Command Palette
Search for a command to run...
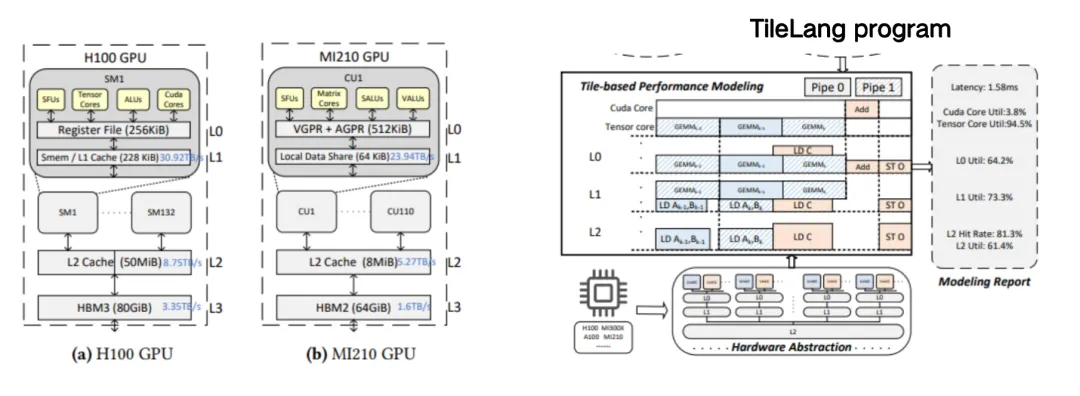
Primitive Auf Kachelebene Sind Mit Automatischen Schlussfolgerungsmechanismen integriert. Der Initiator Der TileAI-Community Analysiert Eingehend Die Kerntechnologie Und Die Vorteile Von TileLang

Am 5. Juli ging der 7. Meet AI Compiler Technology Salon in Peking erfolgreich zu Ende. Branchenexperten tauschten sich über die neuesten Entwicklungen sowie praktische Erfahrungen aus, während Universitätsforscher die Umsetzungsmöglichkeiten und Vorteile innovativer Technologien detailliert erläuterten.
In,Dr. Wang Lei, Gründer der TileAI-Community, hielt eine Rede mit dem Titel „Bridge Programmability and Performance in Modern AI Workloads“.Die innovative Operator-Programmiersprache TileLang wird auf leicht verständliche Weise vorgestellt und ihre wichtigsten Designkonzepte und technischen Vorteile werden erläutert.
TileLang zielt darauf ab, die Effizienz der KI-Kernel-Programmierung zu verbessern, indem der Planungsbereich (einschließlich Thread-Binding, Layout, Tensorisierung und Pipeline) vom Datenfluss entkoppelt und in eine Reihe anpassbarer Annotationen und Primitive gekapselt wird. Dieser Ansatz ermöglicht es Benutzern, sich auf den Kernel-Datenfluss selbst zu konzentrieren, während die meisten anderen Optimierungsarbeiten dem Compiler überlassen werden.
Die Evaluationsergebnisse zeigen, dassTileLang erreicht branchenführende Leistung auf mehreren wichtigen Kerneln.Es demonstriert umfassend sein einheitliches Block-Thread-Programmierparadigma und seine transparenten Planungsfunktionen, die die erforderliche Leistung und Flexibilität für die Entwicklung moderner KI-Systeme bieten können.
HyperAI hat die Rede zusammengestellt und zusammengefasst, ohne die ursprüngliche Absicht zu verletzen. Nachfolgend finden Sie das Transkript der Rede.
Folgen Sie dem öffentlichen WeChat-Konto „HyperAI Super Neuro“ und antworten Sie auf das Schlüsselwort „0705 AI Compiler“, um die PPT mit der Rede des autorisierten Dozenten zu erhalten.
Warum brauchen wir ein „neues DSL“?
In diesem Beitrag wird hauptsächlich die neue DSL TileLang für KI-Workloads vorgestellt, die unser Team im Januar 2025 als Open Source auf GitHub veröffentlicht hat.
Zunächst möchte ich mit Ihnen darüber sprechen, warum wir ein neues DSL brauchen.
Persönlich habe ich während meines Praktikums bei Microsoft an einem Projekt namens BitBLAS teilgenommen, das sich mit Mixed-Precision-Computing beschäftigte. Damals basierte es hauptsächlich auf TVM/Tensor IR und erzielte schließlich sehr gute experimentelle Ergebnisse. Wir stellten jedoch fest, dass es noch viele Probleme gab, beispielsweise die Wartung. Für jeden Operator, beispielsweise die Mixed-Precision-Berechnung der Matrixebene, habe ich 500 Zeilen Schedule Primitives geschrieben. Obwohl es elegant geschrieben war,Aber ich bin der Einzige, der diesen Planungscode versteht, und es ist schwierig, andere zu finden, die ihn pflegen oder erweitern.
Darüber hinaus stellte ich fest, dass es schwierig war, neue Anforderungen oder Optimierungen auf Basis des Schedule IR zu beschreiben. Als ich beispielsweise am Kernel arbeitete, schrieb ich drei Schedule Primitives zur Programmoptimierung, darunter Flash Attention, Linear Attention usw. Diese Operatoren waren auf Basis des Schedule schwer zu beschreiben. Daher dachte ich damals, dass die Verwendung von TIR bei weiterer Skalierung des Projekts möglicherweise nicht funktionieren würde und andere Lösungen erforderlich wären.
Warum also nicht Triton?
Ich habe auch Triton ausprobiert,Ich fand es jedoch schwierig, einen Hochleistungskernel anzupassen.Wenn ich beispielsweise den Dequantize-Operator schreibe, muss ich möglicherweise das Verhalten jedes Threads steuern. Die Implementierung der Dequantisierung jedes Threads auf einem Hochleistungskernel ist immer noch sehr speziell.
Die zweite besteht darin, den Puffer in einem geeigneten Speicherbereich zwischenzuspeichern.Beispielsweise ist es auf manchen GPUs besser, Daten zur Dequantisierung in Registern zwischenzuspeichern und sie dann in den gemeinsamen Speicher zu schreiben, während es auf anderen besser ist, sie direkt wieder in den gemeinsamen Speicher zu schreiben. Auf Triton ist dies jedoch schwer zu kontrollieren.
endlich,Ich finde, der Triton-Index ist etwas kompliziert.Wenn Sie beispielsweise ein Tile lokal zwischenspeichern müssen, müssen Sie den Code schreiben, der auf der linken Seite der Abbildung unten angezeigt wird. Auf dem Tensor IR können Sie jedoch Indizes zum Indizieren verwenden, wie rechts gezeigt, was ich für sehr gut halte.
Auf dieser Grundlage stellte ich fest, dass die vorhandenen DSLs meine Anforderungen nicht erfüllen konnten. Daher wollten wir eine innovative DSL erstellen, die mehr Backends und benutzerdefinierte Operatoren unterstützt und eine bessere Leistung erzielt.Um eine bessere Leistung zu erzielen, müssen verschiedene Designbereiche wie Kacheln und Pipelines optimiert werden.Zu diesem Zweck haben wir das TileLang-Projekt vorgeschlagen.
