Command Palette
Search for a command to run...
ACL 25 Bestes Paper! Stanford University Veröffentlicht Difference-Aware Benchmark-Datensatz Zum Aufbau Differenzbewusster Fairness; Self-Forcing Ermöglicht Echtzeit-Streaming-Videogenerierung Mit Einer Latenz Von Unter Einer Sekunde

KI-Modelle setzen traditionelle „Gleichbehandlung“ oft mit Fairness gleich.In rechtlichen Zusammenhängen und bei der Schadensbewertung ist die mechanische Anwendung des Grundsatzes der „nichtdiskriminierenden Behandlung“ zur Erreichung von Fairness keine universelle Lösung.Eine einzelne Fairnessdimension kann leicht zu verzerrten Ergebnissen führen, was darauf hindeutet, dass Gruppenunterschiede berücksichtigt werden sollten.Daher ist es zunehmend wichtiger, große Modelle zu fördern, um schrittweise einen Paradigmenwechsel von „Fairness ohne Unterscheidung“ zu „Fairness basierend auf wahrgenommenen Unterschieden“ zu erreichen.
Auf dieser GrundlageDie Stanford University hat den Benchmark-Datensatz „Difference Aware Fairness“ veröffentlicht, der die Leistung von Modellen in Bezug auf die Wahrnehmung von Unterschieden und das Kontextbewusstsein messen soll.Die entsprechenden Forschungsergebnisse wurden als die 25 besten Arbeiten des ACL ausgezeichnet. Der Datensatz enthält acht Benchmarks, unterteilt in zwei Typen: deskriptive und normative Aufgaben, die eine Vielzahl realer Szenarien aus den Bereichen Recht, Beruf und Kultur abdecken. Jeder Benchmark enthält 2.000 Fragen, von denen 1.000 eine Differenzierung zwischen verschiedenen Gruppen erfordern (insgesamt 16.000 Fragen). Die Veröffentlichung dieses Benchmarks verbessert die Fairness-Dimension von Großmodellen, leistet einen wertvollen Beitrag zur Überbrückung der Lücke zwischen technologischer Entwicklung und gesellschaftlichem Wert und fördert die tiefgreifende Weiterentwicklung des KI-Ökosystems in eine vielfältigere und präzisere Richtung.
Der Difference Aware Fairness Benchmark Dataset ist jetzt auf der offiziellen Website von HyperAI verfügbar. Laden Sie ihn jetzt herunter und probieren Sie ihn aus!
Online-Nutzung:https://go.hyper.ai/XOx97
Hier ist ein kurzer Überblick über die Updates der offiziellen Website von hyper.ai vom 28. Juli bis 1. August:
* Hochwertige öffentliche Datensätze: 10
* Hochwertige Tutorial-Auswahl: 5
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im August: 9
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. B3DB Biologischer Benchmark-Datensatz
B3DB ist ein umfangreicher biologischer Benchmark-Datensatz der McMaster University in Kanada. Er soll einen Benchmark für die Modellierung der Blut-Hirn-Schranken-Permeabilität kleiner Moleküle liefern. Der Datensatz wurde aus 50 veröffentlichten Quellen zusammengestellt und bietet eine Teilmenge der physikochemischen Eigenschaften dieser Moleküle. Für einige dieser Moleküle werden numerische logBB-Werte bereitgestellt, während der gesamte Datensatz sowohl numerische als auch kategorische Daten enthält.
Direkte Verwendung:https://go.hyper.ai/0mPpP
Anime ist ein Anime-Datensatz von http://MyAnimeList.net Die Datenbank soll Datenwissenschaftlern, Machine-Learning-Ingenieuren und Anime-Enthusiasten eine umfassende, übersichtliche und leicht zugängliche Ressource bieten. Der Datensatz enthält Informationen zu über 28.000 einzigartigen Anime-Werken und bietet Einblicke in Trends in der Anime-Welt.
