Command Palette
Search for a command to run...
Die Trainingsleistung Wurde Deutlich verbessert. Bytedances Zheng Size Erläutert Das Triton-verteilte Framework, Um Eine Effiziente Verteilte Kommunikation Und Computerintegration Für Große Modelle Zu erreichen.

Im Jahr 2025 fand der von HyperAI veranstaltete Meet AI Complier Technology Salon zum siebten Mal statt. Mit der Unterstützung von Community-Partnern und zahlreichen Branchenexperten haben wir mehrere Standorte in Peking, Shanghai, Shenzhen und anderen Orten eingerichtet, um Entwicklern und Enthusiasten eine Kommunikationsplattform zu bieten, die Geheimnisse bahnbrechender Technologien zu lüften, das Anwendungsfeedback von Front-Line-Entwicklern zu erhalten, praktische Erfahrungen bei der Technologieimplementierung auszutauschen und innovatives Denken aus verschiedenen Blickwinkeln zu hören.
Folgen Sie dem öffentlichen WeChat-Konto „HyperAI Super Neuro“ und antworten Sie auf das Schlüsselwort „0705 AI Compiler“, um die PPT mit der Rede des autorisierten Dozenten zu erhalten.




In der Keynote-Rede „Triton-verteilt: Native Python-Programmierung für Hochleistungskommunikation“,Zheng Size, Saatgutforscher bei ByteDanceEs analysiert detailliert den Durchbruch in der Kommunikationseffizienz und plattformübergreifenden Anpassungsfähigkeit von Triton-verteiltem Training für große Modelle sowie wie durch Python-Programmierung eine tiefe Integration von Kommunikation und Computing erreicht werden kann.Nach dem Austausch häuften sich die Fragen schnell. Es gab endlose Diskussionen über Details wie das FLUX-Framework, das Tile-Programmiermodell, die AllGather- und ReduceScatter-Optimierung usw. Die Diskussionen konzentrierten sich auf die wichtigsten technischen Schwierigkeiten und praktischen Erfahrungen und förderten effektiv die Verbindung von Theorie und Anwendung.
HyperAI hat die Rede von Herrn Zheng Size zusammengestellt und zusammengefasst, ohne die ursprüngliche Absicht zu verletzen. Im Folgenden finden Sie die Abschrift der Rede.
Echte Herausforderungen des verteilten Trainings
Im Kontext der schnellen Entwicklung großer Modelle sind sowohl das Training als auch das SchlussfolgernVerteilte Systeme sind aus diesem Kontext nicht mehr wegzudenken.Wir haben in dieser Richtung auch Untersuchungen auf Compilerebene durchgeführt und das Projekt als Open Source veröffentlicht und es „Triton-Distributed“ genannt.
Zu den gängigen Hardware-Verbindungsmethoden zählen NVLink, PCIe und knotenübergreifende Netzwerkkommunikation. Unter idealen Bedingungen kann die unidirektionale NVLink-Bandbreite des H100 450 GB/s erreichen. In den meisten Heimanwendungen ist jedoch der H800 die gängigere Variante, dessen unidirektionale Bandbreite nur etwa 200 GB/s beträgt. Dadurch sind die Gesamtkommunikationsfähigkeit und die Topologiekomplexität erheblich reduziert.Eine offensichtliche Herausforderung, der wir im Projekt gegenüberstanden, war der Engpass bei der Systemleistung, der durch unzureichende Bandbreite und asymmetrische Kommunikationstopologie verursacht wurde.
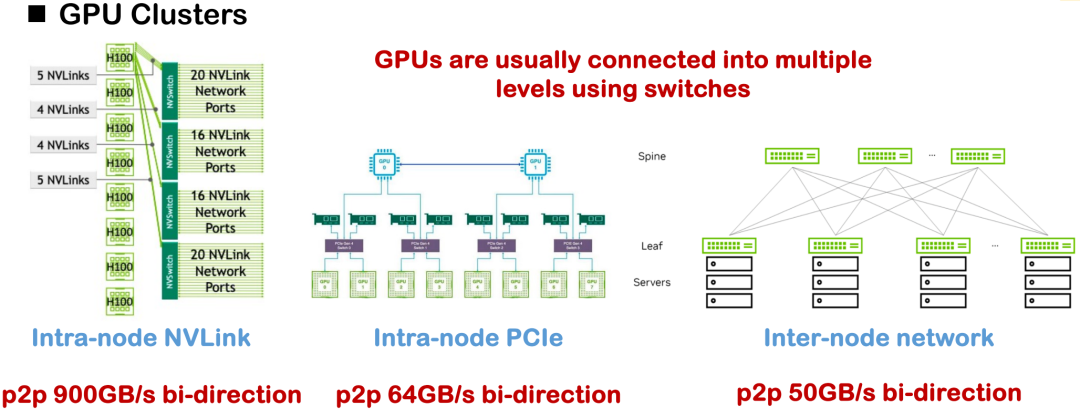
Vor diesem Hintergrund stützte sich die frühe verteilte Optimierung oft auf eine große Anzahl manuell implementierter Kommunikationsoperatoren, darunter Strategien wie Tensor-, Pipeline- und Datenparallelität, die alle eine sorgfältige Entwicklung der zugrunde liegenden Kommunikationslogik erforderten. Üblicherweise werden Kommunikationsbibliotheken wie NCCL und ROCm CCL aufgerufen. Solchen Lösungen mangelt es jedoch oft an Vielseitigkeit und Portabilität, und sie verursachen hohe Entwicklungs- und Wartungskosten.
Bei der Analyse der Engpässe des bestehenden Systems haben wir drei wichtige Fakten zusammengefasst:
Fakt 1: Die Hardwarebandbreite ist begrenzt und die Kommunikationslatenz wird zum Engpass
Die erste ist die Einschränkung durch die grundlegenden Hardwarebedingungen. Beim Training eines großen Modells mit H100 ist die Rechenverzögerung oft deutlich höher als die Kommunikationsverzögerung, sodass der Überlappung von Rechen- und Kommunikationsplanung keine besondere Aufmerksamkeit gewidmet werden muss. In der aktuellen H800-Umgebung ist die Kommunikationsverzögerung jedoch deutlich länger. Wir haben festgestellt, dass in einigen Szenarien fast die Hälfte der Trainingszeit durch Kommunikationsverzögerungen verbraucht wird, was zu einer deutlichen Verringerung der gesamten MSU (Model Scale Utilization) führt. Wird die Überlappung von Kommunikation und Rechenleistung nicht optimiert, führt dies zu erheblicher Ressourcenverschwendung.
