Command Palette
Search for a command to run...
Um Die Verfügbarkeit Wissenschaftlicher Daten Zu Verbessern, Schlug Das Team Von Zhang Zhengde an Der Chinesischen Akademie Der Wissenschaften Eine KI-fähige Datenverarbeitungs- Und -bereitstellungslösung Auf Basis Intelligenter Agenten vor.

In der modernen Hochenergiephysikforschung generieren hochmoderne Großforschungsanlagen ständig enorme Datenmengen. Da diese beispiellose Datenflut die Verarbeitungsgrenzen herkömmlicher Analysemethoden bei weitem übersteigt, entwickeln sich Technologien der künstlichen Intelligenz (KI), insbesondere maschinelles Lernen und tiefe neuronale Netzwerke, schnell zu zentralen Werkzeugen in der gesamten Hochenergiephysikforschung. KI-Algorithmen verarbeiten nicht nur effizient riesige Mengen an Rohdaten und decken darin implizite, nichtlineare und komplexe Muster und Zusammenhänge auf, sondern bieten auch Anwendungsvorteile bei der Optimierung des Beschleunigerbetriebs, der Simulation der Detektorleistung, der Entwicklung experimenteller Triggersysteme und der Erforschung theoretischer Modelle. Die kontinuierliche Innovation und tiefe Integration von KI-Methoden sind zu einer potenziellen treibenden Kraft für die zukünftige Entwicklung der Hochenergiephysik geworden.
Auf der CCF National High Performance Computing Academic Conference 2025 sprach Zhang Zhengde, Forscher und Leiter von AI4S am Rechenzentrum des Instituts für Hochenergiephysik, im Forum „AI-Ready Scientific Data Technology“ zum Thema „Fortschritte und Praktiken der Datenverarbeitung intelligenter Agenten auf der Grundlage großer Modelle“.Ausgehend vom aktuellen Stand wissenschaftlicher Daten aus Großanlagen erläutert diese Arbeit systematisch den effizienten und qualitativ hochwertigen AI-Ready-Aufbauplan für Daten sowie die Anwendung intelligenter Agenten und Multi-Agenten-Frameworks bei der Datenannotation und -bereitstellung.

HyperAI hat die Rede von Professor Zhang Zhengde zusammengestellt und zusammengefasst, ohne die ursprüngliche Absicht zu verletzen. Im Folgenden finden Sie die Abschrift der Rede.
Der Stand KI-fähiger Daten und wissenschaftlicher Daten
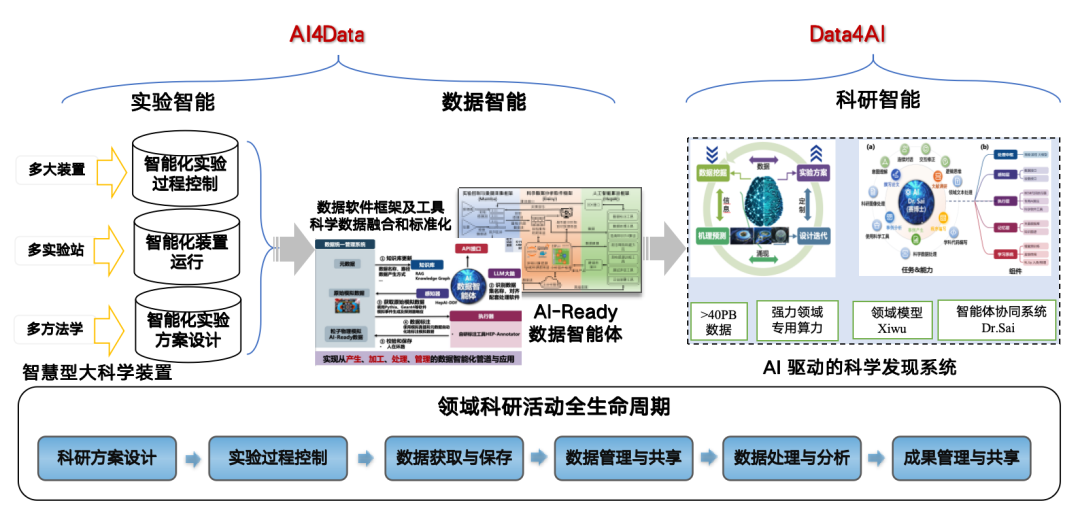
Im Kontext von Open-Source-AI4S-Algorithmen sind Daten zum kritischsten Kernproblem geworden. AI4S erfordert einheitliche Datenstandards für eine effiziente Analyse. Obwohl Daten aus großen wissenschaftlichen Einrichtungen in der Regel ein einheitliches Format und eine einheitliche Speicherarchitektur aufweisen, sind die meisten wissenschaftlichen Daten in der Realität nicht KI-fähig.
Die enormen Datenmengen, die in der Hochenergiephysik generiert werden, stellen nicht nur hohe Anforderungen an Datenerfassungs-, Verarbeitungs- und Fusionstechnologien, sondern stellen auch eine wichtige Ressource für die Entwicklung von KI-Methoden dar. Zu den im heutigen Bericht erwähnten Datentypen gehören nicht nur experimentelle Daten, sondern auch Simulationsdaten, Gerätebetriebsdaten und Korpusdaten.
Die allgemeine Definition eines AI-Ready-Datensatzes ist eine Sammlung von Daten, die effizient, sicher und reproduzierbar zum Trainieren, Bewerten und Bereitstellen von maschinellem Lernen und künstlicher Intelligenz verwendet werden können.Hochwertige KI-fähige Daten weisen 10 Merkmale auf:
* Aufgabenanpassung.Starke Relevanz für das Zielszenario und die Aufgabe, mit umfassender Abdeckung und Repräsentativität;
* Hohe Qualität und Konsistenz.Genau, vollständig, konsistent, dedupliziert und geräuschkontrolliert;
* Erfüllen Sie die Anforderungen der Karosserie und Kennzeichnung,Es verfügt über hochwertige Beschriftungen, Hierarchien und Ontologie-Zuordnungen und ist mit Audits versehen.
* Technik verfügbar.Maschinenlesbar, z. B. durch ein Standardformat, angemessenes Sharding/Bucketing, Streambarkeit und Parallelisierung;
* Auswertbar und wiederverwendbar.Trennen Sie Trainings-, Test- und Validierungsdaten strikt, und der Benchmark-Satz verfügt über klare und sinnvolle Bewertungsindikatoren.
* Metadaten und Anreicherung.Umfasst Methode zur Metadatenerfassung, Zeit, Gerätesystem, Kontext, Version und andere Informationen;
* Datenabweichungskontrolle.Wie etwa Stichprobenverzerrung, Etikettenverzerrung und historische Verzerrung;
* Verfügbar.Stabile Zugriffsschnittstelle, Dokumentation und Beispiele;
* Angemessen und konform.Berechtigungen und Nutzungsrechte, Datenschutz und bester PII;
* Sicher und zuverlässig.Verschlüsselung (während der Übertragung/im Ruhezustand), geringste Privilegien, Schlüsselverwaltung usw.
In der praktischen Forschung dienen Daten nicht nur zum Trainieren von Modellen, sondern müssen auch deren Bewertung unterstützen. Daher erfordern Datensätze die Festlegung entsprechender Bewertungsmetriken wie Präzision, Recall und F1-Score. Diese Metriken sind zwar für einige Aufgaben (wie die Klassifizierung) allgemein anwendbar, für Probleme wie Regression jedoch weniger effektiv. Dies stellt höhere Anforderungen an die Qualität KI-fähiger Datensätze und stellt Herausforderungen dar.
derzeit,Ein qualifizierter AI-Ready-Datensatz sollte neben ontologischen und annotierten Daten auch Metadaten enthalten, darunter Informationen wie eine Beschreibung der KI-Aufgabe. Noch wichtiger ist, dass ein AI-Ready-Datensatz direkt mit wertvollen KI-Aufgaben verknüpft sein muss.Am Beispiel von Lichtquellen sollten ihre KI-Anwendungen in der Lage sein, bestimmte wissenschaftliche Aufgaben wie Bildgebung, Spektroskopie und Beugungsstreuung effektiv zu unterstützen.
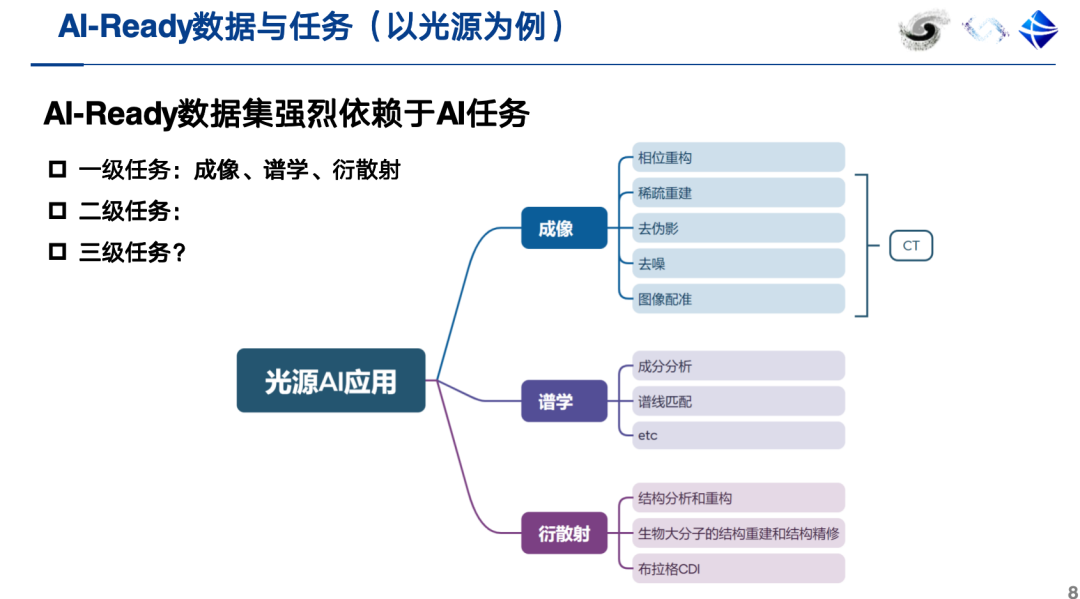
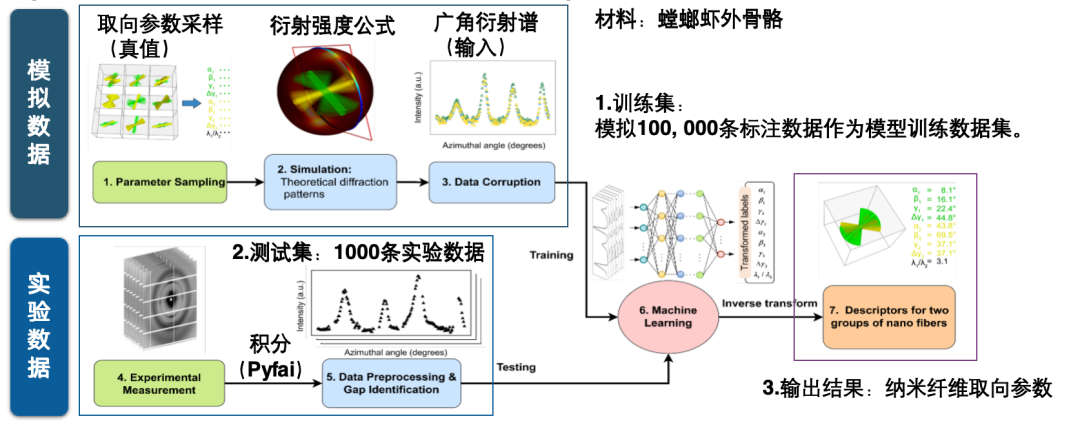
Im Folgenden werde ich anhand von zwei Beispielen veranschaulichen, was einen KI-fähigen Datensatz ausmacht. Der KI-Datensatz zur Vorhersage der Nanofaserorientierung hat beispielsweise eine klare KI-Aufgabe: die direkte Vorhersage der Nanofaserorientierungsparameter anhand von Weitwinkel-Beugungsspektren. Die Erstellung eines solchen Datensatzes erfordert die kombinierte Nutzung simulierter und experimenteller Daten.
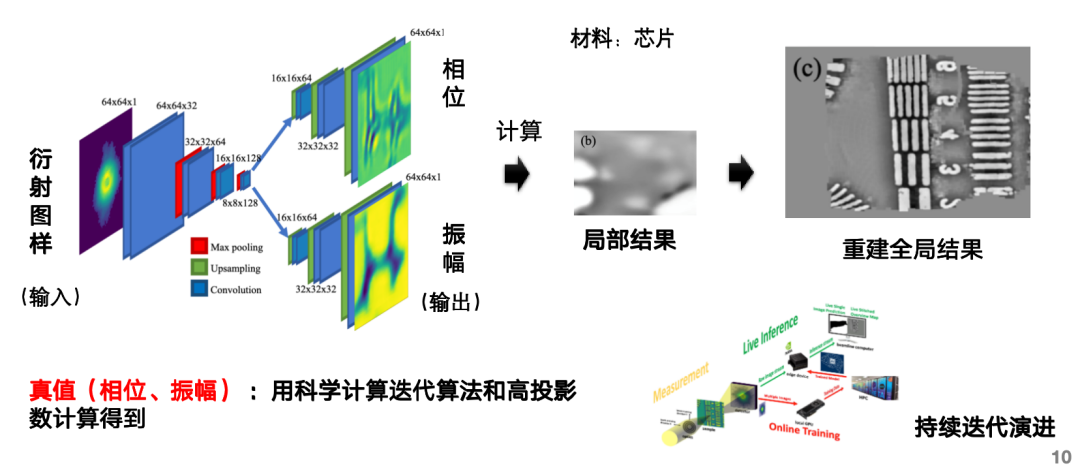
Beispielsweise kann der KI-Datensatz zur schnellen Rekonstruktion gestapelter Bilder die KI-Aufgabe der Eingabe eines Beugungsmusters, der Vorhersage seiner Phase und Amplitude und der Berechnung des rekonstruierten Bildes erfüllen und so den umfangreichen Rechenaufwand der Bildrekonstruktion kompensieren. Diese Architektur umfasst zwei Zweige, einen zur Vorhersage der Phase und einen zur Vorhersage der Amplitude. Die wahren Werte werden mithilfe eines iterativen Algorithmus für wissenschaftliche Berechnungen und einer hohen Anzahl von Projektionen abgeleitet.
Anwendung der Agententechnologie in der Datenverarbeitung
Die Definition eines Agenten kommt der ursprünglichen Definition künstlicher Intelligenz sehr nahe. Diese bezieht sich auf Software oder Systeme, die im Namen der Benutzer auf Grundlage ihres Wissens, ihrer Programme, ihrer Umgebung und ihrer Eingabeinformationen Entscheidungen treffen oder Aktionen ausführen können.
Obwohl intelligente Agenten Ähnlichkeiten mit der Automatisierungstechnologie aufweisen, basiert deren Funktionsweise in der Regel auf festen Prozessen. Im Gegensatz zur herkömmlichen Automatisierung eignen sich intelligente Agenten besonders für die Verarbeitung von Arbeitsabläufen, die nicht effektiv durch deterministische Regeln abgedeckt werden können, und können Aufgaben bewältigen, die mit herkömmlichen regelbasierten Computermethoden nur schwer zu bewältigen sind.Intelligente Agenten eignen sich nicht für alle Szenarien. Ihre Effektivität hängt stark von der jeweiligen Aufgabenumgebung ab und erfordert die umfassende Berücksichtigung der Komplexität der Entscheidungsfindung und -verarbeitung. Daher erfordert die Entwicklung intelligenter Agenten ein Umdenken im Umgang des Systems mit komplexen Entscheidungsprozessen.
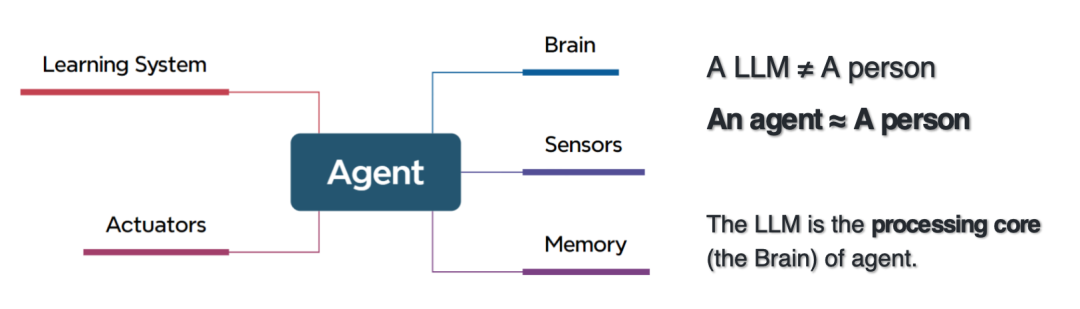
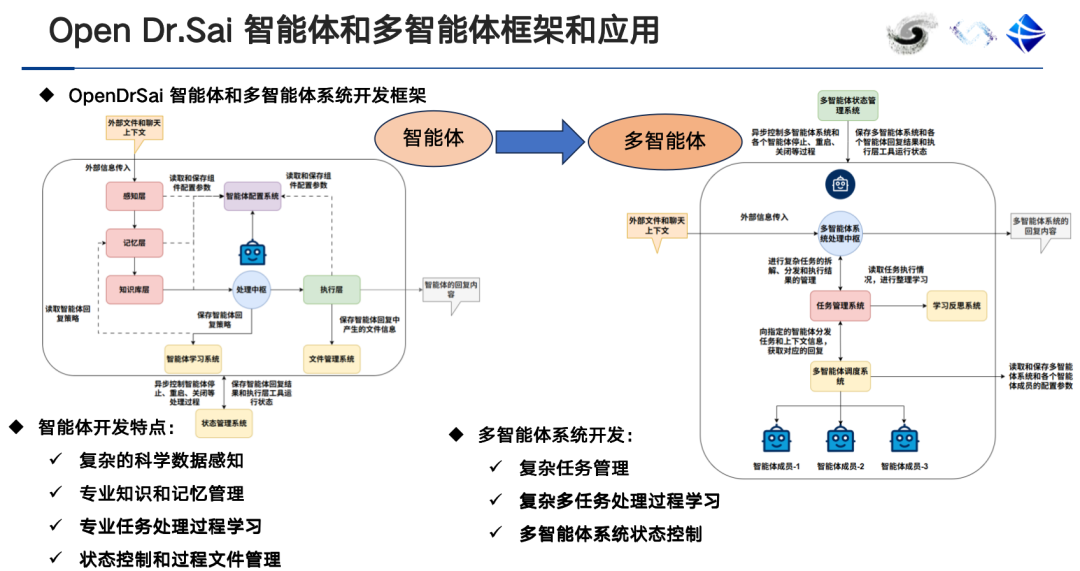
Das Gehirn des intelligenten Agenten ist ein großes Modell, daher ist die Beziehung zwischen dem intelligenten Agenten und dem großen Modell tatsächlich eine Inklusionsbeziehung.Der Unterschied zwischen einem intelligenten Agenten und einem großen Modell besteht darin, dass es eine Wahrnehmungsschicht, eine Ausführungsschicht, eine Speicherschicht und ein Verarbeitungszentrum umfasst.Sie müssen in der Lage sein, Fachwissen und wissenschaftliche Analysetools zu erlernen, Daten und Metadaten wahrzunehmen, Code zu schreiben und Programme auszuführen, Aufgaben zu planen, Rollen zuzuweisen und zusammenzuarbeiten usw.
Gleichzeitig unterscheiden sich die Anwendungsszenarien von Einzelagenten- und Multiagentensystemen. Ein Einzelagentensystem ist in der Regel mit einem einzigen Werkzeug ausgestattet. Mit zunehmender Anzahl der mitgeführten Werkzeuge nimmt die Genauigkeit der Werkzeugauswahl ab. In diesem Fall können Multiagentensysteme verwendet werden, um Verwirrung zu vermeiden.
KI-fähige Datenkennzeichnung auf Basis von Kennzeichnungstools ist hochgenau, erfordert aber einen hohen manuellen Aufwand. KI-fähige Datenkennzeichnung auf Basis intelligenter Agenten ist hochautomatisiert und effizient und kann das Verständnis und die Unterstützung von Dateninformationen erleichtern. Sie eignet sich für interdisziplinäre Forschung, die anfängliche Genauigkeit kann jedoch relativ gering sein und muss durch kontinuierliches Lernen und Feedbackmechanismen kontinuierlich verbessert werden.Derzeit sind viele auf Annotationen basierende Annotationstools schrittweise auf das Modell „ausgestattet mit intelligentem Agentenmodul + Mensch-Computer-Interaktion + intelligenter Unterstützung + Überprüfungssystem + Datenbank“ umgestiegen.
Auf Lichtquellenszenen angewendeter Datenagent
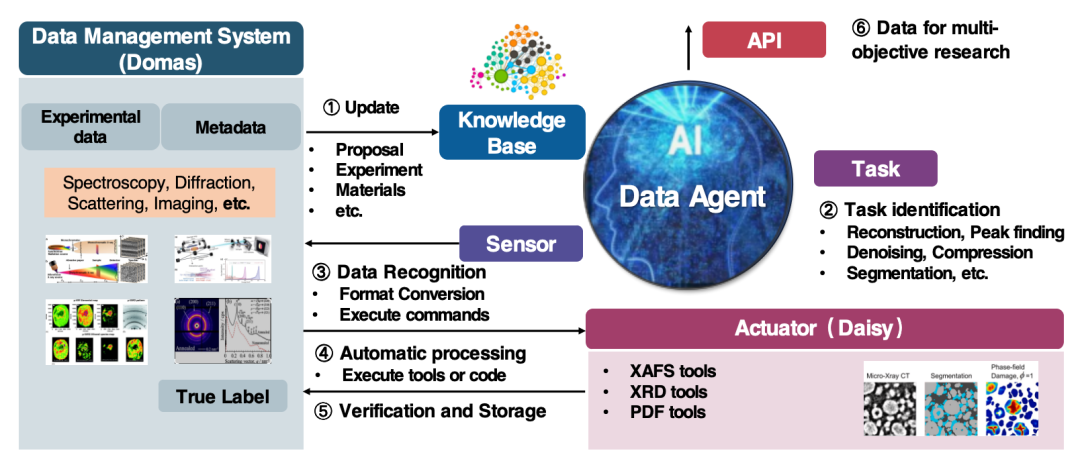
Der Datenagent unseres Teams wird hauptsächlich in Lichtquellen- (HEPS)/Neutronenquellen- (CSNS) Szenarien eingesetzt und unterstützt die Datenverarbeitung und -bereitstellung. Dem Agenten vorgeschaltet ist das Datenmanagementsystem Domas, das wiederum mit dem Datenerfassungssystem des Big-Data-Geräts verbunden ist, das wiederum mit dem Detektor selbst verbunden ist.
Weitere Informationen zu Datenagenten:
https://github.com/hepaihub/drsai
Link zur HepAI-Plattform:
Der Agenten-Workflow ist in 5 Schritte unterteilt:
* Stellen Sie eine Verbindung zu Domas her, um Dateninformationen einschließlich experimenteller Daten und Metadaten zu erhalten.
* Aktualisieren Sie die Wissensdatenbank basierend auf den erfassten Daten.
* Der Agent nimmt Daten basierend auf bestimmten Aufgaben weiter wahr und schließt die Dateninteraktion ab, indem er Datenformate konvertiert und Befehle ausführt.
* Verwenden Sie eine Vielzahl wissenschaftlicher Computertools zur Datenverarbeitung.
* Geben Sie Daten in den Executor ein, um die Aufgabenausführung zu steuern, und geben Sie die Ausgabeergebnisse wieder in Domas ein.
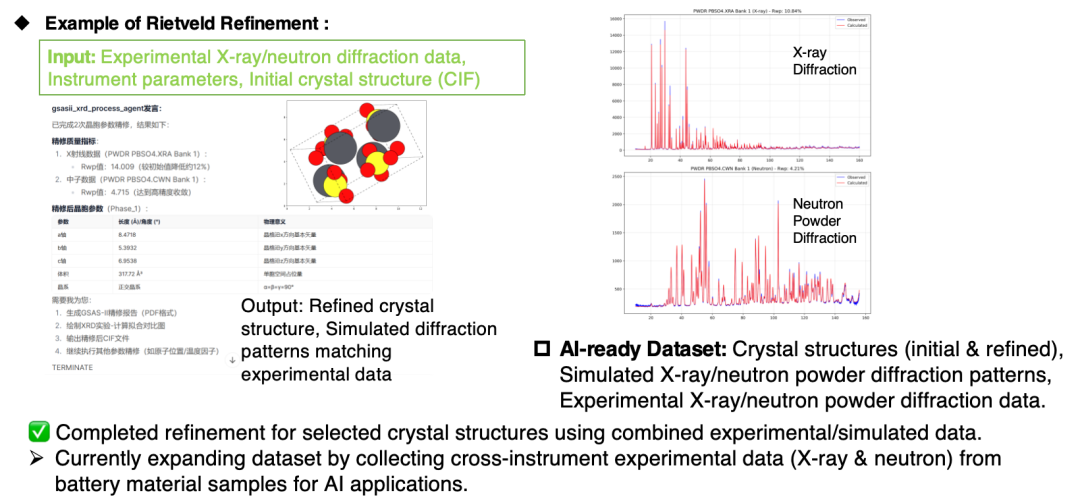
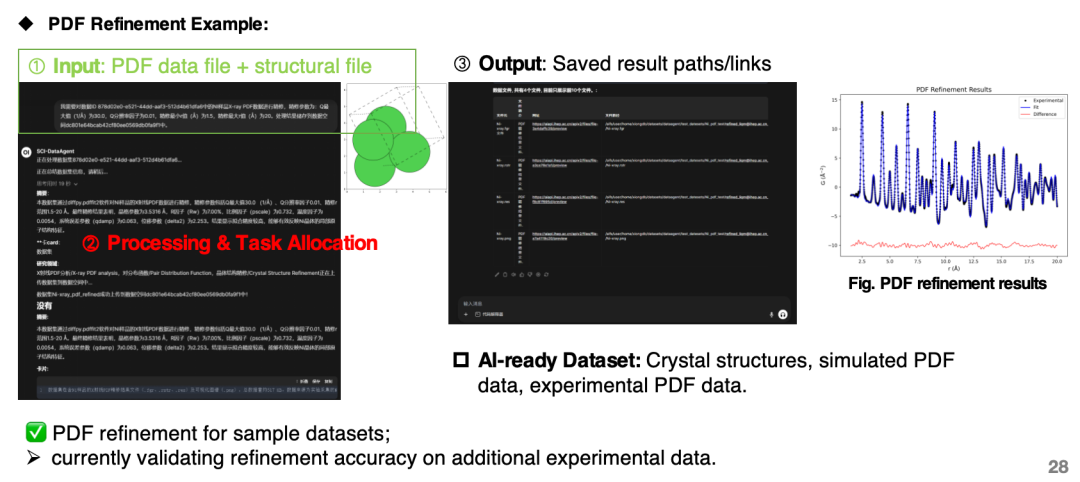
Derzeit kann der Agent zum Erstellen von KI-Datensätzen geräteübergreifender Röntgenbeugungsexperimente und Neutronenpulverbeugungsexperimente und -simulationen sowie zum Erstellen experimenteller und simulierter Fusionsdatensätze von Paarverteilungsfunktionen (PDFs) verwendet werden.
KI-gesteuertes wissenschaftliches Entdeckungssystem
Der Grund, warum wir intelligente Agententechnologie bei der Datenverarbeitung verwenden, liegt darin, dass AI4S allmählich zu einem Entwicklungstrend geworden ist. KI ist hilfreich für die Forschung und Entdeckung der Hochenergiephysik, stellt jedoch hohe Anforderungen an die Daten.Aus diesem Grund haben wir die Strategie „AI4Data“ zu „Data4AI“ übernommen und nutzen KI, um Rohdaten in eine KI-fähige Form umzuwandeln, um Forschungs- und Entwicklungsergebnisse zu fördern und ein KI-gesteuertes wissenschaftliches Entdeckungssystem aufzubauen.
Über den Forscher Zhang Zhengde und sein Team
Dr. Zhang Zhengde ist ein angesehener Nachwuchsforscher am Institut für Hochenergiephysik der Chinesischen Akademie der Wissenschaften. Er promovierte am Shanghai Institute of Applied Physics der Chinesischen Akademie der Wissenschaften in Teilchenphysik und Kernphysik. Seine Forschungsschwerpunkte sind KI-Algorithmen, große Modelle und intelligente Agenten für wissenschaftliche Entdeckungen, darunter Deep-Learning-Algorithmen, große Modelle für wissenschaftliche Daten, Plattformen für künstliche Intelligenz und Softwaresysteme. Sein Hauptziel ist die Förderung der Anwendung von KI in der Teilchenphysik, Teilchenastrophysik, Synchrotronstrahlung, Neutronenforschung und Beschleunigern.

Derzeit hat der Forscher Zhang Zhengde sechs repräsentative Open-Source-Projekte auf GitHub veröffentlicht, neuronale Netzwerke wie CDNet, FINet und MWNet entwickelt, das Hochenergie-Sprachmodell Xiwu und den wissenschaftlichen Forschungsagenten „Science Doctor“ entwickelt und die Hochenergiephysik-Plattform für künstliche Intelligenz HepAI[4] geplant und gebaut. Gleichzeitig leitete er eine Reihe wichtiger wissenschaftlicher Forschungsprojekte, darunter „From 0 to 1 Project – Research on AI Big Model Driven High-Energy Physics Scientific Discovery“ und „Research and Demonstration of High-Energy Physics Big Data Technology Based on Artificial Intelligence“.
Quellen:
[4] hepai-group. (nd). HepAI-Plattform. https://ai.ihep.ac.cn
Erhalten Sie mit einem Klick hochwertige Papiere und ausführliche Interpretationsartikel im Bereich AI4S von 2023 bis 2024 ⬇️