Direkte Verwendung:https://go.hyper.ai/MxrqC
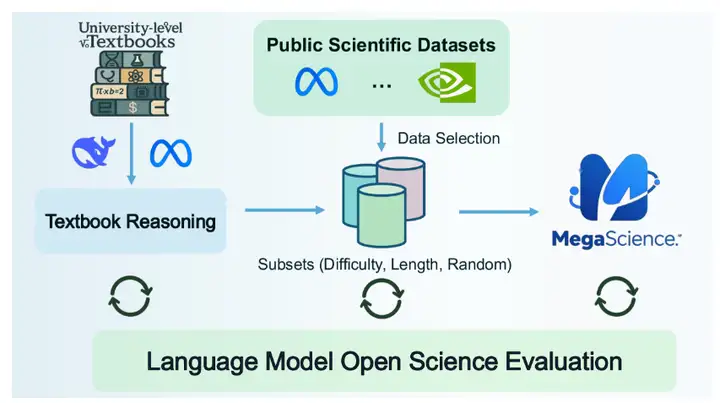
3. MegaScience-Datensatz für wissenschaftliches Denken
MegaScience ist ein wissenschaftlicher Datensatz der Shanghai Jiao Tong University. Der Datensatz enthält 1,25 Millionen Instanzen und wurde entwickelt, um die Verarbeitung natürlicher Sprache (NLP) und maschinelle Lernmodelle zu unterstützen, insbesondere bei Aufgaben wie Literaturrecherche, Informationsextraktion, automatischer Zusammenfassung und Zitationsanalyse im Bereich der wissenschaftlichen Forschung.
Direkte Verwendung:https://go.hyper.ai/694qh
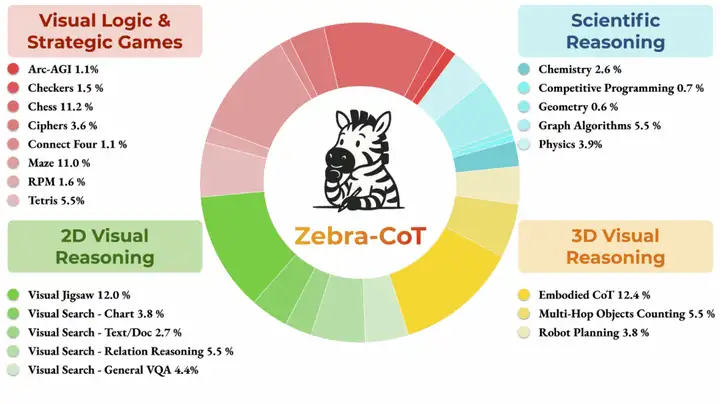
4. Zebra-CoT Text-zu-Bild-Inferenz-Datensatz
Zebra-CoT ist ein gemeinsam von der Columbia University, der University of Maryland, der University of Southern California und der New York University veröffentlichter Datensatz zum visuell-linguistischen Denken. Er soll Modellen helfen, die logischen Beziehungen zwischen Bildern und Text besser zu verstehen. Er wird häufig in Bereichen wie der visuellen Beantwortung von Fragen und der Generierung von Bildbeschreibungen eingesetzt und trägt zur Verbesserung der Denkfähigkeiten und -genauigkeit bei. Der Datensatz enthält 182.384 Beispiele aus vier Hauptkategorien: wissenschaftliches Denken, 2D-visuelles Denken, 3D-visuelles Denken sowie visuelle Logik- und Strategiespiele.
Direkte Verwendung:https://go.hyper.ai/y2a1e
5. PolyMath-Datensatz zum mathematischen Denken
PolyMath ist ein gemeinsam von Alibaba und der Shanghai Jiao Tong University veröffentlichter Datensatz zum mathematischen Denken. Ziel ist die Förderung der Forschung im Bereich der Polymathematik. Der Datensatz enthält 500 hochwertige Fragen zum mathematischen Denken, davon 125 Fragen pro Sprachniveau.
Direkte Verwendung:https://go.hyper.ai/yRVfY
6. SongEval-Datensatz zur Musikbewertung
SongEval ist ein gemeinsam vom Shanghai Conservatory of Music, der Northwestern Polytechnical University, der University of Surrey und der Hong Kong University of Science and Technology veröffentlichter Datensatz zur Musikbewertung. Ziel ist die ästhetische Bewertung ganzer Songs. Der Datensatz enthält über 2.399 Songs (einschließlich Gesangs- und Instrumentalstücke), die von 16 Experten anhand von fünf Wahrnehmungsdimensionen bewertet wurden: Gesamtkohärenz, Einprägsamkeit, Natürlichkeit der Stimmatmung und Phrasierung, Klarheit der Songstruktur und Gesamtmusikalität. Der Datensatz umfasst rund 140 Stunden hochwertiges Audiomaterial, darunter chinesische und englische Songs aus neun Hauptgenres.
