Command Palette
Search for a command to run...
Qwen3-Max Verfügt Über Mehr Als Eine Billion Parameter, Erreicht SOTA Bei Mehreren Benchmarks Und Eine Durch Vorhergesagte Inferenz Verbesserte Version, Die Bei Der Mathematik-Olympiade Die Volle Punktzahl erreicht.

Heute (24. September) wurde die jährliche Yunqi-Konferenz offiziell eröffnet. Auf dieser Bühne, auf der Alibaba Cloud seine Stärken unter Beweis stellt, ist KI zweifellos der Protagonist. Von Open-Source-Modellen über Agentenanwendungen bis hin zu Infrastruktur wie Servern und dem Entwickler-Ökosystem hat das Unternehmen in dieser Runde des KI-Wettbewerbs seine technologische Wettbewerbsfähigkeit voll unter Beweis gestellt.Laut der Hugging Face-Liste hat die Zahl der auf Basis von Tongyi Qianwen entwickelten abgeleiteten Modelle 170.000 erreicht, übertrifft damit die amerikanische Llama-Serie und belegt den ersten Platz weltweit.
Leser, die Alibaba verfolgen, wissen vielleicht, dass Alibabas Tongyi Big Model-Team nur einen Tag vor der Eröffnung der Yunqi-Konferenz bereits drei Hochleistungsmodelle als Open Source veröffentlicht hat: das native omnimodale Big Model Qwen3-Omni, das Sprachgenerierungsmodell Qwen3-TTS und das Bildbearbeitungsmodell Qwen-Image-Edit-2509. Alle drei haben in ihren jeweiligen Bereichen eine Leistung erreicht, die mit Mainstream-Modellen oder sogar SOTA-Niveau vergleichbar ist.
Doch das scheint nur ein Vorgeschmack zu sein. Bei der Eröffnungszeremonie der gerade zu Ende gegangenen Yunqi-Konferenz wurde der Qwen3-Max offiziell vorgestellt. Dieses Modell gilt als das bisher größte und leistungsstärkste. Mit einem Gesamtmodellparameter von 1T hat es mehrere Benchmarks erfolgreich bestanden. Darüber hinausAuf der Konferenz wurden auch Modelle wie Qwen3-VL und Qwen3-Coder vorgestellt.
Qwen3-Max: Der bisher größte und leistungsstärkste
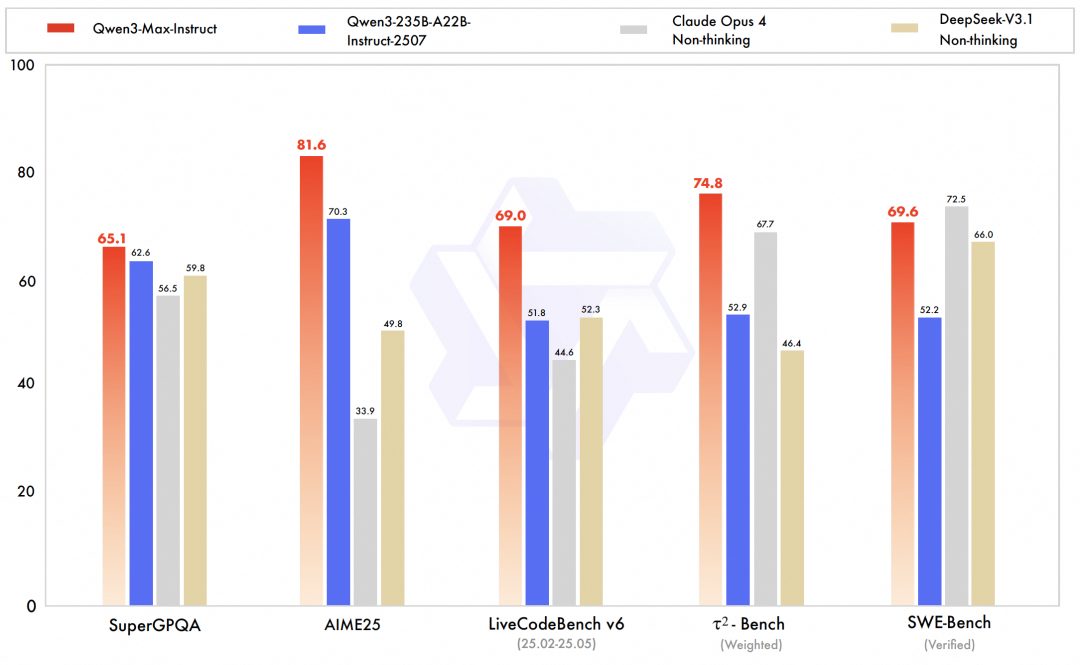
Qwen3-Max ist das unbestrittene Highlight dieser Version. Als bisher größtes und leistungsfähigstes Modell des Teams belegte die Vorschauversion von Qwen3-Max-Instruct den dritten Platz in der LMArena-Text-Bestenliste und übertraf damit GPT-5-Chat.Die offizielle Version verbessert die Code- und Agentenfähigkeiten weiter und erreicht das SOTA-Niveau in umfassenden Benchmarktests, die Wissen, logisches Denken, Programmierung, Befolgen von Anweisungen, Ausrichtung auf menschliche Präferenzen, intelligente Agentenaufgaben und Mehrsprachenverständnis abdecken.Beispielsweise erreichte Qwen3-Max-Instruct beim SWE-Bench Verified-Benchmark, der sich auf die Lösung realer Programmierherausforderungen konzentriert, ein hervorragendes Ergebnis von 69,6 Punkten. Beim Tau2-Bench-Benchmark, der die Tool-Aufruffähigkeiten intelligenter Agenten bewertet, übertraf Qwen3-Max-Instruct Claude Opus 4 und DeepSeek-V3.1 mit einem Ergebnis von 74,8 Punkten.
Insbesondere überschreiten die Gesamtparameter des Qwen3-Max-Modells 1T und 36T-Token werden für das Vortraining verwendet.Die Modellarchitektur folgt dem MoE-Modelldesign der Qwen3-Serie und nutzt den globalen Batch-Lastausgleich, um einen stabilen und reibungslosen Verlust vor dem Training zu gewährleisten. Das Training erfolgt nahtlos, ohne Verlustspitzen oder Anpassungen wie Trainings-Rollback oder Änderungen der Datenverteilung.
Laut offizieller Einführung wurde die Trainingseffizienz von Qwen3-Max-Base durch die Optimierung der effizienten mehrstufigen Pipeline-Parallelstrategie von PAI-FlashMoE deutlich verbessert und die MFU im Vergleich zu Qwen2.5-Max-Base um 30% gesteigert. Im Szenario des Langsequenz-Trainings nutzte das Team zusätzlich die ChunkFlow-Strategie, um einen dreimal höheren Durchsatz als bei der sequenzparallelen Lösung zu erzielen und so das Training des 1M langen Qwen3-Max-Kontexts zu unterstützen. Gleichzeitig wurde durch verschiedene Maßnahmen wie SanityCheck, EasyCheckpoint und Scheduling-Link-OptimierungDer durch Hardwarefehler verursachte Zeitverlust in Qwen3-Max auf einem großen Cluster wird auf ein Fünftel des Zeitverlusts in Qwen2.5-Max reduziert.
Es ist erwähnenswert, dass die um das logische Denken erweiterte Version von Qwen3-Max, Qwen3-Max-Thinking, zwar noch nicht offiziell angekündigt wurde, die Fähigkeiten des tiefen logischen Denkens jedoch laut den vom Team veröffentlichten Daten einen neuen Höchststand erreicht haben und bei den äußerst anspruchsvollen mathematischen Denk-Benchmarks AIME 25 und HMMT die volle Punktzahl erreicht haben und sogar beim Olympischen Mathematik-Wettbewerb die volle Punktzahl erreicht haben.
Qwen3-VL-235B: Erfrischendes SOTA und weltweiter Spitzenplatz
Qwen3-VL ist ein multimodaler Vision-Language-Modellzweig (VLM) innerhalb der Qwen3-Reihe. Ziel ist es, ein Gleichgewicht und einen Durchbruch zwischen visuellem Verständnis und Textgenerierungsfähigkeiten zu erreichen. Das Team bezeichnet es als das bisher leistungsstärkste Vision-Language-Modell der Qwen-Reihe. Qwen3-VL zeigt signifikante Verbesserungen beim Verstehen und Generieren von reinem Text, bei der Wahrnehmung und Argumentation visueller Inhalte, bei der Unterstützung der Kontextlänge, beim Verstehen räumlicher Beziehungen und dynamischer Videos sowie bei der Leistung während der Agenteninteraktion.
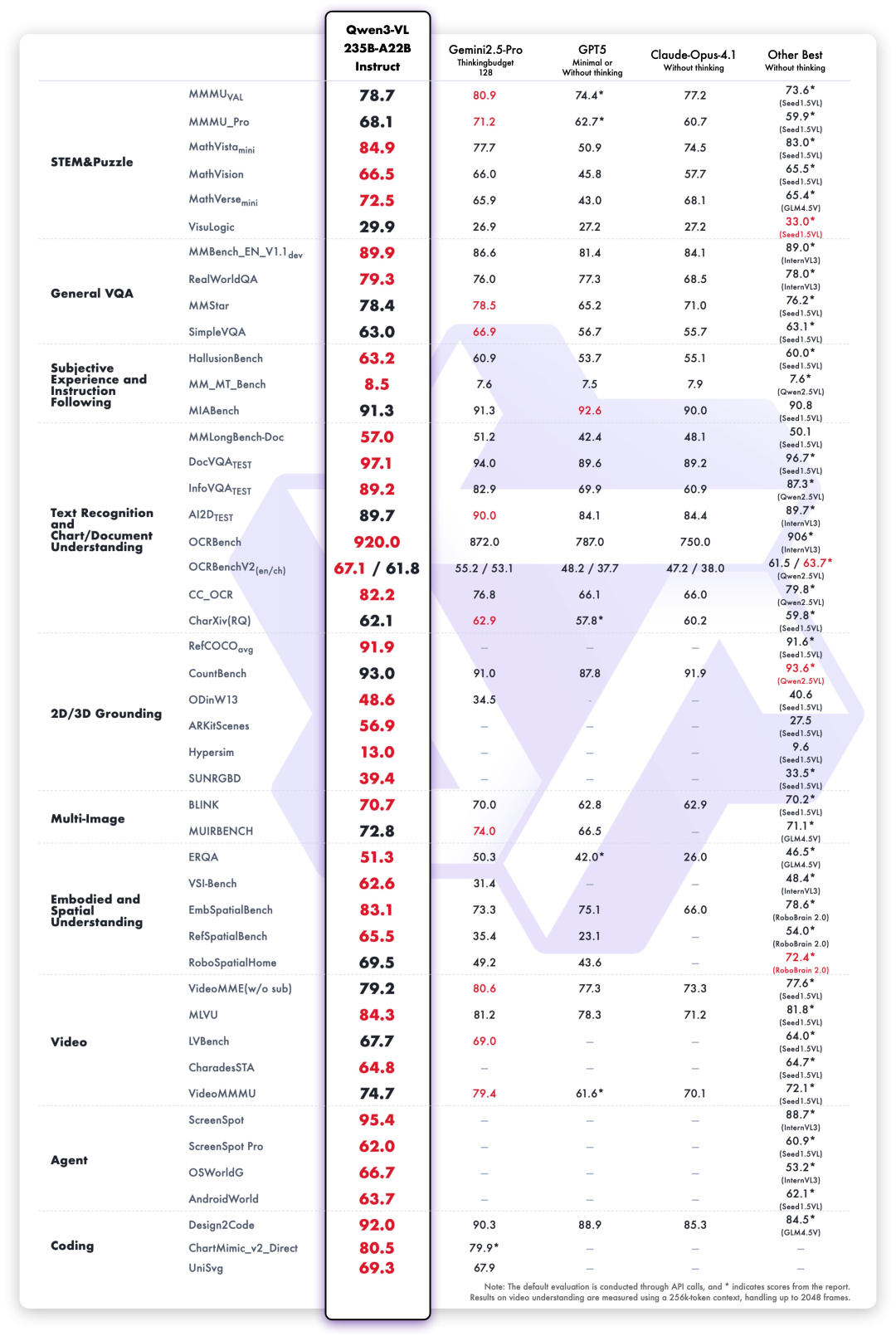
Das neue Open-Source-Flaggschiffmodell Qwen3-VL-235B, das dieses Mal veröffentlicht wurde, belegt hinsichtlich der Gesamtleistung den ersten Platz weltweit und hat seine Leistung bei hochauflösenden komplexen Bildern und feinkörnigen Erkennungsszenen deutlich verbessert.Es enthält sowohl eine Instruct- als auch eine Thinking-Version.
Unter der Bewertung von 10 Dimensionen, darunter umfassende Universitätsfragen, mathematisches und wissenschaftliches Denken, Logikrätsel, allgemeine visuelle Fragenbeantwortung, subjektive Erfahrung und Befolgen von Anweisungen, mehrsprachige Texterkennung und Diagrammdokumentanalyse,Qwen3-VL-235B-A22B-Instruct schneidet bei den meisten Indikatoren unter den Nicht-Inferenzmodellen am besten ab.Es übertrifft Closed-Source-Modelle wie Gemini 2.5 Pro und GPT-5 deutlich und verbessert gleichzeitig die besten Ergebnisse von Open-Source-Multimodalmodellen. Dabei demonstriert es seine starke Generalisierungsfähigkeit und umfassende Leistung bei komplexen visuellen Aufgaben.
Insbesondere wurde Qwen3-VL in mehreren wichtigen Leistungsdimensionen systematisch verbessert:
Visueller Agent:Qwen3-VL kann Computer- und Mobiltelefonschnittstellen bedienen, GUI-Elemente identifizieren, Tastenfunktionen verstehen, Tools aufrufen und Aufgaben ausführen. Es hat bei Benchmarks wie OS World weltweit führende Werte erreicht und kann seine Leistung bei feinkörnigen Wahrnehmungsaufgaben durch den Aufruf von Tools effektiv verbessern.
Die Klartextfunktionen können mit denen der besten Sprachmodelle mithalten:Qwen3-VL nutzt gemischte Text- und Bildmodalitäten für kollaboratives Training in den frühen Phasen des Vortrainings und stärkt so kontinuierlich seine Textfähigkeiten. Letztendlich ist seine Leistung bei reinen Textaufgaben vergleichbar mit der des Flaggschiff-Reintextmodells Qwen3-235B-A22B-2507. Es handelt sich um ein visuelles Sprachmodell der nächsten Generation mit einer soliden Textgrundlage und multimodaler Vielseitigkeit.
Die Möglichkeiten zur visuellen Codierung wurden erheblich verbessert:Implementieren Sie Code zur Bild- und Videogenerierung. Wenn Sie beispielsweise eine Konstruktionszeichnung sehen, generiert der Code Draw.io/HTML/CSS/JS-Code und realisiert so die visuelle Programmierung nach dem Motto „What you see is what you get“.
Die räumliche Wahrnehmungsfähigkeit wird deutlich verbessert:Die 2D-Erdung wechselt von absoluten Koordinaten zu relativen Koordinaten und unterstützt die Beurteilung der Objektausrichtung, Perspektivänderungen und Okklusionsbeziehungen. Sie kann eine 3D-Erdung erreichen und die Grundlage für räumliches Denken und verkörperte Szenen in komplexen Szenarien legen.
Lange Kontextunterstützung und langes Videoverständnis:Die gesamte Modellfamilie unterstützt nativ eine Kontextlänge von 256.000 Token und ist auf eine Million Token skalierbar. Das bedeutet, dass sowohl ein hundertseitiges technisches Dokument, ein ganzes Lehrbuch als auch ein zweistündiges Video vollständig eingegeben, gespeichert und präzise abgerufen werden können. Die sekundengenaue Videoortung wird unterstützt.
Die Fähigkeit zum multimodalen Denken wird deutlich verbessert:Das Thinking-Modell legt den Schwerpunkt auf MINT- und mathematische Denkfähigkeiten. Bei speziellen Themenfragen erfasst das Modell Details, entwirrt komplexe Zusammenhänge, analysiert Ursache und Wirkung und liefert logische, fundierte Antworten. Es hat in renommierten Tests wie MathVision, MMMU und MathVista Spitzenleistungen erzielt.
Die Fähigkeiten zur visuellen Wahrnehmung und Erkennung wurden umfassend verbessert: Durch die Optimierung der Qualität und Breite der vorab trainierten Daten kann das Modell nun eine größere Bandbreite an Objektkategorien erkennen – von Prominenten, Anime-Figuren, Waren, Sehenswürdigkeiten bis hin zu Pflanzen und Tieren – und deckt damit den Bedarf an „Allgemeinerkennung“ im Alltag und im Berufsleben ab.
OCR unterstützt mehr Sprachen und komplexere Szenarien:Die Anzahl der unterstützten Sprachen außer Chinesisch und Englisch wurde von 10 auf 32 erweitert, wodurch mehr Länder und Regionen abgedeckt werden. Die Leistung ist in anspruchsvollen realen Aufnahmeszenarien wie komplexer Beleuchtung, Unschärfe und Neigung stabiler. Die Erkennungsgenauigkeit seltener Zeichen, alter Schriftzeichen und Fachbegriffe wurde ebenfalls deutlich verbessert. Und die Fähigkeit, sehr lange Dokumente zu verstehen und feine Strukturen wiederherzustellen, wurde weiter verbessert.
Qwen3 Coder Plus:ProgrammiereffizienzHöher und präziser
Als exklusives Codiermodell der Qwen3-Serie ist Qwen3 Coder ein umfassendes Upgrade der vorherigen Coder-Generation. Es verwendet eine Closed-Source-API für höhere Programmiereffizienz und -genauigkeit. Es hat sich zu einem der beliebtesten Programmiermodelle weltweit entwickelt und erfreut sich bei Entwicklern großer Beliebtheit.
Der diesmal veröffentlichte Qwen3 Coder Plus ist eine proprietäre Version von Alibabas Open-Source-Qwen3 Coder 480B A35B.Als leistungsstarkes Codieragentenmodell zeichnet es sich durch autonome Programmierung durch Toolaufrufe und Umgebungsinteraktionen aus und kombiniert Codierfunktionen mit einer Vielzahl allgemeiner Funktionen.
Technische Highlights:
* Gemeinsames Training mit Qwen Code- und Claude Code-Systemen verbessert die CLI-Anwendungsleistung erheblich
* Schnellere Denkgeschwindigkeit und effizientere Aufgabenausführung * Verbesserte Codesicherheit, hin zu verantwortungsvoller KI
Auf der offiziellen Website von HyperAI Hyperneural (hyper.ai) wurden zahlreiche hochwertige Open-Source-Modell-Tutorials basierend auf dem Tongyi Qianwen-Team veröffentlicht. Erfahren Sie mehr über den Link zum Ein-Klick-Bereitstellungstutorial: https://hyper.ai/tutorials








