Command Palette
Search for a command to run...
10 Millionen Stunden Sprachdaten! Das Sprachmodell Higgs Audio V2 Verbessert Die Emotionalen Fähigkeiten; MathCaptcha10k Verbessert Die Technologie Zur Erkennung Von Verifizierungscodes

„Was würde passieren, wenn 10 Millionen Stunden Sprachdaten zum Training eines großen Sprachmodells für Text hinzugefügt würden?“ Mit diesem Gedanken,Nach der Recherche veröffentlichten Li Mu und sein Team Boson AI offiziell das groß angelegte Sprachmodell „Higgs Audio V2“.
Herkömmliche TTS-Systeme (Text-to-Speech) verwenden häufig eine mechanische Sprachausgabe, der es an emotionaler Anpassungsfähigkeit und natürlichem Rhythmus mangelt. Dialoge mit mehreren Charakteren erfordern eine manuelle Segmentierung, und es ist schwierig, Klangfarbe und Charakter allein mithilfe von Modellen anzupassen. Higgs Audio V2 hingegen bietet innovative Funktionen, die bei herkömmlichen TTS-Systemen selten zu finden sind.Es umfasst eine automatische Rhythmusanpassung während der Erzählung, die Fähigkeit, Dialoge mit mehreren Sprechern zu generieren, Zero-Sample-Stimmklonen und melodisches Summen sowie die gleichzeitige Generierung von Sprache und Hintergrundmusik, was einen großen Sprung in den Fähigkeiten der Audio-KI darstellt.
Es ist erwähnenswert, dass bei EmergentTTS-Eval,Das Modell übertraf gpt-4o-mini-tts in den Kategorien Stimmung und Frage um 75,7% bzw. 55,7%.Dies spiegelt wider, dass die „emotionale Interaktion“ zu einem wichtigen Schritt für das Modell im Audiobereich geworden ist.
Auf der offiziellen Website von HyperAI wurde kürzlich „Higgs Audio V2: Redefining the Expressive Power of Speech Generation“ veröffentlicht. Kommen Sie vorbei und probieren Sie es aus!
Online-Nutzung:https://go.hyper.ai/Ty0CM
Hier ist ein kurzer Überblick über die Updates der offiziellen Website von hyper.ai vom 4. bis 8. August:
* Hochwertige öffentliche Datensätze: 10
* Auswahl an hochwertigen Tutorials: 7
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im August: 2
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. STRIDE-QA-Mini-Datensatz zur Beantwortung von Fragen zum autonomen Fahren
STRIDE-QA-Mini ist ein Frage-Antwort-Datensatz für autonomes Fahren, der die räumlich-zeitlichen Denkfähigkeiten visueller Sprachmodelle (VLMs) in autonomen Fahrszenarien untersucht. Der Datensatz enthält 103.220 Frage-Antwort-Paare und 5.539 Bildbeispiele. Die Daten stammen aus realen Dashcam-Aufnahmen, die in Tokio gesammelt wurden.
Direkte Verwendung:https://go.hyper.ai/9DVTI
2. MathCaptcha10k-Bilddatensatz mit Arithmetik-Verifizierungscode
MathCaptcha10K ist ein Datensatz mit arithmetischen CAPTCHA-Bildern zum Testen und Trainieren von CAPTCHA-Erkennungsalgorithmen, insbesondere bei CAPTCHAs mit störenden Hintergründen und verzerrtem Text. Der Datensatz enthält 10.000 beschriftete und 11.766 unbeschriftete Beispiele. Jedes beschriftete Beispiel enthält ein CAPTCHA-Bild, die genauen Zeichen im Bild und die ganzzahlige Antwort.
Direkte Verwendung:https://go.hyper.ai/QERJt

3. CoSyn-400K Multimodaler synthetischer Fragen- und Antwortdatensatz
CoSyn-400K ist ein multimodaler synthetischer Frage-Antwort-Datensatz, der gemeinsam von der University of Pennsylvania und dem Allen Institute for Artificial Intelligence veröffentlicht wurde. Ziel ist es, hochwertige, skalierbare synthetische Datenressourcen für das multimodale Modelltraining bereitzustellen. Der Datensatz enthält über 400.000 Bild-Text-Frage-Antwort-Paare und unterstützt visuelle Antwortaufgaben.