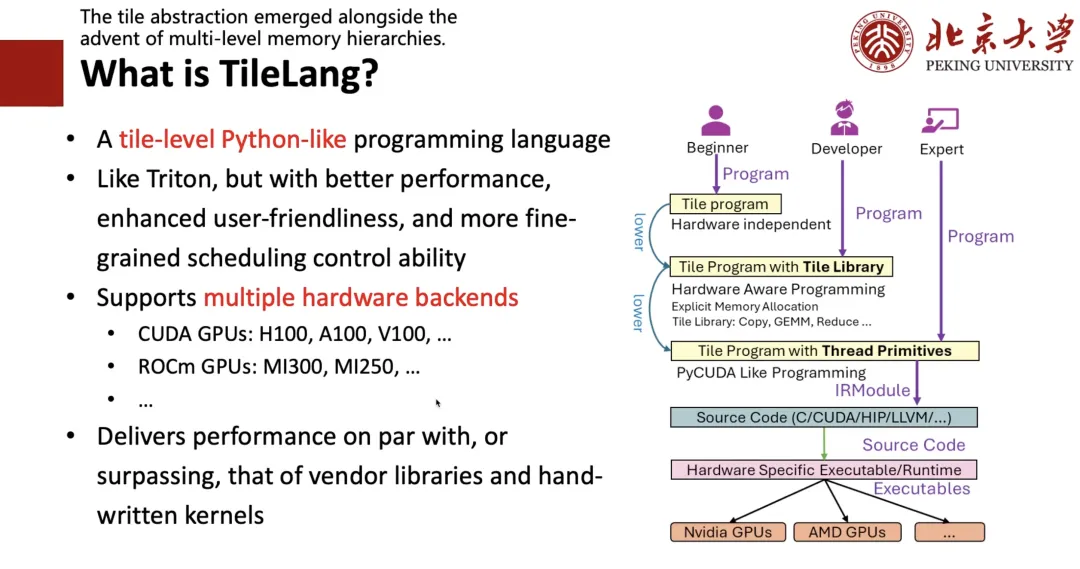
Was ist TileLang?
Warum „Tile“?
Erstens haben wir festgestellt, dass das Tile-Konzept sehr wichtig ist. Solange die Hardware über Cache, Register und gemeinsam genutzten Speicher verfügt, müssen wir beim Schreiben von Hochleistungsprogrammen Rechenblöcke, also Tile, berücksichtigen. Zweitens möchten wir, da jeder dazu neigt, Python-Programme zu schreiben, eine Python-ähnliche Programmiersprache entwickeln, die so einfach zu schreiben ist wie Triton und eine bessere Leistung bietet.
Zu diesem Zweck haben wir das auf der rechten Seite der folgenden Abbildung dargestellte Framework entworfen:Wenn Sie ein Experte sind,Das heißt, wenn Sie sich mit CUDA oder Hardware gut auskennen, können Sie direkt Low-Level-Code schreiben.Wenn Sie Entwickler sind,Das heißt, wenn Sie Triton schreiben können und Konzepte wie „Kachel“ und „Register“ verstehen, können Sie ein Programm auf Kachelebene genauso schreiben wie Triton.Wenn Sie ein Anfänger sind, der nichts über Hardware weiß und nur Algorithmen kennt,Anschließend können Sie einen Ausdruck auf hoher Ebene schreiben, z. B. TRL, und ihn anschließend mithilfe der automatischen Planung in den entsprechenden Code einfügen.
Wie in der folgenden Abbildung gezeigt, habe ich den Dequant-Zeitplan auf der linken Seite mit TIR geschrieben, der nahtlos äquivalent in der Form von TileLang auf der rechten Seite geschrieben werden kann, wodurch die Koexistenz von Level 1 und Level 2 realisiert wird.

Als nächstes werde ich vorstellen, welche Aspekte beim Design von TileLang berücksichtigt werden müssen.
Die linke Seite der folgenden Abbildung zeigt die TileLang-Implementierung von DeepSeek MLA mit etwa 50 Codezeilen. In diesem Kernel sehen wir, dass Benutzer viele Dinge verwalten müssen, z. B. wie viele Blöcke (Thread-Blöcke) angegeben werden müssen, um beim Starten eines GPU-Kernels (Kernelfunktion) Rechenaufgaben parallel auszuführen, und wie viele Threads jedem Block zugewiesen werden sollen. Dies wird als Kachelkonfiguration bezeichnet, d. h. jeder Code unten hat einen Kontext. Benutzer müssen steuern, in welchem Speicherbereich sich der Puffer befindet, das Layout des gemeinsam genutzten Speichers oder der Register festlegen und Pipelines usw. berücksichtigen. All dies erfordert die Unterstützung des Compilers bei der Verwaltung.

