Command Palette
Search for a command to run...
Basierend Auf Über 176.000 Inschriftendaten Veröffentlichte Google DeepMind Aeneas, Das Erstmals Eine Beliebige Längenrestaurierung Antiker Römischer Inschriften Ermöglichte

Alle Erinnerungen an die frühe menschliche Zivilisation sind in Inschriften und Worten verborgen. Inschriften gehören zu den ältesten Schriftformen und ermöglichen den Menschen, Gedanken, Sprache und Geschichte antiker Zivilisationen zu verstehen. Von kaiserlichen Erlassen bis hin zu Sklavengrabsteinen sind diese in Steintafeln und Bronzen eingravierten Worte zu direkten Beweisen für die Altersbestimmung und das Verständnis der Kultur geworden. Schätzungsweise werden jedes Jahr noch 1.500 neue lateinische Inschriften entdeckt, doch die Erforschung der Epigraphik stößt auf viele Schwierigkeiten, wie unvollständige Texte, Interpretationsschwierigkeiten und begrenztes Wissen.
Am 23. Juli 2025 veröffentlichten Forscher von Google DeepMind zusammen mit der University of Nottingham, der University of Warwick und anderen Universitäten eine Forschungsarbeit mit dem Titel „Contextualizing ancient texts with generative neural networks“ (Kontextualisierung antiker Texte mit generativen neuronalen Netzwerken) in der weltweit führenden wissenschaftlichen Zeitschrift Nature.
Diese Forschung enthält drei wichtige innovative Highlights:
* Aeneas kann sowohl Texttranskription als auch Bildinformationen der Inschrift empfangen. Das Bild wird von einem flachen visuellen neuronalen Netzwerk verarbeitet und mit Textmerkmalen kombiniert. Dies ist besonders hilfreich für geografische Zuordnungsaufgaben.
* Zuvor konnte KI nur Texte bekannter Länge reparieren, aber Aeneas durchbrach diese Reparaturbeschränkungen und war der erste Pionier, der die Fähigkeit entwickelte, „Texte beliebiger Länge zu reparieren“.
* Die Kernkompetenz von Aeneas besteht darin, die relevantesten „Paralleltexte“ zur Zielinschrift zu finden. Diese Paralleltexte enthalten nicht nur ähnliche Phrasen, sondern decken auch tiefe Zusammenhänge wie kulturellen Hintergrund und soziale Funktionen ab, die weit über die Grenzen des traditionellen String-Matchings hinausgehen.
Modellarchitektur: Multimodales generatives neuronales Netzwerk Aeneas
Aeneas ist ein multimodales generatives neuronales Netzwerk.Ein Transformer-basierter Decoder verarbeitet die Text- und Bildeingaben der Inschrift. Ein flaches visuelles neuronales Netzwerk ruft ähnliche Inschriften aus dem lateinischen Inschriftendatensatz ab und sortiert sie nach Relevanz. Der Eingabetext wird vom Kernteil des Modells, dem „Torso“, verarbeitet.
Aeneas ist für die kontextuelle Analyse lateinischer Inschriften konzipiert. Seine Architektur besteht aus Eingabeverarbeitung, Kernmodulen, Taskheadern und Kontextualisierungsmechanismen.
Eingabeverarbeitung:Die Eingabe ist die Zeichenfolge der Inschrift und ein 224 × 224 Graustufenbild. Die Zeichenfolge ist bis zu 768 Zeichen lang, "-" wird verwendet, um fehlende Zeichen bekannter Länge zu markieren, "#" wird verwendet, um fehlende Zeichen unbekannter Länge zu markieren und < wird als Satzanfangsmarkierung verwendet;
Kernmodule:Der Text wird von einem Torso verarbeitet, der auf dem T5 Transformer Decoder basiert und 16 Schichten, 8 Attention Heads pro Schicht und eine Einbettung der relativen Positionsrotation aufweist. Das Bild wird von einem visuellen ResNet-8-Netzwerk verarbeitet. Die Ausgaben des Torsos und der visuellen Netzwerke werden dann an dedizierte neuronale Netzwerke in Heads weitergeleitet, die den Text zur Charakterwiederherstellung und Datierung verwenden. Jeder Head ist für drei wichtige epigraphische Aufgaben angepasst.
Aufgabenkopfzeile (Aufgabenleiter):Die Ausgabe verfügt über dedizierte Aufgabenköpfe für die Textreparatur (einschließlich Hilfsköpfe für die Reparatur unbekannter Längen, wobei die Strahlensuche zum Generieren von Hypothesen verwendet wird), die geografische Zuordnung (Kombination von Text- und visuellen Merkmalen zum Klassifizieren von 62 römischen Provinzen) und die chronologische Zuordnung (Zuordnung von Daten in 160 diskrete Dekadenintervalle), alle mit Salienzkarten.
Kontextualisierungsmechanismus:Durch die Integration der Zwischendarstellung von Torso und Aufgabenkopf zur Generierung historisch angereicherter Einbettungen werden relevante parallele Inschriften auf der Grundlage der Kosinusähnlichkeit abgerufen, um Historiker bei ihrer Forschung zu unterstützen.
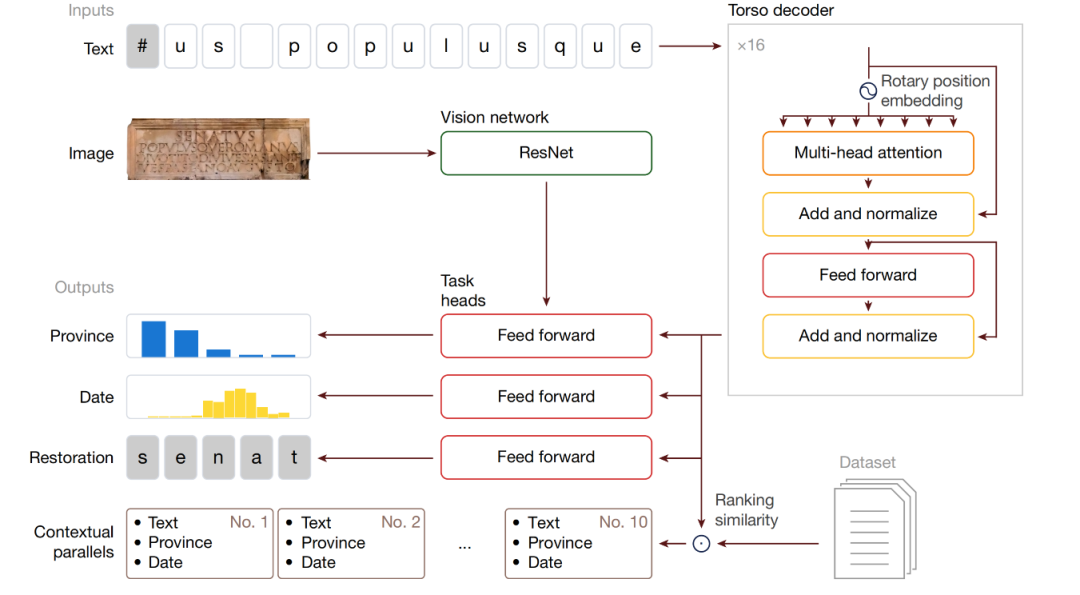
Nehmen wir Aeneas’ Verarbeitung der Phrase „Senatus populusque Romanus“ als Beispiel: Anhand eines Bildes einer Inschrift und ihrer Texttranskription (wobei beschädigte Teile unbekannter Länge mit „#“ gekennzeichnet sind) verarbeitet Aeneas den Text mithilfe von Torsos. Die Köpfe sind für die Charakterwiederherstellung, Datierung und geografische Zuordnung zuständig (die geografische Zuordnung berücksichtigt auch visuelle Merkmale). Die Zwischendarstellungen der Torsos werden zu einem einheitlichen, historisch reichen Einbettungsvektor zusammengeführt, um ähnliche Inschriften aus dem Latin Inscriptions Dataset (LED) abzurufen und nach Relevanz zu sortieren.
Es ist zu beachten, dassDas Aeneas-Modell integriert zusätzliche Eingaben vom visuellen Netzwerk nur für die Geo-Attributionsköpfe; die Text-Inpainting- und chronologischen Attributionsaufgaben verwenden die visuelle Modalität nicht.Die Wiederherstellungsaufgabe schließt visuelle Eingaben aus, um versehentliches Informationslecken zu verhindern. Da ein Teil des Textes künstlich maskiert ist und seine genaue Position im Bild unbekannt ist, kann das Modell visuelle Hinweise verwenden, um die verborgenen Zeichen zu erschließen und wiederherzustellen, wodurch die Integrität der Aufgabe beeinträchtigt wird.
Datensatz: Der größte maschinenlesbare Datensatz lateinischer Inschriften
Die zum Trainieren des Aeneas-Modells verwendete Korpusdatenbank wird in der Studie als Latin Inscriptions Dataset (LED) bezeichnet und stellt den bislang größten maschinenbedienbaren Datensatz lateinischer Inschriften dar. Die umfassenden Korpusdaten des LED-Datensatzes stammen aus den drei umfangreichsten lateinischen Inschriftendatenbanken: der Roman Inscription Database (EDR), der Heidelberg Inscription Database (EDH) und der Clauss-Slaby-Datenbank. Diese enthalten Inschriften vom 7. Jahrhundert v. Chr. bis zum 8. Jahrhundert n. Chr. und decken das Gebiet von den römischen Provinzen Britannia (heute Britannien) und Lusitania (Portugal) im Westen bis nach Ägypten und Mesopotamien im Osten ab. Um die Konsistenz des gesamten LED-Datensatzes zu gewährleisten, nutzte die Studie Identifikatoren der Trismegistos-Datenplattform, um Mehrdeutigkeiten in den Daten zu beseitigen. Zudem wendete sie eine Reihe von Filterregeln an, um menschliche Anmerkungen systematisch zu verarbeiten, damit der Text maschinell verarbeitet werden kann.
Um standardisierte Metadaten zu erhalten,Die Studie konvertierte alle Metadaten zu Daten und historischen Zeiträumen in Zahlen zwischen 800 v. Chr. und 800 n. Chr.Inschriften außerhalb dieses Bereichs wurden ausgeschlossen. Um die Lern- und Generalisierungsfähigkeiten des Modells zu verbessern, wurde der inhaltliche Textinhalt des Datensatzes gemäß dem Standard in ein maschinenlesbares Format konvertiert:
* Entfernen oder normalisieren Sie die Anmerkungen der Historiker zur Inschrift und behalten Sie die Version bei, die der Originalinschrift am nächsten kommt.
* Lateinische Abkürzungen werden nicht analysiert, während Wortformen, die aus diachronen, bidirektionalen oder flektierenden Gründen alternative Schreibweisen aufweisen, beibehalten werden, sodass das Modell ihre epigraphischen, geografischen oder chronologischen spezifischen Variationen lernt.
* Behalten Sie fehlende Zeichen bei, die vom Editor wiederhergestellt wurden oder die letztendlich nicht wiederhergestellt werden konnten, verwenden Sie Rautenzeichen (#) als Platzhalter, wenn die genaue Anzahl der fehlenden Zeichen ungewiss ist, und reduzieren Sie zusätzliche Leerzeichen, um eine präzise Ausgabe zu gewährleisten.
* Entfernen Sie nicht-lateinische Zeichen und lassen Sie nur lateinische Zeichen, vordefinierte Satzzeichen und Platzhalter übrig.
* Filtern Sie doppelte Inschriften. Texte, die den Schwellenwert 90% für inhaltliche Ähnlichkeit überschreiten, werden als Duplikate betrachtet.
Nach der Konvertierung des Formats unterteilte die Studie die LEDs basierend auf der letzten Ziffer der eindeutigen Beschriftungskennung in Trainings-, Validierungs- und Testsätze, um eine gleichmäßige Verteilung der Bilder auf die Teilmengen sicherzustellen.

Nach der Implementierung des automatischen Filterprozesses wurden im Rahmen der Studie verwertbare Inschriftbilder aus dem Datensatz gewonnen. Dies gelang durch die Anwendung eines Schwellenwerts auf das Farbhistogramm, um Bilder zu eliminieren, die hauptsächlich aus einer einzigen reinen Farbe bestehen. Zudem wurde die Varianz der Laplace-Matrix genutzt, um verschwommene Bilder zu identifizieren und zu verwerfen, und die bereinigten Bilder wurden in Graustufenbilder umgewandelt. Der LED-Datensatz enthält insgesamt 176.861 Inschriften, die meisten davon sind jedoch teilweise beschädigt und nur 5%-Inschriften können brauchbare entsprechende Bilder erzeugen.
Experimentelle Schlussfolgerung/Leistung
Die Forscher bewerteten die Leistung des Aeneas-Modells unter drei Aspekten: Aufgabenausführung, onomastische Basis, Kontextualisierungsmechanismus und Forschungseffizienz.
* Onomastik ist die Lehre vom Ursprung, Aufbau, der Entwicklung und der Bedeutung von Eigennamen wie Personen-, Orts-, Stammes- und Götternamen.
Indikatoren für die Aufgabenausführung
Diese Studie verwendet drei Indikatoren für die Textrestaurierung, die geografische Zuordnung und die zeitliche Zuordnung, um einen Bewertungsrahmen zu bilden.Unter anderem verwendeten die Forscher künstliche Methoden, um Text beliebiger Länge zu zerstören und reichten das Modell ein, um reparierte Objekte zu erzeugen. Bei der geografischen Zuordnungsaufgabe wurden die standardmäßigen Top-1- und Top-3-Genauigkeitsindikatoren verwendet, um die Leistung zu bewerten. Bei der zeitlichen Zuordnung wurde ein erklärbarer Indikator verwendet, um die zeitliche Nähe zwischen den vorhergesagten Ergebnissen und den realen Daten zu bewerten.
Experimente zeigen, dass die Architektur von Aeneas multimodale Fähigkeiten bietet.Kann Textsequenzen unbekannter Länge wiederherstellen,Darüber hinaus kann es auf alle antiken Sprachen und Schriftträger wie Papyrus und Münzen angewendet werden, um im Kontextualisierungsprozess der antiken Textforschung die Verbindung zwischen Inschriften und Geschichte zu erfassen.
Onomastik-Grundlinie
Die automatisierte Auswertung der aus der Onomastik abgeleiteten Metadaten durch das Aeneas-Modell wird zu einem Schlüsselindikator für seine Fähigkeiten zur Attributionsvorhersage.Da es keine vorgefertigte Liste römischer Eigennamen gibt,Das Forschungsteam entfernte manuell 350 Elemente aus dem Eigennamen-Repository, die keine Eigennamen darstellten.Einträge, die kürzer waren oder aufgrund von Mehrdeutigkeiten in der Verwendung nicht-lateinische Zeichen enthielten, wurden ausgeschlossen, sodass eine kuratierte Liste mit etwa 38.000 Eigennamen entstand.
Um die Robustheit des Ansatzes zu verbessern, wurden die häufigsten Wörter im Datensatz identifiziert und so gefiltert, dass sie nur aus Einträgen einer kuratierten Liste von Eigennamen bestehen. Anschließend wurde ihre durchschnittliche zeitliche und geografische Verteilung im Trainingsdatensatz berechnet, sodass das Aeneas-Modell die verarbeiteten Eigennamendaten nutzen konnte, um bei der Analyse neuer Inschriften das Datum und die Herkunft vorherzusagen.
Die Auswertungsmethode des Aeneas-Modells für diese Aufgabe kann auf den gesamten Datensatz angewendet werden und erreicht eine verbesserte Skalierbarkeit.
Kontextualisierungsmechanismus und Forschungseffizienz
Die Studie bewertete die Wirksamkeit des Kontextualisierungsmechanismus des Aeneas-Modells als grundlegendes Instrument der historischen Forschung. 23 Epigraphiker unterschiedlicher Herkunft nahmen anonym an der Bewertung teil.Basierend auf den Erfahrungen mit der Durchführung von drei Inskriptionsaufgaben wurde die Effizienz der Verwendung des Kontextualisierungsmechanismus von Aeneas als Hilfsmittel für die Forschung bewertet:
* Das Aeneas-Modell kann den Zeitaufwand für die Suche nach relevanten Informationen erheblich reduzieren, sodass sich die Forscher auf eine tiefere historische Interpretation und die Formulierung von Forschungsfragen konzentrieren können.
* Die vom Aeneas-Modell abgerufenen Informationen sind genau und bieten wertvolle Einblicke in die Art und den Kontext der Inschrift, was zur Weiterentwicklung der Forschungsaufgabe beiträgt.
* Aeneas erweitert die Suche und verfeinert die Ergebnisse, indem es wichtige, aber bisher unbeachtete verwandte Informationen und übersehene Textmerkmale identifiziert.
Einige Experten bezweifeln die Echtheit
„Aeneas markiert den Beginn der künstlichen Intelligenz in der Geschichtswissenschaft“, so David Galbraith, Experte für künstliche Intelligenz. Der Durchbruch von Aeneas ist nicht nur ein technischer Fortschritt, sondern auch ein Zeichen für die enge Verflechtung von Geisteswissenschaften und KI. Für Historiker ist Aeneas kein Ersatz für Wissenschaftler, sondern vielmehr ein „Superassistent“, der mechanische Arbeit reduziert und den Forschungshorizont erweitert. Gleichzeitig beweist Aeneas im Bereich der KI das Potenzial multimodaler und kontextualisierter Modelle bei der Verarbeitung komplexer geisteswissenschaftlicher Daten und bietet ein Modell für die zukünftige Entwicklung der Forschung zu anderen alten Sprachen.
Aeneas hat noch immer seine Grenzen. Angesichts des Durchbruchs von Aeneas äußerte ein anderer Experte für künstliche Intelligenz die Befürchtung, dass „ein übermäßiges Vertrauen in die KI zum Füllen der Lücken Fragen zur Authentizität aufwerfen wird“.

Zugegeben, KI ist ein Werkzeug, kein echter Ersatz. In den Trainingsdaten sind nur 5% Inschriften mit Bildern versehen, und die Anzahl der Inschriften in einigen Regionen (wie Sizilien) und Zeiträumen (wie vor 600 v. Chr.) ist unzureichend, was zu einer verringerten Vorhersagegenauigkeit führt. Dies alles sind Warnungen, dass die aktuelle KI-Technologie noch nicht ausgereift ist und wir ihren Anteil an wissenschaftlicher Forschung und Leben rational wählen sollten.








