Command Palette
Search for a command to run...
Online-Tutorial: SpikingBrain-1.0: Hundertfache Beschleunigung: Erreichen Von Verbesserungen Der Inferenzeffizienz Um Größenordnungen

Die rasante Entwicklung künstlicher Intelligenz ist weitgehend untrennbar mit einer Kernarchitektur verbunden: dem Transformer. Seit seiner Einführung im Jahr 2017 hat sich der Transformer mit seinen parallelen Rechenkapazitäten und leistungsstarken Modellierungsergebnissen zum Mainstream-Standard für groß angelegte Modellarchitekturen entwickelt. Ob GPT-Serie, LLaMA oder die inländische Qwen-Serie – sie alle basieren auf dem Transformer-Fundament.
Mit der weiteren Vergrößerung der Modellgröße treten bei Transformer jedoch nach und nach einige Probleme auf, die schwer zu ignorieren sind.Beispielsweise steigt der Overhead während des Trainings quadratisch mit der Sequenzlänge und die Speichernutzung während der Inferenz steigt linear mit der Sequenzlänge, was zu einem Ressourcenverbrauch führt und die Fähigkeit zur Verarbeitung extrem langer Sequenzen einschränkt.
Im Gegensatz dazu verfolgt das biologische Gehirn einen völlig anderen Ansatz hinsichtlich Energieeffizienz und Flexibilität. Es verbraucht nur etwa 20 Watt, ist aber dennoch in der Lage, eine Vielzahl von Aufgaben zu bewältigen, darunter Wahrnehmung, Gedächtnis, Sprache und komplexes Denken. Dieser Kontrast hat Forscher zu der Frage veranlasst: Könnten große Modelle, die dem Gehirn ähnlicher sind, die Engpässe des Transformers überwinden?
Basierend auf dieser Untersuchung,Das Institut für Automatisierung der Chinesischen Akademie der Wissenschaften hat in Zusammenarbeit mit dem Nationalen Schlüssellabor für Gehirnkognition und gehirninspirierte Intelligenz und anderen Institutionen die komplexen Arbeitsmechanismen von Gehirnneuronen genutzt und eine groß angelegte Modellarchitektur „auf der Grundlage endogener Komplexität“ vorgeschlagen. Im September dieses Jahres veröffentlichten sie ein im Inland produziertes, unabhängig steuerbares, gehirninspiriertes Puls-Großmodell – „SpikingBrain-1.0“.Dieses Modell stellt theoretisch eine Verbindung zwischen der intrinsischen Dynamik feuernder Neuronen und linearen Aufmerksamkeitsmodellen her. Es zeigt, dass bestehende lineare Aufmerksamkeitsmechanismen eine spezialisierte Vereinfachung dendritischer Berechnungen darstellen und demonstriert einen neuen und praktikablen Weg zur kontinuierlichen Verbesserung der Modellkomplexität und -leistung. Darüber hinaus hat das F&E-Team ein neuartiges, vom Gehirn inspiriertes Grundlagenmodell auf Basis feuernder Neuronen mit linearer und gemischt-linearer Komplexität entwickelt und als Open Source bereitgestellt. Es entwickelte außerdem ein effizientes Trainings- und Inferenz-Framework für inländische GPU-Cluster, die Triton-Operatorbibliothek, Modellparallelisierungsstrategien und Cluster-Kommunikationsprimitive.
Durch experimentelle ÜberprüfungSpikingBrain-1.0 hat in vier Leistungsaspekten Durchbrüche erzielt: effizientes Training mit extrem geringen Datenmengen, eine um eine Größenordnung verbesserte Inferenzeffizienz, der Aufbau eines im Inland produzierten, unabhängigen und kontrollierbaren, gehirnähnlichen Modell-Ökosystems im großen Maßstab und die Entwicklung eines mehrskaligen Sparsity-Mechanismus auf Basis dynamischer Schwellenwertpulse.Das SpikingBrain-7B-Modell erreichte eine 100-fache Beschleunigung der Time to First Token (TTF) für eine Sequenz mit 4 Millionen Token. Das Training des SpikingBrain-7B-Modells lief wochenlang stabil auf Hunderten von MetaX C550-GPUs und erreichte eine FLOP-Auslastungsrate von 23,41 TP3T.Das vorgeschlagene Impulsschema erreicht eine Spärlichkeit von 69,15% und ermöglicht so einen Betrieb mit geringem Stromverbrauch.
Es ist erwähnenswert, dassDies ist das erste Mal, dass mein Land eine groß angelegte, gehirnähnliche lineare Basismodellarchitektur vorgeschlagen hat, und das erste Mal, dass ein Trainings- und Inferenzrahmen für ein großes, gehirnähnliches Pulsmodell auf einem inländischen GPU-Computercluster erstellt wurde.Seine Fähigkeit zur Verarbeitung ultralanger Sequenzen bietet erhebliche potenzielle Effizienzvorteile in Szenarien zur Modellierung von Aufgaben mit ultralangen Sequenzen, wie etwa der Analyse juristischer und medizinischer Dokumente, komplexer Multi-Agenten-Simulation, Experimenten in der Hochenergie-Teilchenphysik, DNA-Sequenzanalyse und molekulardynamischen Trajektorien.