Zu diesem Zweck unterteilen wir den Optimierungsraum in zwei Kategorien:Eine davon ist die Schlussfolgerung.Das heißt, der Compiler hilft dem Benutzer direkt, eine bessere Lösung zu finden.Eines ist zu empfehlen,Das heißt, Sie wählen einen Plan auf Grundlage einer Empfehlung aus.
Nach Berücksichtigung aller Optimierungsräume,Wir haben eine leistungsstarke FlashMLA-Implementierung, die ursprünglich aus mehr als 500 Codeblöcken bestand, auf nur 50 Zeilen TileLang-Code komprimiert und dabei die Leistung von 95% beibehalten.
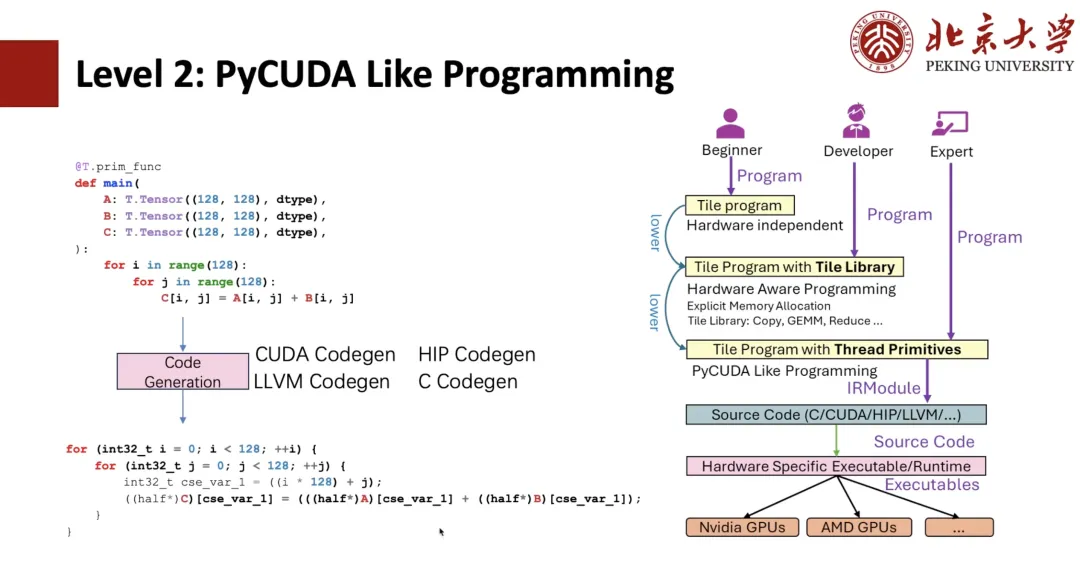
Als nächstes werde ich TileLang von ganz unten vorstellen.
Wie in der folgenden Abbildung dargestellt, sollten Studierende, die mit TIR vertraut sind, erkennen können, dass es sich um einen TIR-Ausdruck handelt. Anschließend können wir PyCUDA-Programmierung basierend auf TIR durchführen. Wenn wir beispielsweise zwei negative Python-Schleifen schreiben, können wir diese über TIR Codegen in CUDA-Ausdrücke generieren.
Wenn wir Thread-Grundelemente wie die Vektorisierung verwenden, können wir die CUDA-Vektorisierung und darüber hinaus die Thread-Bindung implementieren. Die oben genannten Programme sind alle ursprünglich von TIR und Benutzer können Programme wie CUDA schreiben, aber das Schreiben in Python ist immer noch komplizierter.
