Command Palette
Search for a command to run...
Der Neue Stand Der Bildbearbeitung! Qwen-Image-Edit Kombiniert Sowohl Semantische Als Auch Erscheinungsbildbearbeitungsfunktionen; Granary Löst Den Datenmangel Für Mehrsprachige Modelle in 25 Europäischen Sprachen.

Da sich Bildmodelle ständig weiterentwickeln und ausgereifter werden, beschränkt sich der Bedarf der Benutzer an der Verwendung großer Modelle nicht mehr länger auf die Generierung einzelner Bilder, und sie hoffen auch, detailliertere und kontrollierbarere Änderungen an vorhandenen Bildern vornehmen zu können. „Bearbeiten“ ist eine detailliertere und mikroskopischere Nutzungsanforderung als „Generieren“.Herkömmliche Bildbearbeitungssoftware (wie Photoshop) weist eine gewisse Nutzungsschwelle auf und erfordert von den Benutzern häufig ein systematisches Lernen. Bei den derzeit vorhandenen KI-Anwendungen zur Bildbearbeitung besteht sowohl bei den Funktionen als auch bei den Effekten Verbesserungsbedarf, insbesondere bei der Textwiedergabe und den Bearbeitungsfunktionen.
Auf dieser GrundlageDas Alitong Yiqianwen-Team hat das umfassende Bildbearbeitungsmodell Qwen-Image-Edit veröffentlicht, das über doppelte Bearbeitungsfunktionen für Semantik und Erscheinungsbild verfügt.Es kann nicht nur die Anweisungsabsicht der Erscheinungsbildbearbeitung genau verstehen, sondern auch eine erweiterte visuelle semantische Bearbeitung durchführen und dabei die Konsistenz des visuellen Stils des Bildes beibehalten.Dieses Modell erweitert außerdem die hervorragenden chinesischen Textwiedergabefunktionen von Qwen-Image auf den Bereich der Bildbearbeitung und ermöglicht eine präzise Bearbeitung von Text in Bildern.
Als neue Version von Qwen-Image verbessert Qwen-Image-Edit den geschlossenen Kreislauf von der Bildgenerierung über die Kettenbearbeitung bis hin zur endgültigen Effektpräsentation und verbessert so die Benutzerfreundlichkeit der Bilder erheblich.Auswertungen anhand mehrerer öffentlicher Benchmarks zeigen eine hochmoderne Leistung bei Bildbearbeitungsaufgaben.
Auf der offiziellen Website von HyperAI wurde die Demo „Qwen-Image-Edit: All-in-One-Bildbearbeitungsmodell“ veröffentlicht. Kommen Sie vorbei und probieren Sie es aus!
Online-Nutzung:https://go.hyper.ai/nmjYo
Hier ist ein kurzer Überblick über die Updates der offiziellen Website von hyper.ai vom 18. bis 22. August:
* Hochwertige öffentliche Datensätze: 10
* Hochwertige Tutorial-Auswahl: 4
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im August: 2
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Granary European Spracherkennungs- und Übersetzungsdatensatz
Granary ist ein umfangreicher mehrsprachiger Sprachdatensatz von NVIDIA, der hochwertiges Trainings- und Evaluierungsmaterial für mehrsprachige ASR/AST-Modelle bereitstellt. Der Datensatz enthält rund 1 Million Stunden hochwertige pseudo-gelabelte ASR-Sprachdaten aus 25 europäischen Sprachen.
Direkte Verwendung:https://go.hyper.ai/D3926
2. M3-Bench Benchmark-Datensatz für die Beantwortung langer Videofragen
M3-Bench, ein vom ByteDance Seed-Team veröffentlichter Benchmark-Datensatz mit langen Videofragen und -antworten, dient der Bewertung des Langzeitgedächtnisses und der Denkfähigkeiten multimodaler Agenten. Der Datensatz enthält 1.020 Videobeispiele, jedes mit Untertiteln, Zwischenausgaben und Gedächtnisdiagrammen.
