Auf der Top-Konferenz CVPR 2019Ausgezeichnet für den weitreichendsten Beitrag zur Computervision im letzten Jahrzehnt——Der Longuet-Higgins-Preis wurde der Zeitung verliehen, die ImageNet ohne jede Spannung veröffentlichte.
Vor zehn Jahren sah sie die Bedeutung von Daten voraus
Im Jahr 2009 war die vorherrschende Denkweise in der Branche noch immer auf Modelle ausgerichtet, die sich in theoretischem, handcodiertem maschinellem Lernen widerspiegelten, und auf die Verwendung mathematischer Methoden zur Lösung allgemeiner Probleme.
Aber Fei-Fei Li tat etwas ganz „Anderes“, wie sie später in einem Interview sagte,Forschung sollte langfristig angelegt sein und Wirkung zeigen. Betrachten Sie nicht nur aktuelle Trends. Sie sollten sich für fundierte und einflussreiche Forschung engagieren.

Im Jahr 2006 war Fei-Fei Li Professorin für Informatik an der University of Illinois at Urbana-Champaign. Sie stellte fest, dass die gesamte Community bessere Strategien zur Algorithmusspezifikation untersuchte, aber die Rolle der Daten unterschätzte.
Durch eine ruhige Analyse erkannte sie die damit verbundenen Nachteile:Wenn die verwendeten Daten zu Forschungszwecken erstellt werden und die reale Welt nicht widerspiegeln können, ist selbst der beste Algorithmus bedeutungslos.
Dies bestärkte sie in ihrem Entschluss, die Daten zu bearbeiten.
Vor zehn Jahren erkannten Computer Objekte, indem sie Merkmale erfassten und dann Ergebnisse lieferten. Dies hat jedoch viele Nachteile. Beispielsweise macht das computerabstrahierte Modell häufig Fehler, wenn es um dasselbe Objekt in mehreren Haltungen und Winkeln geht.
Das größte Problem ist die Einzigartigkeit der Trainingsdaten. Wenn dem Computer nur eine Art von Bild zugeführt wird, wird er auf eine „stereotype“ Wahrnehmung trainiert und ist bei geringfügigen Änderungen nicht mehr in der Lage, diese zu erkennen.
Fei-Fei Li erkannte schnell, dass dieses Problem den größten Engpass in der Computervision darstellt.
Die Geburt von ImagNet: eine Reihe von Wendungen
Um dieses Problem zu lösen, wandte sich Fei-Fei Li wieder den Menschen zu. Nach ihrem VerständnisEin dreijähriges Kind ist in der Lage, Objekte zu erkennen und zu unterscheiden, da es eine große Anzahl von Objekten mit seinen Augen gesehen und eine große Anzahl von Bildern gesammelt hat.
Wenn einem Computer eine große Anzahl beschrifteter Bilder „eingespeist“ wird, kann die KI möglicherweise lernen, Bilder zu erkennen. Wenn wir uns nach dieser Idee weiterentwickeln, liegt der Schlüssel in den Daten. Doch wie lässt sich ein umfassendes System aufbauen?
Zu diesem Zeitpunkt WordNet Das Projekt entstand in Fei-Fei Lis Vision.
Dies ist eine englische Architektur, die auf der Klassifizierung des Wortschatzes basiert. Jedes Wort wird entsprechend seiner Beziehung zu anderen Wörtern angezeigt. Das gesamte Projekt umfasst Wörter für eine große Anzahl von Objekten auf der Welt.
