Command Palette
Search for a command to run...
Google DeepMind Veröffentlicht Perch 2.0, Das Fast 15.000 Arten Abdeckt Und Einen Neuen Stand Der Technik Für Die Bioakustische Klassifizierung Und Erkennung setzt.

Die Bioakustik ist ein wichtiges Instrument, das Biologie und Ökologie verbindet und eine Schlüsselrolle beim Schutz und der Überwachung der Artenvielfalt spielt. Die frühe Forschung stützte sich auf traditionelle Signalverarbeitungsmethoden wie das Template-Matching, deren Grenzen jedoch angesichts komplexer natürlicher akustischer Umgebungen und umfangreicher Daten zunehmend an ihre Grenzen gestoßen sind, da sie ineffizient und ungenau sind.
In den letzten Jahren hat das explosionsartige Wachstum der künstlichen Intelligenz (KI) dazu geführt, dass Deep Learning und andere Methoden traditionelle Ansätze abgelöst haben und zu zentralen Werkzeugen für die Erkennung und Klassifizierung bioakustischer Ereignisse geworden sind. Beispielsweise hat das BirdNET-Modell, das mit umfangreichen, gekennzeichneten Vogelakustikdaten trainiert wurde, eine außergewöhnliche Leistung bei der Erkennung von Vogelstimmen gezeigt: Es kann nicht nur die Rufe verschiedener Arten präzise unterscheiden, sondern ermöglicht bis zu einem gewissen Grad auch die Identifizierung einzelner Arten. Darüber hinaus haben Modelle wie Perch 1.0 durch kontinuierliche Optimierung und Iteration umfangreiche Erfolge auf dem Gebiet der Bioakustik erzielt und bieten solide technische Unterstützung für die Überwachung und den Schutz der Artenvielfalt.
Vor ein paar TagenPerch 2.0, gemeinsam von Google DeepMind und Google Research gestartet,Perch 2.0 hebt die bioakustische Forschung auf ein neues Niveau und betrachtet die Artenklassifizierung als zentrale Trainingsaufgabe. Es integriert nicht nur mehr Trainingsdaten von Nicht-Vogelgruppen, sondern setzt auch neue Strategien zur Datenerweiterung und Trainingsziele ein.Dieses Modell hat den aktuellen SOTA in zwei maßgeblichen bioakustischen Benchmarks, BirdSET und BEANS, aktualisiert.Es weist ein starkes Leistungspotenzial und breite Anwendungsmöglichkeiten auf.
Die entsprechenden Forschungsergebnisse wurden als Preprint auf arXiv unter dem Titel „Perch 2.0: The Bittern Lesson for Bioacoustics“ veröffentlicht.
Papieradresse:
https://arxiv.org/abs/2508.04665
Folgen Sie dem offiziellen Konto und antworten Sie mit „Bioacoustics“, um das vollständige PDF zu erhalten
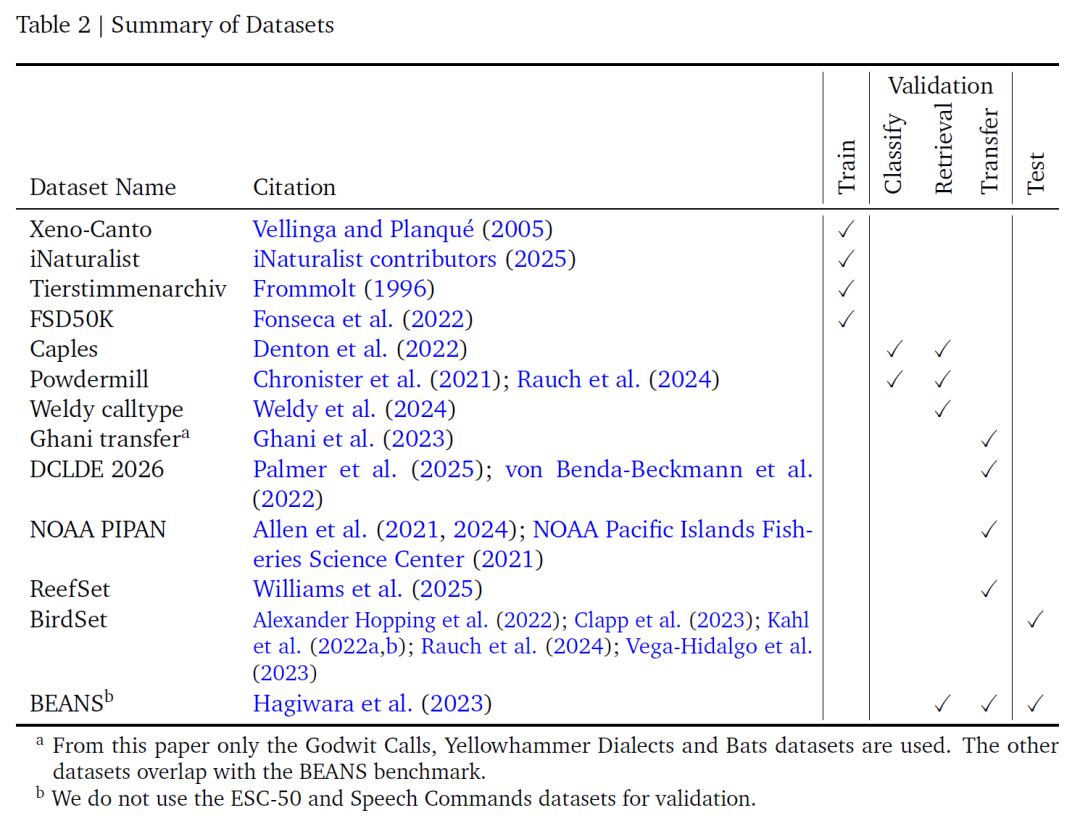
Datensatz: Benchmark für die Konstruktion und Auswertung von Trainingsdaten
Diese Studie integrierte vier beschriftete Audio-Datensätze für das Modelltraining: Xeno-Canto, iNaturalist, Tierstimmenarchiv und FSD50K.Zusammen bilden sie die grundlegende Datenbasis für das Modelllernen. Wie die folgende Tabelle zeigt, sind Xeno-Canto und iNaturalist große Citizen-Science-Repositorien: Auf Xeno-Canto wird über eine öffentliche API zugegriffen, während iNaturalist aus Audiodaten mit Forschungsqualität auf der GBIF-Plattform stammt. Beide enthalten eine große Anzahl von akustischen Aufnahmen von Vögeln und anderen Lebewesen. Das Tierstimmenarchiv des Berliner Museums für Naturkunde konzentriert sich ebenfalls auf Bioakustik. FSD50K ergänzt dies schließlich durch eine Vielzahl von Nicht-Vogel-Geräuschen.
Diese vier Datenkategorien enthalten insgesamt 14.795 Kategorien.Davon waren 14.597 Arten und die restlichen 198 Nicht-Arten-Schallereignisse. Diese umfassende Kategorieabdeckung gewährleistet nicht nur ein tiefes Lernen bioakustischer Signale, sondern erweitert auch die Anwendbarkeit des Modells durch die Einbeziehung von Nicht-Vogelgeräuschdaten. Da die ersten drei Datensätze jedoch unterschiedliche Artenklassifizierungssysteme verwendeten, hat das Forschungsteam die Kategorienamen manuell zugeordnet und vereinheitlicht und Fledermausaufzeichnungen entfernt, die mit den ausgewählten Spektrogrammparametern nicht dargestellt werden konnten, um Datenkonsistenz und Anwendbarkeit zu gewährleisten.
In Anbetracht der Tatsache, dass die Aufzeichnungsdauer verschiedener Datenquellen stark variiert (von weniger als 1 Sekunde bis über 1 Stunde, die meisten dauern 5 bis 150 Sekunden) und das Modell auf 5-Sekunden-Clips als Eingabe festgelegt ist,Das Forschungsteam entwickelte zwei Strategien zur Fensterauswahl:Bei der Zufallsfensterstrategie werden bei der Auswahl einer Aufnahme zufällig 5 Sekunden abgefangen. Dies kann zwar Abschnitte enthalten, in denen die Zielart keine Laute von sich gab, was zu einem gewissen Label-Rauschen führen kann, liegt aber im Allgemeinen in einem akzeptablen Bereich. Die Energiespitzenstrategie folgt der Idee von Perch 1.0 und wählt mithilfe der Wavelet-Transformation den 6-Sekunden-Bereich mit der stärksten Energie in der Aufnahme aus. Anschließend werden 5 Sekunden aus diesem Bereich zufällig ausgewählt, um die Stichprobenvalidität zu verbessern, basierend auf der Annahme, dass „energiereiche Bereiche eher die Laute der Zielart enthalten“.Diese Methode entspricht der Detektordesignlogik von Modellen wie BirdNET und kann effektive akustische Signale genauer erfassen.
Um die Anpassungsfähigkeit des Modells an komplexe akustische Umgebungen weiter zu verbessern, hat das Forschungsteam eine Datenerweiterungsvariante von Mixup übernommen.Generieren Sie ein zusammengesetztes Signal, indem Sie mehrere Audiofenster mischen:Zunächst wird die Anzahl der gemischten Audiosignale durch Stichprobennahme aus der Beta-Binomialverteilung ermittelt. Anschließend werden die Gewichte über die symmetrische Dirichlet-Verteilung abgetastet. Die ausgewählten Mehrfachsignale werden gewichtet, summiert und die Verstärkungen normalisiert.
Im Gegensatz zum ursprünglichen Mixup verwendet diese Methode einen gewichteten Durchschnitt von Multi-Hot-Zielvektoren anstelle von One-Hot-Vektoren. Dadurch wird sichergestellt, dass alle Geräusche innerhalb des Fensters (unabhängig von der Lautstärke) mit hoher Zuverlässigkeit identifiziert werden können. Die Optimierung der relevanten Parameter als Hyperparameter kann die Fähigkeit des Modells verbessern, überlappende Geräusche zu unterscheiden und die Klassifizierungsgenauigkeit zu verbessern.
Die Modellbewertung basiert auf zwei maßgeblichen Benchmarks: BirdSet und BEANS. BirdSet enthält sechs vollständig annotierte Soundscape-Datensätze aus den kontinentalen Vereinigten Staaten, Hawaii, Peru und Kolumbien. Bei der Auswertung erfolgt keine Feinabstimmung, und die Ausgabe des Prototyp-Lernklassifikators wird direkt verwendet; BEANS deckt zwölf kategorieübergreifende Testaufgaben ab (mit Vögeln, Land- und Meeressäugetieren, Anuren und Insekten). Nur sein Trainingssatz wird zum Trainieren linearer und prototypischer Sonden verwendet, und das Einbettungsnetzwerk wird ebenfalls nicht angepasst.
Perch 2.0: Ein leistungsstarkes bioakustisches Vortrainingsmodell
Die Modellarchitektur von Perch 2.0 besteht aus einem Frontend, einem Einbettungsmodell und einer Reihe von Ausgabeköpfen.Diese Teile arbeiten zusammen, um den gesamten Prozess vom Audiosignal bis zur Artenidentifizierung zu ermöglichen.
In,Das Frontend ist für die Konvertierung des Rohaudios in eine Feature-Form verantwortlich, die das Modell verarbeiten kann.Es empfängt Mono-Audio mit einer Abtastrate von 32 kHz und generiert für ein 5-Sekunden-Segment (mit 160.000 Abtastpunkten) durch Verarbeitung mit einer Fensterlänge von 20 ms und einer Sprunglänge von 10 ms ein Log-Mel-Spektrogramm mit 500 Frames und 128 Mel-Bändern pro Frame. Dadurch wird der Frequenzbereich von 60 Hz bis 16 kHz abgedeckt und grundlegende Funktionen für die anschließende Analyse bereitgestellt.
Das Einbettungsnetzwerk übernimmt die EfficientNet-B3-ArchitekturDies ist ein Faltungs-Restnetzwerk mit 120 Millionen Parametern, das die Parametereffizienz durch Verwendung eines tiefentrennbaren Faltungsdesigns maximiert. Im Vergleich zum 78 Millionen Parameter umfassenden EfficientNet-B1 der vorherigen Perch-Version ist es größer, um dem Wachstum der Trainingsdaten gerecht zu werden.
Nach der Verarbeitung durch das Einbettungsnetzwerk wird eine räumliche Einbettung mit der Form (5, 3, 1536) erhalten (die Dimensionen entsprechen jeweils Zeit-, Frequenz- und Merkmalskanälen). Nach der Mittelung der räumlichen Dimensionen kann eine 1536-dimensionale globale Einbettung erhalten werden, die als Kernmerkmal für die nachfolgende Klassifizierung dient.
Der Ausgabekopf ist für bestimmte Vorhersage- und Lernaufgaben verantwortlich.Es besteht aus drei Teilen: Der lineare Klassifikator projiziert die globale Einbettung in einen 14.795-dimensionalen Kategorienraum und macht durch Training die Einbettungen verschiedener Arten linear trennbar, wodurch der lineare Erkennungseffekt bei der Anpassung an neue Aufgaben verbessert wird. Der Prototyp-Lernklassifikator verwendet die räumliche Einbettung als Eingabe, lernt 4 Prototypen für jede Kategorie und wählt den Prototyp mit der maximalen Aktivierung für die Vorhersage. Dieses Design ist vom AudioProtoPNet im Bereich der Bioakustik abgeleitet. Der Quellenvorhersagekopf ist ein linearer Klassifikator, der die ursprüngliche Aufnahmequelle des Audioclips basierend auf der globalen Einbettung vorhersagt. Da der Trainingssatz mehr als 1,5 Millionen Quellenaufnahmen enthält, wird eine effiziente Berechnung durch eine Low-Rank-Projektion mit Rang 512 erreicht, was dem Erlernen des selbstüberwachten Quellenvorhersageverlusts dient.
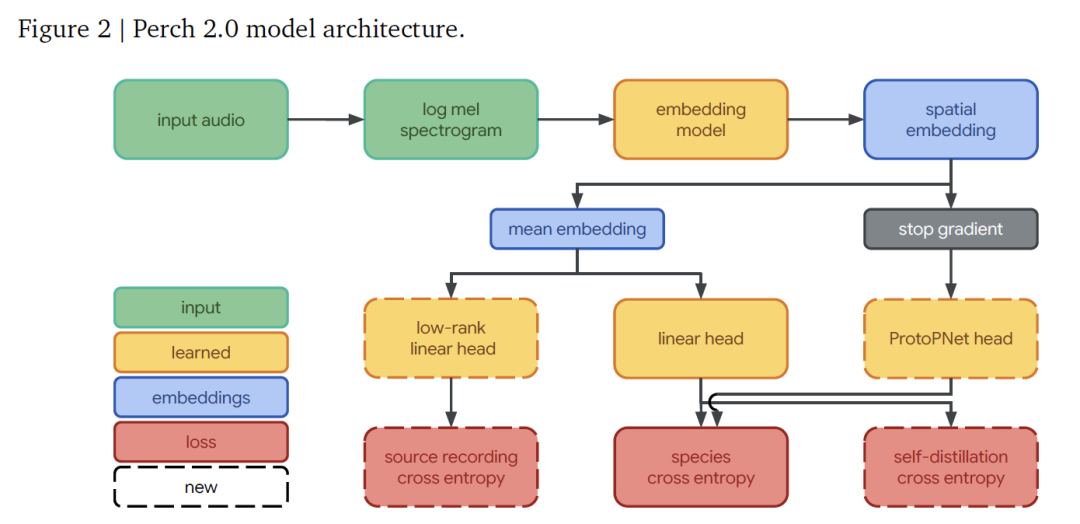
Das Modelltraining wird durchgängig durch drei unabhängige Ziele optimiert:
* Kreuzentropie für die Artenklassifizierung verwendet Softmax-Aktivierung und Kreuzentropieverlust für lineare Klassifikatoren und weist den Zielkategorien einheitliche Gewichte zu;
Beim Selbstdestillationsmechanismus fungiert der Prototyp-Lernklassifizierer als „Lehrer“, dessen Vorhersagen den linearen „Schüler“-Klassifizierer leiten, während der Prototypunterschied durch den orthogonalen Verlust maximiert wird und der Gradient nicht zurück zum Einbettungsnetzwerk propagiert wird.
* Die Quellenvorhersage wird als selbstüberwachtes Ziel verwendet, wobei die Originalaufzeichnungen als unabhängige Kategorien für das Training behandelt werden und das Modell dazu angehalten wird, hervorstechende Merkmale zu erfassen.
Die Ausbildung gliedert sich in zwei Phasen:Die erste Phase konzentrierte sich auf das Training des Prototyp-Lernklassifikators (ohne Selbstdestillation, bis zu 300.000 Schritte); die zweite Phase ermöglichte die Selbstdestillation (bis zu 400.000 Schritte), beides unter Verwendung des Adam-Optimierers.
Die Auswahl der Hyperparameter basiert auf dem Vizier-Algorithmus.In der ersten Phase werden Lernrate, Abbruchrate usw. ermittelt und nach zwei Screening-Runden das optimale Modell ermittelt. In der zweiten Phase wird das Selbstdestillationsverlustgewicht erhöht und die Suche fortgesetzt. Die beiden Fensterstichprobenverfahren werden durchgehend verwendet.
Die Ergebnisse zeigen, dass in der ersten Phase bevorzugt 2–5 Signale gemischt werden, wobei der Verlust der Quellenvorhersage zwischen 0,1 und 0,9 liegt. Die Selbstdestillationsphase tendiert zu einer niedrigen Lernrate, verwendet weniger Mixup und weist dem Selbstdestillationsverlust ein hohes Gewicht von 1,5–4,5 zu. Diese Parameter unterstützen die Modellleistung.
Bewertung der Generalisierungsfähigkeit von Perch 2.0: Basisleistung und praktischer Wert
Die Evaluierung von Perch 2.0 konzentriert sich auf die Generalisierungsfähigkeit und untersucht die Leistung bei Vogelklanglandschaften (die sich deutlich von den Trainingsaufnahmen unterscheiden) und bei nicht-artbezogenen Identifikationsaufgaben (wie der Rufartenidentifikation) sowie die Übertragbarkeit auf nicht-vogelartige Gruppen wie Fledermäuse und Meeressäuger. Da Praktiker oft mit kleinen oder gar keinen gekennzeichneten Daten arbeiten müssen,Das Kernprinzip der Evaluierung besteht darin, die Wirksamkeit des „eingefrorenen eingebetteten Netzwerks“ zu überprüfen.Das heißt, durch die gleichzeitige Extraktion von Merkmalen können neue Aufgaben wie Clustering und Lernen kleiner Stichproben schnell angepasst werden.
Die Modellauswahlphase überprüft die Praxistauglichkeit unter drei Gesichtspunkten:
* Leistung des vortrainierten Klassifikators unter Verwendung von ROC-AUC zur Bewertung der sofort einsatzbereiten Möglichkeiten zur Artenvorhersage anhand eines vollständig annotierten Vogeldatensatzes;
* Ein-Beispiel-Abruf unter Verwendung der Kosinusdistanz zur Messung der Cluster- und Suchleistung;
* Lineare Migration, Simulation kleiner Beispielszenarien zum Testen der Anpassungsfähigkeit.
Die Punktzahlen dieser Aufgaben werden durch geometrisches Mittel berechnet und die Endergebnisse der 19 Unterdatensätze spiegeln die tatsächliche Verwendbarkeit des Modells wider.
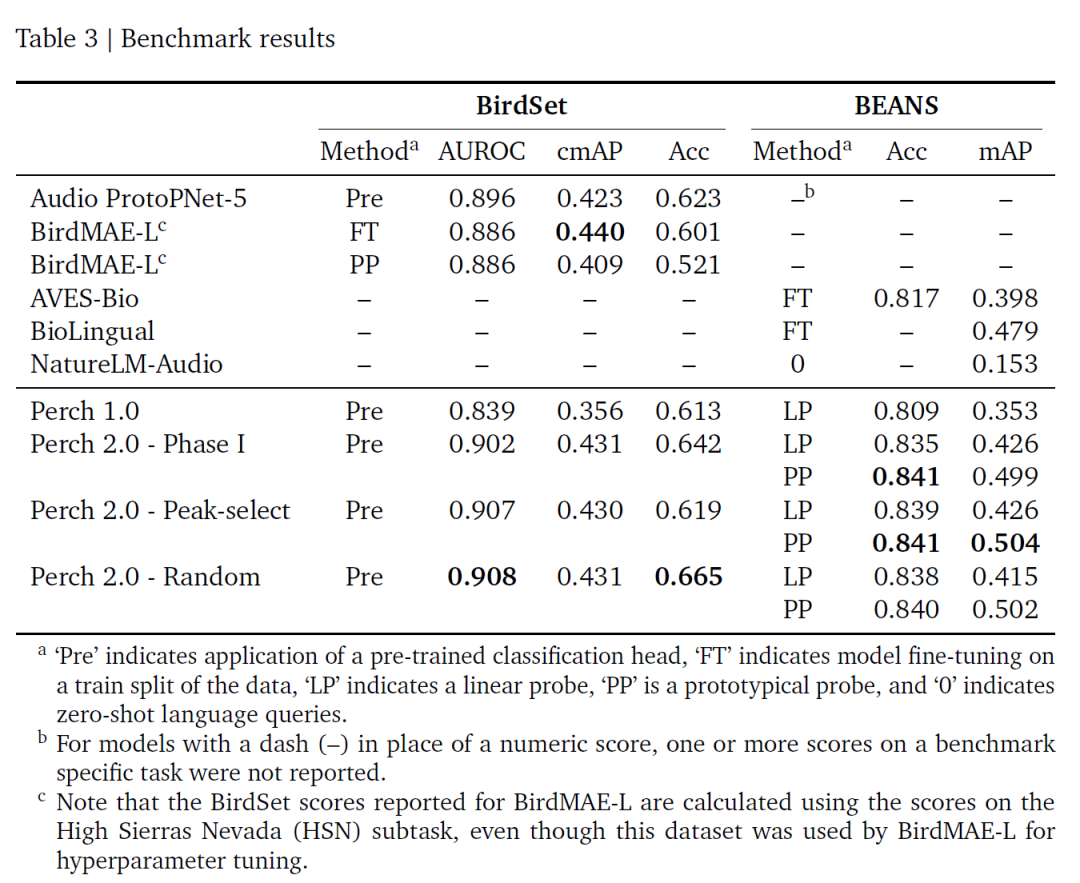
Basierend auf den beiden Benchmarks von BirdSet und BEANS sind die Bewertungsergebnisse dieser Studie in der folgenden Tabelle dargestellt:Perch 2.0 weist bei vielen Indikatoren eine hervorragende Leistung auf, insbesondere bei ROC-AUC, das derzeit das beste ist.Und es ist keine Feinabstimmung erforderlich; die Trainingsstrategien für Zufallsfenster und Energiespitzenfenster weisen eine ähnliche Leistung auf, vermutlich weil die Selbstdestillation die Auswirkungen des Etikettenrauschens verringert.
Insgesamt basiert Perch 2.0 auf überwachtem Lernen und ist eng mit bioakustischen Eigenschaften verbunden. Der Durchbruch von Perch 2.0 zeigt, dassFür hochwertiges Transferlernen sind keine sehr großen Modelle erforderlich. Fein abgestimmte überwachte Modelle in Kombination mit Datenerweiterung und zusätzlichen Zielen können gute Ergebnisse erzielen.Das feste Einbettungsdesign (das wiederholte Feinabstimmungen überflüssig macht) reduziert die Kosten der Datenverarbeitung im großen Maßstab und ermöglicht eine agile Modellierung. Zukünftige Entwicklungen in diesem Bereich umfassen die Erstellung realistischer Bewertungsmaßstäbe, die Entwicklung neuer Aufgaben unter Verwendung von Metadaten und die Erforschung des halbüberwachten Lernens.
Die Schnittstelle zwischen Bioakustik und künstlicher Intelligenz
An der Schnittstelle zwischen Bioakustik und künstlicher Intelligenz haben Forschungsrichtungen wie kategorienübergreifendes Transferlernen, selbstüberwachtes Zieldesign und die Optimierung von Netzwerken mit fester Einbettung zu umfangreichen Untersuchungen in der Wissenschaft und Wirtschaft auf der ganzen Welt geführt.
Die vom Team der Universität Cambridge entwickelte Cosine Distance Virtual Adversarial Training (CD-VAT)-Technologie verbessert die Unterscheidbarkeit akustischer Einbettungen durch Konsistenzregularisierung.Stellt eine Verbesserung der Fehlerrate von 32,51 % TP3T bei einer groß angelegten Sprecherüberprüfungsaufgabe wieder her.Bietet ein neues Paradigma für halbüberwachtes Lernen bei der Spracherkennung.
MIT und CETI arbeiten bei der Erforschung der Stimmabdrücke von Pottwalen zusammen.Durch maschinelles Lernen wird ein „Klangalphabet“ bestehend aus Rhythmus, Takt, Tremolo und Verzierung herausgearbeitet.Die Komplexität ihres Kommunikationssystems erwies sich als weitaus größer als erwartet – allein der Pottwalstamm der Ostkaribik verfügt über mindestens 143 unterscheidbare Lautkombinationen und seine Informationsübertragungskapazität übersteigt sogar die Grundstruktur der menschlichen Sprache.
Die von der ETH Zürich entwickelte photoakustische Bildgebungstechnologie durchbricht die akustische Beugungsgrenze, indem sie Mikrokapseln mit Eisenoxid-Nanopartikeln belädt.Erzielen Sie eine superauflösende Abbildung tiefer Gewebemikrogefäße (Auflösung bis zu 20 Mikrometer),Es hat das Potenzial für die dynamische Überwachung mehrerer Parameter in der Hirnforschung und Tumorforschung aufgezeigt.
gleichzeitig,Das Open-Source-Projekt BirdNET hat weltweit 150 Millionen Aufnahmen gesammelt.Es hat sich zu einem Benchmark-Tool für die ökologische Überwachung entwickelt. Die leichtgewichtige Version, BirdNET-Lite, kann in Echtzeit auf Edge-Geräten wie Raspberry Pi ausgeführt werden, unterstützt die Identifizierung von mehr als 6.000 Vogelarten und bietet eine kostengünstige Lösung für die Biodiversitätsforschung.
Das von der japanischen Firma Hylable im Hibiya-Park eingesetzte KI-Vogelgesangserkennungssystem kombiniert ein Multimikrofon-Array mit DNN.Erzielen Sie eine gleichzeitige Ausgabe der Schallquellenlokalisierung und der Artenidentifizierung mit einer Genauigkeitsrate von über 95%.Der fachliche Rahmen wurde auf die Bereiche der ökologischen Bewertung städtischer Grünflächen und des barrierefreien Gebäudebaus erweitert.
Es ist erwähnenswert, dassDas Projekt Zoonomia von Google DeepMind erforscht die evolutionären Mechanismen akustischer Gemeinsamkeiten zwischen Arten, indem es genomische und akustische Daten von 240 Säugetierarten integriert.Die Studie ergab, dass die harmonische Energieverteilung des freudigen Bellens von Hunden (Verhältnis der 3. zur 5. Harmonischen: 0,78±0,12) eine hohe Homologie zum sozialen Pfeifen von Delfinen (0,81±0,09) aufweist. Diese molekularbiologische Korrelation bildet nicht nur die Grundlage für die artenübergreifende Modellmigration, sondern inspiriert auch zu einem neuen Modellierungsansatz für „biologisch inspirierte KI“ – die Einbeziehung von Informationen aus dem Evolutionsbaum in das Training eingebetteter Netzwerke und damit die Überwindung der Grenzen traditioneller bioakustischer Modelle.
Diese Forschungen verleihen der Verbindung von Bioakustik und künstlicher Intelligenz eine neue Dimension. Wenn die Tiefe akademischer Forschung auf die Breite industrieller Anwendung trifft, werden Lebenssignale, die einst in Regenwaldkronen und Tiefseeriffen verborgen waren, deutlicher erfasst und interpretiert. Dies führt letztendlich zu Handlungsleitfäden zum Schutz bedrohter Arten und intelligenten Lösungen für das harmonische Zusammenleben von Städten und Natur.
Referenzlinks:
1.https://mp.weixin.qq.com/s/ZWBg8zAQq0nSRapqDeETsQ
2.https://mp.weixin.qq.com/s/UdGi6iSW-j_kcAaSsGW3-A
3.https://mp.weixin.qq.com/s/57sXpOs7vRhmopPubXTSXQ
Scannen Sie den entsprechenden QR-Code, um auf hochwertige AI4S-Dokumente von 2023 bis 2024 nach Fachgebieten zuzugreifen, einschließlich ausführlicher Interpretationsberichte ⬇️