Direkte Verwendung:https://go.hyper.ai/LIHsO
3. HiFiTTS-2 Großer Sprachdatensatz mit hoher Bandbreite
HiFiTTS-2 ist ein umfangreicher Sprachdatensatz mit hoher Bandbreite, der das Training und die Evaluierung hochwertiger Zero-Shot-Text-to-Speech-Modelle (TTS) unterstützt. Der Datensatz enthält Audiometadaten von 5.000 Sprechern, etwa 36.700 Stunden englische Sprachaufnahmen bei 22,05 kHz und 31.700 Stunden bei 44,1 kHz, die nach Bandbreitenqualität und Abtastrate in Schichten organisiert sind.
Direkte Verwendung:https://go.hyper.ai/XZwDD
4. CulturalGround Mehrsprachiger kultureller visueller Fragen- und Antwortdatensatz
CulturalGround ist ein mehrsprachiger und multimodaler visueller Frage-Antwort-Datensatz zur kulturellen Wissensausrichtung, der von NeuLab an der Carnegie Mellon University veröffentlicht wurde. Ziel ist es, das Verständnis und die Argumentationsfähigkeiten multimodaler großer Sprachmodelle für kulturelle Nischeneinheiten und ressourcenarme Sprachen zu verbessern.
Direkte Verwendung:https://go.hyper.ai/wayAA
5. HPDv3-Datensatz zu menschlichen Präferenzen
HPDv3 ist der erste breit gefächerte Datensatz zu menschlichen Präferenzen, der von MizzenAI und MMLab an der Chinesischen Universität Hongkong veröffentlicht wurde. Die zugehörige Arbeit wurde für die ICCV 2025 ausgewählt. Dieser Datensatz dient der Ausrichtung, Permutation und Evaluierung von Text-zu-Bild-Generierungsmodellen und soll die Modellentwicklung bei der Anpassung an die menschliche Ästhetik und der Verbesserung der semantischen Konsistenz fördern.
Direkte Verwendung:https://go.hyper.ai/xV8fK
6. COREVQA Benchmark-Datensatz für visuelle Fragen und Antworten
COREVQA, ein vom Algoverse AI Research Center veröffentlichter Benchmark-Datensatz zur visuellen Frage- und Antwortanalyse, dient der Bewertung der Denkfähigkeiten visueller Sprachmodelle (VLMs) in Menschenmengen. Der Datensatz umfasst hauptsächlich reale Menschenmengenszenen und betont Herausforderungen wie Okklusion, Perspektivwechsel und Hintergrundstörungen. Ziel ist es, die feinkörnige Wahrnehmung und Denkfähigkeit von VLMs in komplexen sozialen Szenarien zu verbessern.
Direkte Verwendung:https://go.hyper.ai/tOFNw
7. DDOS UAV-Datensatz zur Tiefen- und Hindernissegmentierung
DDOS ist ein synthetischer Datensatz mit Luftbildern, der die Algorithmenentwicklung für autonome Drohnen vorantreiben soll. Der Datensatz ist sorgfältig nach Umgebungstyp kategorisiert. Der Trainingsdatensatz besteht aus 300 Flügen mit insgesamt 30.000 Bildern; der Validierungsdatensatz besteht aus 20 Flügen mit insgesamt 2.000 Bildern; und der Testdatensatz besteht aus 20 Flügen mit insgesamt 2.000 Bildern.
Direkte Verwendung:https://go.hyper.ai/XRE6R

8. Nemotron Multi-Domain Reasoning-Datensatz
Nemotron ist ein von NVIDIA veröffentlichter Multi-Domain-Reasoning-Datensatz, der die Effizienz und Genauigkeit des Llama-Modells verbessern soll. Der Datensatz enthält 25,66 Millionen Beispiele aus fünf Kategorien: Konversation, Code, Mathematik, MINT und Tool-Aufrufe.
Direkte Verwendung:https://go.hyper.ai/WP2Ym
9. Document Haystack Multimodaler Dokument-Benchmark-Datensatz
Document Haystack ist ein multimodaler Dokument-Benchmark-Datensatz von Amazon AGI. Er enthält 400 Dokumentvarianten und 8.250 Abfragefragen. Ziel ist es, die Informationsabruf- und Verständnisfähigkeiten visueller Sprachmodelle (VLMs) in langen und komplexen Kontextdokumenten zu bewerten.
Direkte Verwendung:https://go.hyper.ai/Q08Xt
10. CSEMOTIONS Emotionaler Audio-Datensatz
CSEMOTIONS ist ein emotionaler Audiodatensatz, der die Forschung zu Steuerbarkeit und natürlicher Sprachgenerierung unterstützen soll. Der Datensatz enthält etwa 10 Stunden hochwertige Audiodaten aus sieben emotionalen Kategorien, darunter Ruhe, Glück und Wut, aufgenommen von 10 professionellen Synchronsprechern.
Direkte Verwendung:https://go.hyper.ai/4fe7A
Ausgewählte öffentliche Tutorials
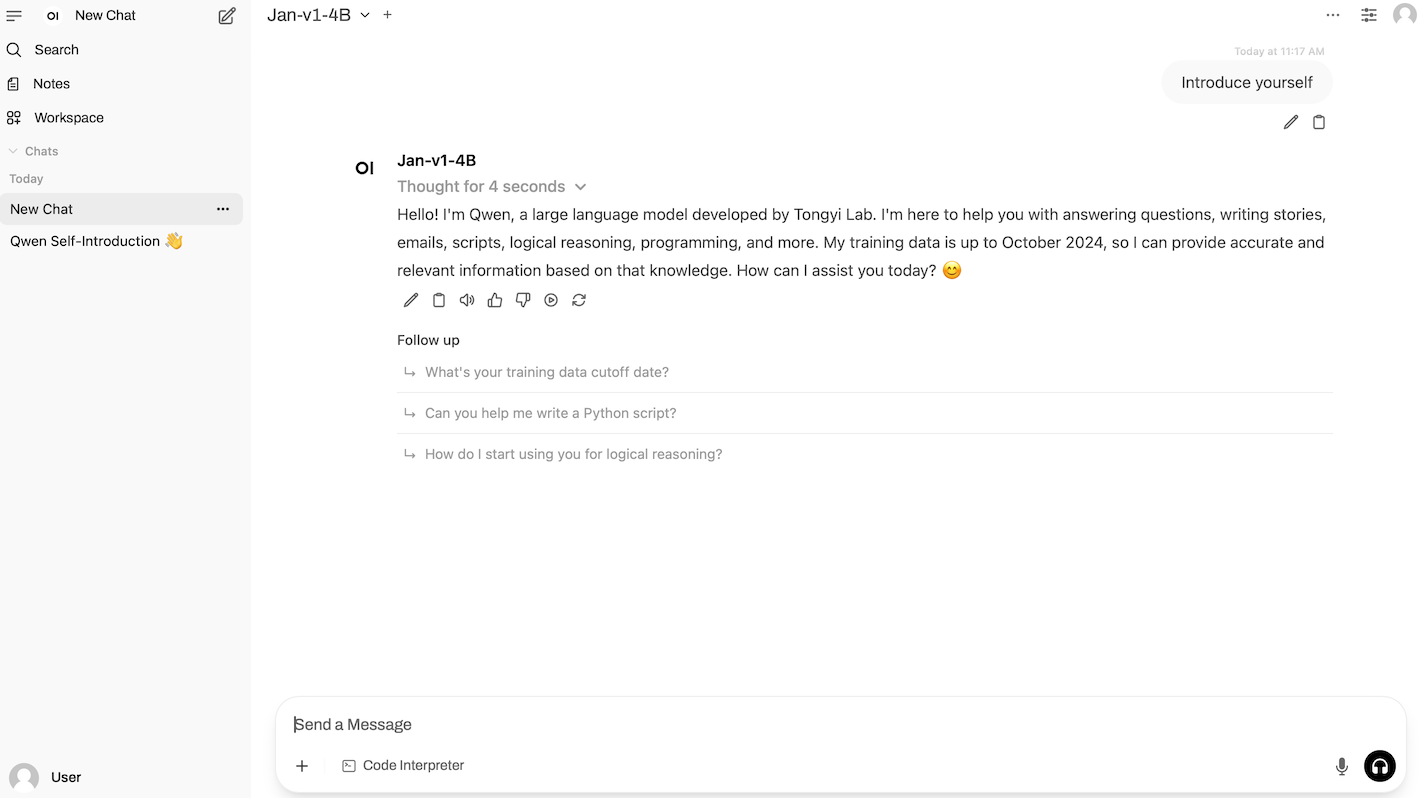
1. vLLM + Open-WebUI stellen Jan-v1-4B bereit
Jan-v1-4B ist ein vom Jan-Team veröffentlichtes Open-Source-Sprachmodell mit 4 Milliarden Parametern. Es ist die erste Version der Jan-Familie und auf intelligentes körperbasiertes Denken und Tool-Aufrufe ausgerichtet. Es ist für reale Workflow-Szenarien in Jan-Apps optimiert. Basierend auf Qwen3-4B-Thinking-2507 wurde dieses Modell optimiert und erweitert. Es erreichte eine Genauigkeit von 91,1% im SimpleQA-Benchmark und zeigt damit deutliche Leistungsverbesserungen durch Modellerweiterung und -optimierung.
Online ausführen:https://go.hyper.ai/CZf3s
2. Tutorial zur Klassifizierungsvorhersage für Brustkrebsdiagnosedatensätze durch maschinelles Lernen
Dieses Tutorial basiert auf dem Wisconsin Breast Cancer Diagnosis Dataset (WDBC) und demonstriert den gesamten maschinellen Lernprozess für ein binäres Klassifizierungsproblem. Es vermittelt Ihnen die grundlegende Logik der Merkmalsauswahl, Modelloptimierung und Ergebnisvisualisierung und bietet eine Referenz für die Modellierung der Diagnostik anderer Krankheiten.
Online ausführen:https://go.hyper.ai/zFjil
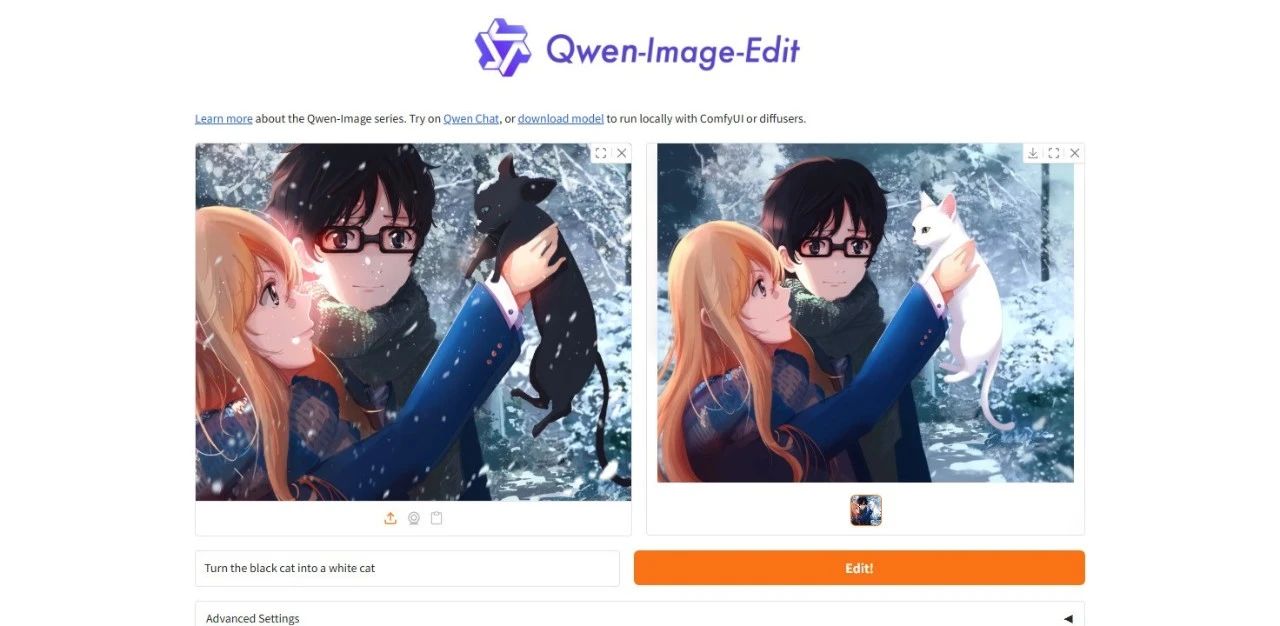
3. Qwen-Image-Edit: Allround-Bildbearbeitungsmodell-Demo
Qwen-Image-Edit ist ein umfassendes Bildbearbeitungsmodell, das vom Alibaba Tongyi Qianwen-Team entwickelt wurde. Es kombiniert semantische und visuelle Bearbeitungsfunktionen, unterstützt die präzise Bearbeitung von Text in Chinesisch und Englisch und ermöglicht die Änderung von Text in Bildern unter Beibehaltung der ursprünglichen Schriftart, -größe und -stil.
Online ausführen:https://go.hyper.ai/nmjYo
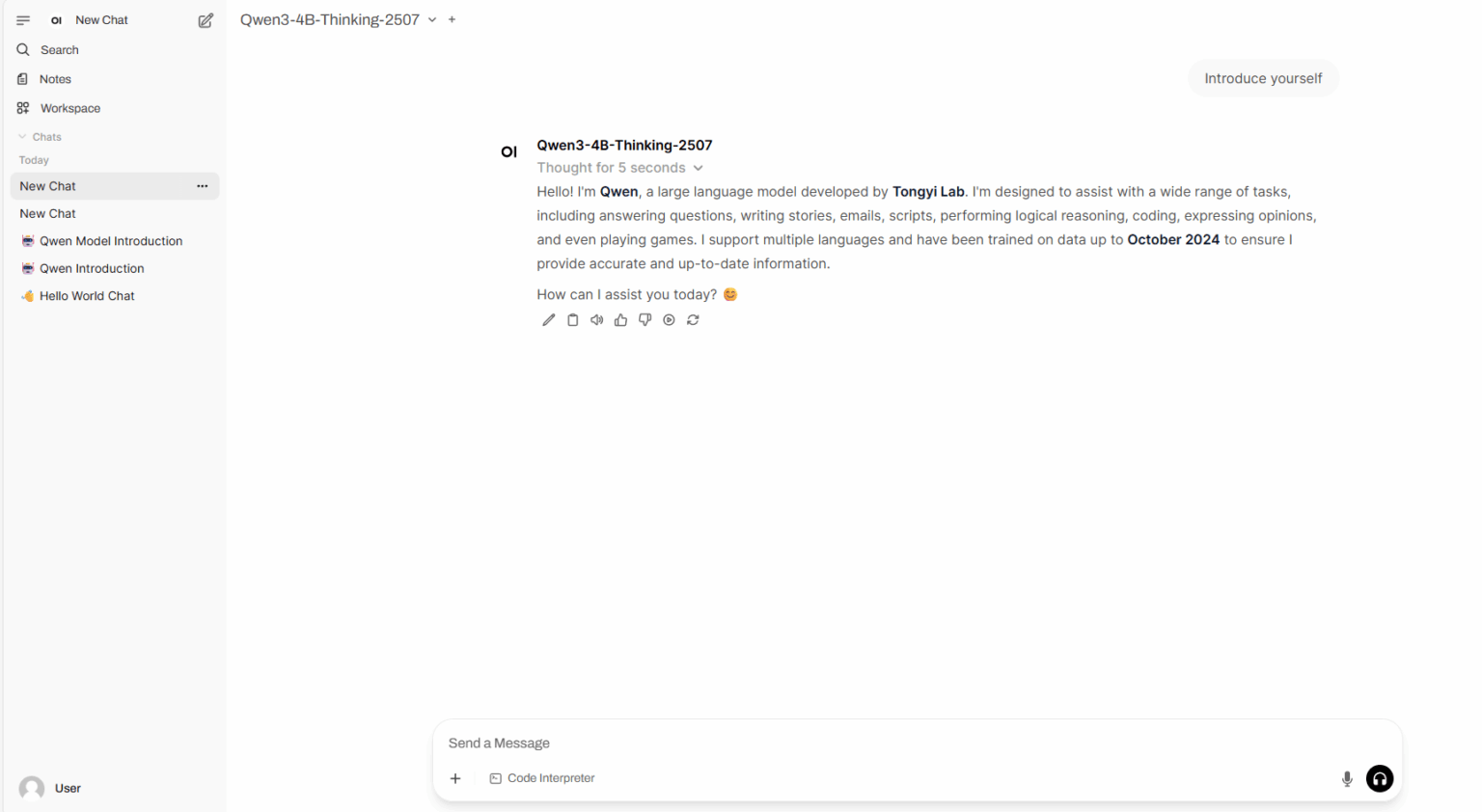
4. Ein-Klick-Bereitstellung von Qwen3-4B-2507
Qwen3-4B-Thinking-2507 und Qwen3-4B-Instruct-2507 sind große Sprachmodelle, die vom Alibaba Tongyi Qianwen-Team entwickelt wurden. In puncto Leistung übertrifft Qwen3-4B-Thinking-2507 das kleinere Qwen3-Modell gleicher Größe deutlich in den Bereichen komplexes Problemdenken, mathematische Fähigkeiten, Codierungsfähigkeiten und mehrstufige Funktionsaufruffähigkeiten. In nicht-denkenden Bereichen übertrifft Qwen3-4B-Instruct-2507 das Closed-Source-Kleinmodell GPT-4.1-nano in den Bereichen Wissen, Denken, Programmierung, Ausrichtung und Agentenfähigkeiten deutlich und erreicht eine ähnliche Leistung wie das mittelgroße Qwen3-30B-A3B (nicht-denkend).
Online ausführen:https://go.hyper.ai/HiqSR
💡Wir haben außerdem eine Austauschgruppe für Tutorials zur stabilen Diffusion eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~

Die Zeitungsempfehlung dieser Woche
1. DINOv3
Dieser technische Bericht stellt DINOv3 vor, das hochwertige, dichte Features generiert und bei einer Vielzahl von Bildverarbeitungsaufgaben außergewöhnlich gute Ergebnisse liefert. Dabei übertrifft es frühere selbstüberwachte und schwach überwachte Basismodelle deutlich. Forscher veröffentlichten außerdem die DINOv3-Familie von Bildverarbeitungsmodellen, um den Stand der Technik für eine Vielzahl von Aufgaben und Datensätzen zu verbessern, indem skalierbare Lösungen für unterschiedliche Ressourcenbeschränkungen und Einsatzszenarien bereitgestellt werden.
Link zum Artikel:https://go.hyper.ai/tBuYx
2. Technischer Bericht zu Ovis2.5