Direkte Verwendung:https://go.hyper.ai/aNjiz
4. NonverbalTTS-Datensatz zur nonverbalen Audiogenerierung
NonverbalTTS ist ein von VK Lab und Yandex veröffentlichter Datensatz zur Generierung nonverbaler Audiodaten. Ziel ist es, die Forschung zu ausdrucksstarkem Text-to-Audio (TTS) zu fördern und Modelle zur Generierung natürlicher Sprache mit Emotionen und nonverbalen Klängen zu unterstützen.
Direkte Verwendung:https://go.hyper.ai/0Gz9V
5. GPT Image Edit-1,5M Bildgenerierungsdatensatz
GPT Image Edit-1.5M ist ein Bildgenerierungsdatensatz der University of California, Santa Cruz, und der University of Edinburgh. Er soll eine umfassende multimodale Datenressource für das Training und die Evaluierung von Bildbearbeitungsmodellen bereitstellen. Der Datensatz enthält über 1,5 Millionen hochwertige Triplets (Anleitung, Quellbild, bearbeitetes Bild).
Direkte Verwendung:https://go.hyper.ai/ohpmD

6. UniRef50-Proteinsequenz-Datensatz
Der UniRef50-Proteinsequenzdatensatz basiert auf der UniProt-Wissensdatenbank und wird durch iteratives Clustering aus UniParc-Sequenzen abgeleitet. Dieser iterative Prozess stellt sicher, dass die repräsentativen Sequenzen in UniRef50 qualitativ hochwertig, redundant und vielfältig sind und eine umfassende Abdeckung des Proteinsequenzraums für Proteinsprachenmodelle bieten.
Direkte Verwendung:https://go.hyper.ai/EcUF5
7. Benchmark-Datensatz zur differenzbewussten Fairness-Differenzwahrnehmung
Difference-Aware Fairness ist ein differenzbewusster Benchmark-Datensatz der Stanford University. Ziel ist es, die Leistung von Modellen in der Unterschiedswahrnehmung und Kontextsensitivität zu messen. Das zugehörige Paper wurde auf der ACL 2025 veröffentlicht und mit dem Best Paper Award ausgezeichnet.
Direkte Verwendung:https://go.hyper.ai/wwBos
8. T-Wix Russischer SFT-Datensatz
T-Wix ist ein SFT-Datensatz mit 499.598 russischen Sprachbeispielen, der die Fähigkeiten des Modells von der Lösung algorithmischer und mathematischer Probleme bis hin zu Konversation, logischem Denken und Argumentationsmustern verbessern soll.
Direkte Verwendung:https://go.hyper.ai/p0sgT
9. Von WebInstruct verifizierter Multi-Domain-Reasoning-Datensatz
WebInstruct-verified ist ein multidomänenbasierter Datensatz zum folgerichtigen Denken, der gemeinsam von der University of Waterloo und dem Vector Institute veröffentlicht wurde. Ziel ist es, die folgerichtigen Fähigkeiten von LL.M.-Studierenden in verschiedenen Bereichen zu verbessern und gleichzeitig ihre Stärken in Mathematik zu erhalten. Der Datensatz enthält rund 230.000 folgerichtige Fragen in verschiedenen Antwortformaten, darunter Multiple-Choice-Fragen und Datensätze zu numerischen Ausdrücken, mit einer ausgewogenen Verteilung auf die verschiedenen Bereiche.
Direkte Verwendung:https://go.hyper.ai/oCgsZ
10. Finance-Instruct-500k-Datensatz für Finanzinferenzen
Finance-Instruct-500k ist ein Datensatz zum Thema Finanz-Argumentation, der für das Training fortgeschrittener Sprachmodelle für Finanzaufgaben, Schlussfolgerungen und mehrstufige Dialoge entwickelt wurde. Der Datensatz enthält über 500.000 hochwertige Datensätze aus dem Finanzbereich und deckt die Beantwortung von Finanzfragen, Schlussfolgerungen, Stimmungsanalysen, Themenklassifizierung, mehrsprachige Named-Entity-Erkennung und Konversations-KI ab.
Direkte Verwendung:https://go.hyper.ai/03UVH
Ausgewählte öffentliche Tutorials
1. Higgs Audio V2: Die Ausdruckskraft der Sprachgenerierung neu definieren
Higgs Audio V2 ist ein umfangreiches Sprachmodell, das von Li Mu und seinem Team bei Boson AI veröffentlicht wurde. Es erreicht Spitzenleistungen bei traditionellen TTS-Benchmarks, darunter Seed-TTS Eval und Emotional Speech Dataset (ESD). Das Modell zeigt Fähigkeiten, die in früheren Systemen selten zu finden waren, darunter die automatische prosodische Adaption während der Erzählung und die Zero-Shot-Generierung natürlicher Mehrsprechergespräche in mehreren Sprachen.
Online ausführen:https://go.hyper.ai/BqZJD
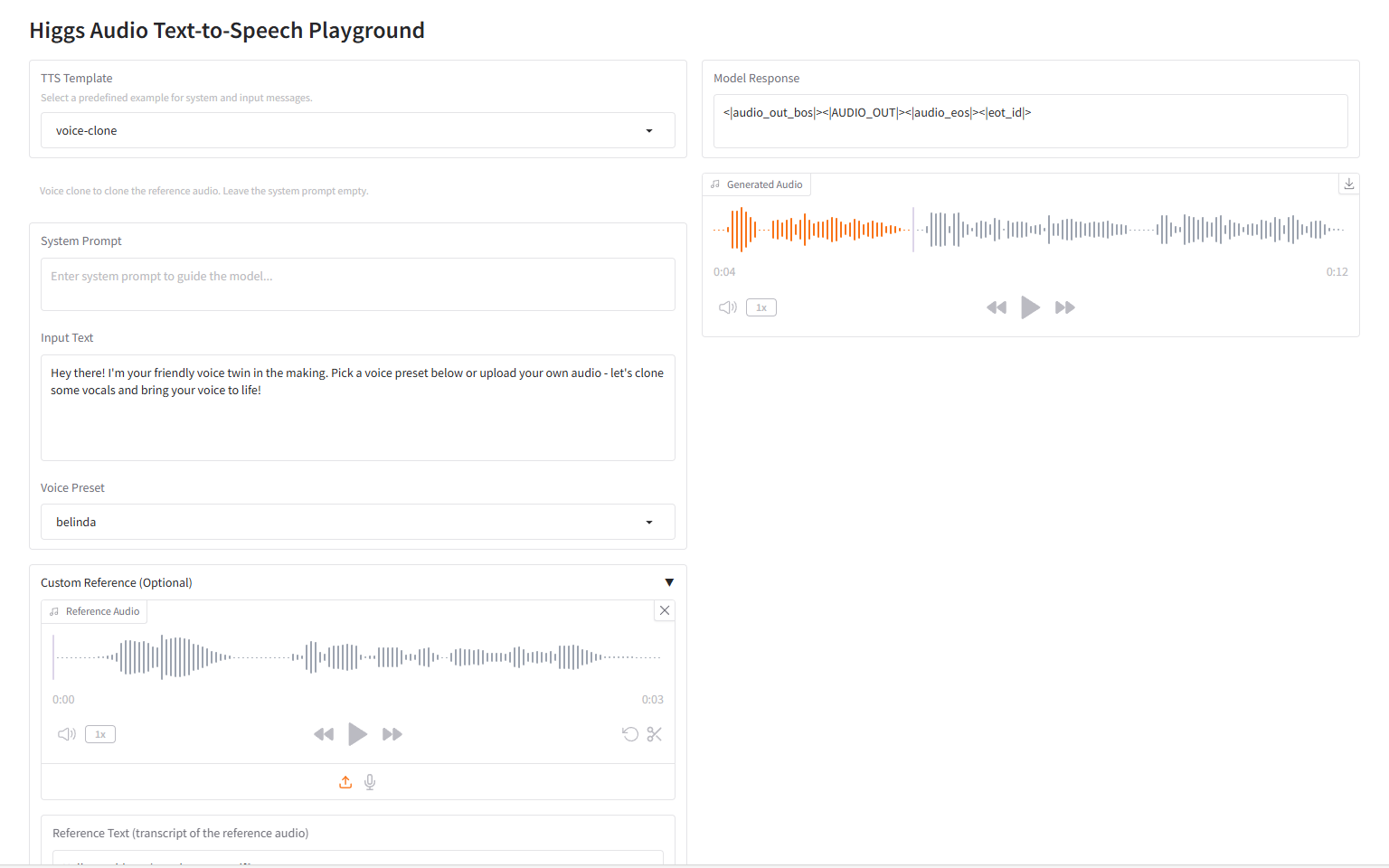
2. Ovis-U1-3B: Multimodales Verständnis- und Generierungsmodell
Ovis-U1-3B ist ein multimodales, einheitliches Modell, das vom Ovis-Team der Alibaba Group veröffentlicht wurde. Dieses Modell integriert drei Kernfunktionen: multimodales Verständnis, Text-zu-Bild-Generierung und Bildbearbeitung. Durch die Nutzung fortschrittlicher Architektur und kollaboratives, einheitliches Training ermöglicht es eine hochpräzise Bildsynthese und eine effiziente Text-zu-Bild-Interaktion.
Online ausführen:https://go.hyper.ai/oSA7p

3. Neta Lumina: Hochwertiges Bildgenerierungsmodell im 2D-Stil
Neta Lumina ist ein hochwertiges Bildgenerierungsmodell im Anime-Stil, das von Neta.art veröffentlicht wurde. Basierend auf Lumina-Image-2.0, der Open-Source-Arbeit des Alpha-VLLM-Teams am Shanghai Artificial Intelligence Laboratory, nutzt das Modell riesige Mengen hochwertiger Bilder im Anime-Stil und mehrsprachig beschrifteter Daten, um dem Modell leistungsstarke Funktionen zum Verständnis und zur Interpretation von Anforderungen zu verleihen.
Online ausführen:https://go.hyper.ai/nxCwD

4. Qwen-Image: Ein Bildmodell mit erweiterten Text-Rendering-Funktionen
Qwen-Image ist ein groß angelegtes Modell zur hochwertigen Bilderzeugung und -bearbeitung, das vom Alibaba Tongyi Qianwen-Team entwickelt wurde. Dieses Modell erzielt Durchbrüche bei der Textwiedergabe, unterstützt die hochauflösende Ausgabe auf mehrzeiliger Absatzebene sowohl in Chinesisch als auch in Englisch und gibt komplexe Szenen und millimetergenaue Details präzise wieder.
Online ausführen:https://go.hyper.ai/8s00s

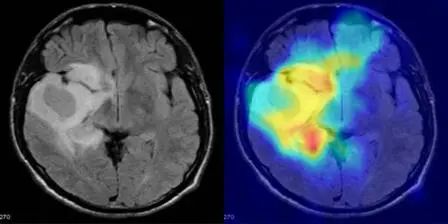
5. MediCLIP: Anomalieerkennung in kleinen Stichproben medizinischer Bilder mit CLIP
MediCLIP, veröffentlicht von der Peking-Universität, ist eine effiziente Methode zur Erkennung von Anomalien in medizinischen Bildern mit wenigen Aufnahmen, die mit nur einer sehr kleinen Anzahl normaler medizinischer Bilder eine hochmoderne Anomalieerkennungsleistung erreicht. Das Modell integriert lernbare Hinweise, Adapter und realistische Aufgaben zur Anomaliesynthese in medizinischen Bildern.
Online ausführen:https://go.hyper.ai/3BnDy
6. Aeneas-Modell: Demo zur Restaurierung antiker römischer Inschriften
Aeneas ist ein multimodales generatives neuronales Netzwerk, das von Google DeepMind in Zusammenarbeit mit mehreren Universitäten entwickelt wurde. Es dient der Textrestaurierung sowie der geographischen und chronologischen Zuordnung lateinischer und altgriechischer Inschriften. Die Veröffentlichung dieses Modells markiert eine neue Ära in der digitalen Epigraphik. Sein Potenzial in Bereichen wie der Restaurierung antiker Texte, der geographischen/chronologischen Zuordnung und der Unterstützung historischer Forschung ist enorm und wird voraussichtlich wissenschaftliche Entdeckungen und interdisziplinäre Anwendungen beschleunigen.
Online ausführen:https://go.hyper.ai/8ROfT

7. Ein-Klick-Bereitstellung von Qwen3-Coder-30B-A3B-Instruct
Qwen3-Coder-30B-A3B-Instruct ist ein umfangreiches Sprachmodell, das vom Tongyi Wanxiang Lab von Alibaba entwickelt wurde. Es zeigt eine bemerkenswerte Leistung in offenen Modellen für Proxy-Codierung, Proxy-Browser-Nutzung und andere grundlegende Codierungsaufgaben und kann Codierungsaufgaben in mehreren Programmiersprachen effizient bewältigen. Sein leistungsstarkes Kontextverständnis und seine logischen Argumentationsfähigkeiten machen es zu einer ausgezeichneten Wahl für die Entwicklung komplexer Projekte und die Codeoptimierung.
Online ausführen:https://go.hyper.ai/vYf3s
💡Wir haben außerdem eine Austauschgruppe für Tutorials zur stabilen Diffusion eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~

Die Zeitungsempfehlung dieser Woche
1. Technischer Bericht zu Qwen-Image
Qwen-Image, ein grundlegendes Bildgenerierungsmodell der Qwen-Familie, hat bedeutende Fortschritte bei der komplexen Textwiedergabe und präzisen Bildbearbeitung erzielt. Um die Herausforderungen der komplexen Textwiedergabe zu bewältigen, entwickelten die Forscher eine umfassende Datenverarbeitungspipeline, die umfangreiche Datenerfassung, Filterung, Annotation, Synthese und Balancing umfasst. Das Modell erreicht in mehreren Benchmarks Spitzenleistung und stellt seine Leistungsfähigkeit bei der Bildgenerierung und -bearbeitung voll unter Beweis.
Link zum Artikel:https://go.hyper.ai/HWjVM
2. Seed Diffusion: Ein groß angelegtes Diffusionssprachenmodell mit Hochgeschwindigkeitsinferenz
Dieses Dokument stellt Seed Diffusion Preview vor, ein groß angelegtes Sprachmodell, das auf einem diskreten Zustandsdiffusionsmechanismus basiert und eine extrem hohe Inferenzgeschwindigkeit bietet. Dank seines nicht-sequenziellen, parallelen Generierungsmechanismus verbessert das diskrete Diffusionsmodell die Inferenzeffizienz erheblich und reduziert effektiv die inhärente Latenz, die mit der herkömmlichen Token-für-Token-Dekodierung verbunden ist.
Link zum Artikel:https://go.hyper.ai/NvrNm
3. Cognitive Kernel-Pro: Ein Framework für Deep Research Agents und Agent Foundation Models Training
Allgemeine KI-Agenten gelten zunehmend als Eckpfeiler der nächsten Generation künstlicher Intelligenz, da sie komplexes Denken, vernetzte Interaktion, Programmierung und autonome Forschung ermöglichen. In dieser Studie schlagen Forscher Cognitive Kernel-Pro vor, ein vollständig quelloffenes und weitgehend kostenloses, mehrmoduliges intelligentes Agenten-Framework, das die Entwicklung und Evaluierung fortschrittlicher KI-Agenten demokratisieren soll.
Link zum Artikel:https://go.hyper.ai/65j3v
4. Mehr als nur fest: Rauschunterdrückung mit variabler Länge für die Diffusion großer Sprachmodelle
In diesem Artikel schlagen Forscher eine neuartige, trainingsfreie Rauschunterdrückungsstrategie namens DAEDAL vor, die eine dynamische, adaptive Längenerweiterung von DLLMs ermöglicht. Umfangreiche Experimente mit verschiedenen DLLMs zeigen, dass DAEDAL die Leistung sorgfältig abgestimmter Basismodelle mit fester Länge erreicht und in einigen Fällen sogar übertrifft. Gleichzeitig verbessert es die Recheneffizienz deutlich und erreicht ein höheres effektives Token-Verhältnis.
Link zum Artikel:https://go.hyper.ai/p7WxK
5. Skywork UniPic: Einheitliche autoregressive Modellierung für visuelles Verständnis und Generierung
Dieses Dokument stellt Skywork UniPic vor, ein autoregressives Modell mit 1,5 Milliarden Parametern, das Bildverständnis, Text-zu-Bild-Generierung und Bildbearbeitung in einer einzigen Architektur vereint, ohne auf aufgabenspezifische Adapter oder modulübergreifende Konnektoren angewiesen zu sein. Indem Skywork UniPic zeigt, dass hochpräzise multimodale Fusion ohne unerschwingliche Ressourcenkosten erreicht werden kann, etabliert es ein praktisches Paradigma für einsetzbare, hochpräzise multimodale KI.
Link zum Artikel:https://go.hyper.ai/FiVaf
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
Ein Forschungsteam der University of Nevada in Las Vegas hat eine multivariate Analysemethode namens ICA-Var vorgeschlagen, die auf der Entwicklung unüberwachter maschineller Lernprozesse basiert. Durch unabhängige Komponentenanalyse extrahiert es Kovariationen und sich im Laufe der Zeit entwickelnde Mutationsmuster aus Abwasserdaten und ermöglicht so eine frühere und genauere Erkennung von Varianten.
Den vollständigen Bericht ansehen:https://go.hyper.ai/z1vVo
Das Qwen-Team hat Qwen3-Coder-Flash als Open Source veröffentlicht. Es bietet unter den Open-Source-Modellen die beste Leistung bei Proxy-Codierung, Proxy-Browser-Nutzung und anderen grundlegenden Codierungsaufgaben. Es kann Codierungsaufgaben in mehreren Programmiersprachen effizient bewältigen. Gleichzeitig ermöglichen sein leistungsstarkes Kontextverständnis und seine logischen Denkfähigkeiten eine gute Leistung bei der Entwicklung komplexer Projekte und der Codeoptimierung.
Den vollständigen Bericht ansehen:https://go.hyper.ai/FmOep
Um das Problem der gezielten Ansteuerung natürlich ungeordneter Proteine zu lösen, schlugen David Baker und sein Team eine Proteindesignstrategie namens Logos vor. Diese ermöglicht es Proteinen, in verschiedenen ausgedehnten Konformationen an natürlich ungeordnete Regionen zu binden, wobei sich Seitenketten in komplementäre Bindungstaschen einfügen. Diese Studie nutzt das RFdiffusionsmodell, um Taschen neu zu organisieren und auf ein breites Spektrum von Sequenzen zu verallgemeinern. Dies ermöglicht die universelle Erkennung ungeordneter Proteinregionen basierend auf einer entwickelten Vorlage für bindende Protein-Zielpeptide.
Den vollständigen Bericht ansehen:https://go.hyper.ai/F0lti
Die Forschungsgruppe von Zhou Hao am Institute of Intelligent Industries der Tsinghua-Universität entwickelte in Zusammenarbeit mit dem Shanghai Artificial Intelligence Laboratory das Protein-Grundlagenmodell AMix-1 auf Basis bayesscher Flussnetzwerke. Zum ersten Mal nutzten sie die systematische Methodik des Vortrainings-Skalierungsgesetzes, emergenter Fähigkeiten, kontextbezogenem Lernen und Testzeitskalierung, um ein Protein-Grundlagenmodell zu konstruieren und führten damit das erfolgreiche Paradigma großer Sprachmodelle in das Proteindesign ein. Ihre Effizienz und Vielseitigkeit wurden durch Testzeitskalierung und reale Experimente verifiziert.
Den vollständigen Bericht ansehen:https://go.hyper.ai/X9iMe
OpenAI hat GPT-5 offiziell veröffentlicht und damit die Leistung in den drei häufigsten Anwendungsfällen von ChatGPT weiter verbessert: Schreiben, Programmieren und Gesundheit. GPT-5 ist ein einheitliches System, das aus einem intelligenten und effizienten Modell zur Beantwortung der meisten Fragen (GPT-5-main), einem Deep-Reasoning-Modell für komplexere Probleme (GPT-5-thinking) und einem Echtzeit-Router besteht, der schnell entscheidet, welches Modell verwendet werden soll, basierend auf Konversationstyp, Fragenkomplexität, erforderlichen Tools und der expliziten Absicht des Benutzers.
Den vollständigen Bericht ansehen:https://go.hyper.ai/gFHQg
Beliebte Enzyklopädieartikel
1. DALL-E
2. Reziproke Sortierfusion RRF
3. Pareto-Front
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kontrastives Lernen
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:https://go.hyper.ai/wiki
August-Frist für den Gipfel
21. August 11:59:59 ASPLOS 2026
27. August 7:59:59 USENIX Sicherheitssymposium 2025
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