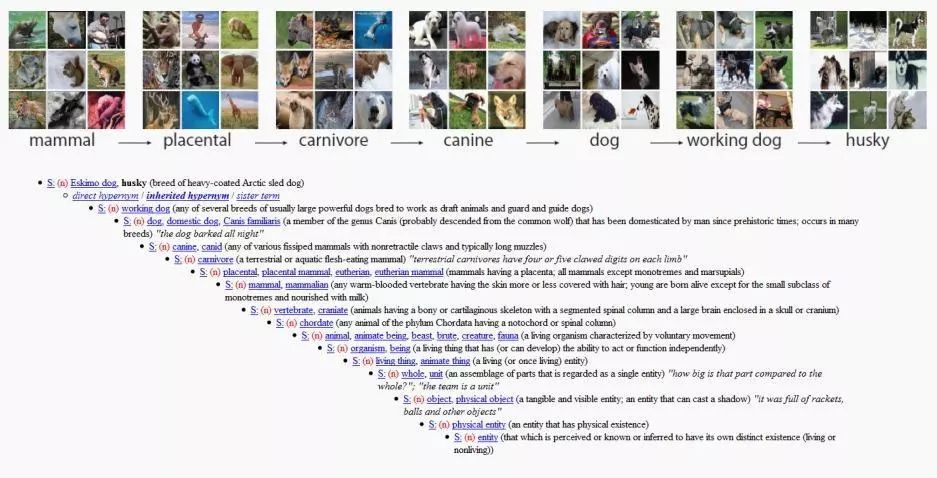
Nach einem Treffen mit der WordNet-Forscherin Professor Christiane Fellbaum im Jahr 2006 hatte Fei-Fei Li die Antwort: Sie wollte den Ansatz von WordNet nachahmen und einen großen Datensatz erstellen, um Beispielbilder für jedes Wort bereitzustellen.
Im folgenden Jahr, während seiner Arbeit an der Princeton University, startete Fei-Fei Li ImageNet Projekt und begann, ein Team zusammenzustellen, um diese enorme Arbeit zu vollenden. Ihre Ziele sind:Besorgen Sie sich genügend kommentierte Bilder, um ein vollständiges und umfangreiches Bildsystem aufzubauen.
Die Aufgabe war jedoch so umfangreich, dass sie zunächst College-Studenten einstellen wollten, um Online-Bilder zu suchen, zu filtern, zu beschriften und sie dem Datensatz hinzuzufügen.
Doch Fei-Fei Li erkannte bald, dass diese Methode der Bilderfassung zu langsam war. Einer groben Schätzung zufolge dauert es Jahrzehnte, wenn ein Mensch ohne Pause, ohne Essen oder Trinken markiert.
Durch Zufall entdeckte Fei-Fei Li einen weiteren Wendepunkt. Sie haben es herausgefunden, weil es jemand vorgestellt hat.Amazon Mechanical Turk ist eine Online-Crowdsourcing-Methode.Auf dieser Plattform können Arbeitgeber viele Leute online einstellen, um einige einfache Korrekturen vorzunehmen.
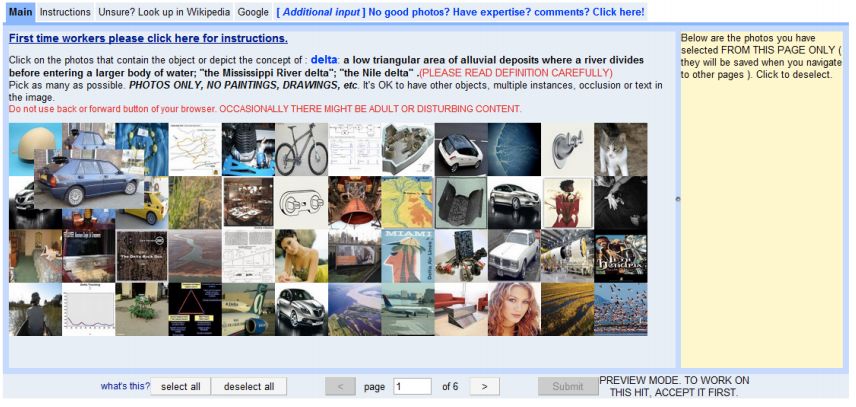
Letztendlich, durch die Nutzung des Crowdsourcing-Dienstes von Amazon,49.000 Menschen aus 167 Ländern verbrachten zweieinhalb JahreZeit, dieses riesige Projekt abzuschließen.
Trotz zahlreicher Herausforderungen wie mangelnder Unterstützung, unzureichender Finanzierung und Personalmangel konnte ImageNet dank seiner Beharrlichkeit weitergeführt werden.
Als neue Sache wurde ImageNet zunächst nicht ernst genommen. Auf der CVPR-Konferenz 2009 wurde das ImageNet-Papier nur als Forschungsposter verwendet und an einer unauffälligen Stelle ausgehängt.
Mit dem von ImageNet abgeleiteten Challenge-Wettbewerb wurde diese Situation völlig umgekehrt.
ILSVRC-Wettbewerb: Lassen Sie ImageNet ein Erfolg werden
Ein Jahr nach der Veröffentlichung von ImageNet, dank der Bemühungen von Fei-Fei Li und anderen, ImageNet Large Scale Visual Recognition Challenge (ILSVRC) ist gestartet.
ILSVRC ist auch als ImageNet-Wettbewerb bekannt, der seit 2010 jährlich stattfindet. Bei diesem Wettbewerb verwenden die Teilnehmer den ImageNet-Datensatz als Benchmark, um ihre Leistung bei der Erkennung großflächiger Objekte und der Bildklassifizierung zu bewerten.
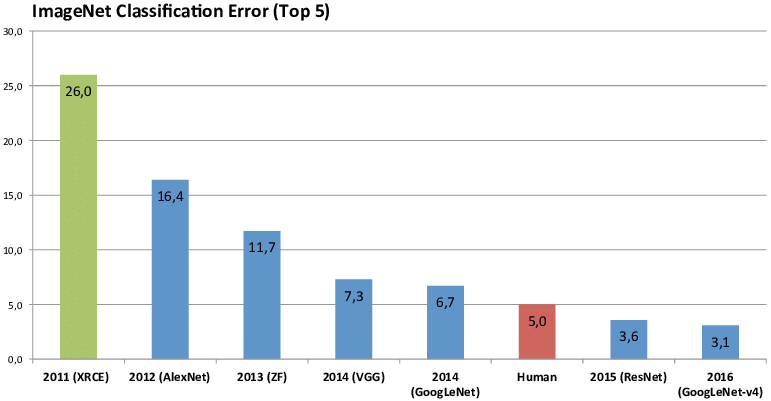
Bald entwickelte sich die Veranstaltung zu einer Art Olympiade der Screening-Algorithmus-Wettbewerbe. Große Institutionen haben es als Übungsgelände genutzt, um die Vor- und Nachteile ihrer eigenen Algorithmen zu testen. Ganz plötzlich kam es zu verschiedenen Durchbrüchen und Erfolgen.
Das Highlight des ImageNet-Wettbewerbs ist jedoch, dass er den Aufstieg neuronaler Netzwerke und des Deep Learning gefördert hat.
Hinton führte sein Team zur Teilnahme am ImageNet-Wettbewerb 2012. In diesem Jahr war die von Hintons Team verwendete Deep-Learning-Methode im Wettbewerb der Bilderkennung allen anderen Methoden weit voraus. Das von ihnen eingereichte tiefe Convolutional-Neuronal-Network-Strukturmodell Alexnet verbesserte die Leistung um 10,8 %, was 41% mehr ist als auf dem zweiten Platz.

Was ist das Konzept dahinter? Damals galt die Leistungsverbesserung von 1% als „großer Beitrag“, und das neuronale Netzwerk, eine Methode, die seit mehr als zehn Jahren ruhte, überschritt tatsächlich 10 Prozentpunkte, was sofort ein gewaltiges Erdbeben auslöste.

Zuvor waren tiefe neuronale Netzwerke noch nie mit Daten in einem solchen Umfang trainiert worden. Nach AlexNet wurden die hervorragenden Fähigkeiten tiefer neuronaler Netzwerke mithilfe von ImagNet vollständig demonstriert.
Zwei Jahre später nutzten alle an der ImageNet Challenge teilnehmenden Teams Deep Learning.
Wettbewerb beendet, Forschung geht weiter
Im Jahr 2017, acht Jahre später, erfüllte die ImagNet Challenge ihr Ziel: Die Erkennungsfehlerraten von Computern waren niedriger als die von Menschen. Die ausgereifte Bilderkennung stellte keine Herausforderung mehr dar und der neue Weg wies auf das Bildverständnis hin, sodass der Wettbewerb erfolgreich abgeschlossen werden konnte.