Dieses Dokument stellt Ovis2.5 vor, den Nachfolger von Ovis2, der für visuelle Wahrnehmung in nativer Auflösung und leistungsstarkes multimodales Denken entwickelt wurde. Ovis2.5 integriert einen visuellen Transformator in nativer Auflösung, der Bilder direkt in ihrer nativen, variablen Auflösung verarbeitet. Dadurch werden die mit der Segmentierung in fester Auflösung verbundenen Qualitätseinbußen vermieden, während feine Details und das globale Layout vollständig erhalten bleiben.
Link zum Artikel:https://go.hyper.ai/jlEXl
3. SSRL: Selbstsuch-Verstärkungslernen
Forscher untersuchen das Potenzial großer Sprachmodelle (LLMs) als effiziente Simulatoren für Agentensuchaufgaben im bestärkenden Lernen (RL), um die Abhängigkeit von teuren externen Suchmaschineninteraktionen zu reduzieren. Empirische Auswertungen zeigen, dass mit SSRL trainierte Policy-Modelle eine kostengünstige und stabile Umgebung für suchbasiertes RL-Training bieten, die Abhängigkeit von externen Suchmaschinen deutlich reduzieren und einen robusten Transfer von der Simulation in die Realität ermöglichen.
Link zum Artikel:https://go.hyper.ai/4TFRe
4. Thymian: Denken Sie über Bilder hinaus
Da derzeit kein Open-Source-Werk einen Funktionsumfang bietet, der mit dem proprietärer Modelle vergleichbar ist, führt dieses Dokument vorläufige Untersuchungen in dieser Richtung durch und schlägt Thyme (Think Beyond Images) vor, das es multimodalen Large Language Models (MLLMs) ermöglicht, über bestehende Methoden des „Denkens durch Bilder“ hinauszugehen und verschiedene Bildverarbeitungs- und Rechenoperationen durch ausführbaren Code autonom zu generieren und auszuführen.
Link zum Artikel:https://go.hyper.ai/ZhLMI
5. Agentenkette: End-to-End-Agenten-Foundation-Modelle über Multi-Agenten-Destillation und Agentic RL
Die meisten bestehenden Multi-Agenten-Systeme basieren auf manuell erstellten Eingabeaufforderungen oder Workflow-Engineering und bauen auf komplexen Agenten-Frameworks auf. Dies führt zu Rechenineffizienz, eingeschränkten Fähigkeiten und der Unfähigkeit, von datenzentriertem Lernen zu profitieren. Diese Forschung schlägt Chain-of-Agents (CoA) vor, ein neuartiges LLM-Argumentationsparadigma, das die durchgängige Lösung komplexer Probleme innerhalb eines einzigen Modells ermöglicht und dabei die gleichen Mechanismen wie Multi-Agenten-Systeme nutzt.
Link zum Artikel:https://go.hyper.ai/5m3gV
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
Ein gemeinsames Team der Universität Oxford und anderer Universitäten hat eine graphenbasierte RAG-Methode speziell für den medizinischen Bereich entwickelt – Medical GraphRAG. Diese Methode verbessert die Leistung des LLM im medizinischen Bereich effektiv, indem sie evidenzbasierte Antworten und offizielle Erklärungen zur medizinischen Terminologie generiert.
Den vollständigen Bericht ansehen:https://go.hyper.ai/3458z
Das Team von Tongyi Qianwen erweitert seine Open-Source-Modellmatrix kontinuierlich und konzentriert sich dabei auf architektonische Innovationen, Effizienzsteigerungen und Durchbrüche in Deep-Dive-Szenarien. So erreicht es eine Leistung, die mit der von Branchenführern vergleichbar ist. Im Bereich „Tutorials“ der offiziellen HyperAI-Website wurden mehrere Tutorials zum Open-Source-Modell von Tongyi veröffentlicht.
Den vollständigen Bericht ansehen:https://go.hyper.ai/JKJTY
Ein Team der Cornell University hat einen integrierten Schaltkreis namens Microwave Neural Network (MNN) vorgeschlagen, der gleichzeitig ultraschnelle Daten und drahtlose Kommunikationssignale verarbeiten kann. Dank seines geringen Stromverbrauchs und seiner geringen Größe bietet er eine neue Lösung für Anwendungen mit hoher Bandbreite.
Den vollständigen Bericht ansehen:https://go.hyper.ai/Cki2I
Auf der Sommerschule „AI For Bioengineering“ 2025 der Shanghai Jiao Tong University teilte Professor Zhuang Yingping von der East China University of Science and Technology ihre Ansichten zum Thema „KI unterstützt effiziente Bioproduktionsprozesse“. Sie stellte das technische System und die Teamleistungen aus drei Perspektiven vor: die Beziehung zwischen Bioproduktion und synthetischer Biologie, die Anwendungsfelder synthetischer Biologieprodukte sowie intelligente Bioproduktionstechnologie und -praxis.
Den vollständigen Bericht ansehen:https://go.hyper.ai/LgKcG
Um die weitverbreitete Anwendung künstlicher Intelligenz im Bereich des Protein-Engineerings zu fördern, hat die Forschungsgruppe von Professor Hong Liang an der Shanghai Jiao Tong University eine zentrale Open-Source-Workbench für das Protein-Engineering namens VenusFactory entwickelt, um die Abfrage biologischer Daten, standardisiertes Aufgaben-Benchmarking und vortrainierte Proteinsprachenmodelle zu integrieren.
Den vollständigen Bericht ansehen:https://go.hyper.ai/p3llU
Beliebte Enzyklopädieartikel
1. DALL-E
2. Reziproke Sortierfusion RRF
3. Pareto-Front
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kontrastives Lernen
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:https://go.hyper.ai/wiki

Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








