Command Palette
Search for a command to run...
Ein Neuer Meilenstein Im Bereich Der Gehirn-Computer-Schnittstellen: Gedanken Sprechen, Maschinen Interpretieren
Die Verwendung neuronaler Netzwerke zum Dekodieren der neuronalen Signale in den entsprechenden Gehirnbereichen beim Sprechen und die anschließende Verwendung rekurrierender neuronaler Netzwerke zum Synthetisieren der Signale zu Sprache kann Patienten mit Sprachstörungen bei der Lösung sprachlicher Kommunikationsprobleme helfen.
„Gedankenlesen“ könnte tatsächlich Realität werden.
Für die meisten Menschen ist Reden etwas ganz Alltägliches. Dennoch gibt es immer noch viele Menschen auf dieser Welt, die an diesen Krankheiten leiden: Schlaganfall, traumatische Hirnverletzung, neurodegenerative Erkrankungen wie Parkinson, Multiple Sklerose und amyotrophe Lateralsklerose (ALS oder Lou-Gehrig-Krankheit) usw., und sie leiden oft anIrreversibler Verlust der Sprechfähigkeit.
Wissenschaftler arbeiten intensiv an der Wiederherstellung menschlicher Funktionen und der Reparatur von Nerven. Dabei ist die Gehirn-Computer-Schnittstelle (BCI) ein Schlüsselbereich.
Unter Brain-Computer-Interface versteht man eine direkte Verbindung zwischen dem menschlichen oder tierischen Gehirn und externen Geräten, die einen Informationsaustausch zwischen dem Gehirn und dem Gerät ermöglicht.
Doch es scheint, dass die Gehirn-Computer-Schnittstelle schon immer ein fernes Konzept war. Heute wurde ein Artikel in der renommierten Fachzeitschrift Nature veröffentlicht.Sprachsynthese durch neuronale Dekodierung gesprochener Sätze” („Sprachsynthese mit neuronaler Dekodierung gesprochener Sätze“), was uns zeigt, dass die Forschung auf dem Gebiet der Gehirn-Computer-Schnittstellen einen großen Schritt nach vorne gemacht hat.
Die Notlage von Menschen mit Sprachbehinderungen
Tatsächlich wird die Forschung zu Gehirn-Computer-Schnittstellen bereits seit mehr als 40 Jahren betrieben. Die erfolgreichsten und klinisch am weitesten verbreiteten Technologien sind bislang jedoch lediglich Technologien zur sensorischen Wiederherstellung wie Cochlea-Implantate.
Bis heute können manche Menschen mit schweren Sprachbehinderungen ihre Gedanken nur mithilfe von Hilfsmitteln Wort für Wort ausdrücken.
Diese Hilfsmittel können sehr subtile Augen- oder Gesichtsmuskelbewegungen verfolgen und Wörter basierend auf den Gesten des Patienten buchstabieren.
Der Physiker Stephen Hawking hatte einst ein solches Gerät an seinem Rollstuhl installiert.

Damals verließ sich Hawking auf per Infrarot erfasste Muskelbewegungen, um Befehle zu erteilen, die vom Computercursor gescannten Buchstaben zu bestätigen und die gewünschten Wörter aufzuschreiben. Verwenden Sie anschließend ein Text-to-Speech-Gerät, um die Wörter zu „sprechen“. Mithilfe dieser schwarzen Technologien können wir sein Buch „Eine kurze Geschichte der Zeit“ lesen.
Doch mit solchen GerätenDas Generieren von Text oder synthetischer Sprache ist mühsam, fehleranfällig und sehr langsam.Normalerweise sind maximal 10 Wörter pro Minute erlaubt. Hawking war damals bereits sehr schnell, konnte jedoch nur 15–20 Wörter buchstabieren. Natürliche Sprache kann 100 bis 150 Wörter pro Minute erreichen.
Darüber hinaus ist diese Methode durch die Bewegungsfähigkeit des Körpers des Bedieners stark eingeschränkt.
Um diese Probleme zu lösen, untersucht man im Bereich der Gehirn-Computer-Schnittstellen, wie man die entsprechenden elektrischen Signale der Großhirnrinde direkt in Sprache umsetzen kann.
Neuronale Netzwerke interpretieren Gehirnsignale, um Sprache zu synthetisieren
Nun ist bei der Lösung dieses schwierigen Problems ein Durchbruch gelungen.
Edward Chang, Professor für Neurochirurgie an der University of California, San Francisco, und seine Kollegen schlugen in ihrem Artikel „Speech Synthesis from Neural Decoding of Spoken Sentences“ vor, dassDie entwickelte Gehirn-Computer-Schnittstelle kann die beim Sprechen erzeugten neuronalen Signale dekodieren und zu Sprache synthetisieren.Das System kann 150 Wörter pro Minute generieren, was der normalen menschlichen Sprechgeschwindigkeit nahe kommt.