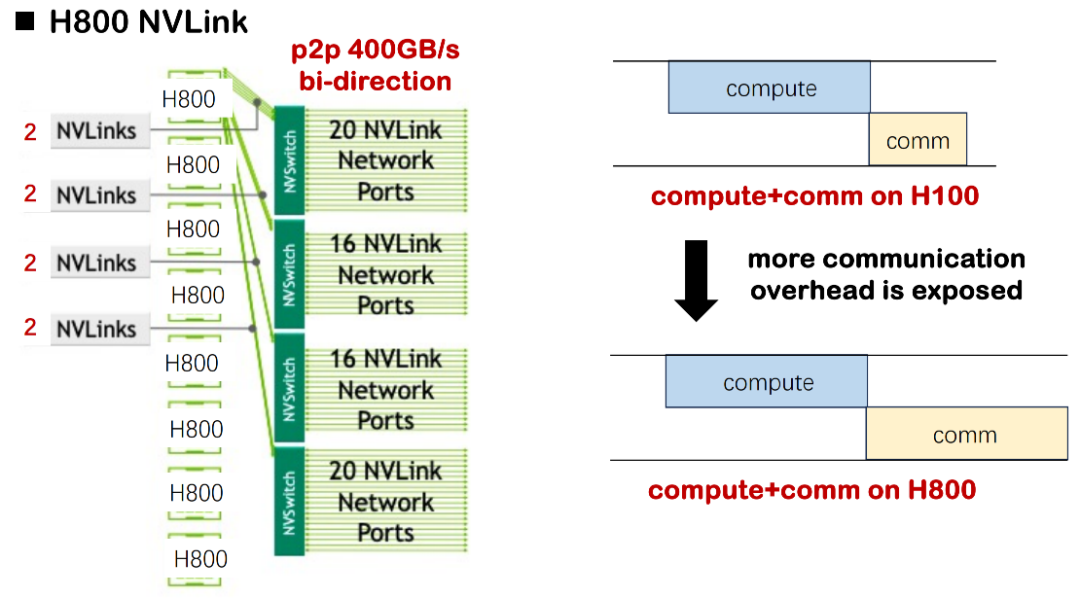
In kleinen und mittelgroßen Fällen ist dieser Verlust akzeptabel. Sobald das Modell jedoch auf Tausende von Karten erweitert wird, wie beispielsweise in der Trainingspraxis von MegaScale oder DeepSeek, erreicht der kumulierte Ressourcenverlust Millionen oder sogar Dutzende Millionen Dollar, was für Unternehmen einen sehr realen Kostendruck darstellt.
Gleiches gilt für Inferenzszenarien. Die ersten Inferenz-Implementierungen von DeepSeek nutzten bis zu 320 Karten. Trotz späterer Komprimierung und Optimierung ist die Kommunikationslatenz nach wie vor ein unvermeidbares Kernproblem verteilter Systeme. Daher ist die effektive Planung von Kommunikation und Computing auf Programmebene und die Verbesserung der Gesamteffizienz zu einem zentralen Thema geworden, dem wir uns direkt stellen müssen.
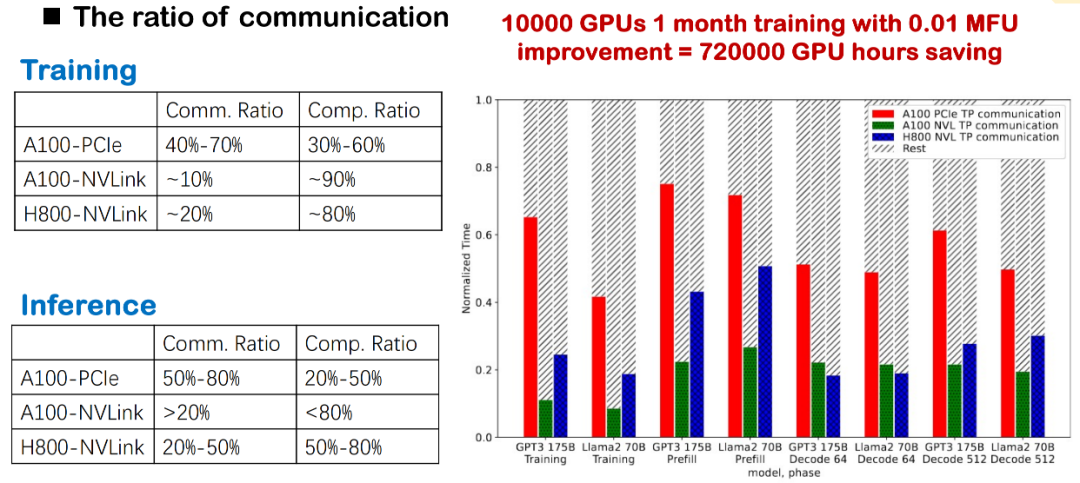
Fakt 2: Hoher Kommunikationsaufwand wirkt sich direkt auf die MFU-Leistung aus
Beim Training und der Argumentation groß angelegter Modelle stellt der Kommunikationsaufwand stets einen erheblichen Engpass dar. Wir haben beobachtet, dass der Kommunikationsanteil sehr hoch ist, unabhängig davon, ob die zugrunde liegende Schicht NVLink, PCIe oder verschiedene GPU-Generationen (wie A100 und H800) verwendet. Insbesondere bei realen Implementierungen im Inland beeinträchtigen Kommunikationsverzögerungen aufgrund offensichtlicher Bandbreitenbeschränkungen die Gesamteffizienz unmittelbar.
Beim Training großer Modelle reduziert diese hochfrequente kartenübergreifende Kommunikation die MFU des Systems erheblich. Daher ist die Optimierung des Kommunikations-Overheads ein entscheidender Verbesserungspunkt für die Verbesserung der Trainings- und Inferenzleistung und gehört zu unseren Schwerpunkten.
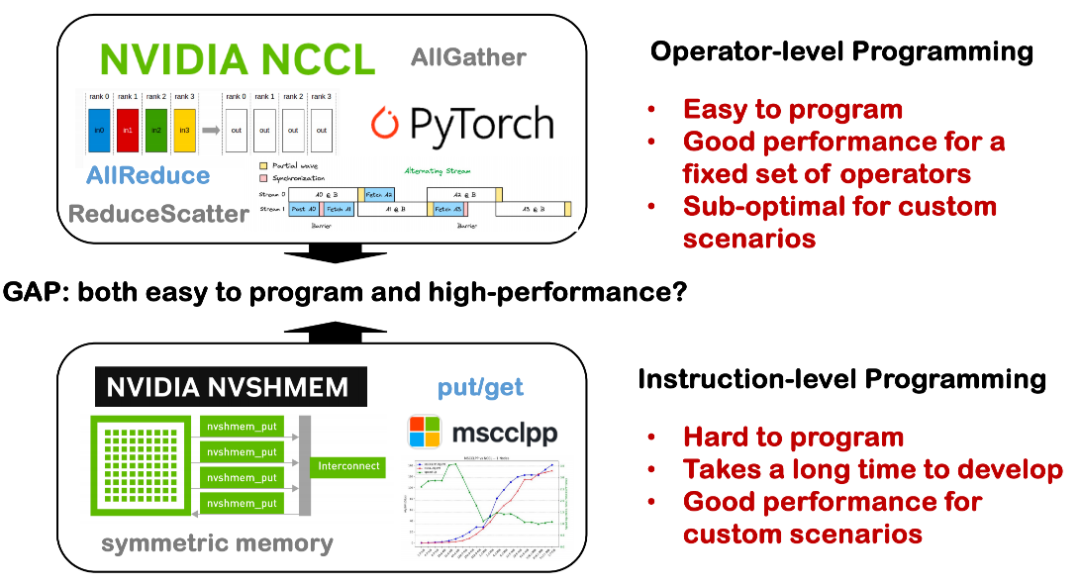
Fakt 3: Die Lücke zwischen Programmierbarkeit und Leistung
Derzeit besteht in verteilten Systemen noch eine große Lücke zwischen Programmierbarkeit und Leistung. Früher lag der Fokus stärker auf den Optimierungsmöglichkeiten von Single-Card-Compilern, beispielsweise darauf, wie sich mit einer einzelnen Karte eine hervorragende Leistung erzielen lässt. Bei der Erweiterung auf eine einzelne Maschine mit mehreren Karten oder sogar auf ein verteiltes System über mehrere Knoten hinweg wird die Situation jedoch komplizierter.
Einerseits erfordert verteilte Kommunikation viele grundlegende technische Details wie NCCL, MPI und Topologie, die in verschiedenen dedizierten Bibliotheken verstreut sind und eine hohe Nutzungsschwelle aufweisen. Entwickler müssen Kommunikationslogik oft manuell implementieren, Berechnungen und Synchronisierung manuell planen, was zu hohen Entwicklungskosten und einer hohen Fehlerquote führt. Andererseits können Tools, die komplexe Kommunikationsplanung und Operatoroptimierung unter verteilten Bedingungen automatisch durchführen, Entwicklern helfen, die Entwicklungsschwelle deutlich zu senken und die Verfügbarkeit und Wartbarkeit verteilter Systeme zu verbessern. Dies ist eines der Probleme, die wir mit Triton-Distributed lösen möchten.
Basierend auf den drei oben genannten praktischen Problemen haben wir drei Kernrichtungen in Triton-Distributed vorgeschlagen:
Erstens: Fördern Sie den Überschneidungsmechanismus von Kommunikation und Computertechnik.In verteilten Szenarien, in denen der Kommunikationsaufwand immer stärker in den Vordergrund rückt, hoffen wir, möglichst viele parallele Zeitfenster für Berechnung und Kommunikation einplanen zu können, um die Gesamteffizienz des Systems zu verbessern.
Zweitens ist es notwendig, die Rechen- und Kommunikationsmodi großer Modelle umfassend zu integrieren und anzupassen.Beispielsweise versuchen wir, die gängigen Kommunikationsmuster wie AllReduce und Broadcast mit dem Berechnungsmuster in das Modell zu integrieren, um das synchrone Warten zu reduzieren und den Ausführungspfad zu komprimieren.
Schließlich sind wir der Meinung, dass diese Optimierungen vom Compiler durchgeführt werden sollten, anstatt sich darauf zu verlassen, dass Entwickler hochgradig angepasste CUDA-Implementierungen von Hand schreiben.Wir arbeiten daran, die Entwicklung verteilter Systeme abstrakter und effizienter zu gestalten.
Analyse der verteilten Architektur von Triton: natives Python für Hochleistungskommunikation
Wir hoffen, im verteilten Training Überlappung zu erreichen, doch die Umsetzung ist nicht einfach. Konzeptionell bedeutet Überlappung, Berechnungen und Kommunikation gleichzeitig über mehrere Streams durchzuführen, um Kommunikationsverzögerungen zu kaschieren. Dies ist in Szenarien ohne Abhängigkeit zwischen Operatoren einfacher. In Tensor Parallel (TP) oder Expert Parallel (EP) muss AllGather jedoch abgeschlossen sein, bevor GEMM ausgeführt werden kann. Beide liegen im kritischen Pfad, und Überlappung ist sehr schwierig.
Gängige Methoden umfassen derzeit: erstens die Aufteilung der Aufgabe in mehrere Mikro-Batches und das Erreichen von Überlappungen mit der Unabhängigkeit der Batches; zweitens die Aufteilung mit feinerer Granularität (z. B. Kachelgranularität) innerhalb eines einzelnen Batches und das Erreichen paralleler Effekte durch Kernelfusion. Wir haben diese Art der Aufteilung und des Planungsmechanismus auch in Flux untersucht. Gleichzeitig ist der Kommunikationsmodus beim Training großer Modelle hochkomplex. Beispielsweise muss DeepSeek bei MoE die All-to-All-Kommunikation anpassen, um Bandbreite und Lastverteilung zu berücksichtigen; beispielsweise können allgemeine Bibliotheken wie NCCL in Szenarien mit geringer Latenz und Quantisierung die Leistungsanforderungen nur schwer erfüllen und erfordern oft handgeschriebene Kommunikationskernel, was den Anpassungsaufwand erhöht.
Deshalb glauben wirDie Optimierungsfähigkeit der Kommunikations-Computer-Fusion sollte von der Compilerebene übernommen werden, um mit komplexen Modellstrukturen und unterschiedlichen Hardwareumgebungen zurechtzukommen und den Entwicklungsaufwand zu vermeiden, der durch wiederholte manuelle Implementierung entsteht.
Zweischichtige Kommunikation – primitive Abstraktion
In unserem Compiler-Design haben wir eine abstrakte Struktur mit zweischichtigen Kommunikationsprimitiven übernommen, um sowohl die Ausdrucksfähigkeit der Optimierung auf der oberen Schicht als auch die Durchführbarkeit der zugrunde liegenden Bereitstellung zu berücksichtigen.
Die erste Schicht ist ein Primitiv auf relativ hoher Ebene, das hauptsächlich die Berechnungsplanung auf Kachelgranularitätsebene durchführt und eine abstrakte Schnittstelle für die Kommunikation bereitstellt.Es verwendet Push/Get-Operationen zwischen Rängen als Kommunikationsabstraktion und unterscheidet jedes Kommunikationsverhalten durch einen Tag-Identifizierungsmechanismus, wodurch es für den Scheduler einfacher wird, Datenflüsse und Abhängigkeiten zu verfolgen.
Die zweite Schicht ist näher an der zugrunde liegenden Implementierung und verwendet ein primitives System, das dem Open Shared Memory-Standard (OpenSHMEM) ähnelt.Diese Schicht wird hauptsächlich zum Zuordnen zu vorhandenen Kommunikationsbibliotheken oder Hardware-Backends verwendet, um echtes Kommunikationsverhalten zu implementieren.
Auch,Im Multi-Rank-Szenario müssen wir auch Barriere- und Signalkontrollmechanismen für die Cross-Rank-Synchronisierung einführen.Wenn Sie beispielsweise andere Ränge benachrichtigen müssen, dass Ihre Daten geschrieben wurden, oder wenn Sie darauf warten, dass die Daten eines bestimmten Ranges bereit sind, ist diese Art von Synchronisierungssignal sehr wichtig.

Compilerarchitektur und semantische Modellierung
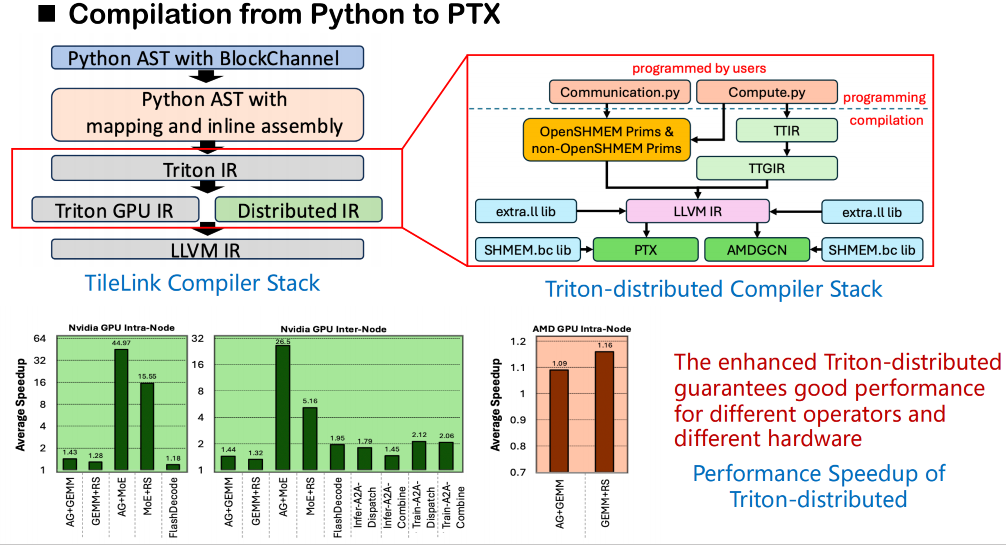
Was den Kompilierstapel betrifft, basiert unser Gesamtprozess weiterhin auf dem ursprünglichen Triton-Kompilierframework. Ausgehend vom Quellcode konvertiert Triton den Benutzercode zunächst in einen abstrakten Syntaxbaum (AST) und übersetzt ihn anschließend in Triton IR. In dem von uns erstellten Triton-DistributedDas ursprüngliche Triton IR wurde erweitert und eine neue IR-Schicht für verteilte Semantik hinzugefügt.Diese verteilte IR führt die semantische Modellierung von Synchronisationsvorgängen wie Warten und Benachrichtigen ein, um die Kommunikationsabhängigkeiten zwischen den Rängen zu beschreiben. Gleichzeitig entwickeln wir eine Reihe semantischer Schnittstellen für OpenSHMEM, um Kommunikationsaufrufe auf niedrigerer Ebene zu unterstützen.
In der eigentlichen Codegenerierungsphase kann diese Semantik auf externe Aufrufe der zugrunde liegenden Kommunikationsbibliothek abgebildet werden. Wir verknüpfen diese Aufrufe direkt mit der Bitcode-Version der Bibliothek (nicht mit dem Quellcode), die von OpenSHMEM über die LLVM-Mittelschicht bereitgestellt wird, um eine effiziente Shared-Memory-Kommunikation über verschiedene Ränge hinweg zu erreichen. Diese Methode umgeht die Einschränkung, dass Triton keinen direkten Zugriff auf externe Bibliotheken vom Quellcode aus unterstützt. Dadurch können Shared-Memory-bezogene Aufrufe die Symbolauflösung und die Verknüpfung während der Kompilierung reibungslos durchführen.
Zuordnungsmechanismus zwischen Primitiven auf hoher Ebene und Ausführung auf niedriger Ebene
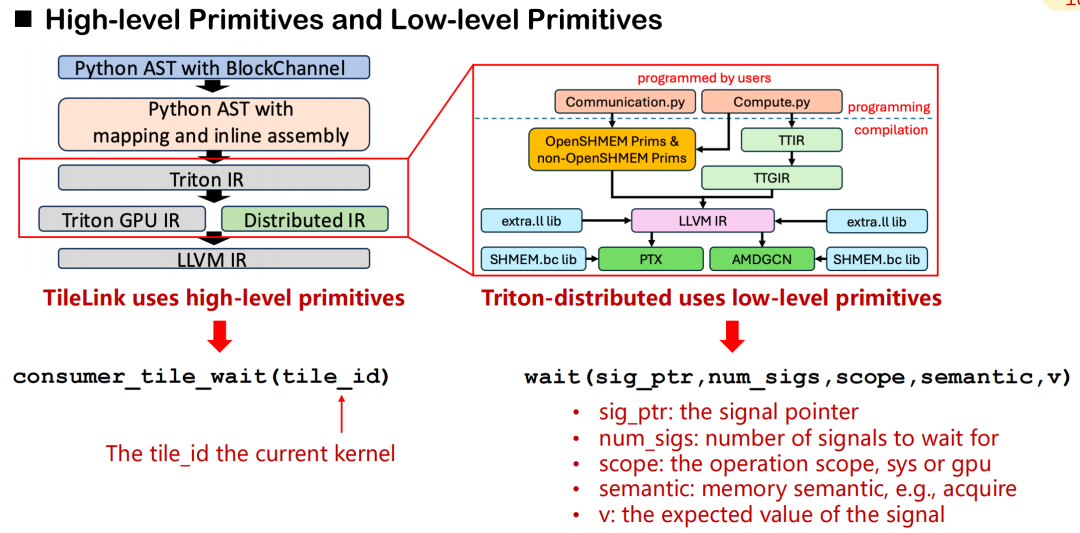
In Triton-Distributed haben wir ein System von Kommunikationsprimitiven entwickelt, das eine Abstraktion auf hoher Ebene und eine Steuerung auf niedriger Ebene abdeckt.Am Beispiel von consumer_tile_wait müssen Entwickler lediglich die zu wartende Kachel-ID deklarieren. Das System leitet dann automatisch den spezifischen Rang und Offset des Kommunikationsziels basierend auf der aktuellen Operatorsemantik (z. B. AllGather) ab, um die Synchronisierungslogik abzuschließen. Hochrangige Primitive schützen die Details spezifischer Datenquellen und Signalübertragungen und verbessern so die Entwicklungseffizienz.
