Command Palette
Search for a command to run...
Online-Tutorial | Mistral AIs Erstes Open-Source-Audiomodell Voxtral, Versionen 24B Und 3B Berücksichtigen Tiefes Sprachverständnis in Mehreren Szenarien

Als natürlichste Art der menschlichen Interaktion entwickelt sich die Sprache zunehmend zum Kernszenario der Mensch-Computer-Interaktion. Mit der zunehmenden Verbreitung der Sprachinteraktion werden auch Audiomodelle ständig weiterentwickelt und bedarfsgerecht optimiert.Die rasante Entwicklung geht jedoch mit einer Polarisierung des Marktangebots einher: Kostengünstige Open-Source-Modelle sind anfälliger für Probleme wie hohe Fehlerraten und mangelndes semantisches Verständnis, während teure Closed-Source-Modelle in der Regel teuer sind und Einschränkungen bei der Bereitstellung aufweisen. Beide Modelle können den unterschiedlichen Anforderungen nur schwer gerecht werden.
Auf dieser GrundlageMistral AI hat vor Kurzem offiziell sein erstes fortschrittliches Audiomodell, Voxtral, herausgebracht, das sich mit Open Source, hoher Leistung und niedrigen Kosten auf die Schwachstellen des Marktes für Sprachintelligenz konzentriert.Das Modell ist in zwei Versionen erhältlich: 24B und 3B. Erstere eignet sich für den großflächigen Einsatz auf Unternehmensebene, während Letztere die Einstiegshürde für den individuellen, leichtgewichtigen Einsatz senkt. Voxtral bietet Funktionen, die auf exzellenter