Direkte Verwendung:https://go.hyper.ai/ohp0k
7. Vchitect T2V-Datensatz zur Videogenerierung
Vchitect T2V ist ein vom Shanghai Artificial Intelligence Laboratory veröffentlichter Datensatz zur Videogenerierung. Er zielt darauf ab, die Fähigkeit von Modellen zur Übersetzung zwischen Text und Bildinhalten zu verbessern und Forschern und Entwicklern dabei zu helfen, Fortschritte bei der Bildgenerierung, dem semantischen Verständnis und modalübergreifenden Aufgaben zu erzielen. Der Datensatz enthält 14 Millionen hochwertige Videos, jedes mit ausführlichen Textunterschriften.
Direkte Verwendung:https://go.hyper.ai/vLs9z
8. LED-Datensatz für lateinische Inschriften
LED ist der bislang größte maschinenlesbare Datensatz lateinischer Inschriften und umfasst 176.861 Inschriften. Die meisten dieser Inschriften sind jedoch teilweise beschädigt, und nur 51 TP3T-Inschriften liefern brauchbare Bilder. Die Daten stammen aus drei der umfassendsten lateinischen Inschriftendatenbanken: der Database of Roman Inscriptions (EDR), der Database of Heidelberg Inscriptions (EDH) und der Clauss-Slaby-Datenbank.
Direkte Verwendung:https://go.hyper.ai/O8noU
9. AutoCaption Video Caption Benchmark-Datensatz
Der AutoCaption-Datensatz ist ein von Tjunlp Labs veröffentlichter Benchmark-Datensatz für Videountertitel. Er zielt darauf ab, die Forschung im Bereich multimodaler Großsprachenmodelle für die Generierung von Videountertiteln zu fördern. Der Datensatz enthält zwei Teilmengen mit insgesamt 11.184 Beispielen.
Direkte Verwendung:https://go.hyper.ai/pgOCw
10. Interaktiver Bilddatensatz der ArtVIP-Maschine
ArtVIP ist ein maschineninteraktiver Bilddatensatz, der vom Beijing Humanoid Robotics Innovation Center veröffentlicht wurde. Dieser Datensatz enthält 206 artikulierte Objekte aus 26 Kategorien. Er gewährleistet visuellen Realismus durch präzise geometrische Netze und hochauflösende Texturen, erreicht physikalische Wiedergabetreue durch fein abgestimmte dynamische Parameter und ist der erste, der modulare interaktive Verhaltensweisen in die Assets einbettet und gleichzeitig die Annotation von Affordanzen auf Pixelebene ermöglicht.
Direkte Verwendung:https://go.hyper.ai/vGYek

Ausgewählte öffentliche Tutorials
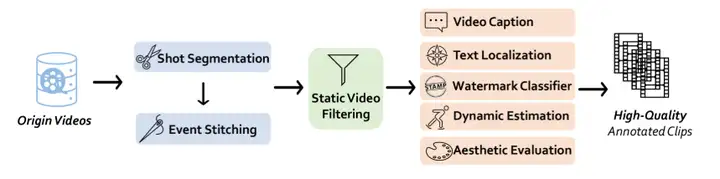
1. Selbsterzwingende Echtzeit-Videogenerierung
Self-Forcing ist ein neuartiges Trainingsparadigma für autoregressive Videodiffusionsmodelle, das von Xun Huangs Team vorgeschlagen wurde. Es befasst sich mit dem seit langem bestehenden Problem des Belichtungsbias, bei dem ein im realen Kontext trainiertes Modell während der Inferenz Sequenzen basierend auf seinen eigenen unvollkommenen Ergebnissen generieren muss. Dieses Modell ermöglicht die Echtzeit-Streaming-Videogenerierung mit einer Latenz von unter einer Sekunde auf einer einzelnen GPU und erreicht dabei die Generierungsqualität deutlich langsamerer und nicht-kausaler Diffusionsmodelle oder übertrifft diese sogar.