Angetrieben von ImageNet und der Herausforderung,Die Genauigkeit des Computers bei der Klassifizierung von Objekten stieg von 71,8 % auf 97,3 %., weit über das menschliche Niveau hinaus.
Rückblickend war die Gründung von ImageNet damals keine alltägliche Aufgabe. Diese „gegen den Trend“ gerichtete Arbeit förderte jedoch dank der Beharrlichkeit von Fei-Fei Li und anderen letztlich den historischen Fortschritt der KI. Gleichzeitig hinterließ Fei-Fei Li mit ImageNet auch im Bereich der Computervision bedeutende Spuren.
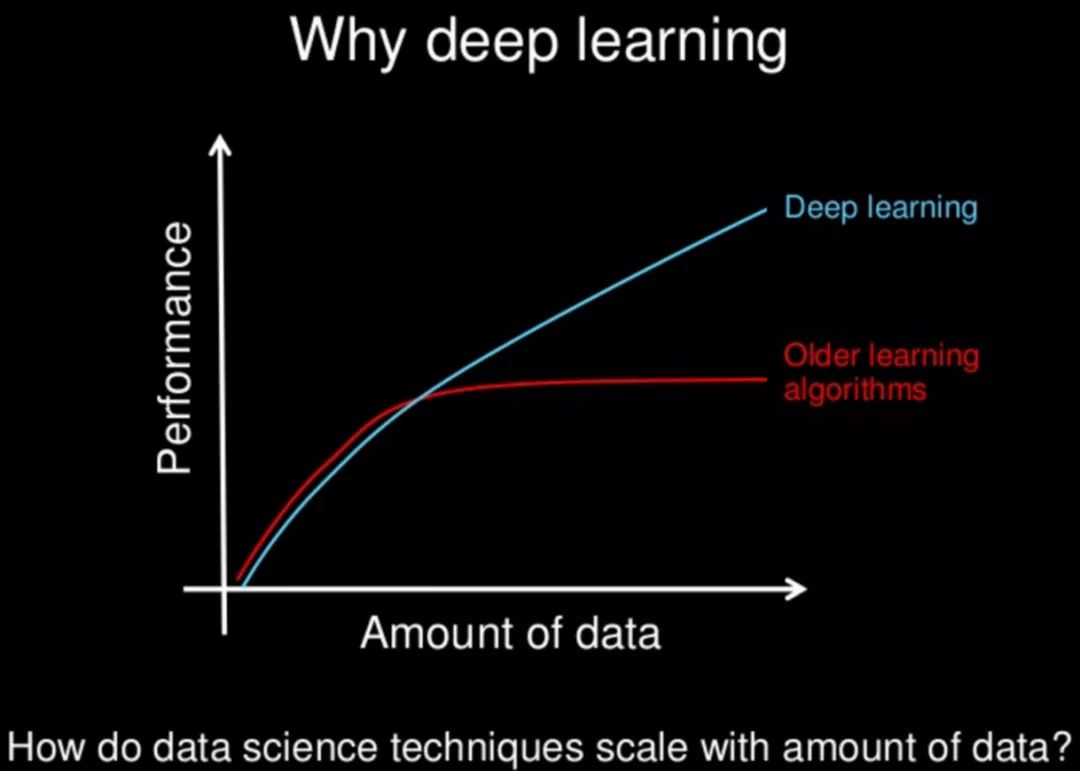
Wenn Daten mit dem „Raketentreibstoff“ des maschinellen Lernens verglichen werden, ist ImageNet zweifellos das erste und bedeutendste Treibstofffass.
Wie Fei-Fei Lis Team sagte:„Sie müssen nicht das Populärste tun, aber Sie müssen etwas tun, woran Sie glauben und was Wirkung zeigt.“

Quellen:
1. Die Daten, die die KI-Forschung – und möglicherweise die Welt – verändert haben
2. Wie wir Computern das Verstehen von Bildern wieder beibringen
4. Es gab nur einen KI-Durchbruch
5. ImageNet-Veröffentlichungen und -Zitate
6. Herausforderung der visuellen Erkennung im großen Maßstab
-- über--