Das Forscherteam rekrutierte fünf Epilepsiepatienten, die sich in Behandlung befanden, und ließ sie Hunderte von Sätzen laut aussprechen, während ihre hochdichten Elektroenzephalogramm-Signale (ECoG) aufgezeichnet und die neuronale Aktivität im ventralen sensorischen Motorkortex, dem Sprachproduktionszentrum des Gehirns, verfolgt wurden.
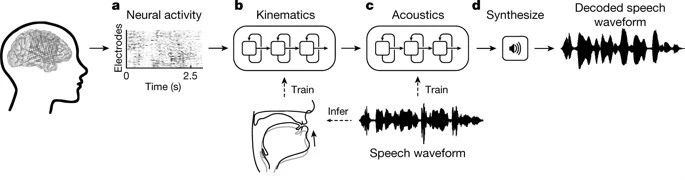
verwendenRekurrente neuronale Netze (RNNs)entschlüsselten die Forscher die gesammelten neuronalen Signale in zwei Schritten.
ErstensWandeln Sie neuronale Signale in Signale um, die die Bewegungen der Stimmorgane darstellen.Beinhaltet Gehirnsignale im Zusammenhang mit Kiefer-, Rachen-, Lippen- und Zungenbewegungen.
Der zweite Schritt besteht darin, das Signal basierend auf den dekodierten Bewegungen der Stimmorgane in gesprochene Wörter umzuwandeln.

Beim Dekodierungsprozess entschlüsselten die Forscher zunächst die kontinuierlichen Elektrogrammsignale von der Oberfläche dreier Gehirnregionen, wenn der Patient sprach. Diese Elektrogrammsignale wurden durch invasive Elektroden aufgezeichnet.
Nach der Dekodierung werden 33 Arten von charakteristischen Indikatoren für die Bewegung des Stimmorgans erhalten, die dann in 32 Sprachparameter (einschließlich Tonhöhe, Stimmhaftigkeit usw.) dekodiert werden. Schließlich werden Sprachschallwellen basierend auf diesen Parametern synthetisiert.
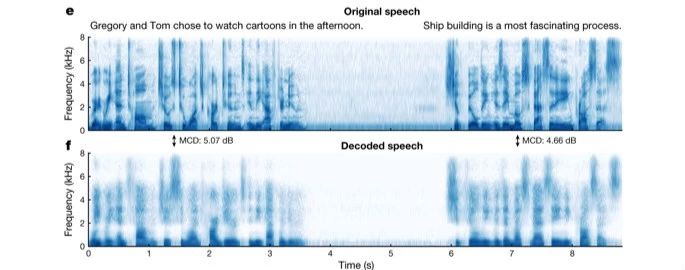
Um die Genauigkeit der synthetisierten Sprache bei der Wiedergabe echter Sprache zu analysieren, verglichen die Forscher die klanglichen Merkmale der Originalsprache mit der synthetisierten Sprache und stellten fest, dass die vom neuronalen Netzwerk dekodierte Sprache die einzelnen Phoneme in den vom Patienten geäußerten Originalsätzen sowie die natürlichen Verbindungen und Pausen zwischen den Phonemen ziemlich vollständig wiedergab.
Anschließend baten die Forscher per Crowdsourcing die Internetnutzer, die vom Decoder synthetisierte Sprache zu identifizieren. Das Endergebnis ist, dass der Zuhörer den Inhalt der synthetisierten Sprache wiederholt.Die Erfolgsrate liegt bei etwa 70%.
Darüber hinaus testeten die Forscher die Fähigkeit des Decoders, Sprache aus stiller Sprache zu synthetisieren. Der Prüfling sagt zunächst einen Satz und rezitiert anschließend denselben Satz still (mit Bewegungen, aber ohne ein Geräusch zu machen). Die Ergebnisse zeigten, dass das vom Decoder für stille Sprachbewegungen synthetisierte Sprachspektrum dem Stimmspektrum desselben Satzes ähnelte.
Meilenstein: Herausforderungen und Erwartungen bestehen nebeneinander
„Diese Studie zeigt zum ersten Mal, dass wir auf der Grundlage der Gehirnaktivität einer Person vollständige gesprochene Sätze generieren können“, sagte Chang. „Das ist spannend. Diese Technologie ist in greifbare Nähe gerückt, und wir sollten in der Lage sein, klinisch praktikable Geräte für Patienten mit Sprachverlust zu entwickeln.“
Gopala Anumanchipalli, Erstautor des Artikels, fügte hinzu: „Ich bin stolz darauf, Fachwissen aus den Neurowissenschaften, der Linguistik und dem maschinellen Lernen zusammengebracht zu haben, um an diesem wichtigen Meilenstein in der Hilfe für Menschen mit neurologischen Behinderungen mitzuwirken.“
Natürlich gibt es noch viele Herausforderungen, um bei der Sprachinteraktion über Gehirn-Computer-Schnittstellen wirklich eine 100-prozentige Sprachsynthese zu erreichen. So muss beispielsweise geprüft werden, ob die Patienten einen invasiven chirurgischen Eingriff zum Einsetzen von Elektroden akzeptieren, ob die Gehirnströme im Experiment mit denen echter Patienten übereinstimmen usw.
Aus dieser Studie haben wir jedoch gesehen,Die Gehirn-Computer-Schnittstelle zur Sprachsynthese ist nicht länger nur ein Konzept.
Wir hoffen, dass Menschen mit Sprachstörungen eines Tages so schnell wie möglich wieder die Fähigkeit erlangen, zu „sprechen“ und ihre Gedanken auszudrücken.