Online ausführen:https://go.hyper.ai/j19Hx
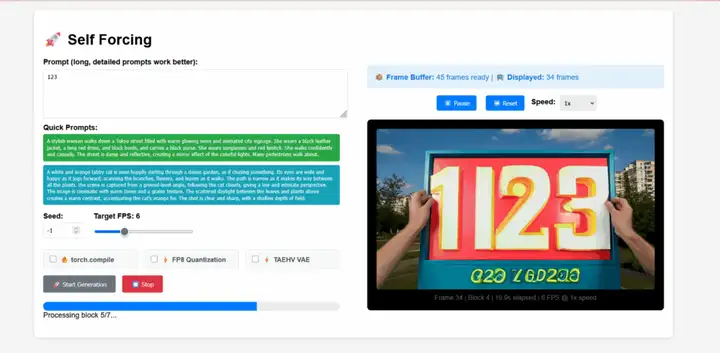
2. Stellen Sie EXAONE-4.0-32B mit vLLM + Open WebUI bereit
EXAONE-4.0 ist ein hybrides KI-Modell der nächsten Generation, das von LG AI Research in Südkorea eingeführt wurde. Es ist zugleich Südkoreas erstes hybrides KI-Modell. Dieses Modell kombiniert allgemeine Fähigkeiten zur Verarbeitung natürlicher Sprache mit den von EXAONE Deep verifizierten erweiterten Denkfähigkeiten und erzielt Durchbrüche in anspruchsvollen Bereichen wie Mathematik, Naturwissenschaften und Programmierung.
Online ausführen:https://go.hyper.ai/7XiZM
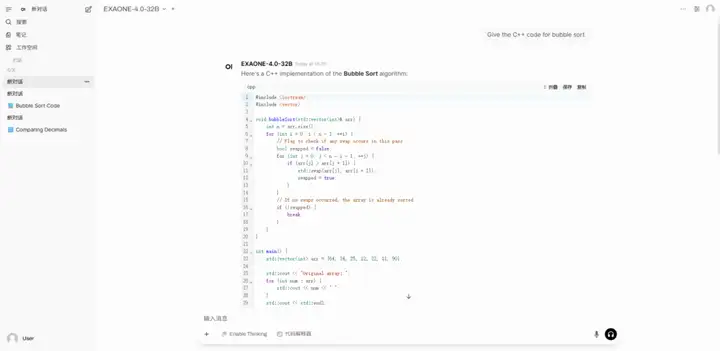
3. Ein-Klick-Bereitstellung von Qwen3-30B-A3B-Instruct-2507
Qwen3-30B-A3B-Instruct-2507 ist ein umfangreiches Sprachmodell, das vom Tongyi Wanxiang Lab von Alibaba entwickelt wurde. Dieses Modell ist eine aktualisierte Version des Non-Thinking-Modus von Qwen3-30B-A3B. Sein Highlight ist, dass es mit nur 3 Milliarden (3B) aktivierten Parametern eine beeindruckende Leistung zeigt, die mit Googles Gemini 2.5-Flash (Non-Thinking-Modus) und OpenAIs GPT-4o vergleichbar ist. Dies stellt einen bedeutenden Durchbruch in der Modelleffizienz und Leistungsoptimierung dar.
Online ausführen:https://go.hyper.ai/hr1o6
4. Wan2.2: Offenes erweitertes Modell zur Videogenerierung im großen Maßstab
Wan-2.2 ist ein Open-Source-Modell zur fortschrittlichen KI-Videogenerierung, das vom Tongyi Wanxiang Lab von Alibaba entwickelt wurde. Dieses Modell führt eine Mixture of Experts (MoE)-Architektur ein, die die Generierungsqualität und Rechenleistung effektiv verbessert. Es ist außerdem Vorreiter eines filmischen ästhetischen Steuerungssystems, das eine präzise Steuerung von Beleuchtung, Farbe, Komposition und anderen ästhetischen Effekten ermöglicht.
Online ausführen:https://go.hyper.ai/AG6CE
5. PE3R: Ein Framework für effiziente Wahrnehmung und 3D-Rekonstruktion
PE3R (Perception-Efficient 3D Reconstruction) ist ein innovatives Open-Source-Framework für 3D-Rekonstruktion, das vom XML Lab der National University of Singapore (NUS) veröffentlicht wurde. Es integriert multimodale Wahrnehmungstechnologien für eine effiziente und intelligente Szenenmodellierung. Entwickelt auf Basis modernster Forschungsergebnisse im Bereich Computer Vision, rekonstruiert es 3D-Szenen schnell aus nur 2D-Bildern. Auf einer RTX 3090-Grafikkarte beträgt die durchschnittliche Rekonstruktionszeit für eine einzelne Szene nur 2,3 Minuten – eine Verbesserung von über 65% im Vergleich zu herkömmlichen Methoden.
Online ausführen:https://go.hyper.ai/3BnDy

Die Zeitungsempfehlung dieser Woche
1. Agentisch verstärkte Richtlinienoptimierung
In realen Reasoning-Szenarien profitieren Large Language Models (LLMs) häufig von externen Tools zur Lösung von Aufgaben. Bestehende Reinforcement-Learning-Algorithmen haben jedoch Schwierigkeiten, die inhärenten Fähigkeiten des Modells zum Long-Range-Reasoning mit seiner Kompetenz in mehrstufigen Tool-Interaktionen in Einklang zu bringen. Um diese Lücke zu schließen, schlägt dieses Papier Agent Reinforcement Policy Optimization (ARPO) vor, einen neuartigen Agent Reinforcement-Learning-Algorithmus, der speziell für das Training mehrstufiger LLM-basierter Agenten entwickelt wurde. Er erzielt Leistungsverbesserungen mit nur der Hälfte des Tool-Budgets bestehender Methoden und bietet eine skalierbare Lösung für die Anpassung LLM-basierter Agenten an dynamische Echtzeitumgebungen.
Link zum Artikel:https://go.hyper.ai/lPyT2
Die Generierung immersiver und interaktiver 3D-Welten aus Text oder Bildern bleibt eine grundlegende Herausforderung in der Computervision und Grafik. Bestehende Methoden zur Weltgenerierung leiden unter Einschränkungen wie unzureichender 3D-Konsistenz und geringer Rendering-Effizienz. Um dieses Problem zu lösen, schlägt dieses Papier ein innovatives Framework, HunyuanWorld 1.0, vor, um immersive, erforschbare und interaktive 3D-Szenen aus Text und Bildern zu generieren.
Link zum Artikel:https://go.hyper.ai/aMbdz
Trotz jüngster Fortschritte bei der Text-zu-Code-Generierung mithilfe großer Sprachmodelle (LLMs) basieren viele bestehende Methoden ausschließlich auf natürlichen Sprachmerkmalen und können die räumliche Struktur von Layouts und die visuelle Designabsicht kaum effektiv erfassen. Im Gegensatz dazu ist die Entwicklung realer UIs von Natur aus multimodal und beginnt oft mit visuellen Skizzen oder Prototypen. Um diese Lücke zu schließen, schlägt dieses Dokument ScreenCoder vor, ein modulares Multi-Agenten-Framework, das die UI-zu-Code-Generierung in drei interpretierbaren Phasen ermöglicht: Lokalisierung, Planung und Generierung.
Link zum Artikel:https://go.hyper.ai/k4p58
4. ARC-Hunyuan-Video-7B: Strukturiertes Videoverständnis von Kurzfilmen aus der realen Welt
Aktuellen groß angelegten multimodalen Modellen fehlt das notwendige zeitlich strukturierte, detaillierte und tiefgreifende Videoverständnis, das für eine effektive Videosuche und -empfehlung sowie für neue Videoanwendungen von grundlegender Bedeutung ist. Diese Studie schlägt ARC-Hunyuan-Video vor, ein multimodales Modell, das visuelle, Audio- und Textsignale aus Rohvideoeingaben durchgängig verarbeitet, um ein strukturiertes Verständnis zu erreichen. Das Modell bietet mehrgranulare, zeitgestempelte Videobeschreibungen und -zusammenfassungen, die Beantwortung offener Videofragen, zeitliche Videolokalisierung und Videoschlussfolgerung.