Im Gegensatz dazu bieten Low-Level-Primitive feingranulare Steuerungsmöglichkeiten. Entwickler müssen Signalzeiger, Bereiche (GPU oder System), Speichersemantik (Erfassen, Freigeben usw.) und erwartete Werte manuell angeben. Obwohl dieser Mechanismus komplexer ist, eignet er sich für Szenarien mit extrem hohen Anforderungen an Kommunikationslatenz und Planungsgenauigkeit.
Hochrangige Primitive lassen sich grob in zwei Kategorien unterteilen: Signalsteuerung und Datensteuerung. In der Semantik der SignalsteuerungWir definieren hauptsächlich drei Arten von Rollen: Produzent, Verbraucher und Peer.Sie erreichen die Synchronisierung durch Lese- und Schreibsignale, was dem Handshake-Mechanismus in der verteilten Kommunikation ähnelt. Für die Datenübertragung bietet Triton-Distributed zwei Grundelemente: Push und Pull, die dem aktiven Senden von Daten an die Remote-Karte bzw. dem Abrufen von Daten von der Remote-Karte auf die lokale Karte entsprechen.
Alle Low-Level-Kommunikationsprimitive folgen dem OpenSHMEM-Standard und unterstützen derzeit NVSHMEM und ROCSHMEM. Es besteht eine klare Zuordnungsbeziehung zwischen High-Level- und Low-Level-Primitiven, und der Compiler ist für die automatische Konvertierung einfacher Schnittstellen in Low-Level-Synchronisations- und Übertragungsanweisungen verantwortlich. Durch diesen MechanismusDie Triton-Verteilung behält nicht nur die Hochleistungsfunktionen der Kommunikationsplanung bei, sondern reduziert auch die Komplexität der verteilten Programmierung erheblich.
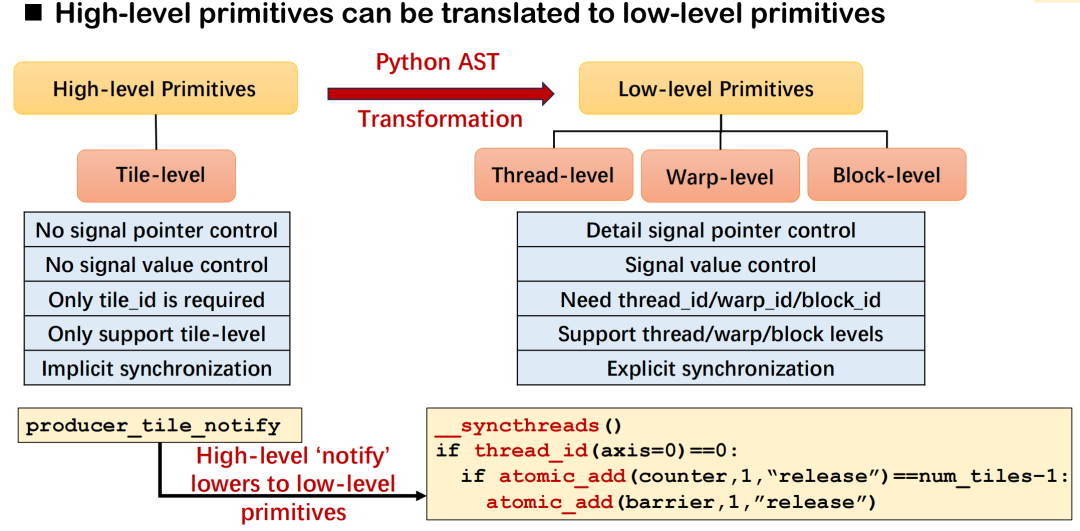
In der Triton-Verteilung besteht das Designziel hochrangiger Kommunikationsprimitive (wie „Notify“ und „Wait“) darin, die kartenübergreifenden Synchronisationsanforderungen mit präziser Semantik zu beschreiben. Der Compiler ist für die Übersetzung in die entsprechende zugrunde liegende Ausführungslogik verantwortlich. Am Beispiel von „Notify“ bilden „It“ und „Wait“ ein Paar von Synchronisationssemantiken: „It“ dient zum Senden von Benachrichtigungen, „It“ zum Warten auf den Abschluss der Datenaufbereitung. Entwickler müssen lediglich die Kachel-ID angeben, und das System kann die zugrunde liegenden Details wie Kommunikationsziele und Signaloffsets automatisch anhand des Operatortyps und der Kommunikationstopologie ableiten.
Die konkrete zugrunde liegende Implementierung variiert je nach Einsatzumgebung. Beispielsweise kann diese Art der Synchronisierung in einem Szenario mit acht GPUs durch _syncthreads() und atomic_dd innerhalb eines Threads erreicht werden. Bei der maschinenübergreifenden Bereitstellung werden Primitive wie signal_up von NVSHMEM oder ROCSHMEM verwendet, um entsprechende Operationen auszuführen. Diese Mechanismen bilden zusammen die Zuordnungsbeziehung zwischen hochrangiger Semantik und niedrigrangigen Primitiven und zeichnen sich durch hohe Vielseitigkeit und Skalierbarkeit aus.
Nehmen wir als Beispiel ein GEMM ReduceScatter-Kommunikationsszenario: Angenommen, das System verfügt über 4 GPUs, und die Zielposition jedes Tiles wird durch vorberechnete Metadaten (wie Tile-Zuweisung und Barrierenummer für jeden Rang) bestimmt. Entwickler müssen lediglich eine Benachrichtigungsanweisung in den in Triton geschriebenen GEMM-Kernel einfügen, und der ReduceScatter-Kernel verwendet „Wait“, um Daten synchron zu empfangen.
Der gesamte Prozess kann in Python dargestellt werden und unterstützt den Kernelmodus des Dual-Stream-Starts mit klarer Kommunikationslogik und einfacher Planung. Dieser Mechanismus verbessert nicht nur die Ausdrucksfähigkeit der kartenübergreifenden Kommunikationsprogrammierung, sondern reduziert auch die Komplexität der zugrunde liegenden Implementierung erheblich und bietet eine starke Basisunterstützung für effizientes Training und Denken großer verteilter Modelle.
