Command Palette
Search for a command to run...
Online-Tutorial | NVIDIA Pusht Kleine Modelle: Der Kleine Und Kompakte Nemotron-Nano-9B-v2 Ist 6-mal Schneller Als Qwen3

Hätten Sie sich bei der Einführung großer Sprachmodelle jemals vorstellen können, dass sie eines Tages klein genug sein würden, um in eine Smartwatch zu passen? Heute wird dieser Traum allmählich Wirklichkeit: Geräte wie Smartwatches greifen auf Modelle aus der Cloud zu und ermöglichen so Sprachkonversationen und intelligente Assistenten. Die Herausforderung besteht jedoch nicht nur darin, sie auf kleinen Geräten einzusetzen, sondern auch darin, die Denkfähigkeiten und die Effizienz des Modells beizubehalten und gleichzeitig seine geringe Größe zu bewahren.
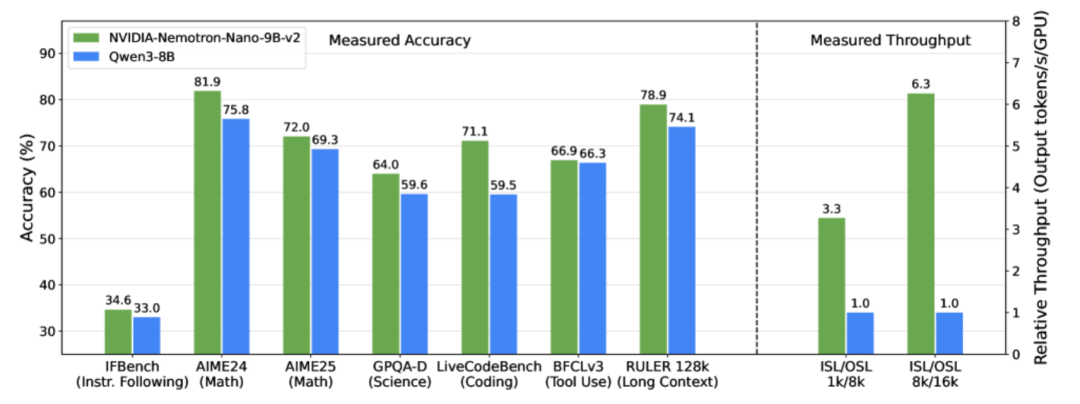
Um dieses Problem zu lösen, hat das NVIDIA-Team am 19. August 2025 das leichtgewichtige große Sprachmodell NVIDIA-Nemotron-Nano-9B-v2 herausgebracht. Als für die Hybridarchitektur optimierte Version der Nemotron-ReiheDieses Modell kombiniert auf innovative Weise die effiziente Verarbeitung langer Sequenzen von Mamba mit den starken semantischen Modellierungsfunktionen von Transformer und ersetzt die meisten Self-Attention-Ebenen durch Mamba-2-Zustandsraumebenen, wodurch das Modell bei der Verarbeitung langer Inferenztrajektorien schneller wird.Mit nur 9 Milliarden Parametern erreicht es die Unterstützung für 128K ultralange Kontexte. Bei komplexen Schlussfolgerungs-Benchmarks erreicht es eine Genauigkeit, die mit der des führenden Open-Source-Modells derselben Größenordnung, Qwen3-8B, vergleichbar oder sogar besser ist, und sein Durchsatz ist im Vergleich zu letzterem bis zu sechsmal höher, was einen großen Durchbruch im Bereich der leichtgewichtigen Bereitstellung und des Langtextverständnisses großer Sprachmodelle darstellt.
Mit anderen Worten: Nemotron-Nano-9B-v2 stellt mehr dar als nur ein „Modell in einem kleinen Gerät“.Stattdessen zielt es darauf ab, leistungsstarke Denkfähigkeiten wirklich leichtgewichtig und für die Öffentlichkeit zugänglich zu machen.Vielleicht können große Sprachmodelle in Zukunft den Menschen jederzeit und überall intelligente Dienste in einer „kleinen und präzisen“ Form zur Verfügung stellen.
Veröffentlichen Sie mehrsprachige Post-Training-Datensätze, um die Modellfunktionen umfassend zu verbessern
Anstatt einfach ein kleines Modell zu erstellen, begann das Forschungsteam mit einem 12B-Parameter-Basismodell, Nemotron-Nano-12B-v2-Base, und trainierte es anhand einer großen Menge kuratierter und synthetischer Daten vor. Um die Schlussfolgerung zu verbessern, wurden außerdem SFT-artige Daten aus mehreren Domänen hinzugefügt.
Anschließend führte das Team ein mehrstufiges Nachtraining durch, darunter SFT (überwachte Feinabstimmung), IFeval RL (Anweisung nach Auswertung), DPO (direkte Präferenzoptimierung) und RLHF (menschliches Feedback-Verstärkungslernen), um das Modell hinsichtlich Mathematik, Code, Tool-Aufrufen und Dialogen mit langem Kontext genauer und robuster zu machen.Der zugehörige Post-Training-Datensatz wurde aktualisiert und als „Nemotron-Post-Training-Dataset-v2“ veröffentlicht.Erweitern Sie SFT- und RL-Daten auf fünf Zielsprachen (Spanisch, Französisch, Deutsch, Italienisch und Japanisch) und decken Sie Szenarien wie Mathematik, Codierung, MINT (Mathematik, Informatik, Naturwissenschaften und Technik) und Dialog ab, um die Argumentations- und Befehlsfolgefähigkeiten des Modells zu verbessern.
Datensatzadresse:
Basierend auf der Minitron-Komprimierungs- und Destillationsstrategie verwendete das Forschungsteam eine leichtgewichtige neuronale Architektursuchmethode, um die Bedeutung von Modellkomponenten (wie jeder Schicht und dem Feedforward-Neuralnetzwerk) zu bewerten und diese anschließend zu bereinigen. Durch Destillation und erneutes Training verfeinerte das Team die Fähigkeiten des ursprünglichen Modells im bereinigten Modell. Schließlich komprimierten sie das 12-Byte-Modell in das 9-Byte-Modell Nemotron-Nano-9B-v2, wodurch der Ressourcenverbrauch deutlich reduziert und gleichzeitig die Inferenzgenauigkeit erhalten blieb.
„Bereitstellung von NVIDIA-Nemotron-Nano-9B-v2 mit vLLM + Open WebUI“ ist jetzt im Abschnitt „Tutorials“ der HyperAI Hyperneuron-Website (hyper.ai) verfügbar. Kommen Sie und erleben Sie die Kommunikation mit diesem „kleinen, aber präzisen“ großen Sprachmodell!
Link zum Tutorial:
Demolauf
1. Geben Sie die URL hyper.ai in Ihren Browser ein. Klicken Sie nach dem Aufrufen der Startseite auf die Seite „Tutorials“, wählen Sie „vLLM + Open WebUI“ aus, um NVIDIA-Nemotron-Nano-9B-v2 bereitzustellen, und klicken Sie auf „Dieses Tutorial online ausführen“.
2. Klicken Sie nach dem Seitensprung oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
3. Wählen Sie die NVIDIA RTX A6000 48 GB und PyTorch-Images aus und klicken Sie auf „Weiter“. Die OpenBayes-Plattform bietet vier Abrechnungsoptionen: Pay-as-you-go oder Tages-/Wochen-/Monatstarife. Neue Benutzer können sich über den unten stehenden Einladungslink registrieren und erhalten 4 Stunden kostenlose RTX 4090 und 5 Stunden kostenlose CPU-Zeit!
Exklusiver Einladungslink von HyperAI (kopieren und im Browser öffnen):
https://openbayes.com/console/signup?r=Ada0322_NR0n
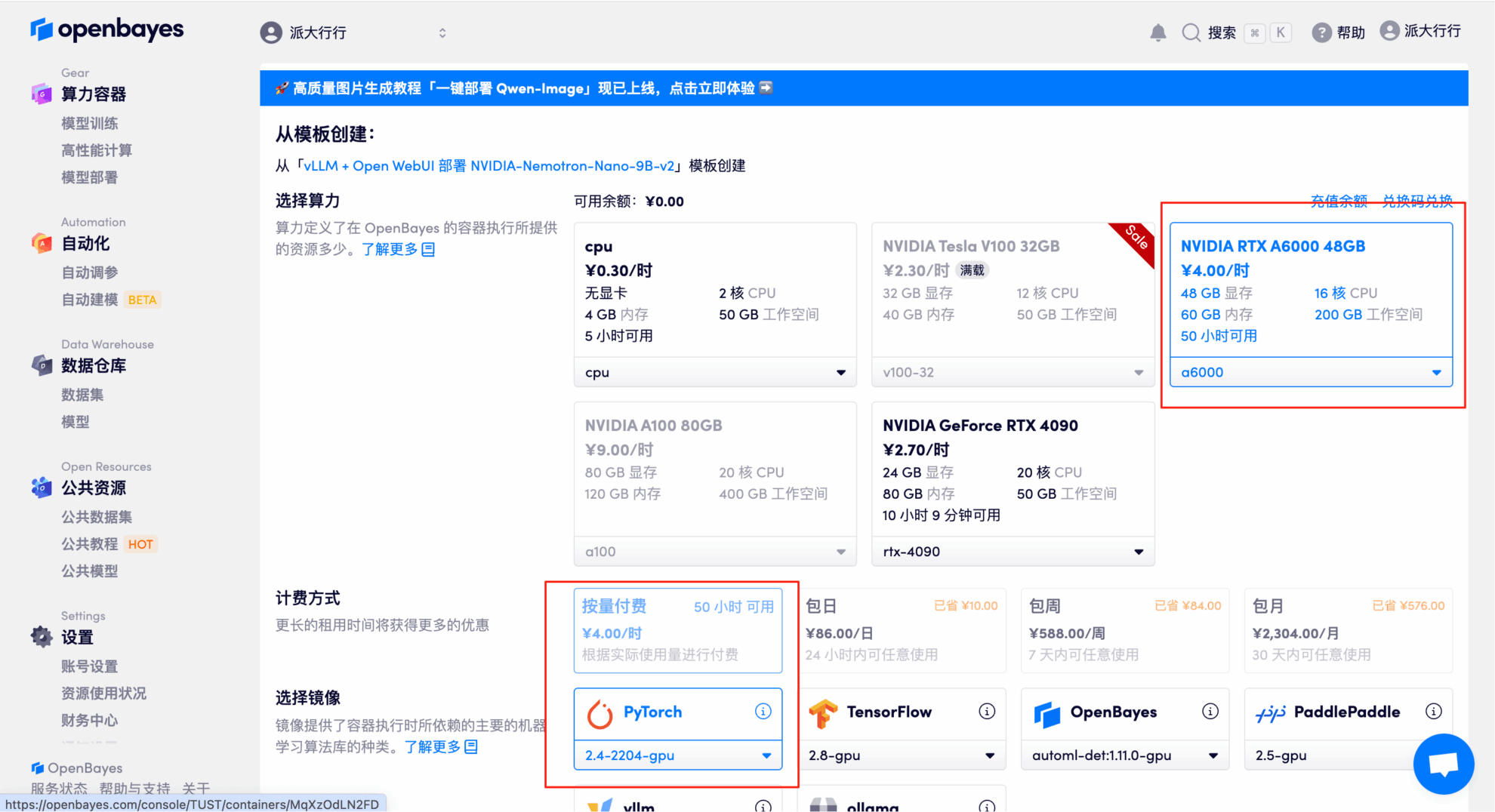
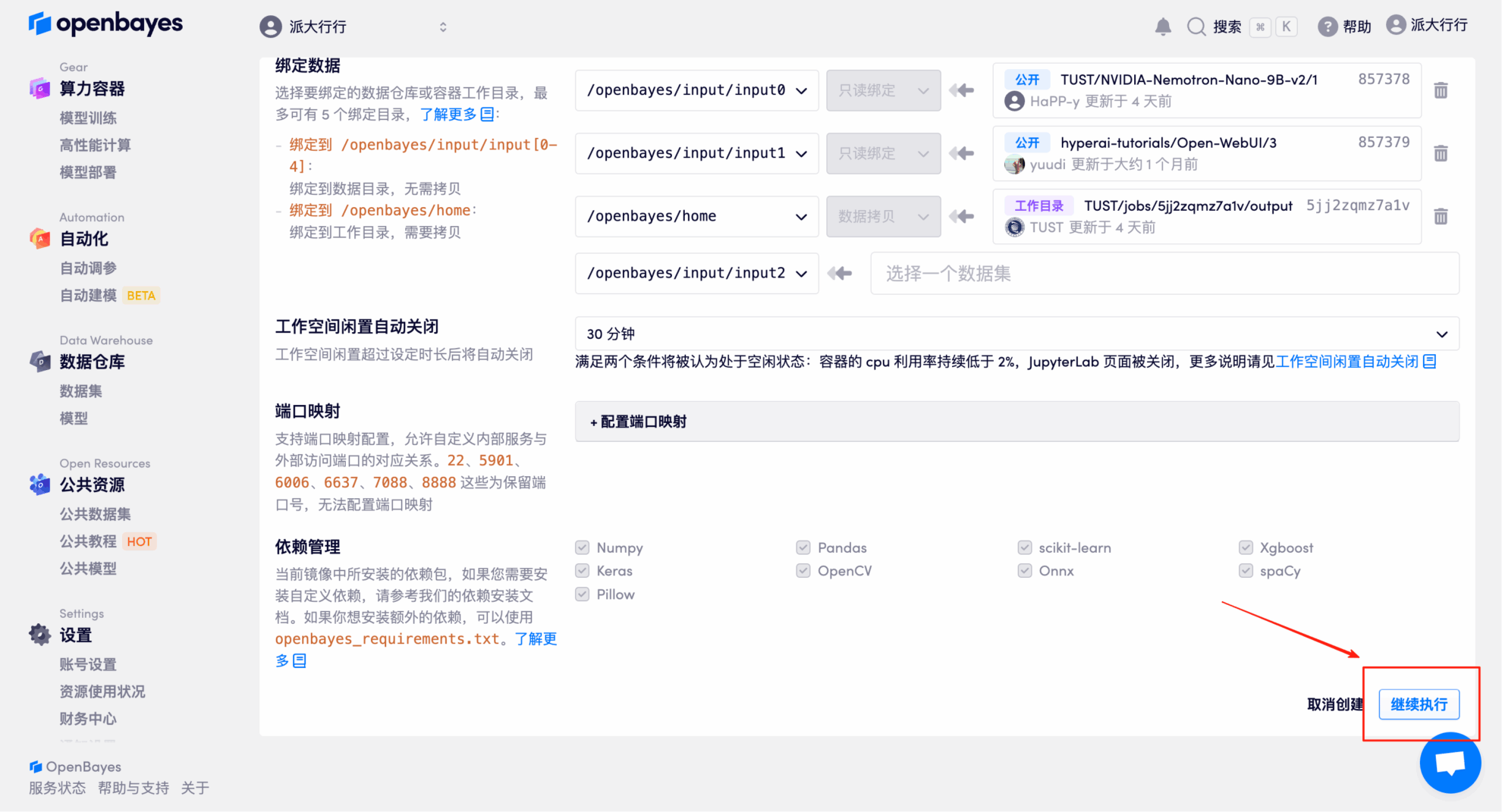
4. Warten Sie, bis die Ressourcen zugewiesen sind. Der erste Klonvorgang dauert etwa 3 Minuten. Wenn der Status auf „Läuft“ wechselt, klicken Sie auf den Pfeil neben „API-Adresse“, um zur Demoseite zu gelangen. Bitte beachten Sie, dass Benutzer vor der Verwendung der API-Adresse eine Echtnamen-Authentifizierung durchführen müssen.
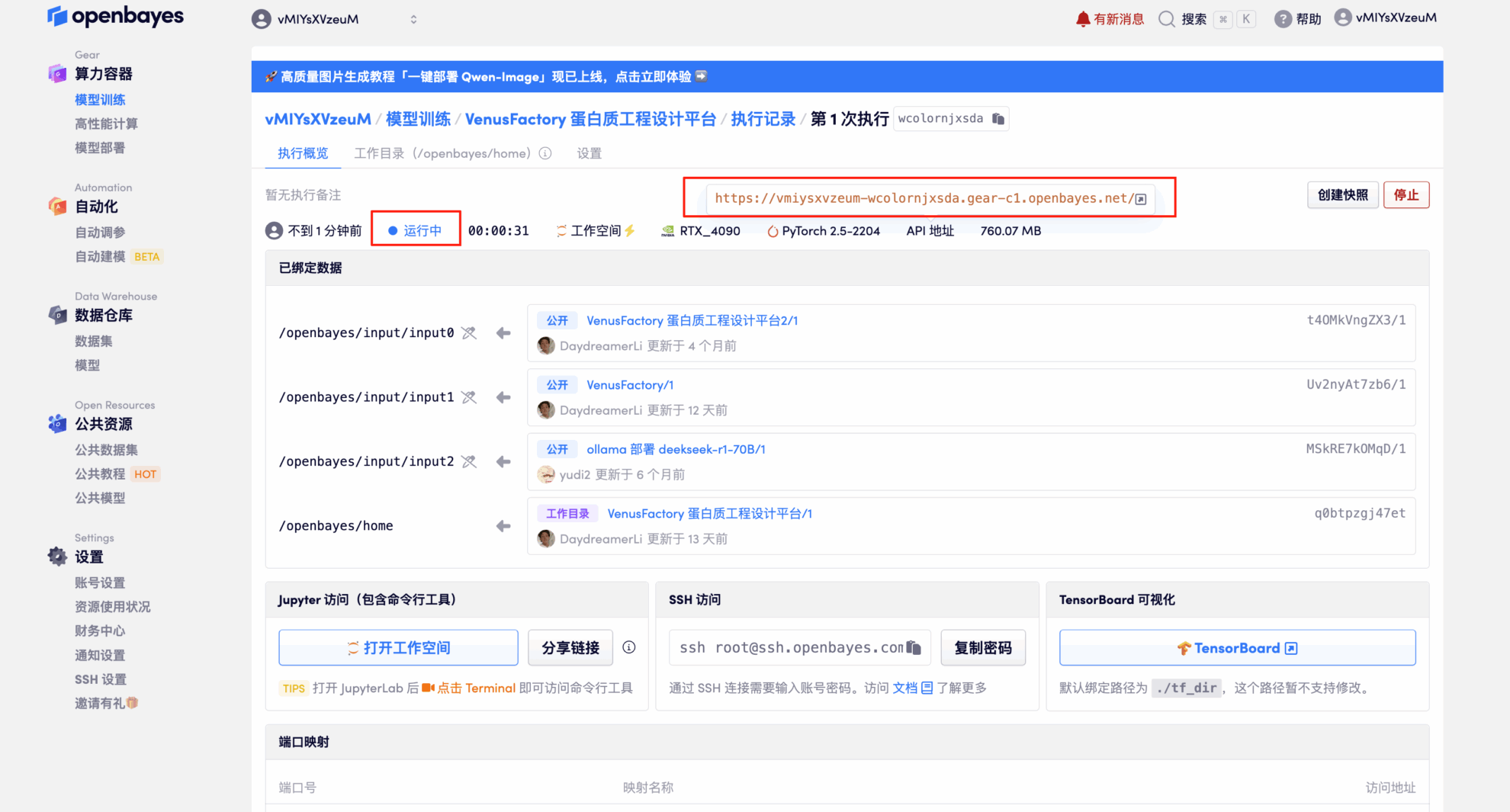
Effektdemonstration
Nachdem Sie die Seite „Demo ausführen“ aufgerufen haben, geben Sie im Dialogfeld „Eingabeaufforderung“ ein und klicken Sie auf „Ausführen“.
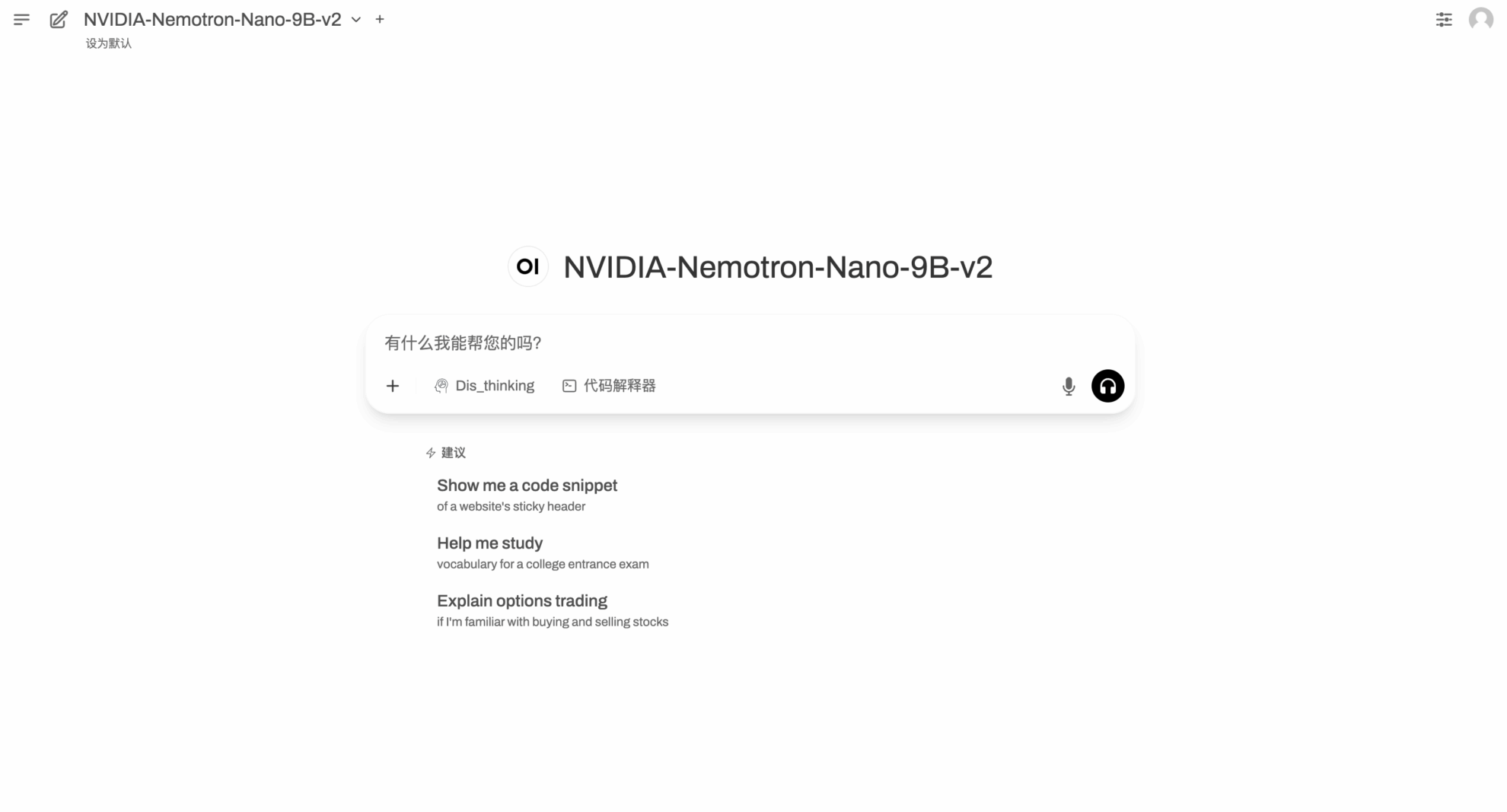
Nach Herbstbeginn kühlt das Wetter allmählich ab. Nemotron-Nano-9B-v2 gibt uns einige Tipps, wie Sie sich im Frühherbst warm halten.



Das Obige ist das diesmal von HyperAI empfohlene Tutorial. Jeder ist herzlich eingeladen, vorbeizukommen und es auszuprobieren!
Link zum Tutorial:
Erhalten Sie mit einem Klick hochwertige Papiere und ausführliche Interpretationsartikel im Bereich AI4S von 2023 bis 2024 ⬇️