Link zum Artikel:https://go.hyper.ai/ogYbH
5. Deep Researcher mit Test-Time Diffusion
Bei der Verwendung gängiger Algorithmen zur Testzeitskalierung zur Erstellung komplexer und umfangreicher Forschungsberichte kommt es häufig zu Leistungsengpässen. Inspiriert vom iterativen Charakter des menschlichen Forschungsprozesses schlägt dieses Dokument den Test-Time Diffusion Deep Researcher (TTD-DR) vor. TTD-DR beginnt den Prozess mit einem vorläufigen Entwurf (einem aktualisierbaren Framework), der als Grundlage für die Forschungsrichtung dient. Dieses entwurfszentrierte Design macht den Berichterstellungsprozess zeitnaher und kohärenter und reduziert Informationsverluste während der iterativen Suche.
Link zum Artikel:https://go.hyper.ai/D4gUK
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
Ein Team um Shi Boxin von der Peking-Universität hat in Zusammenarbeit mit OpenBayes Bayesian Computing PanoWan entwickelt, ein Framework zur textbasierten Panoramavideo-Generierung. Dieser Ansatz mit seiner minimalistischen und effizienten modularen Architektur überträgt die generativen Vorkenntnisse vortrainierter Text-zu-Video-Modelle nahtlos auf den Panoramabereich.
Den vollständigen Bericht ansehen:https://go.hyper.ai/9UWXl
Ein Forschungsteam der Universiti Putra Malaysia (UPM) und der University of New South Wales (UNSW) Sydney hat gemeinsam ein intelligentes Framework für die automatische Klassifizierung und Marktwertschätzung von Keramikartefakten auf Basis des YOLOv11-Modells entwickelt. Das optimierte YOLOv11-Modell kann wichtige Keramikmerkmale wie dekorative Muster, Formen und Handwerkskunst identifizieren und Marktpreise anhand extrahierter visueller Merkmale und Auktionsdaten aus mehreren Quellen vorhersagen. Dies bietet eine skalierbare Lösung für die intelligente Keramikauthentifizierung und die Kuratierung digitaler Artefakte.
Den vollständigen Bericht ansehen:https://go.hyper.ai/XcuLz
Ein Forschungsteam der University of Pennsylvania in den USA integrierte vier große Giftdatenbanken, um eine globale Giftdatenbank aufzubauen. Dabei wendete es ein Sequenz-zu-Funktion-Deep-Learning-Modell namens APEX an, das speziell dazu dient, potenzielle antibakterielle Kandidaten im Giftproteom systematisch zu identifizieren. Sie filterten schließlich 386 Kandidatenpeptide mit antibakteriellem Potenzial und geringer Sequenzähnlichkeit mit bekannten AMPs heraus.
Den vollständigen Bericht ansehen:https://go.hyper.ai/u067l
Ein gemeinsames Forschungsteam von NVIDIA, dem Lawrence Berkeley National Laboratory, der University of California, Berkeley und dem California Institute of Technology hat FourCastNet 3 (FCN3) vorgestellt, ein probabilistisches Wettervorhersagesystem auf Basis maschinellen Lernens, das sphärische Signalverarbeitung mit einem Hidden-Markov-Set-Framework kombiniert. Es kann auf einer einzigen NVIDIA H100-GPU in 60 Sekunden eine 15-Tage-Vorhersage erstellen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/JQh25
Alibabas Tongyi Wanxiang Lab hat kürzlich sein fortschrittliches KI-Videogenerierungsmodell Wan2.2 als Open Source veröffentlicht. Dieses Modell, das eine Mixture of Experts (MoE)-Architektur einführt, verbessert effektiv die Generierungsqualität und Rechenleistung und ermöglicht so einen effizienten Betrieb auf Grafikkarten für Endverbraucher wie der NVIDIA RTX 4090. Es entwickelte außerdem ein filmisches Ästhetik-Steuerungssystem, das eine präzise Steuerung von Beleuchtung, Farbe, Komposition und anderen ästhetischen Effekten ermöglicht.
Den vollständigen Bericht ansehen:https://go.hyper.ai/RgFmY
Beliebte Enzyklopädieartikel
1. DALL-E
2. Reziproke Sortierfusion RRF
3. Pareto-Front
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kontrastives Lernen
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:

Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








