Command Palette
Search for a command to run...
Gehen Sie Nicht Zurück Zur Schule, Die Methoden Der Lehrer Sind Raffinierter geworden.

Von Super Neuro
Heute ist der Internationale Lehrertag. In meinem Freundeskreis wurden die Segnungen für Lehrer überhäuft. Alle zollen den Lehrern Tribut und vermissen den Campus. Aber wenn Sie wüssten, in welch schwierigen Lebensumständen die heutigen Mittelschüler leben, würden Sie wohl denken.
Vor Kurzem hat die Hangzhou No. 11 Middle School das Smart Eye-System getestet, bei dem eine Kombination von Kameras im Klassenzimmer installiert wird, um die Mimik und Bewegungen der Schüler im Unterricht aufzuzeichnen. Mithilfe der Gesichtserkennungstechnologie werden sechs Verhaltensweisen und sieben Ausdrucksarten der Schüler im Klassenzimmer erfasst.

Das Lehrsystem, das für Aufsehen sorgte, heißt „Smart Classroom Behavior Management System“, kurz „Smart Eye“.
Es wird gesagt, dass es Schüler genau erfassen kannLesen, aufstehen, die Hand heben, auf dem Tisch liegen, zuhören und schreibenUnd andere 6 Verhaltensweisen, kombiniert mit den Gesichtsausdrücken der Schüler zu analysierenNeutral, glücklich, traurig, wütend, verängstigt, angewidert und überrascht 7 Emotionen.
Smart Eyes - Der Schüler, der in der Klasse am liebsten Geschichten erzählt
Nachdem das System diese Informationen einfach verarbeitet hat, generiert es eine Reihe von Codes, wie etwa A für aufmerksames Zuhören im Unterricht, B für Schlafengehen und C für Beantworten von Fragen, und verwendet diese, um den Status des Schülers zu beurteilen. Ein guter Zustand, wie etwa aufmerksames Zuhören im Unterricht, führt zu Punkten, während ein schlechter Zustand, wie etwa Schlafen im Unterricht, zu Punktabzügen führt.
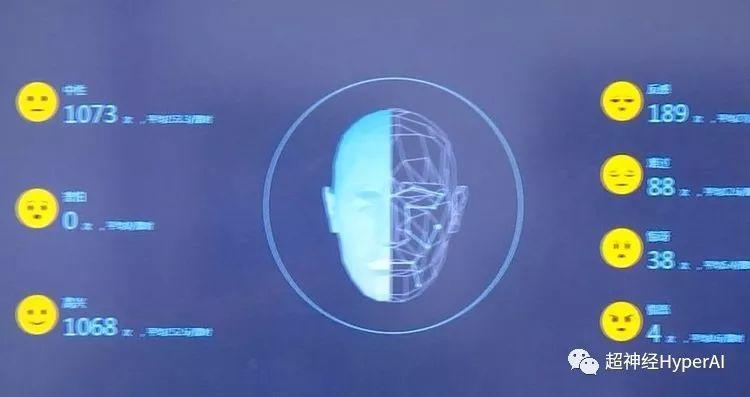
Diese Daten werden nach dem Unterricht direkt an die Lehrer weitergeleitet, damit diese die Wirkung des Unterrichts und die Reaktionen der Schüler verstehen können.
Lehrkräfte können damit ihre Unterrichtsmethoden optimieren und Schulen können damit die Qualität des Unterrichts ihrer Lehrkräfte beurteilen. Aufgrund der Anwesenheit von Kameras ist es jedoch unvermeidlich, dass sich die Schüler etwas unwohl fühlen, was verständlich ist.
Hinsichtlich der Datenschutz- und Datenleckprobleme, die die Öffentlichkeit beunruhigen, heißt es, dass die von diesem System generierten Dateninformationen nur von Lehrern und älteren Schülern eingesehen werden können und dass andere Lehrer oder Außenstehende kein Recht haben, sie einzusehen.

(Der rote Kreis oben ist das Gesichtserkennungsgerät und der rote Kreis unten ist die Kamera, die Informationen sammelt.)
Der Hardwareteil besteht aus einer drehbaren Kamera und einem Gerät zur Gesichtserkennung. In jedem Klassenzimmer gibt es etwa drei davon, die alle 30 Sekunden scannen.
Alle Kameras dienen ausschließlich der Erfassung von Verhaltensinformationen und werden nicht zur Überwachung oder Aufzeichnung verwendet. Es wird keine Probleme mit dem Datenschutz oder Datenverlust geben.
Die Mittelschule Nr. 11 plant, dieses System noch in diesem Jahr in allen Klassenzimmern zu installieren. Es soll nicht nur die Emotionen der Schüler im Unterricht überwachen, sondern auch ihre Anwesenheit per Gesichtserkennung erfassen. Das System befindet sich jedoch noch in der Anfangsphase und benötigt mehr Daten, aus denen es lernen kann, um die Genauigkeit der Emotionserkennung zu verbessern.
Für die Zukunft ist geplant, das Durchziehen von Karten in der Schule vollständig durch Gesichtsscans zu ersetzen und so den ersten kartenlosen Campus des Landes zu schaffen. Ich frage mich, ob dies von Jack Ma von Alibaba nebenan inspiriert wurde.
Überwachung im Klassenzimmer kann eine gute Sache sein
Die Hangzhou No. 11 Middle School sollte die erste sein, die Spitzentechnologie auf den Campus bringt, aber wir hoffen auch, dass die Schule die emotionale Erkennung, die zur Verbesserung der Unterrichtsqualität eingesetzt wird, nicht als Echtzeit-Überwachungstool verwendet. Denn auch wenn der Campus ein öffentlicher Ort ist, sollte jedem Studierenden innerhalb gewisser Grenzen ein gewisses Maß an Privatsphäre gewahrt bleiben.
Der Grund, warum das Smart Eye-System Aufmerksamkeit und Diskussionen erregt hat, liegt letztlich darin, dass jeder das Gefühl hat, die Schüler würden überwacht. Aber denken Sie mal andersherum darüber nach. Huiyan behauptet, dass die Daten weder gespeichert noch öffentlich zugänglich gemacht werden, was eigentlich den Augen eines Lehrers im herkömmlichen Sinne gleichkommt.
Das Wichtigste ist daher die „Benutzervereinbarung“. Was die Schule jetzt klären sollte, ist der Nutzungs- und Autorisierungsumfang der Videoinhalte in Huiyan.
Technische Umsetzung der Emotionserkennung
Es ist mittlerweile Realität, dass Maschinen menschliche Emotionen erkennen können, doch die Komplexität der riesigen Trainingsdaten und der Modellerstellung schreckt viele Forscher ab.
Nun haben fünf große Jungs ein leichtgewichtiges Emotionserkennungsmodell entwickelt, das nicht nur die Klassifizierung von Trainingssätzen automatisch abschließen kann, sondern auch den Modellerstellungsprozess vereinfacht und so die Hürde für die Erstellung von Emotionserkennungsmodellen erheblich senkt.
Die Emotionserkennung basiert auf Technologien wie Bild- und Gesichtserkennung und identifiziert menschliche Gefühlszustände durch die Analyse des physischen Verhaltens von Menschen (wie etwa Gesichtsausdruckserkennung, Stimme und Körperhaltung).

Die Vielfalt menschlicher Gesichtsemotionen
Obwohl neuronale Netzwerke zur Emotionserkennung in Bereichen wie dem Gesundheitswesen und der Kundenanalyse weit verbreitet sind, sind die meisten Emotionserkennungsmodelle immer noch nicht in der Lage, menschliche Emotionen wirklich zu verstehen. Zudem ist die Entwicklung eines solchen Modells sehr kostspielig und schwierig.
Leichtgewichtiges Modell zur Emotionserkennung, schauen wir uns das an
Um dieses Problem zu lösen, veröffentlichten fünf Ingenieure von Orange Labs und der Universität Caen Normandie (UNICAEN) in Frankreich gemeinsam ein Papier „Eine Occam's Razor-Ansicht zum Erlernen audiovisueller Emotionen“.
In ihrem Artikel schlugen sie ein leichtes Deep-Neural-Network-Modell vor, das auf audiovisueller Emotionserkennung (d. h. Emotionserkennung mithilfe von Audio und Video) basiert. Das Modell soll leicht zu trainieren sein, den Trainingssatz automatisch klassifizieren können, eine hohe Genauigkeit aufweisen und auch mit einem kleinen Trainingssatz eine gute Leistung erzielen.
Das in diesem Artikel vorgeschlagene Modell folgtOckhams Rasiermesserund basierend auf dem AFEW-Datensatz trainiert. Audio und Video werden über mehrere Verarbeitungsebenen (die zur Merkmalsextraktion, Analyse usw. verwendet werden) gleichzeitig vorverarbeitet und einer Merkmalsanalyse unterzogen. Schließlich werden beide kombiniert, um das Ergebnis der Emotionserkennung auszugeben.
AFEW steht für „Acted Facial Expressions In The Wild“. Es handelt sich um eine Sammlung von Daten zur Ausdruckserkennung, die Testdaten für das Training von Emotionserkennungsmodellen und die EmotiW-Reihe von Herausforderungen zur Emotionserkennung bereitstellt.
Alle Daten stammen aus Videoclips mit aus Filmen und Fernsehdramen herausgeschnittenen Gesichtsausdrücken, darunter die sechs Grundausdrücke „Freude, Überraschung, Ekel, Wut, Angst und Traurigkeit“ sowie neutrale Ausdrücke.
Damit das Modell die Trainingsdaten in AFEW besser erkennt, haben die fünf F&E-Mitarbeiter auch einige Neuerungen am Modell vorgenommen:
1) Reduzieren Sie die Merkmalsdimensionen und vereinfachen Sie Modellanalyseprozesse durch Transferlernen und Einbettung in niedrigdimensionale Räume.
2) Sampling durch Bewertung jedes Frames, um die Größe des Trainingssatzes zu reduzieren;
3) Verwenden Sie einen einfachen Frame-Auswahlmechanismus, um die Bildsequenz zu gewichten.
4) In der Vorhersagephase werden verschiedene Formen der Merkmalsfusion durchgeführt, d. h. Video und Audio werden separat verarbeitet und dann zusammengeführt.
Diese Reihe von Innovationen reduziert die Anzahl der Parameter, die die Eigenschaften des Datensatzes charakterisieren, erheblich, vereinfacht den Modelltrainingsprozess und verbessert die Genauigkeit der Emotionserkennung. Beim Emotionserkennungswettbewerb EmotiW (Emotion Recognition In The Wild Challenge) 2018 erreichte das Modell eine Erkennungsgenauigkeit von 60,64 % und belegte damit den vierten Platz.
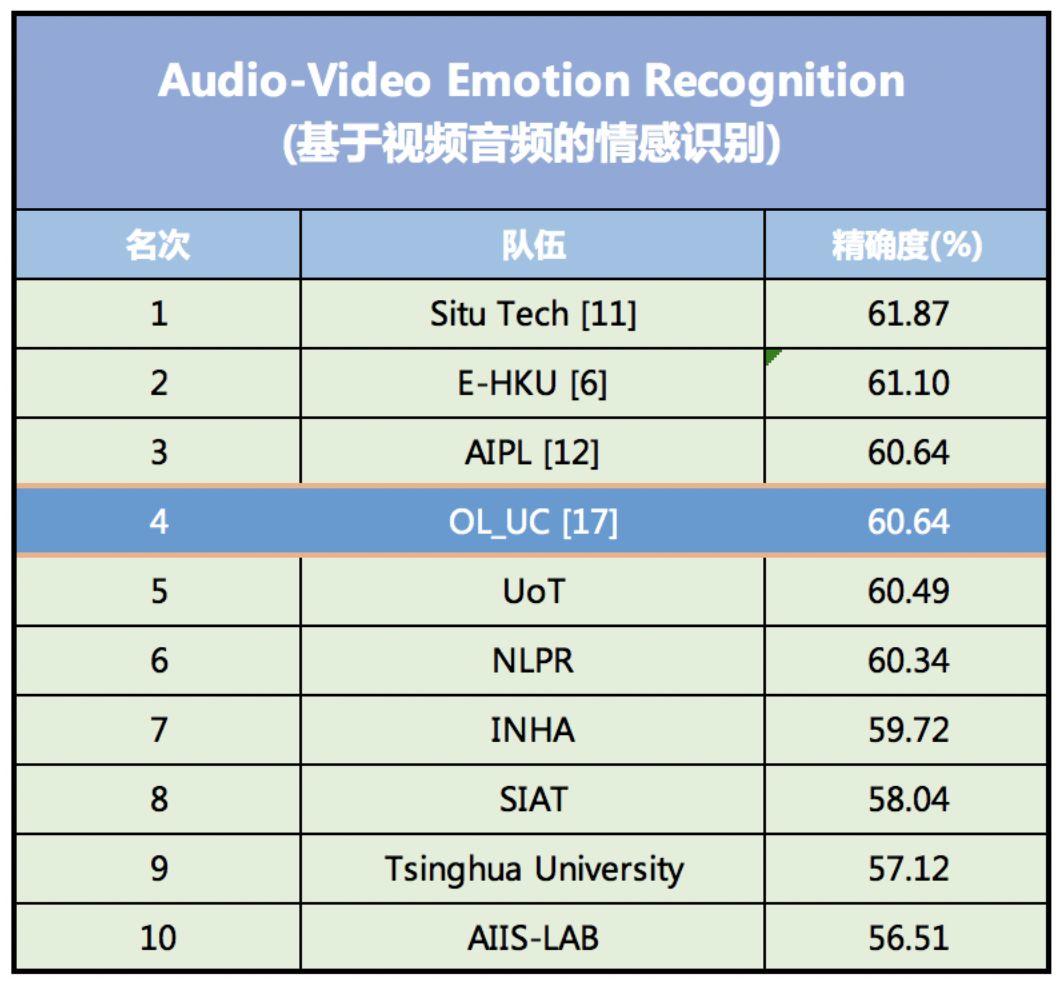
Im Genauigkeitsranking der audiovisuellen Emotionserkennungsmodelle von EmotiW aus dem Jahr 2018 belegte das Modell den vierten Platz.