Mehrdimensionale Überlappungsoptimierung: Vom Planungsmechanismus zur Topologieerkennung
Obwohl Triton-Distributed eine relativ übersichtliche Schnittstelle für primitive Kommunikationssysteme auf hoher Ebene bietet, gibt es beim Schreiben und Optimieren des Kernels noch gewisse technische Hürden. Wir haben festgestellt, dass das primitive Design zwar eine gute Ausdruckskraft aufweist, die Anzahl der Benutzer, die es wirklich flexibel anwenden und tiefgreifend optimieren können, jedoch immer noch begrenzt ist. Im Wesentlichen ist die Kommunikationsoptimierung nach wie vor eine Aufgabe, die stark von technischer Erfahrung und Planungsverständnis abhängt und derzeit noch manuell von Entwicklern gesteuert werden muss. Zu diesem Thema haben wir einige wichtige Optimierungspfade zusammengefasst. Im Folgenden finden Sie typische Implementierungsstrategien für Triton-Distributed.
Push vs. Pull: Datenflussrichtung und Kontrolle der Barrierenanzahl
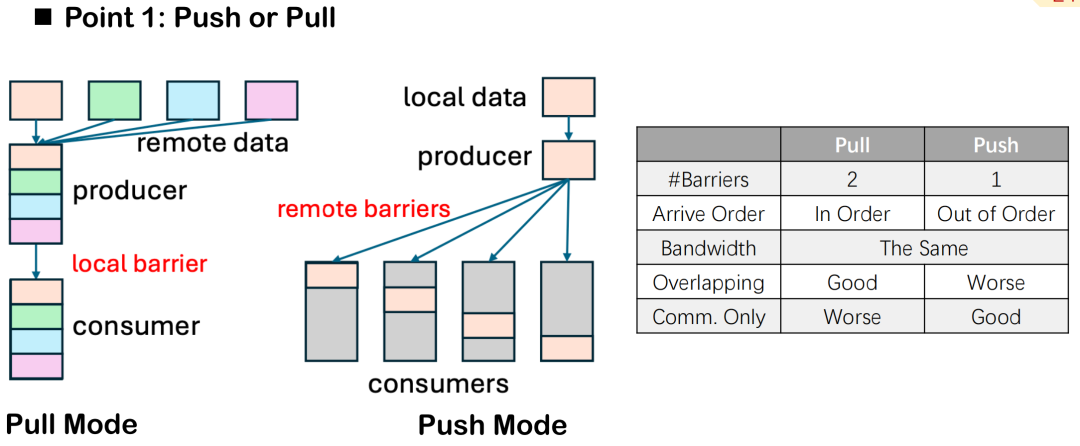
Bei der Überlappungsoptimierung von Kommunikation und BerechnungTriton-Distributed bietet zwei Datenübertragungsmethoden: Push und Pull.Obwohl der semantische Unterschied zwischen ihnen nur in der Richtung des „aktiven Sendens“ und des „passiven Ziehens“ liegt, gibt es bei der tatsächlichen verteilten Ausführung offensichtliche Unterschiede in ihrer Leistung und ihren Planungssteuerungsfunktionen.
Am Beispiel der Anzahl der Barrieren sind im Pull-Modus in der Regel zwei Barrieren erforderlich: eine, um sicherzustellen, dass die lokalen Daten vor dem Pull durch die Gegenstelle bereitstehen, und eine, um die Daten während des gesamten Kommunikationszyklus vor Änderungen durch die lokale Task zu schützen und so Dateninkonsistenzen oder Lese-/Schreibkonflikte zu vermeiden. Im Push-Modus muss nach dem Schreiben der Daten auf das Remote-Ende nur eine Barriere gesetzt werden, um alle Geräte zu synchronisieren. Dies vereinfacht die Gesamtsteuerung.
Der Pull-Modus bietet jedoch auch Vorteile. Er ermöglicht es lokalen Knoten, die Reihenfolge des Datenabrufs aktiv zu steuern und so den Zeitpunkt der Kommunikation und die Überlappung der Berechnungen präziser zu planen. Um den Überlappungseffekt zu maximieren und Parallelität zwischen Kommunikation und Berechnung zu erreichen, bietet Pull mehr Flexibilität.
Wenn das Hauptziel in der Verbesserung der Überlappung liegt, wird im Allgemeinen Pull empfohlen. Bei einigen reinen Kommunikationsaufgaben, wie etwa einem separaten AllGather- oder ReduceScatter-Kernel, ist der Push-Modus aufgrund seiner Einfachheit und des geringeren Overheads üblicher.
Swizzling Scheduling: Dynamisches Anpassen der Reihenfolge basierend auf dem Datenstandort
Die Überschneidung von Kommunikation und Berechnung hängt nicht nur von der Wahl der Primitiven, sondern auch von der Planungsstrategie ab. Swizzling ist eine Methode zur Planungsoptimierung, die auf Topologiebewusstsein basiert und darauf abzielt, Leerlaufzeiten bei kartenübergreifendem Computing zu reduzieren. Aus verteilter Sicht kann jede GPU-Karte als unabhängige Ausführungseinheit betrachtet werden. Da jede Karte zunächst unterschiedliche Datenfragmente enthält, müssen einige Ränge warten, bis die Daten verfügbar sind, wenn alle Karten mit demselben Kachelindex beginnen. Dies führt zu langen Leerlaufzeiten in der Ausführungsphase und mindert somit die Gesamteffizienz der Berechnung.
Die Kernidee von Swizzling ist:Der Startberechnungsoffset wird dynamisch basierend auf dem Speicherort der vorhandenen lokalen Daten auf jeder Karte angepasst.Im AllGather-Szenario kann beispielsweise jede Karte die Verarbeitung ihrer eigenen Daten priorisieren und gleichzeitig Daten von Remote-Kacheln abrufen. Dadurch wird eine parallele Planung von Kommunikation und Berechnung erreicht. Wenn alle Karten mit der Verarbeitung von Kachel 0 beginnen, kann nur Rang 0 sofort mit der Berechnung beginnen. Bei den übrigen Rängen kommt es aufgrund des Wartens auf Daten zu seriellen Verzögerungen.
In komplexeren Situationen, wie beispielsweise im maschinenübergreifenden ReduceScatter-Szenario, muss die Swizzling-Strategie in Kombination mit der Netzwerktopologie entwickelt werden. Am Beispiel zweier Knoten sieht eine sinnvolle Planungsmethode folgendermaßen aus: Die Berechnung der vom anderen Knoten benötigten Daten sollte Priorität haben, die maschinenübergreifende Punkt-zu-Punkt-Kommunikation sollte so früh wie möglich ausgelöst werden; während des Übertragungsvorgangs sollten die vom lokalen Knoten benötigten Daten parallel berechnet werden, um den Überlappungseffekt von Kommunikation und Berechnung zu maximieren.
Derzeit wird diese Art der Scheduling-Optimierung noch vom Programmierer gesteuert, um zu vermeiden, dass der Compiler bei der allgemeinen Optimierung wichtige Leistungspfade opfert. Wir sind uns auch bewusst, dass das Verständnis von Details wie Swizzling für Entwickler eine gewisse Hürde darstellt. Wir hoffen, in Zukunft mehr praktische Fälle und Codevorlagen bereitstellen zu können, um Entwicklern zu helfen, das Entwicklungsmodell für verteilte Operatoren schneller zu beherrschen und schrittweise ein offenes und effizientes Triton-Ökosystem für verteilte Programmierung aufzubauen.

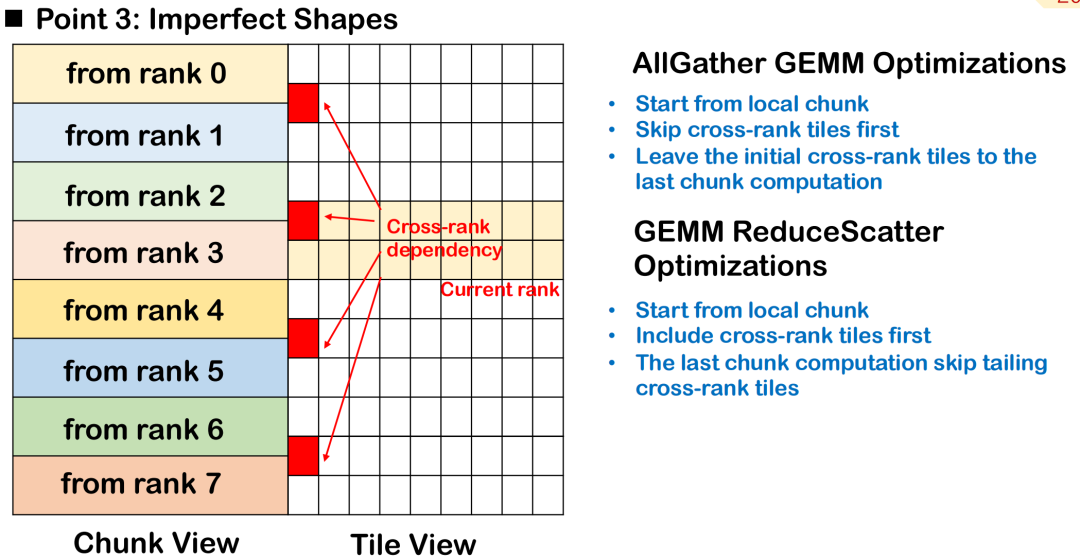
Unvollkommene Blockplanung: Verarbeitung von Prioritäten über Rangkacheln hinweg
In tatsächlichen Trainings- und Inferenzszenarien großer Modelle ist die Eingabeform des Operators häufig unregelmäßig, insbesondere wenn die Tokenlänge nicht festgelegt ist, und es ist schwierig, die Kachelblöcke sauber und einheitlich zu halten.Diese unvollständige Kachelung führt dazu, dass sich einige Kacheln über mehrere Ränge erstrecken, d. h., die Daten derselben Kachel werden auf mehrere Geräte verteilt, was die Komplexität der Planung und Synchronisierung erhöht.
Nehmen wir AllGather GEMM als Beispiel: Angenommen, ein Tile enthält sowohl lokale als auch Remote-Daten. Startet die Berechnung von diesem Tile, muss zunächst auf die Übertragung der Remote-Daten gewartet werden. Dies führt zu zusätzlichen Blasen und beeinträchtigt die Parallelität der Gesamtberechnung. Ein besserer Ansatz besteht darin, dieses Cross-Rank-Tile zu überspringen, der Verarbeitung vollständig lokal verfügbarer Daten Priorität einzuräumen und das Tile, das auf Remote-Eingaben wartet, als letztes auszuführen, um eine maximale Überlappung zwischen Kommunikation und Berechnung zu erreichen.
Im ReduceScatter-Szenario sollte die Planungsreihenfolge umgekehrt werden. Da die Berechnungsergebnisse der rangübergreifenden Kacheln so schnell wie möglich an das Remote-Ende gesendet werden müssen, besteht die beste Strategie darin, den von den Remote-Knoten benötigten Kacheln Priorität einzuräumen, um die maschinenübergreifende Datenübertragung so schnell wie möglich abzuschließen und die Remote-Abhängigkeit zu verringern.
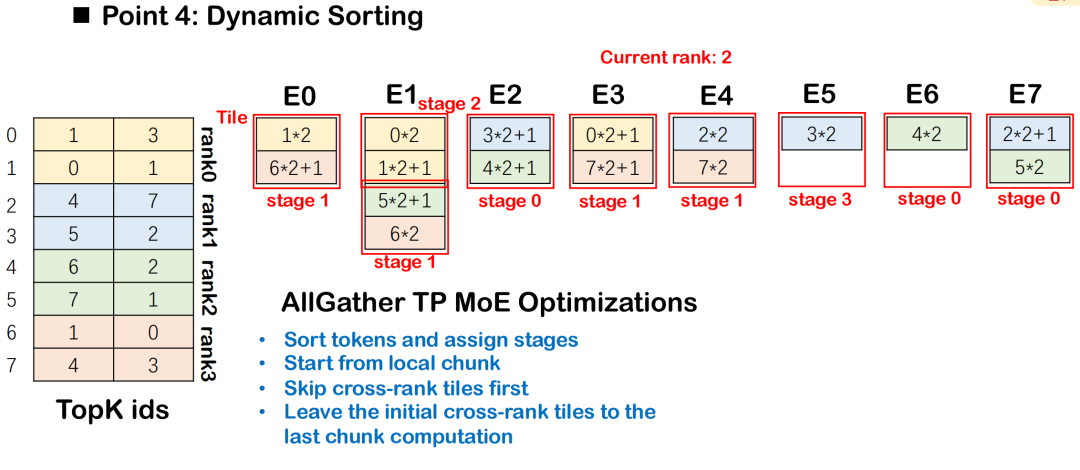
Dynamische Sortierstrategie unter MoE
Im MoE-Modell (Mixture-of-Experts) müssen Token basierend auf Routing-Ergebnissen an mehrere Experten verteilt werden, üblicherweise begleitet von All-to-All-Kommunikation und Group-GEMM-Berechnungen. Um die Effizienz der Kommunikation und des Computings zu verbessern, führt Triton-distributed die dynamische Sortierung ein. Dabei werden Computing-Aufgaben stufenweise entsprechend der Intensität ihrer Abhängigkeit von Kommunikationsdaten geplant, wobei Aufgaben mit geringerer Datenabhängigkeit Priorität erhalten.
Diese Reihenfolge stellt sicher, dass die Berechnung jeder Phase mit der geringstmöglichen Kommunikationsblockierung beginnen kann, wodurch eine bessere Überlappung zwischen All-to-All und Group GEMM erreicht wird.Die Gesamtplanung beginnt mit der Kachel mit den geringsten Datenabhängigkeiten und wird schrittweise auf die Kacheln mit komplexen Abhängigkeiten ausgeweitet, wodurch die Ausführungsparallelität maximiert wird.
Hardwarebasierte Kommunikationsbeschleunigung
Triton-Distributed unterstützt auch die Kommunikationsoptimierung in Kombination mit spezifischen Hardwarefunktionen.Insbesondere bei Verwendung der NVSwitch-Architektur ermöglicht der integrierte SHARP Accelerator die Durchführung von Kommunikationsberechnungen mit geringer Latenz. Dieses Modul kann Operationen wie Broadcast und AllReduce im Switch-Chip ausführen, um die Datenaggregation im Übertragungspfad zu beschleunigen und so Latenz und Bandbreitenverbrauch zu reduzieren. Die entsprechenden Anweisungen wurden in die Triton-Distribution integriert und können von Nutzern mit entsprechender Hardware direkt aufgerufen werden, um einen effizienteren Kommunikationskernel aufzubauen.
AOT-Kompilierungsoptimierung: Reduzierung des Inferenzlatenz-Overheads
Triton-Distributed führt den AOT-Mechanismus (Ahead-of-Time) ein, der speziell für extrem latenzempfindliche Anforderungen in Inferenzszenarien optimiert ist. Triton verwendet standardmäßig die JIT-Kompilierungsmethode (Just-In-Time-Kompilierung). Bei der ersten Ausführung der Funktion entsteht ein erheblicher Kompilierungs- und Cache-Overhead.
Der AOT-Mechanismus ermöglicht es Benutzern, Funktionen vor der Ausführung in Bytecode vorzukompilieren und sie während der Inferenzphase direkt zu laden und auszuführen. Dadurch wird der JIT-Kompilierungsprozess vermieden und die durch Kompilierung und Caching verursachte Verzögerung effektiv reduziert. Darauf aufbauend hat Triton-distributed den AOT-Mechanismus erweitert und unterstützt nun die AOT-Kompilierung und -Bereitstellung in verteilten Umgebungen, wodurch die Leistung der verteilten Inferenz weiter verbessert wird.
Leistungsmessung und Fallreproduktion
Wir haben einen umfassenden Test der Leistung von Triton-Distributed in Multiplattform- und Multitasking-Szenarien durchgeführt, der NVIDIA H800, AMD GPU, 8-Karten-GPU und maschinenübergreifende Cluster abdeckt, und gängige verteilte Implementierungslösungen wie PyTorch und Flux verglichen.
Auf 8 GPU-Karten,Die Triton-Verteilung erreicht im Vergleich zur PyTorch-Implementierung in AG GEMM- und GEMM RS-Aufgaben eine erhebliche Beschleunigung.Im Vergleich zur manuell optimierten Flux-Lösung wird dank verschiedener Optimierungen wie Swizzling-Planung, Kommunikations-Offload und AOT-Kompilierung eine bessere Leistung erzielt. Gleichzeitig wird im Vergleich zur Kombination aus PyTorch und RCCL auf der AMD-Plattform zwar eine etwas geringere Gesamtbeschleunigung erzielt, aber auch hier eine deutliche Optimierung erreicht. Die Haupteinschränkungen ergeben sich aus der schwachen Rechenleistung der Testhardware und der Nicht-Switch-Topologie.
In der AllReduce-AufgabeTriton-Distributed weist in den von uns getesteten Hardwarekonfigurationen für eine Reihe von Nachrichtengrößen von klein bis groß eine deutliche Geschwindigkeitssteigerung gegenüber NCCL auf, mit einer durchschnittlichen Beschleunigung von etwa dem 1,6-Fachen.Im Attention-Szenario haben wir hauptsächlich den Gather-KV-Typ der Attention-Operation getestet. Im Vergleich zur nativen Implementierung von PyTorch Touch konnte die Leistung der auf 8 GPU-Karten verteilten Triton-Implementierung um etwa das Fünffache verbessert werden. Sie ist auch besser als die Open-Source-Implementierung von Ring Attention, mit einer Verbesserung um etwa das Zweifache.
Maschinenübergreifendes Testen:AG GEMM ist 1,3-mal schneller und GEMM RS 1,4-mal schneller, was etwas weniger ist als Flux, aber mehr Vorteile in Bezug auf Formflexibilität und Skalierbarkeit bietet.Wir haben auch die Dekodierung einzelner Token in Hochgeschwindigkeits-Inferenzszenarien getestet. Die Latenz lag im Kontext von 1M-Token bei 20–30 Mikrosekunden. Die Lösung ist mit NVLink und PCIe kompatibel.
Darüber hinaus haben wir die verteilte Planungslogik in DeepEP reproduziert und dabei hauptsächlich die All-to-All-Routing- und Kontextverteilungsstrategien angepasst. In Szenarien mit weniger als 64 Karten ist die Leistung der Triton-Verteilung im Wesentlichen dieselbe wie die von DeepEP und in einigen Konfigurationen sogar leicht verbessert.
Schließlich bieten wir auch eine Prefill- und Decodierdemo basierend auf Qwen-32B an, die die Bereitstellung und den Betrieb auf 8 GPU-Karten unterstützt. Der tatsächliche Test zeigt, dass der Inferenzbeschleunigungseffekt um das 1,2-fache erreicht werden kann.
Aufbau eines offenen, verteilten Kompilierungs-Ökosystems
Wir stehen derzeit vor der Herausforderung, kundenspezifische Überlappungsszenarien zu lösen, für deren Lösung wir uns in der Vergangenheit hauptsächlich auf manuelle Optimierung verlassen haben, was arbeitsintensiv und kostspielig ist.Wir haben das verteilte Framework Triton vorgeschlagen und als Open Source bereitgestellt.Obwohl die Implementierung auf Triton basiert, kann sie unabhängig vom verwendeten Compiler oder der zugrunde liegenden Kommunikationsbibliothek des jeweiligen Unternehmens integriert werden, um ein offenes, verteiltes Ökosystem zu schaffen.
Dieses Feld ist in China und weltweit noch relativ unbebaut. Wir hoffen, die Stärke der Community zu nutzen, um mehr Entwickler für die Teilnahme zu gewinnen, sei es bei der Syntaxentwicklung, der Leistungsoptimierung oder der Unterstützung verschiedener Hardwaretypen, um gemeinsam den technologischen Fortschritt voranzutreiben. Wir haben bereits eine gute Leistung erzielt, und alle zugehörigen Beispiele sind Open Source. Wir laden Sie herzlich ein, aktiv Probleme zur Kommunikation anzusprechen, und freuen uns darauf, wenn sich uns weitere Partner anschließen, um eine bessere Zukunft zu gestalten!