Um den Benutzern die Bedienung zu erleichtern,Die Schreibmethode der Level 1 Tile Library wurde vorgeschlagen.Beispielsweise geben wir einen Kernelkontext mit 128 Threads an und umschließen Copy anschließend mit „T.Parallel“. Nach der Compiler-Inferenz kann die soeben gezeigte Hochleistungsform abgeleitet und schließlich in CUDA-Code umgewandelt werden. Für eine elegantere Darstellung können Sie „T.copy“ direkt schreiben und Copy direkt in den Ausdruck „T.Parallel“ erweitern.
T.Parallel kann nicht nur kopieren, sondern auch komplexe Berechnungen durchführen und automatisch Vektorisierung und Thread-Bindung implementieren. Derzeit bieten wir neben dem Kopieren auch eine Sammlung von Kachelbibliotheken wie Reduzieren, Füllen, Löschen usw. an. Basierend auf der Kachelbibliothek können Sie dann einen guten Operator wie Triton schreiben.
Also,Das Kernkonzept, das „T.Parallel“ unterstützt, ist das Speicherlayout.
In TileLang unterstützen wir die Indizierung mehrdimensionaler Arrays mithilfe von High-Level-Schnittstellen wie A[i, k]. Dieser High-Level-Index wird schließlich über eine Reihe von Software- und Hardware-Abstraktionsschichten in eine physische Speicheradresse umgewandelt. Um diesen Indexkonvertierungsprozess zu modellieren,Wir haben das Layout eingeführt, um zu beschreiben, wie Daten im Speicher organisiert und abgebildet werden.
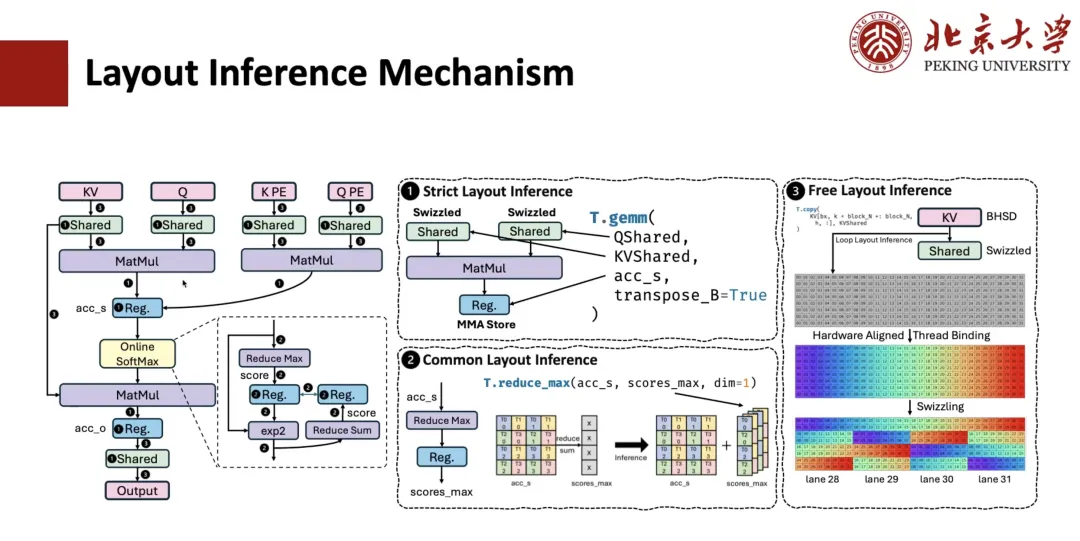
Wie wird die Layoutableitung für MLA-Berechnungen durchgeführt? Normalerweise umfasst dieser Prozess 3 Schritte.
Der erste Schritt ist die strikte Layout-Inferenz.Beispielsweise unterliegen Operatoren wie die Matrixmultiplikation strengen Einschränkungen hinsichtlich des Datenlayouts und müssen dem vorgegebenen Layout folgen. Daher wird auch das Layout der damit verbundenen Register festgelegt. Handelt es sich um gemeinsam genutzten Speicher und ist bekannt, dass dieser Operator eine Spill-Operation ausführen muss, wird auch das entsprechende Speicherlayout festgelegt.
Der zweite Schritt ist die gemeinsame Layout-Inferenz.Beispielsweise sollte für Ausdrücke, die mit dem im vorherigen Schritt ermittelten Layout verknüpft sind, auch deren Layout ermittelt werden. Nehmen wir beispielsweise eine Reduzierungsoperation von accum_s auf scope_max an, wobei das Layout von QMS über die Matrixebene festgelegt wird. Daraus lässt sich das Layout von scope_max ableiten. Durch diese allgemeine Argumentation lässt sich das Layout der meisten Zwischenausdrücke bestimmen.
Der dritte Schritt ist die freie Layout-Inferenz.Das heißt, das verbleibende freie Layout wird abgeleitet. Da es keinen starken Einschränkungen unterliegt, werden üblicherweise einige auf die Hardware abgestimmte Layout-Inferenzstrategien angewendet, um basierend auf dem Zugriffsmodus und dem Speicherumfang die optimale Layoutlösung abzuleiten.
Im Folgenden wird beschrieben, wie Pipeline die Ableitung durchführt.
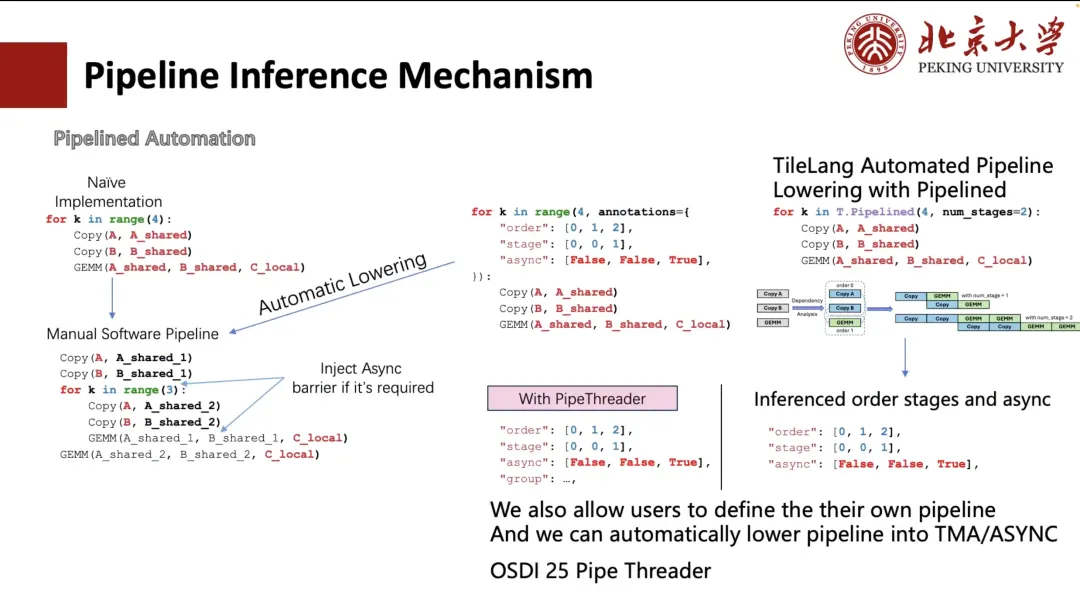
Normalerweise können wir die Pipeline manuell erweitern, aber diese Schreibmethode ist umständlich und nicht benutzerfreundlich. Daher hat TVM eine Möglichkeit erkundet, den Prozess durch Annotationen zu vereinfachen. Benutzer müssen lediglich die Ausführungsreihenfolge und die Planungsphase der Schleife angeben.TVM kann die Schleife automatisch in eine Struktur umwandeln, die dem manuellen Abrollen entspricht (wie in der unteren linken Ecke der Abbildung unten gezeigt).