Das am höchsten bewertete Modell zur Emotionserkennung wurde von SEEK TRUTH entwickelt, einem inländischen KI-Finanztechnologieunternehmen, und weist eine Genauigkeitsrate von 61,87% auf. Das zweitplatzierte Modell wurde von DeepAI entwickelt, einem KI-Startup in Kalifornien, USA, mit einer Genauigkeitsrate von 61.10%.
Das Modell kann dem Trainingssatz automatisch Beschriftungen hinzufügen
Im Vergleich zu anderen Modellen zur Emotionserkennung besteht der größte Vorteil dieses Modells darin, dass es einfach zu erstellen und zu trainieren ist. Es kann Computern die Wahrnehmung menschlicher Mikroausdrücke, einschließlich der Körpersprache, erleichtern.
Derzeit werden die meisten Modelle zur Emotionserkennung anhand der Gesichtsausdrücke von Figuren in Filmen und Fernsehdramen trainiert. Erstens sind die Anschaffungskosten gering und zweitens sind die Ausdrucksmöglichkeiten umfangreich.

Wenn diese Daten jedoch in den Trainingssatz eingegeben werden, werden sie nicht klassifiziert (d. h. jedem Video werden Emotionsbezeichnungen hinzugefügt). Daher müssen sie vor dem Training manuell oder mithilfe anderer Methoden klassifiziert werden, was schwierig durchzuführen ist und leicht zu einer Verzerrung des Trainingssatzes führen kann.
Das von Frédéric Jurie und anderen entwickelte audiovisuelle Emotionserkennungsmodell kann Ausdrücke im Trainingssatz automatisch über ein tiefes neuronales Netzwerk klassifizieren, um sie im Modell zu verwenden.
Auf diese Weise wird der Schwierigkeitsgrad des Modelltrainings reduziert und gleichzeitig die Erkennungsgenauigkeit verbessert.
Dieses Modell beweist auch, dass leichtgewichtige neuronale Netzwerkmodelle gute Ergebnisse erzielen können und einfacher zu trainieren sind, im Gegensatz zu den immer komplexer werdenden neuronalen Netzwerkmodellen von heute.
In Zukunft werden sie weiter untersuchen, wie sich Daten in Nicht-Videoformaten besser integrieren und Daten mit weniger oder gar keinen Klassifizierungen erkennen lassen.