„SpikingBrain-1.0: Ein gehirnähnliches Spiking-Modell basierend auf intrinsischer Komplexität“ ist jetzt auf der offiziellen HyperAI-Website im Bereich „Tutorial“ verfügbar. Klicken Sie auf den untenstehenden Link, um das Ein-Klick-Bereitstellungstutorial zu erleben ⬇️
Link zum Tutorial:
Demolauf
1. Nachdem Sie die Homepage von hyper.ai besucht haben, wählen Sie die Seite „Tutorials“, wählen Sie „SpikingBrain-1.0: Ein großes, gehirnähnliches Spiking-Modell basierend auf intrinsischer Komplexität“ und klicken Sie auf „Dieses Tutorial online ausführen“.
2. Klicken Sie nach dem Seitensprung oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
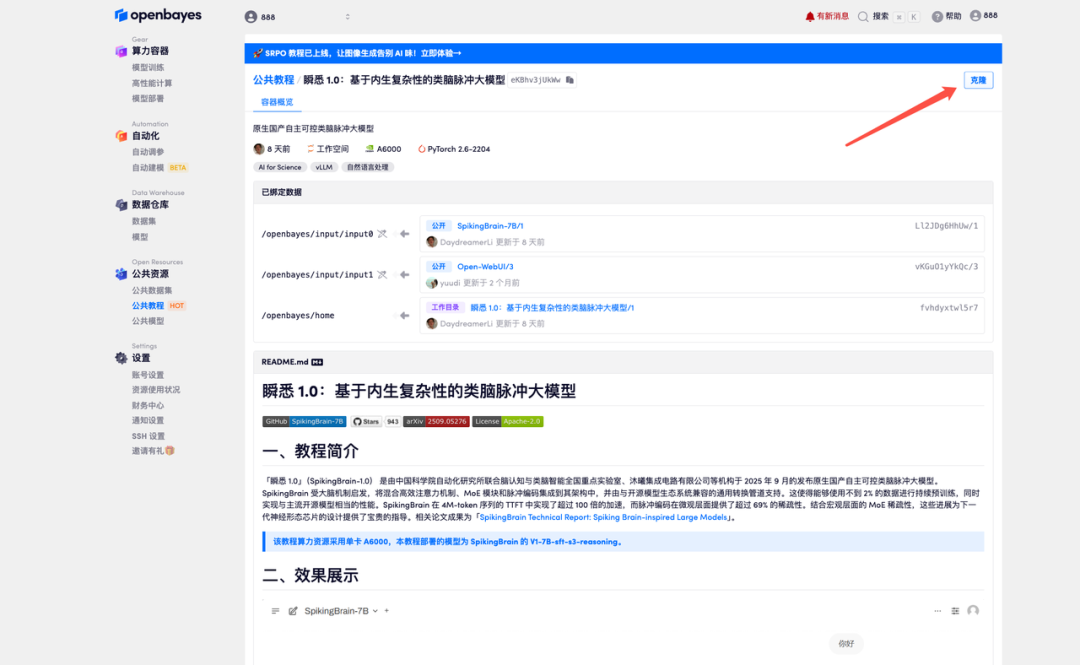
3. Wählen Sie die NVIDIA RTX A6000 48 GB und PyTorch-Images aus und klicken Sie auf „Weiter“. Die OpenBayes-Plattform bietet vier Abrechnungsoptionen: Pay-as-you-go oder Tages-/Wochen-/Monatstarife. Neue Benutzer können sich über den unten stehenden Einladungslink registrieren und erhalten 4 Stunden kostenlose RTX 4090 und 5 Stunden kostenlose CPU-Zeit!
Exklusiver Einladungslink von HyperAI (kopieren und im Browser öffnen):
https://openbayes.com/console/signup?r=Ada0322_NR0n
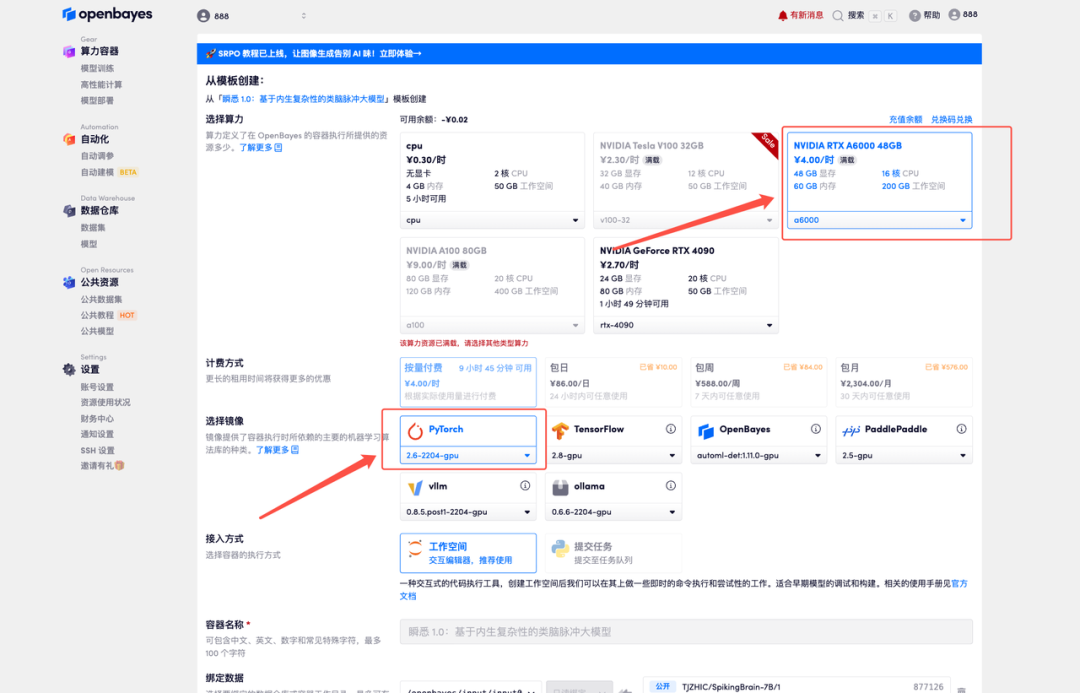
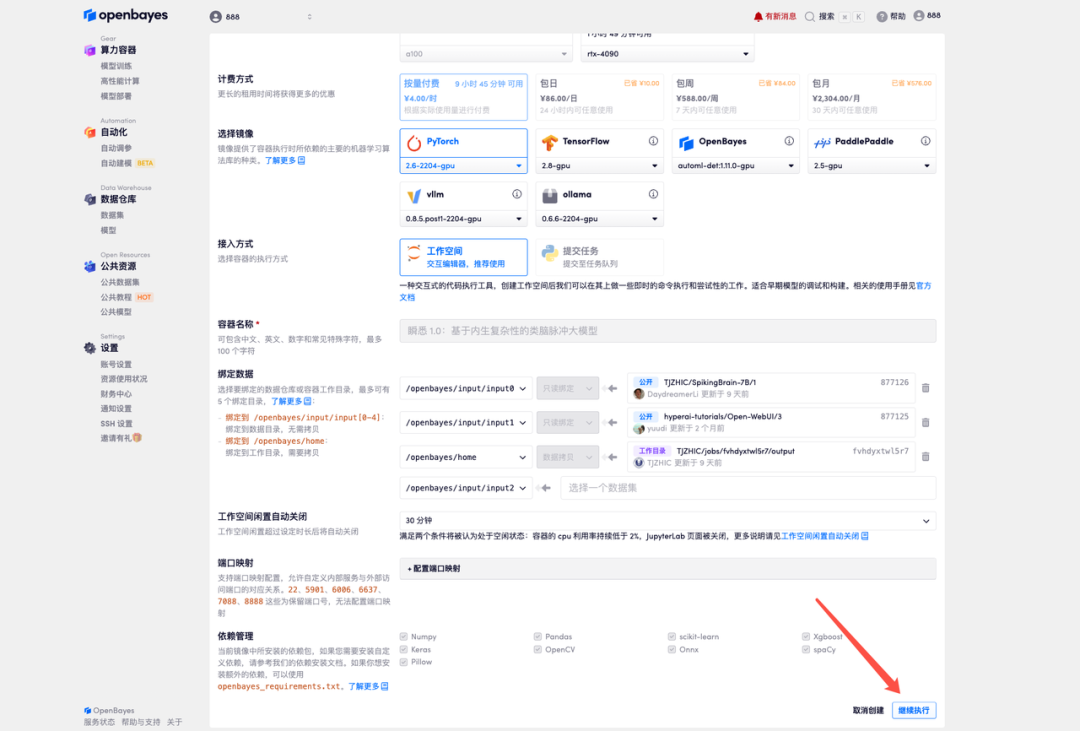
4. Warten Sie, bis die Ressourcen zugewiesen sind. Der erste Klonvorgang dauert etwa 3 Minuten. Wenn der Status auf „Läuft“ wechselt, klicken Sie auf den Pfeil neben „API-Adresse“, um zur Demoseite zu gelangen. Bitte beachten Sie, dass Benutzer vor der Verwendung der API-Adresse eine Echtnamen-Authentifizierung durchführen müssen.
5. Geben Sie die Frage in das Dialogfeld ein, um mit der Beantwortung zu beginnen.
Effektdemonstration
Ich habe die Frage „Zeigen Sie mir einen Codeausschnitt des Sticky Headers einer Website in CSS und JavaScript.“ als Beispiel gestellt. Das Ergebnis ist in der folgenden Abbildung dargestellt:

Das Obige ist das diesmal von HyperAI empfohlene Tutorial. Jeder ist herzlich eingeladen, vorbeizukommen und es auszuprobieren!
Link zum Tutorial:








