Command Palette
Search for a command to run...
270M Leichtgewicht-Modell! Gemma-3-270M-IT Konzentriert Sich Auf Leichte Langtextinteraktion; Die Erste Wahl Für Plattformübergreifende GUI-Agenten! AgentNet Deckt Über 200 Websites Ab

Da der Umfang großer Modellparameter weiter zunimmt, divergieren die Anforderungen der Benutzer an die KI-Nutzung allmählich: Einerseits benötigen sie leistungsstarke Modelle zur Bewältigung komplexer Aufgaben, andererseits wünschen sie sich ein einfaches und praktisches Gesprächserlebnis in einer Umgebung mit geringem Rechenaufwand. In langen Textgesprächen und alltäglichen AufgabenszenarienHerkömmliche große Modelle erfordern nicht nur eine hohe Rechenleistung, sondern sind auch anfällig für Reaktionsverzögerungen, Kontextverlust oder Probleme bei der inkohärenten Generierung. Daher ist die Frage, ob leichte Modelle „verwendbar, einfach zu verwenden und gut lauffähig“ sind, ein Problem, das dringend angegangen werden muss.
Auf dieser Grundlage hat Google das leichtgewichtige Feinabstimmungsmodell für Anweisungen Gemma-3-270M-IT auf den Markt gebracht.Es verfügt zwar nur über 270 Millionen Parameter, kann aber problemlos in einer Umgebung mit einer einzelnen Karte und 1 GB Videospeicher ausgeführt werden, wodurch die Schwelle für eine lokale Bereitstellung erheblich gesenkt wird.Es unterstützt außerdem ein 32K-Token-Kontextfenster und ist somit für die Verarbeitung langer Textkonversationen und Dokumente geeignet. Durch spezielle Feinabstimmungen für alltägliche Frage-und-Antwort-Sitzungen und einfache Aufgaben gewährleistet das Gemma-3-270M-IT einen leichten und effizienten Betrieb und gleicht gleichzeitig die Praktikabilität der Konversationsinteraktion aus.
Gemma-3-270M-IT zeigt einen weiteren Entwicklungspfad: Neben dem Trend „größer und stärker“,Durch die Unterstützung leichter und langer Kontexte bietet es neue Möglichkeiten für die Edge-Bereitstellung und inklusive Anwendungen.
Auf der offiziellen Website von HyperAI Hyperneuron wurde die Funktion „vLLM + Open WebUI deployment gemma-3-270m-it“ eingeführt. Kommen Sie vorbei und probieren Sie es aus!
Online-Nutzung:https://go.hyper.ai/kBjw3
Hier ist ein kurzer Überblick über die Updates der offiziellen Website von hyper.ai vom 25. bis 29. August:
* Hochwertige öffentliche Datensätze: 12
* Hochwertige Tutorial-Auswahl: 4
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 6 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im September: 5
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Nemotron-Post-Training-Dataset-v2 Post-Training-Datensatz
Nemotron-Post-Training-Dataset-v2 ist eine Erweiterung des bestehenden Post-Training-Korpus von NVIDIA. Dieser Datensatz erweitert SFT- und RL-Daten auf fünf Zielsprachen (Spanisch, Französisch, Deutsch, Italienisch und Japanisch) und deckt Szenarien wie Mathematik, Codierung, MINT (Mathematik, Informatik, Naturwissenschaften und Technik) und Konversation ab.
Direkte Nutzung: https://go.hyper.ai/lSIjR
2. Nemotron-CC-v2-Vortrainingsdatensatz
Nemotron-CC-v2 fügt dem ursprünglichen englischen Webseitenkorpus acht Common Crawl-Snapshots aus den Jahren 2024–2025 hinzu und führt eine globale Deduplizierung und englische Filterung durch. Außerdem verwendet es Qwen3-30B-A3B, um Webseiteninhalte zu synthetisieren und neu zu formulieren, ergänzt mit abwechslungsreichen Fragen und Antworten und übersetzt sie zusätzlich in 15 Sprachen, um das mehrsprachige logische Denken und das Vortraining des Allgemeinwissens zu stärken.
Direkte Nutzung: https://go.hyper.ai/xRtbR
3.Nemotron-Pretraining-Dataset-Beispiel-Sampling-Dataset
Das Nemotron-Pretraining-Dataset-Sample enthält 10 repräsentative Teilmengen, die aus verschiedenen Komponenten des vollständigen SFT- und Pretraining-Korpus ausgewählt wurden und hochwertige Frage-Antwort-Daten, mathematisch fokussierte Auszüge, Code-Metadaten und Anweisungsdaten im SFT-Stil abdecken, die für Überprüfungen und schnelle Experimente geeignet sind.
Direkte Nutzung: https://go.hyper.ai/xzwY5
4. Nemotron-Pretraining-Code-v1-Code-Datensatz
Nemotron-Pretraining-Code-v1 ist ein umfangreicher, kuratierter Code-Datensatz, der auf GitHub erstellt wurde. Dieser Datensatz wurde durch mehrstufige Deduplizierung, Lizenzdurchsetzung und heuristische Qualitätsprüfungen gefiltert und enthält LLM-generierte Code-Frage-Antwort-Paare in elf Programmiersprachen.
Direkte Verwendung: https://go.hyper.ai/DRWAw
5. Nemotron-Pretraining-SFT-v1 überwachter Feinabstimmungsdatensatz
Nemotron-Pretraining-SFT-v1 ist für MINT-Fächer, akademische Bereiche, logisches Denken und mehrsprachige Szenarien konzipiert. Es basiert auf hochwertigen mathematischen und wissenschaftlichen Materialien und kombiniert akademische Texte auf Hochschulniveau mit vortrainierten SFT-Daten, um komplexe Multiple-Choice- und analytische Fragen (mit vollständigen Antworten/Gedanken) zu konstruieren, die eine Vielzahl von Aufgaben abdecken, darunter Mathematik, Programmierung, Allgemeinwissen und logisches Denken.
Direkte Nutzung: https://go.hyper.ai/g568w
6. Nemotron-CC-Math Mathematik-Vortrainingsdatensatz
Nemotron-CC-Math ist ein hochwertiger, umfangreicher, vortrainierter Datensatz mit Schwerpunkt Mathematik. Der Datensatz enthält 133 Milliarden Token, bewahrt die Struktur von Gleichungen und Code und vereinheitlicht gleichzeitig den mathematischen Inhalt in einem editierbaren LaTeX-Format. Dies ist der erste Datensatz, der zuverlässig eine breite Palette mathematischer Formate (einschließlich Long-Tail-Formate) im Web abdeckt.
Direkte Nutzung: https://go.hyper.ai/aEGc4
7. Echo-4o-Image – Datensatz zur synthetischen Bildgenerierung
Der von GPT-4o generierte Echo-4o-Image-Datensatz enthält rund 179.000 Beispiele aus drei verschiedenen Aufgabentypen: komplexe Anweisungsausführung (rund 68.000 Beispiele), hyperrealistische Fantasiegenerierung (rund 38.000 Beispiele) und Multireferenz-Bildgenerierung (rund 73.000 Beispiele). Jedes Beispiel besteht aus einem 2×2-Bildraster mit einer Auflösung von 1024×1024, das strukturierte Informationen über den Bildpfad, Merkmale (Attribute/Subjekte) und die generierte Eingabeaufforderung enthält.
Direkte Nutzung: https://go.hyper.ai/uLJEh

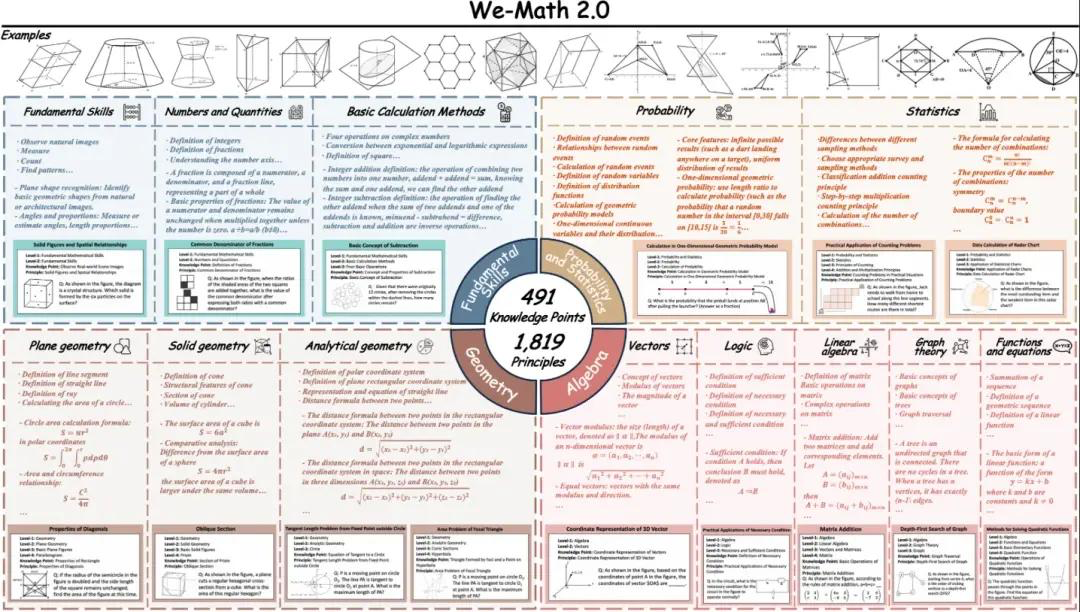
8. We-Math2.0-Standard-Benchmark-Datensatz für visuelles mathematisches Denken
We-Math2.0-Standard etabliert einen einheitlichen Kennzeichnungsraum für 1.819 präzise definierte Prinzipien. Jede Aufgabe ist explizit mit dem Prinzip gekennzeichnet und sorgfältig kuratiert, wodurch eine breite und ausgewogene Abdeckung erreicht wird, insbesondere durch die Verbesserung bisher unterrepräsentierter mathematischer Teilgebiete und Aufgabentypen. Der Datensatz nutzt ein duales Erweiterungsdesign: mehrere Abbildungen pro Aufgabe und mehrere Fragen pro Abbildung.
Direkte Nutzung: https://go.hyper.ai/VlqK1
9. AgentNet Desktop Operation Task-Datensatz
AgentNet ist der erste groß angelegte Datensatz zur Agenten-Nutzung von Desktop-Computern. Er wurde entwickelt, um plattformübergreifende GUI-Manipulationsagenten und Vision-Language-Action-Modelle zu unterstützen und zu bewerten. Der Datensatz enthält 22,6.000 manuell annotierte Computer-Nutzungs-Task-Trajektorien unter Windows, macOS und Ubuntu sowie über 200 Anwendungen und Websites. Die Szenarien lassen sich in vier Kategorien einteilen: Büro, Beruf, Alltag und Systemnutzung.
Direkte Nutzung: https://go.hyper.ai/3DGDs
10. WideSearch-Benchmark-Datensatz zur Informationserfassung
WideSearch ist der erste Benchmark-Datensatz, der speziell für die großflächige Informationssammlung entwickelt wurde. Der Benchmark besteht aus 200 hochwertigen Fragen (100 auf Englisch und 100 auf Chinesisch), die sorgfältig ausgewählt und manuell aus echten Benutzeranfragen bereinigt wurden. Diese Fragen stammen aus über 15 verschiedenen Domänen.
Direkte Nutzung: https://go.hyper.ai/36kKj
11. MCD-Datensatz zur multimodalen Codegenerierung
MCD enthält rund 598.000 hochwertige Beispiele/Paare, organisiert in einem befehlsorientierten Format. Es deckt eine Vielzahl von Eingabemodalitäten (Text, Bilder, Code) und Ausgabemodalitäten (Code, Antworten, Erklärungen) ab und eignet sich daher für multimodale Codeverständnis- und -generierungsaufgaben. Die Daten umfassen: erweiterten HTML-Code, Diagramme, Fragen und Antworten sowie Algorithmen.
Direkte Nutzung: https://go.hyper.ai/yMPeD
12. Llama-Nemotron-Post-Training-Dataset Post-Training-Datensatz
Der Llama-Nemotron Post-Training-Datensatz ist ein umfangreicher Post-Training-Datensatz, der die mathematischen, Code-, allgemeinen Denk- und Anweisungsfähigkeiten der Llama-Nemotron-Modellfamilie während der Post-Training-Phasen (z. B. SFT und RL) verbessern soll. Dieser Datensatz kombiniert Daten aus den Phasen der überwachten Feinabstimmung und des bestärkenden Lernens.
Direkte Nutzung: https://go.hyper.ai/Vk0Pk
Ausgewählte öffentliche Tutorials
1. Microsoft VibeVoice-1.5B definiert die TTS-Technologie neuGrenze
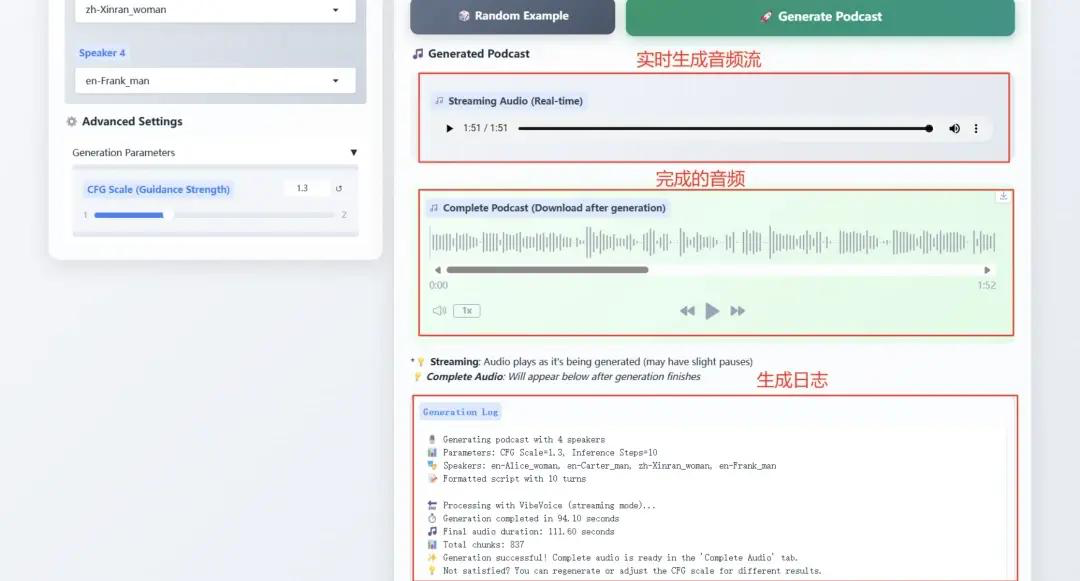
VibeVoice-1.5B ist ein neues Text-to-Speech-Modell (TTS), das ausdrucksstarke, lange Konversations-Audios mit mehreren Sprechern, wie z. B. Podcasts, generiert. VibeVoice verarbeitet lange Audiosequenzen effizient und bei gleichzeitig hoher Wiedergabetreue und unterstützt die Synthese von bis zu 90 Minuten Sprache mit bis zu vier verschiedenen Sprechern.
Online-Betrieb:https://go.hyper.ai/Ofjb1
2. vLLM + Open WebUI deploy NVIDIA-Nemotron-Nano-9B-v2
NVIDIA-Nemotron-Nano-9B-v2 kombiniert auf innovative Weise die effiziente Verarbeitung langer Sequenzen von Mamba mit den leistungsstarken semantischen Modellierungsfunktionen von Transformer und erreicht so die Unterstützung von 128.000 ultralangen Kontexten mit nur 9 Milliarden (9B) Parametern. Seine Inferenzeffizienz und Aufgabenleistung auf Edge-Computing-Geräten (wie GPUs der RTX 4090-Klasse) sind mit modernsten Modellen mit derselben Parameterskala vergleichbar.
Online ausführen: https://go.hyper.ai/cVzPp
3. vLLM + Offene WebUI-Bereitstellung gemma-3-270m-it
gemma-3-270m-it basiert auf 270M (270 Millionen) Parametern und konzentriert sich auf effiziente Konversationsinteraktion und schlanke Implementierung. Dieses schlanke und effiziente Modell benötigt nur über 1 GB Grafikspeicher auf einer einzigen Grafikkarte und eignet sich daher für Edge-Geräte und ressourcenarme Szenarien. Das Modell unterstützt mehrstufige Konversationen und ist speziell auf alltägliche Fragen und Antworten sowie einfache Aufgabenanweisungen abgestimmt. Es konzentriert sich auf Textgenerierung und -verständnis und unterstützt ein Kontextfenster mit 32.000 Token, wodurch es auch lange Textkonversationen verarbeiten kann.
Online ausführen: https://go.hyper.ai/kBjw3

4. vLLM+Open WebUI Deployment Seed-OSS-36B-Anweisung
Seed-OSS-36B-Instruct verwendete 12 Billionen (12 Terabyte) Token für das Training und erzielte hervorragende Leistungen bei mehreren gängigen Open-Source-Benchmarks. Eines seiner repräsentativsten Merkmale ist die native Long-Context-Fähigkeit mit einer maximalen Kontextlänge von 512.000 Token. Dadurch kann es extrem lange Dokumente und Argumentationsketten ohne Leistungseinbußen verarbeiten. Diese Länge ist doppelt so lang wie die der neuesten GPT-5-Modellfamilie von OpenAI und entspricht etwa 1.600 Textseiten.
Online ausführen: https://go.hyper.ai/aKw9w

💡Wir haben außerdem eine Austauschgruppe für Tutorials zur stabilen Diffusion eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~

Die Zeitungsempfehlung dieser Woche
1. Mehr als Pass@1: Selbstspiel mit Variationsproblemsynthese unterstützt RLVR
Dieses Papier schlägt eine Synthesestrategie für selbstspielende Variationsprobleme vor, um das verifizierbare Belohnungsverstärkungslernen für große Sprachmodelle zu verbessern. Während traditionelles RLVR Pass@1 verbessert, reduziert es die Generationsvielfalt aufgrund des Entropiekollapses und schränkt so die Pass@k-Leistung ein. SvS mildert den Entropiekollaps und erhält die Trainingsvielfalt durch die Synthese äquivalenter Variationsprobleme basierend auf korrekten Lösungen.
Link zum Artikel: https://go.hyper.ai/IU71P
2. Memento: Feinabstimmung von LLM-Agenten ohne Feinabstimmung von LLMs
Dieser Artikel schlägt ein neuartiges Lernparadigma für adaptive Agenten großer Sprachmodelle vor, das die Feinabstimmung des zugrunde liegenden LLM überflüssig macht. Bestehende Methoden weisen häufig zwei Einschränkungen auf: Sie sind entweder zu starr oder rechenintensiv. Das Forschungsteam erreicht eine kostengünstige kontinuierliche Anpassung durch gedächtnisbasiertes Online-Verstärkungslernen. Sie formalisieren diesen Prozess als gedächtnisgestützten Markov-Entscheidungsprozess (M-MDP) und führen eine neuronale Fallauswahlstrategie zur Steuerung von Handlungsentscheidungen ein.
Link zum Artikel: https://go.hyper.ai/sl9Yj
3. TreePO: Überbrückung der Lücke zwischen Richtlinienoptimierung und Wirksamkeit sowie Inferenzeffizienz mit heuristischer baumbasierter Modellierung
Dieses Papier stellt TreePO vor, einen selbstgesteuerten Rollout-Algorithmus, der die Sequenzgenerierung als baumartigen Suchprozess behandelt. TreePO basiert auf einer dynamischen Baum-Sampling-Strategie und Segmentdekodierung mit fester Länge und nutzt lokale Unsicherheiten zur Generierung zusätzlicher Zweige. Durch die Amortisierung des Rechenaufwands über gemeinsame Präfixe und das frühzeitige Beschneiden von Pfaden mit geringem Wert reduziert TreePO effektiv den Rechenaufwand jedes Updates und erhält oder verbessert gleichzeitig die Explorationsvielfalt.
Link zum Artikel: https://go.hyper.ai/J8tKk
4. Technischer Bericht zu VibeVoice
Dieses Dokument stellt ein neuartiges Sprachsynthesemodell namens VibeVoice vor, das lange, mehrsprachige Sprachsequenzen auf Basis der Next-Token-Diffusion generiert. Der kontinuierliche Sprach-Tokenizer erreicht eine 80-fach verbesserte Komprimierungsrate im Vergleich zu Encodec und verbessert so die Effizienz der Verarbeitung langer Sequenzen bei gleichbleibender Klangqualität deutlich. Das Modell unterstützt die Synthese von bis zu 90 Minuten Konversation für bis zu vier Sprecher in einem 64k-Kontext, stellt die Kommunikationsatmosphäre authentisch nach und übertrifft bestehende Open-Source- und kommerzielle Modelle.
Link zum Artikel: https://go.hyper.ai/pokVi
5. CMPhysBench: Ein Benchmark zur Bewertung großer Sprachmodelle in der Festkörperphysik
In diesem Artikel wird CMPhysBench vorgestellt, ein neuartiger Benchmark zur Bewertung der Leistungsfähigkeit großer Sprachmodelle in der Festkörperphysik. CMPhysBench besteht aus über 520 sorgfältig zusammengestellten Problemen auf Graduiertenniveau, die repräsentative Teilgebiete und grundlegende theoretische Rahmenbedingungen der Festkörperphysik abdecken, wie z. B. Magnetismus, Supraleitung und stark korrelierte Systeme.
Link zum Artikel: https://go.hyper.ai/uo8de
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
Bei der dritten „AI for Bioengineering Summer School“, die von der Shanghai Jiao Tong University veranstaltet wurde, teilte Li Mingchen, Postdoktorand in der Forschungsgruppe von Hong Liang am Institut für Naturwissenschaften der Shanghai Jiao Tong University, unter dem Motto „Protein and Genome Basic Model“ die neuesten Forschungsfortschritte und technologischen Durchbrüche im Bereich des Basismodells von Proteinen und Genomen mit allen.
Den vollständigen Bericht ansehen: https://go.hyper.ai/Ynjdj
Durch die Kombination von Cheminformatik-Tools mit der neuen organischen Löslichkeitsdatenbank BigSolDB verbesserte das MIT-Forschungsteam die Modellarchitekturen von FASTPROP und CHEMPROP. Das Modell kann nun gleichzeitig gelöste Stoffe und Lösungsmittelmoleküle sowie Temperaturparameter für ein direktes Regressionstraining auf logS eingeben. In einem Szenario mit rigoroser Extrapolation gelöster Stoffe erreichte das optimierte Modell eine zwei- bis dreifache Reduzierung des RMSE und eine 50-fache Steigerung der Inferenzgeschwindigkeit im Vergleich zum hochmodernen Modell von Vermeire et al.
Den vollständigen Bericht ansehen: https://go.hyper.ai/cj9RX
NVIDIA hat die offizielle Markteinführung des Jetson AGX Thor-Entwicklungskits angekündigt. Der Preis beginnt bei 3.499 US-Dollar. Das Thor T5000-Modul ist ab sofort für Unternehmenskunden erhältlich. Jetson AGX Thor, auch als „Robotergehirn“ bezeichnet, soll Millionen von Robotern in Branchen wie Fertigung, Logistik, Transport, Gesundheitswesen, Landwirtschaft und Einzelhandel unterstützen.
Den vollständigen Bericht ansehen: https://go.hyper.ai/1XLXn
Ein Forschungsteam der Fakultät für Chemieingenieurwesen und Angewandte Chemie der Universität Toronto in Kanada hat eine multimodale Methode des maschinellen Lernens vorgeschlagen. Diese nutzt die nach der Synthese von MOFs verfügbaren Informationen: PXRD und die bei der Synthese verwendeten Chemikalien, um MOFs mit Potenzial in anderen Bereichen als den ursprünglich beschriebenen zu identifizieren. Diese Forschung beschleunigt die Verbindung zwischen der Synthese von MOFs und Anwendungsszenarien.
Den vollständigen Bericht ansehen: https://go.hyper.ai/cqX1t
Auf der 2025CCF National High Performance Computing Academic Conference erarbeitete der Forscher Zhang Zhengde, Leiter von AI4S am Rechenzentrum des Instituts für Hochenergiephysik, systematisch den effizienten und qualitativ hochwertigen AI-Ready-Konstruktionsplan für Daten, basierend auf dem aktuellen Stand wissenschaftlicher Daten aus Großanlagen, sowie die Anwendung intelligenter Agenten und Multi-Agenten-Frameworks bei der Datenannotation und -bereitstellung.
Den vollständigen Bericht ansehen: https://go.hyper.ai/u7F9L
Beliebte Enzyklopädieartikel
1. DALL-E
2. Reziproke Sortierfusion RRF
3. Pareto-Front
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kontrastives Lernen
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:https://go.hyper.ai/wiki
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