Für Benutzer ist es jedoch immer noch kompliziert und umständlich. Daher reduzieren wir es in TileLang auf „num_stage“. Benutzer müssen lediglich den Wert „num_stage“ angeben, und das System kann die Abhängigkeiten in der Berechnung automatisch analysieren, planen und entsprechend aufteilen. Auf GPUs oder den meisten anderen Geräten können tatsächlich nur Copy und GEMM eine echte asynchrone Ausführung erreichen, insbesondere Kopiervorgänge, die asynchrone Übertragung durch Mechanismen wie ASYNC oder TMA unterstützen.
daher,Bei der Planung werden wir den Kopiervorgang in eine separate Phase aufteilen.Und leiten Sie automatisch die entsprechende Phaseneinteilung für die gesamte Pipeline ab. Natürlich können Benutzer die Planungsmethode auch manuell angeben, wie beispielsweise die beiden benutzerdefinierten Anordnungen in der Abbildung links.
Darüber hinaus unterstützen wir auch die automatische Layout-Inferenz und Scheduling-Optimierung basierend auf Hardwarefunktionen (wie z. B. TMA-Modulen auf A100 und H100). Dieser Teil der Arbeit stammt aus unserem Projekt Pipe Threader, das dieses Jahr auf der OSDI 25 veröffentlicht wird.
Als Nächstes werde ich Ihnen die Schlussfolgerung der Anweisungen erläutern.
Am Beispiel der Matrixmultiplikation gibt es zahlreiche Hardwarebefehle, die für „T.GEMM“ aufgerufen werden können. Beispielsweise können unter INT8-Präzision DP4A-Befehle oder eine auf TensorCore basierende INT8-Implementierung verwendet werden. Da jeder Befehl selbst mehrere Formen unterstützt, ist die Auswahl der optimalen Kachelkonfiguration unter diesen Implementierungen ein zentrales Problem.
Zu diesem Zweck bietet TileLang zwei Verwendungsmöglichkeiten:
Der erste besteht darin, dass TileLang es Benutzern ermöglicht, ASM durch Aufrufen von PTX zu schreiben.Der Nachteil dieser Methode besteht jedoch darin, dass der Kombinationsraum riesig ist. Wenn Sie mit allen PTX kompatibel sein möchten, müssen Sie viel Code schreiben und auch das Layout verwalten. Diese Methode ist jedoch sehr frei und gefällt mir persönlich sehr gut.
Aber wir verwenden jetzt die zweite Methode.Das heißt, auf „T.GEMM“ folgt eine Kachelbibliothek wie CUTE/CK-TILE.Es bietet eine Bibliotheksschnittstelle auf Kachelebene, die üblicherweise für die Matrixmultiplikation verwendet wird. Der Nachteil besteht jedoch darin, dass die Kompilierung aufgrund der Vorlagenerweiterung sehr lange dauert. Auf der RTX 4090 kann die Kompilierung einer Flash Attention 10 Sekunden dauern, wovon mehr als 901 TP3T für die Vorlagenerweiterung aufgewendet werden. Ein weiteres Problem ist die starke Trennung vom Python-Frontend.
Wir denken also,Die Kachelbibliothek ist eine Richtung, auf die wir uns in Zukunft konzentrieren werden.Das heißt, durch die native Syntax von Tile werden verschiedene Bibliotheken auf Tile-Ebene wie „T.GEMM“ und „T.GEMMSP“ unterstützt.
Zukünftige Berufsaussichten
Abschließend möchte ich Ihnen einige zukünftige Arbeiten unseres Teams vorstellen.
Das erste ist Tile Sight, das speziell dafür entwickelt wurde, die Leistungsoptimierung großer, komplexer Kernel (wie FlashAttention und FlashMLA) in großen Sprachmodellen zu beschleunigen.Dies ist ein leichtgewichtiges Framework zur automatischen Optimierung, das darauf abzielt, effiziente Kachelkonfigurationen (d. h. Kachelstrategien oder Planungshinweise) für mehrere Backends wie GPUs, CPUs und Beschleuniger zu generieren und zu bewerten. Dadurch können Entwickler schnell Planungsstrategien mit überlegener Leistung finden und die manuelle Optimierungszeit reduzieren.
Basierend auf dem oben genannten benutzerdefinierten Modell ist es für Benutzer einfacher, einen schwierigen Kernel wie MLA zu schreiben. Das benutzerdefinierte Modell kann Benutzer anleiten, jeden Cache auf der entsprechenden gemeinsam genutzten Stelle zu platzieren.
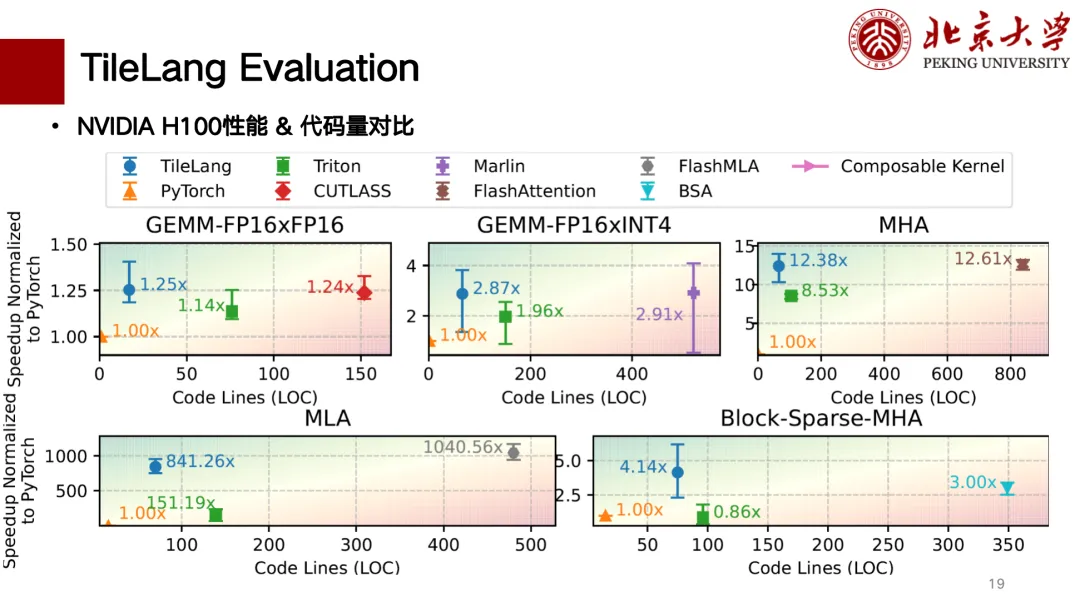
Nachfolgend finden Sie eine teilweise Leistungsbewertung von TileLang. Wir haben die Unterstützung für H- und A-Karten weitgehend abgeschlossen. Die folgende Abbildung zeigt einen Vergleich der Anzahl der Codezeilen mit der Leistung. Die Leistung ist oben links besser. TileLang erreicht beispielsweise bei der Matrizenmultiplikation eine ähnliche Leistung wie CUTLASS. Auch Operatoren wie MLA, Flash Attention, Block Sparse usw. erreichen eine ähnliche Leistung wie CUTLASS. Die Anzahl der Codezeilen ist relativ gering und der Code lässt sich relativ sauber schreiben.
Im TileLang-Ökosystem wird es bereits von einigen Nutzern verwendet. Beispielsweise basiert der Kernquantisierungsoperator des niedrigpräzisen großen BitNet-Modells von Microsoft auf TileLang, und auch Microsofts BitBLAS basiert vollständig auf TileLang. In Bezug auf die Unterstützung inländischer Chips bieten wir auch Unterstützung für Suanneng TPU und Ascend NPU.