Sprachtranskription und tiefem Sprachverständnis basieren. Es unterstützt mehrere Sprachen, die Verarbeitung langer Textkontexte sowie integrierte Frage-Antwort- und Zusammenfassungsfunktionen und übertrifft in mehreren Benchmarks die Leistung bestehender Open-Source-Audiomodelle. Gleichzeitig ist es kostengünstiger und vielseitig einsetzbar, was zur Popularisierung der Sprachinteraktion beiträgt.
Voxtral nutzt Technologie, um den qualitativen Wandel von Sprachinteraktionsmodellen von „benutzbar“ zu „benutzerfreundlich“ voranzutreiben.Es erfüllt nicht nur die Marktnachfrage nach leistungsstarken Audiomodellen, sondern erweitert auch die Anwendungsszenarien der Sprachinteraktion und bildet damit den intelligenten ökologischen Eckpfeiler des natürlichen Dialogs.
„Demo des Sprachverständnismodells Voxtral-Small-3B/24B-2507“Der Abschnitt „Tutorial“ der offiziellen Website von HyperAI (hyper.ai) ist jetzt online.Lassen Sie uns ein immersives Erlebnis der Sprachinteraktion beginnen, bei dem wir „genauer hören und tiefer verstehen“ und neue Durchbrüche bei fortschrittlichen Audiomodellen erleben können!
Link zum Tutorial:
* Demo des Sprachverständnismodells Voxtral-Mini-3B-2507:
* Voxtral-Small-24B-2507 Sprachverständnismodell Demo:
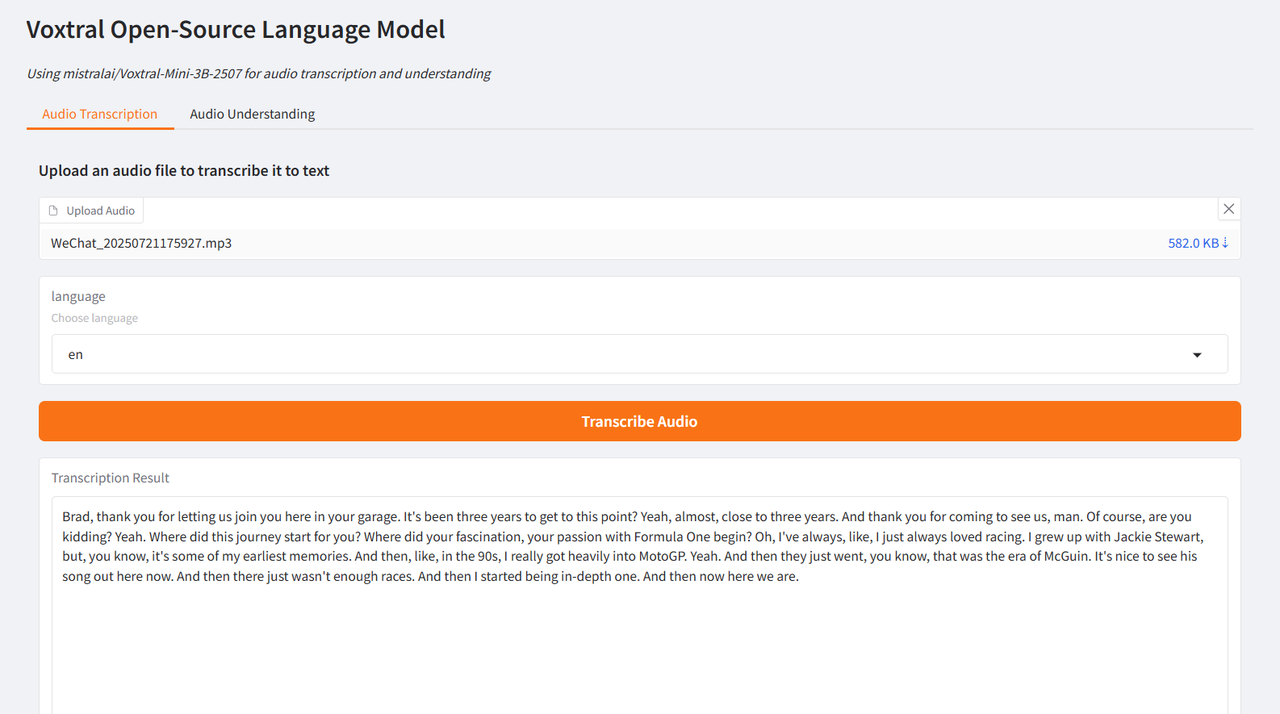
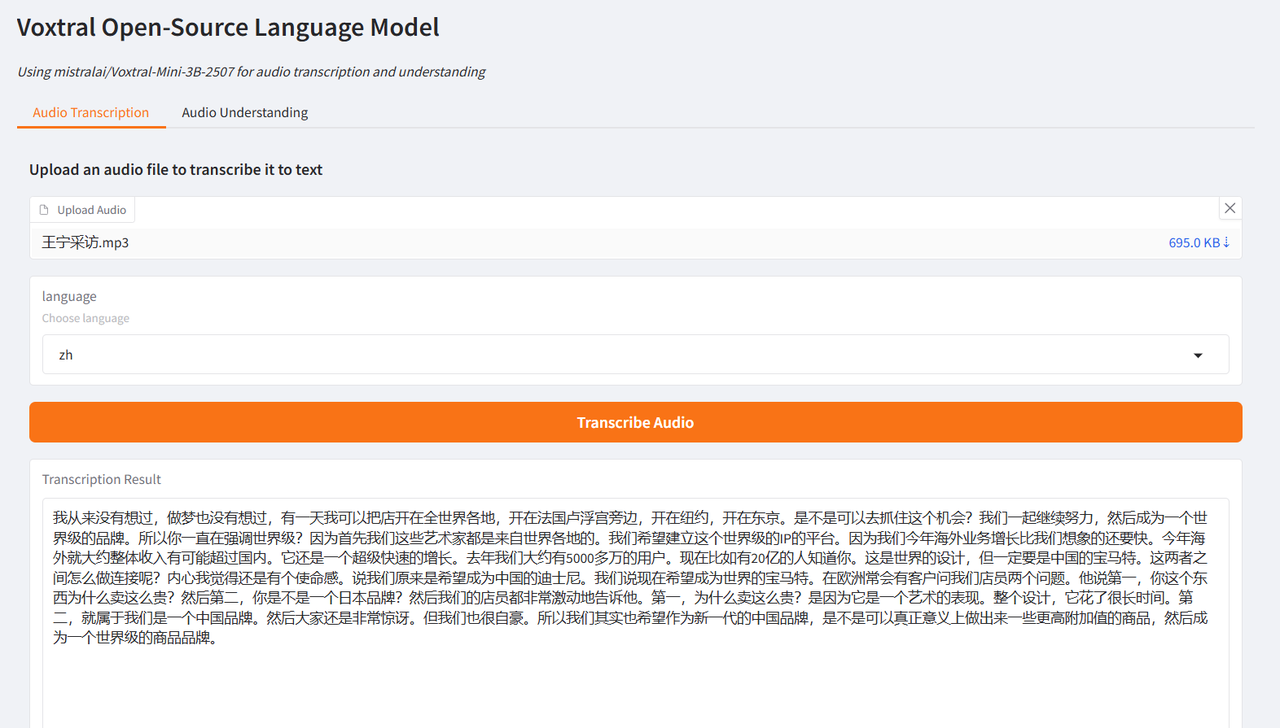
Der Autor testete es anhand von Interviewausschnitten von Brad Pitt, dem Hauptdarsteller von „F1: Wild Race“, und Wang Ning, dem Gründer von Pop Mart, die von CCTV interviewt wurden. Die erzielten Ergebnisse waren sehr optimal und bestätigten die leistungsstarken Funktionen von Voxtral.
Demolauf
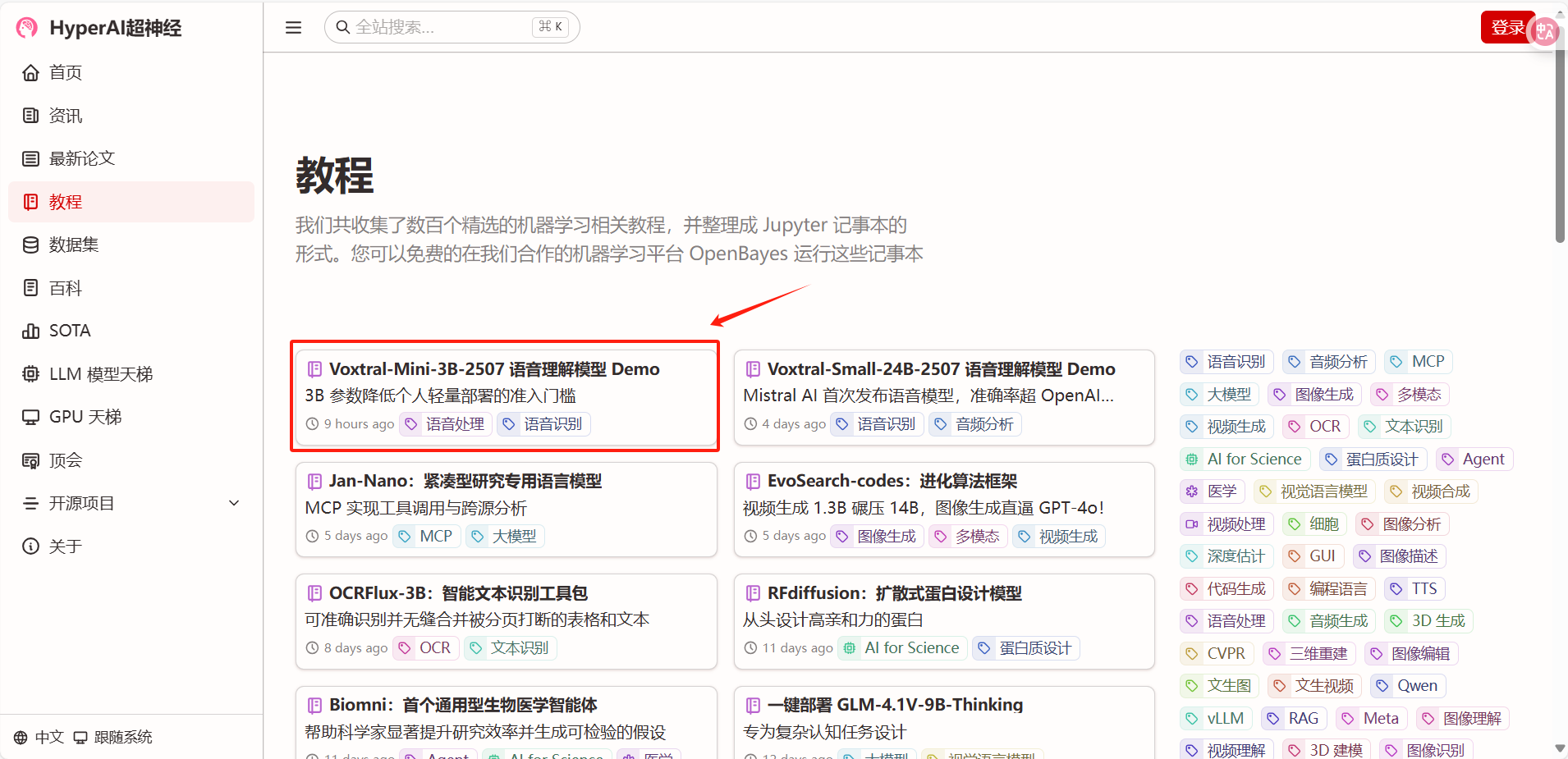
1. Nachdem Sie die Homepage von hyper.ai aufgerufen haben, wählen Sie die Seite „Tutorial“, wählen Sie „Voxtral-Mini-3B-2507 Speech Understanding Model Demo“ und klicken Sie auf „Dieses Tutorial online ausführen“.
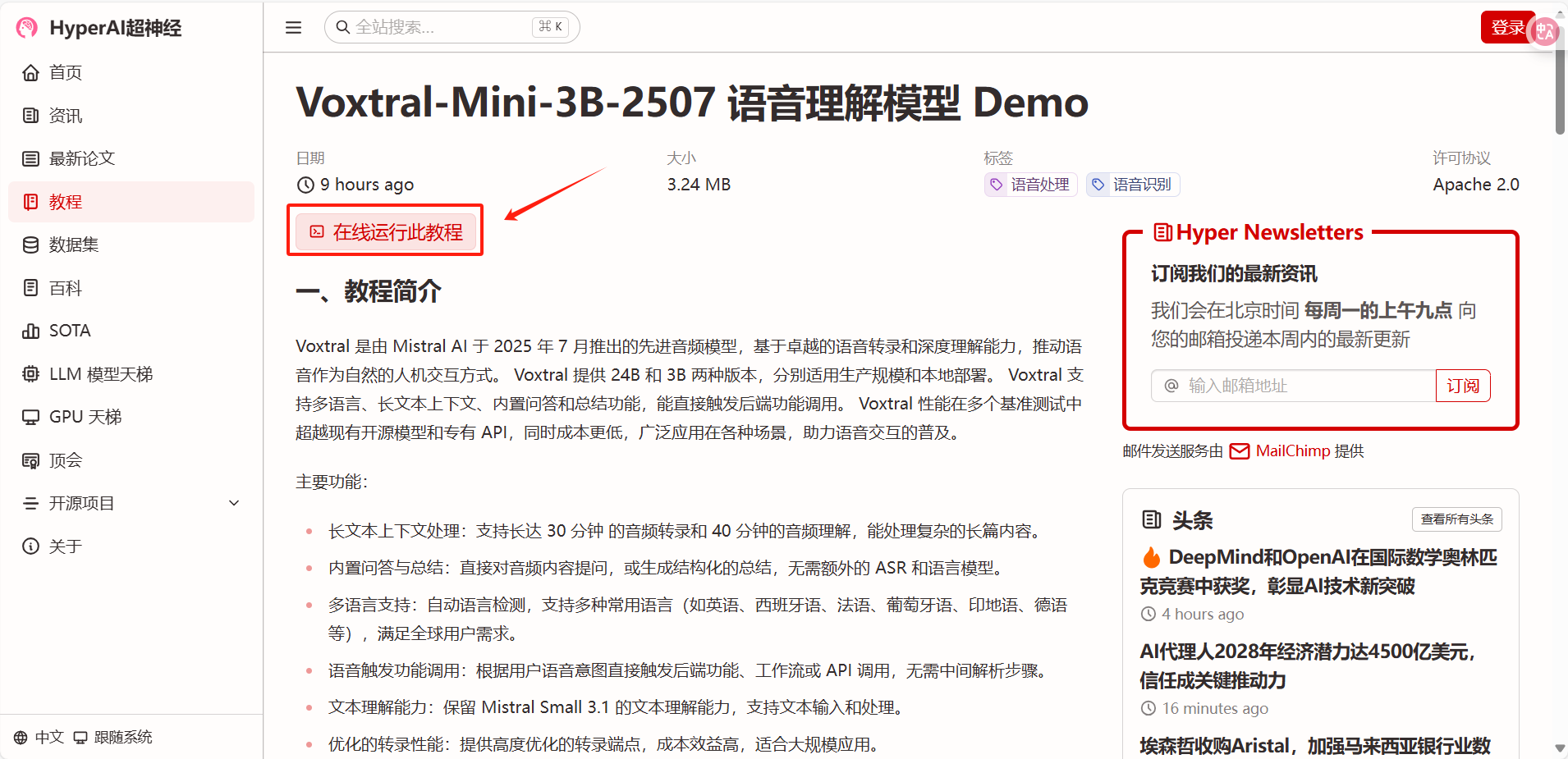
2. Klicken Sie nach dem Seitensprung oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
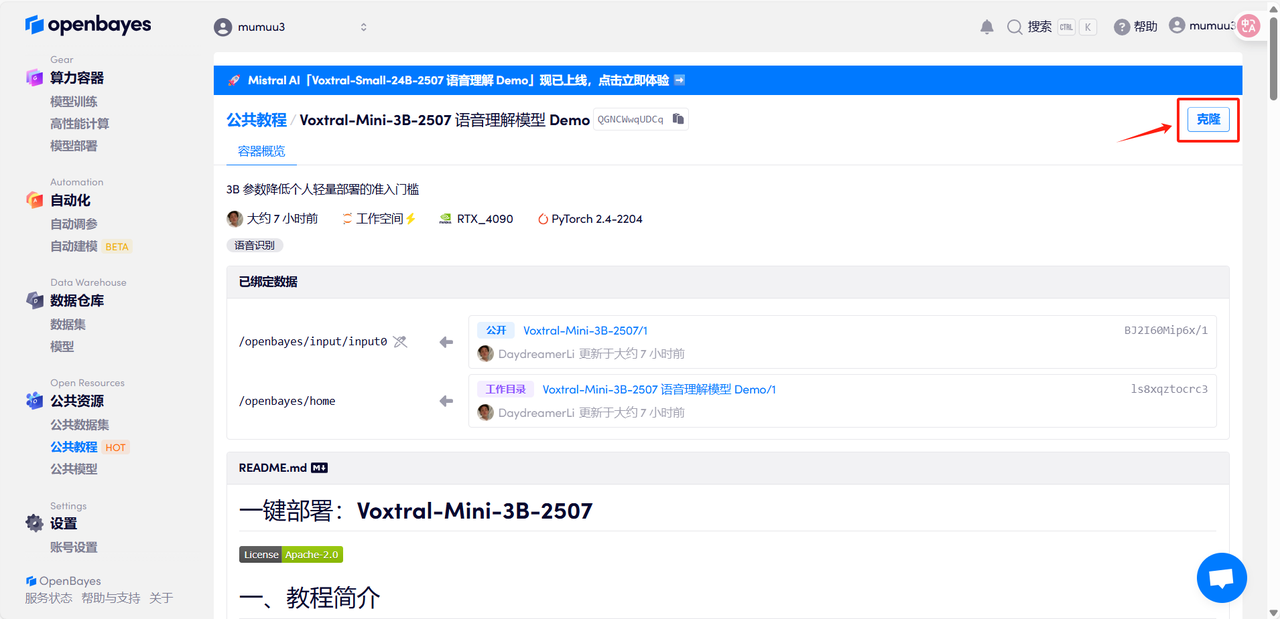
3. Wähle die Bilder „NVIDIA GeForce RTX 4090“ und „PyTorch“ aus, wähle je nach Bedarf „Pay as you go“ oder „Tages-/Wochen-/Monatspaket“ und klicke auf „Weiter“. Neue Benutzer können sich über den unten stehenden Einladungslink registrieren und erhalten 4 Stunden RTX 4090 + 5 Stunden CPU-freie Zeit!
Exklusiver Einladungslink von HyperAI (kopieren und im Browser öffnen):
https://openbayes.com/console/signup?r=Ada0322_NR0n
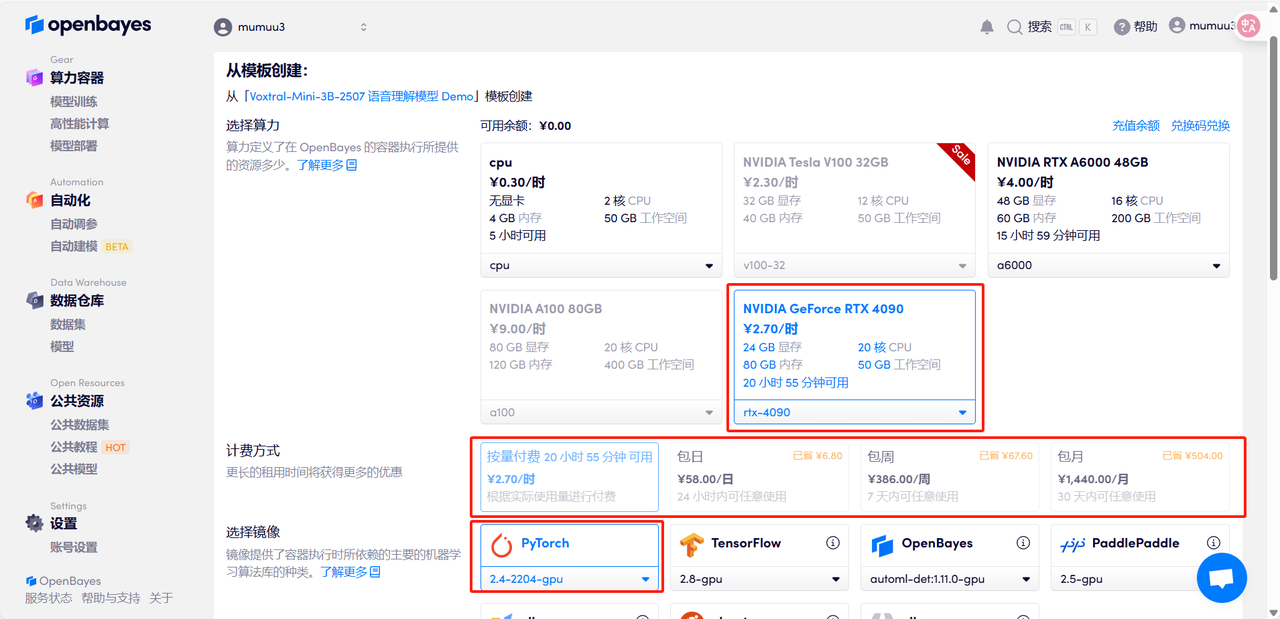
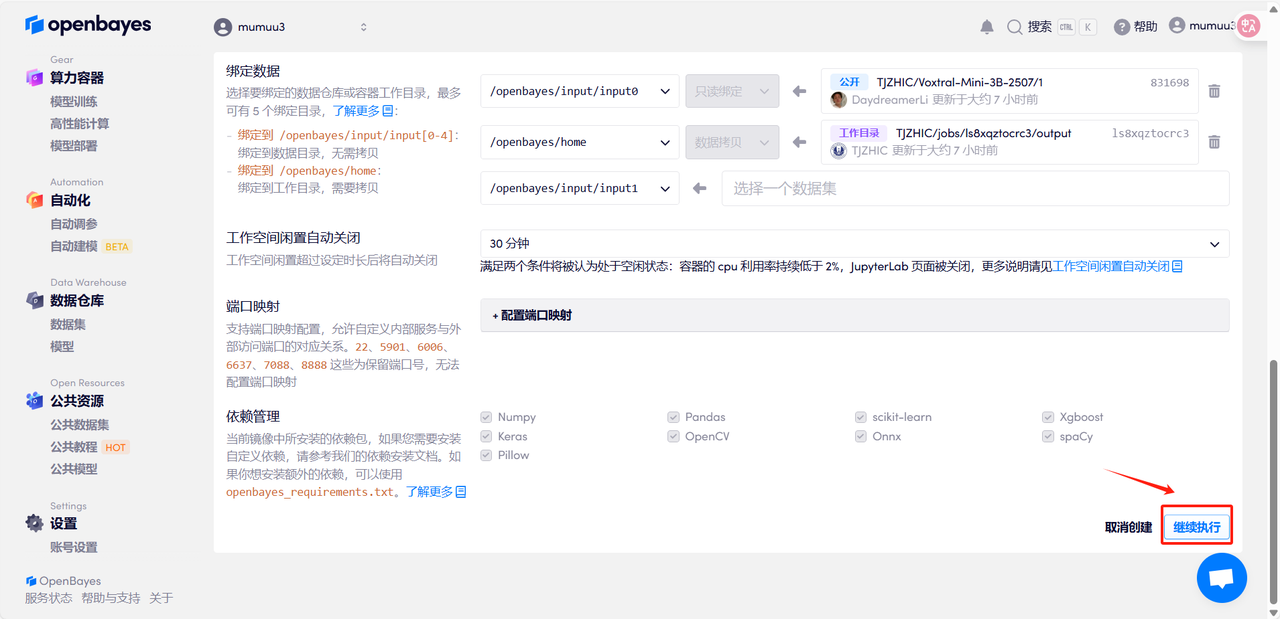
4. Warten Sie, bis die Ressourcen zugewiesen sind. Der erste Klon dauert etwa 3 Minuten. Sobald der Status auf „Läuft“ wechselt, klicken Sie auf den Sprungpfeil neben „API-Adresse“, um zur Demoseite zu gelangen. Bitte beachten Sie, dass Benutzer vor der Nutzung der API-Adresszugriffsfunktion eine Echtnamenauthentifizierung durchführen müssen.
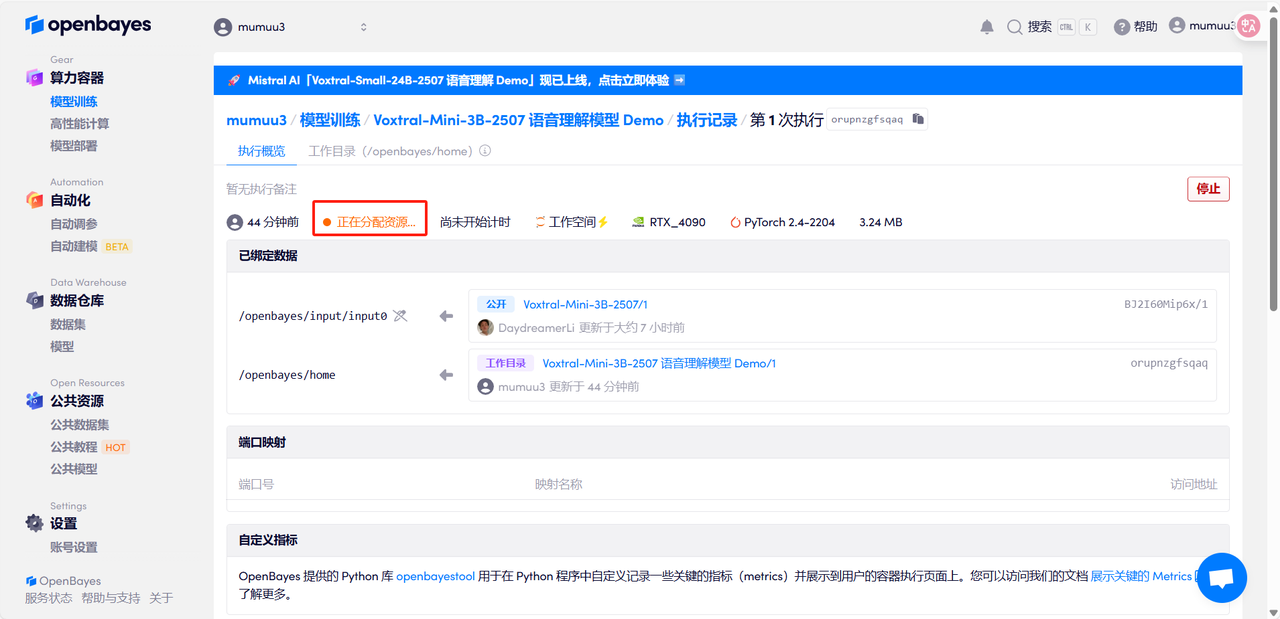
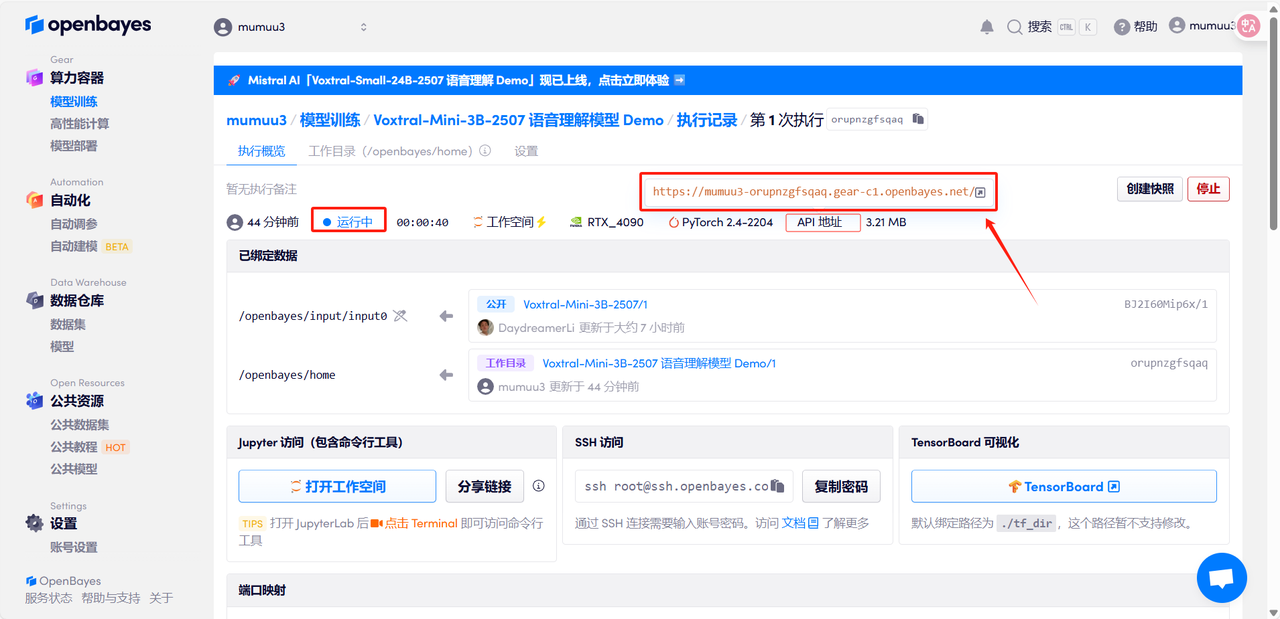
Effektdemonstration
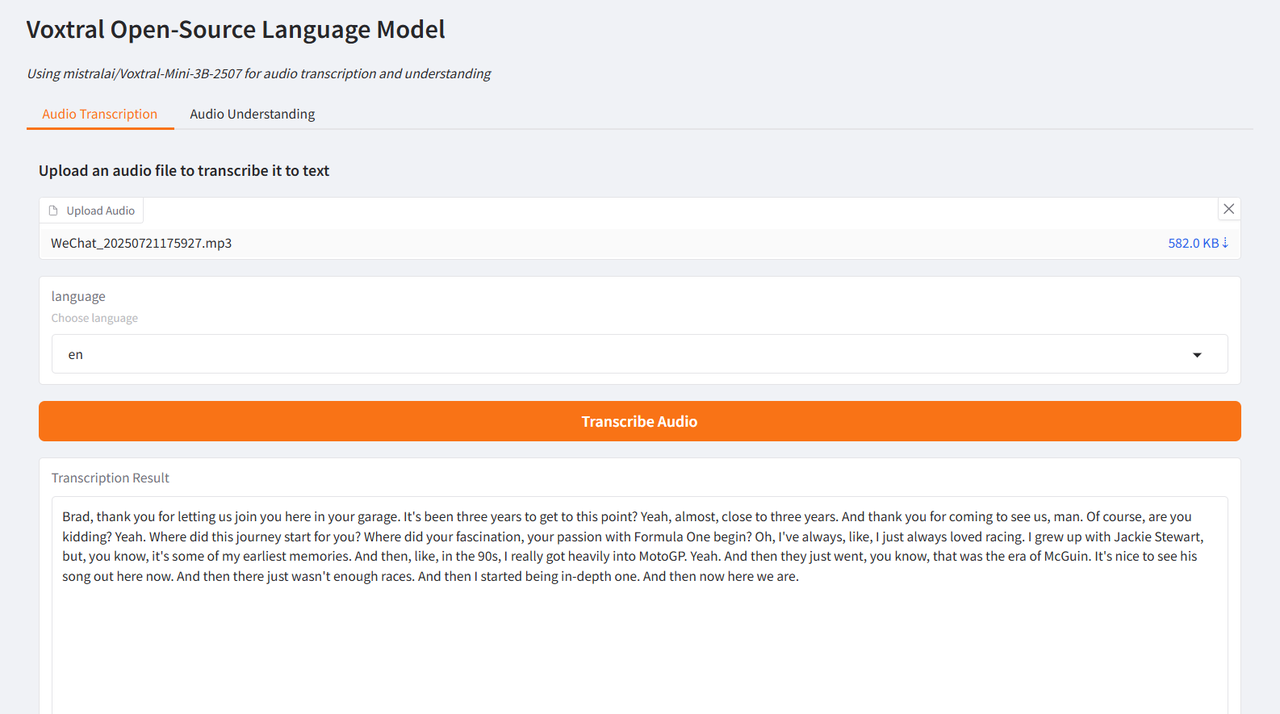
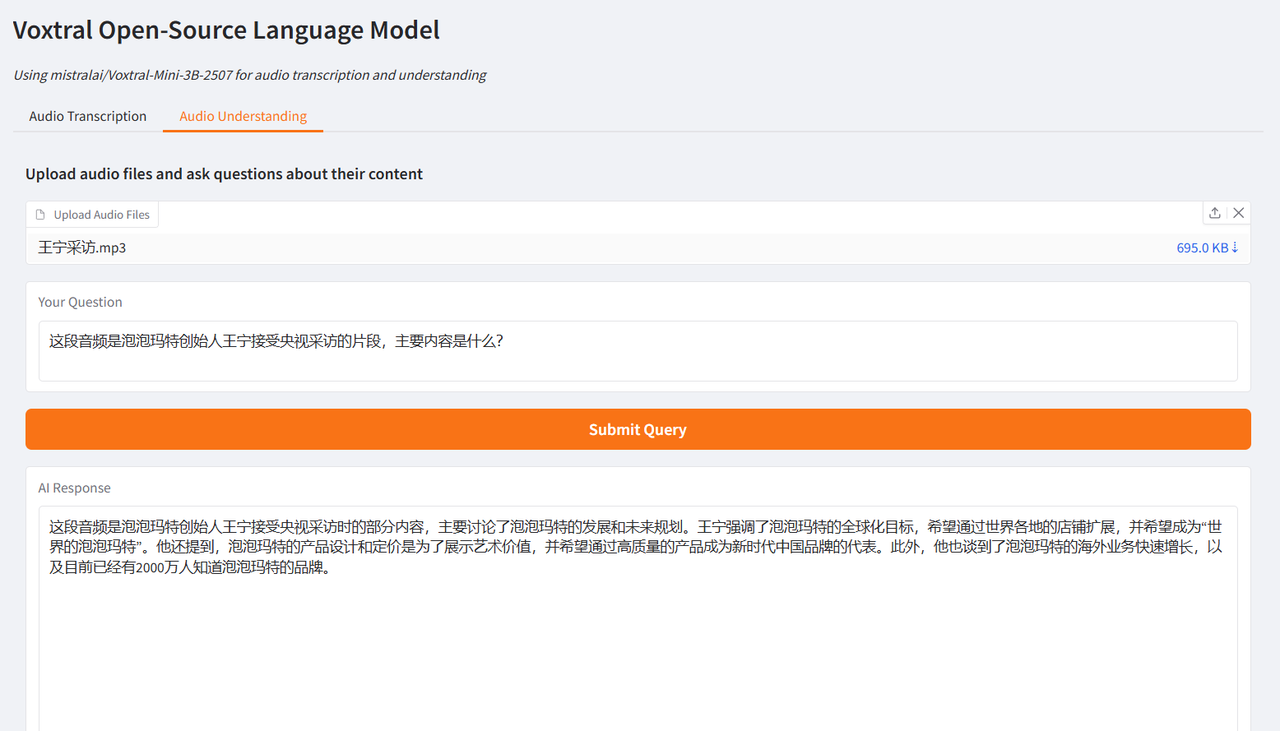
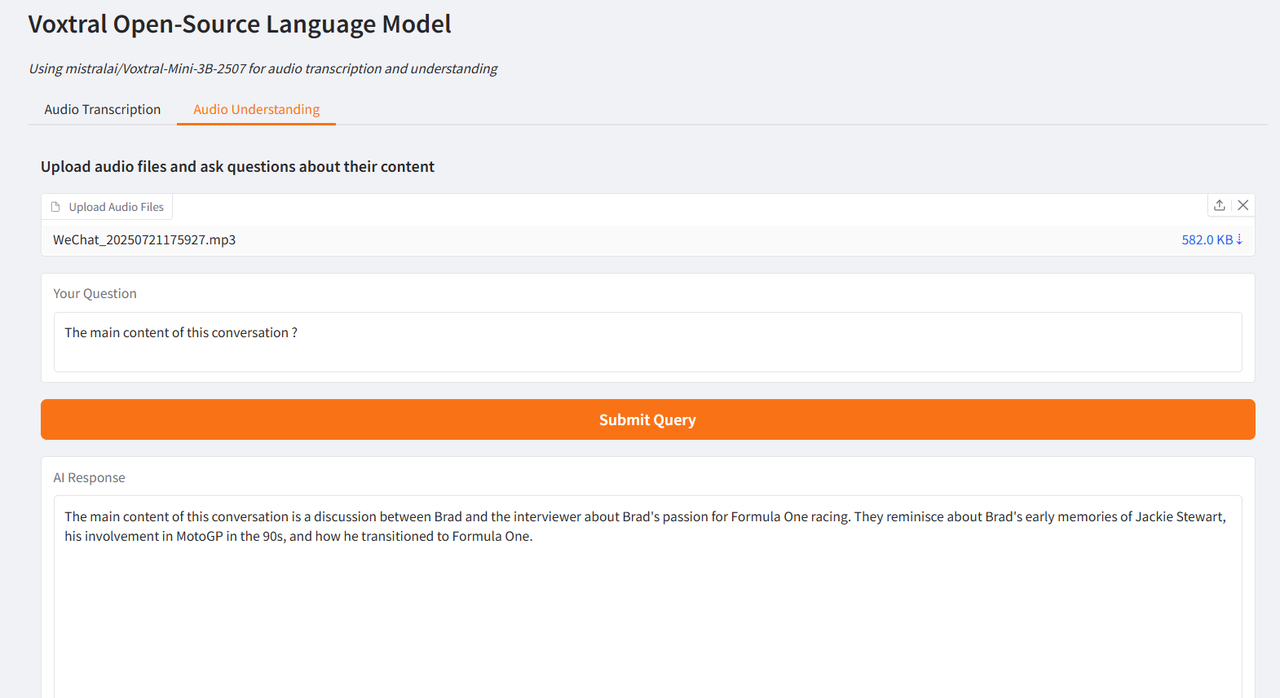
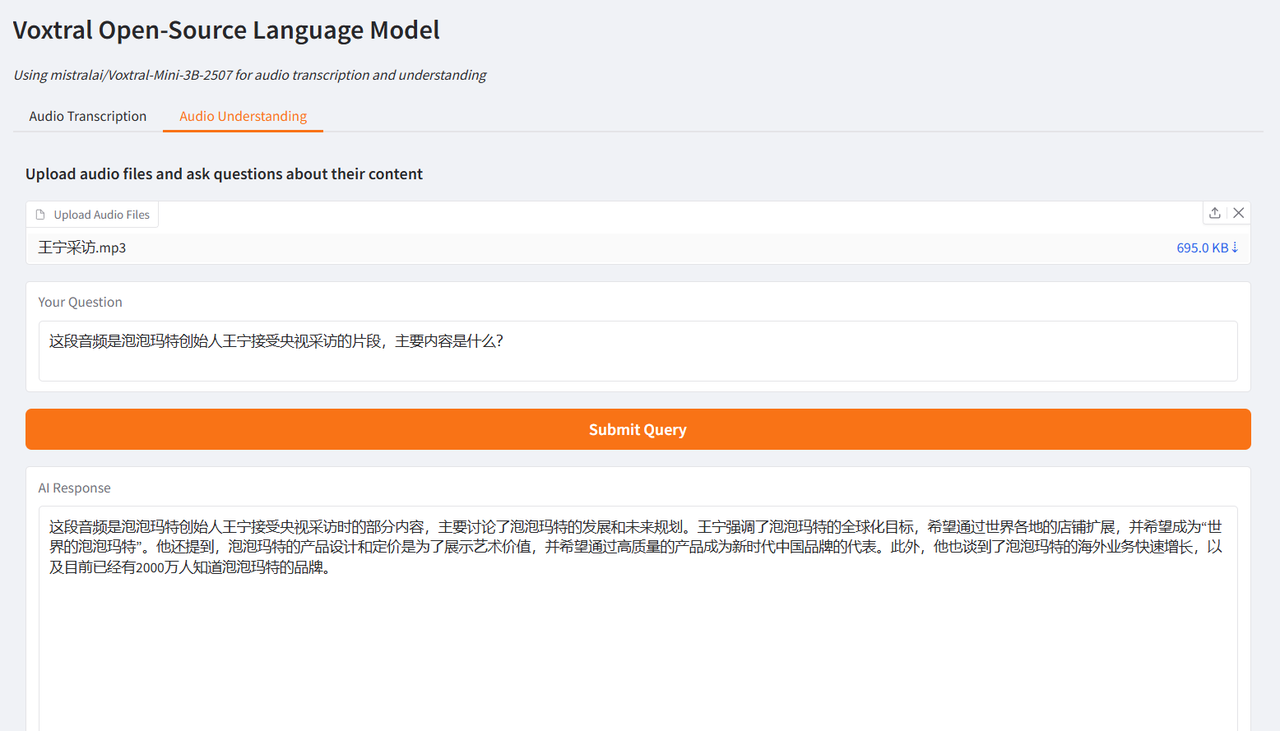
Der Autor testete es anhand von Interviewausschnitten von Brad Pitt, dem Hauptdarsteller von „F1: Wild Race“, und Wang Ning, dem Gründer von Pop Mart, die von CCTV interviewt wurden. Die erzielten Ergebnisse waren sehr optimal und bestätigten die leistungsstarken Funktionen von Voxtral.
Wählen Sie die Testfunktion „Audiotranskription“, laden Sie einen Audioclip hoch, wählen Sie die Sprache aus und klicken Sie auf „Audio transkribieren“. Das Ergebnis wird nach kurzer Zeit generiert.
Wählen Sie die Testfunktion „Audioverständnis“, laden Sie einen Audioclip hoch, geben Sie die Frage ein, klicken Sie auf „Anfrage senden“ und die Ergebnisse werden nach einer Weile generiert.
Darüber hinaus eignet sich die von Voxtral bereitgestellte 24B-Version für den groß angelegten Einsatz auf Unternehmensebene. Sie ist jetzt im Abschnitt „Tutorial“ der offiziellen HyperAI-Website (hyper.ai) verfügbar und kann von Benutzern nach Bedarf ausprobiert werden!
Link zum Tutorial:
* Demo des Sprachverständnismodells Voxtral-Mini-3B-2507:
* Voxtral-Small-24B-2507 Sprachverständnismodell Demo:








