Command Palette
Search for a command to run...
Von Architektonischen Merkmalen Bis Hin Zum Aufbau Von Ökosystemen Analysiert Muxi Dong Zhaohua Eingehend Die Anwendungspraxis Von TVM Auf Inländischen GPUs

Am 5. Juli ging der 7. Meet AI Compiler Technology Salon von HyperAI erfolgreich zu Ende. Von der grundlegenden Innovation der GPU-Architektur bis zum Top-Level-Design der hardwareübergreifenden Kompilierungsökologie, von der Einzelchip-Operatoroptimierung bis zu Durchbrüchen in der verteilten Multi-Node-Kompilierung – Praktiker und Wissenschaftler aus dem Bereich der KI-Kompilierung trafen sich zu diesem Spitzentechnologie-Fest. Das Veranstaltungsgelände war dicht gedrängt, und die Kommunikationsatmosphäre war intensiv.
Folgen Sie dem öffentlichen WeChat-Konto „HyperAI Super Neuro“ und antworten Sie auf das Schlüsselwort „0705 AI Compiler“, um die PPT mit der Rede des autorisierten Dozenten zu erhalten.
Bei der Veranstaltung gab uns der Architekt Zhang Ning von AMD eine detaillierte Analyse der Geheimnisse der Leistungsoptimierung des Triton-Compilers auf der AMD-GPU-Plattform und verriet, wie man Python-Code dazu bringt, den Hochleistungs-GPU-Kernel einfach zu steuern. Direktor Dong Zhaohua von Muxi Integrated Circuit brachte praktische Erfahrung mit TVM-Anwendungen auf inländischen GPUs mit und zeigte die Funken der Kollision zwischen unabhängigen Chips und Open-Source-Kompilierungsframeworks. Forscher Zheng Size von ByteDance enthüllte das Geheimnis der Triton-Verteilung und teilte mit, wie Python die Leistungsgrenze der verteilten Kommunikation untergräbt. TileLang von Dr. Wang Lei von der Peking-Universität definiert die Effizienzgrenze der Operatorentwicklung neu.




In der Keynote-Rede „TVM-Anwendungspraxis auf Muxi GPU“,Dong Zhaohua, Senior Director von Muxi Integrated Circuit, stellte die technischen Merkmale seiner GPU-Produkte, TVM-Compiler-Anpassungslösungen, praktische Anwendungsfälle und die Vision einer ökologischen Konstruktion vor.Es demonstrierte die technologischen Durchbrüche und das Anwendungspotenzial inländischer GPUs in den Bereichen Hochleistungsrechnen und KI.
HyperAI hat die Rede von Professor Dong Zhaohua zusammengestellt und zusammengefasst, ohne die ursprüngliche Absicht zu verletzen. Im Folgenden finden Sie die Abschrift der Rede.
Muxi GPU Einführung
Muxi GPU umfasst derzeit mehrere Produktlinien wie die N-, C- und G-Serie und deckt damit ein breites Spektrum an Szenarien ab – von KI-Training und -Argumentation bis hin zu wissenschaftlichem Rechnen. Durch den Aufbau eines mehrstufigen Software-Stacks wird eine nahtlose Integration mit gängigen Frameworks erreicht. Als Kernmodul des Software-Stacks ist der Compiler verantwortlich für die Bereitstellung einer benutzerfreundlichen Programmieroberfläche, die Optimierung übergeordneter Anwendungen, die Generierung entsprechender Maschinencodes entsprechend unterschiedlicher Maschinenarchitekturen und deren Bereitstellung an die GPU zur Ausführung. Nach präzisen Anpassungen durch Ingenieure hat die Leistung international führendes Niveau erreicht und sich mit den gängigen Computing-Bibliotheken der Branche kompatibel gemacht.
Muxi GPU verfügt über eine umfangreiche Funktionsschnittstelle auf Befehlsebene.Unsere selbst entwickelte MACA-C-Schnittstelle basiert auf der Erweiterung der C-Sprache, integriert grammatikalische Elemente spezifischer Felder und ist funktional gleichwertig mit den zugrunde liegenden Programmierschnittstellen gängiger Hersteller, sodass Entwickler Migrationen und Anpassungen schnell durchführen können. Gleichzeitig bietet sie vielfältige Programmierschnittstellen wie Python, Triton und Fortran, unterstützt parallele Programmierstandards wie OpenACC und OpenCL und zeichnet sich durch eine hervorragende Effizienz bei der automatischen Parallelisierungscodegenerierung aus.
Auch,Muxi GPU verwendet die GPGPU-Architektur (General Purpose Graphics Processing Unit).Das LLVM-basierte Kompilierungssystem unterstützt die vollständige Prozessoptimierung von höheren Programmiersprachen bis hin zu maschinennahen Codes, berücksichtigt sowohl die Entwicklungseffizienz als auch die Hardwareleistung und bietet einen leistungsstarken Software-Stack.
TVM-Anpassung auf Muxi-GPU
Als Open-Source-Deep-Learning-Compiler kann TVM Deep-Learning-Modelle in Code umwandeln, der auf unterschiedlicher Hardware effizient ausgeführt werden kann. Das Muxi-Team entwickelte eine vollständige TVM-Anpassungslösung basierend auf den Eigenschaften der eigenen GPU, um eine vollständige Prozessoptimierung von der Modelldefinition bis zur Hardwareausführung zu erreichen.
Aus Sicht der Compilerarchitektur wurde vollständige Unterstützung erreicht.Und theoretisch kann es eine Verbindung zu vier Kernebenen herstellen.
Zur Anpassung der C++-Schnittstelle möchten wir diese in die MACA-Sprache konvertieren. Dieser Prozess ist recht komplex und die Implementierung einer toolbasierten automatischen Konvertierung bringt gewisse Herausforderungen mit sich.
Wenn die Codeabstraktion hoch ist, ist es einfacher, eine ebenenübergreifende Anpassung zu erreichen. Darüber hinaus müssen Sie beim Herstellen einer Verbindung mit LLVM auf Probleme mit der Versionskompatibilität achten. Da es viele LLVM-Versionen gibt, hängt die Anpassung einer bestimmten Version von der Unterstützung der entsprechenden Version ab, und Versionskonflikte können zu abnormalen Kompilierungsvorgängen führen.
In Bezug auf die GPU-Anpassung von Muxi Arch:
tvm.Target fügt MACA Target hinzu und fügt Unterstützung für jede Phase hinzu: Fügen Sie zuerst die Pipeline von MACA Target in Transform/Lower hinzu, um den allgemeinen GPU-Prozess wiederzuverwenden. Fügen Sie dann die Planungsregeln von MACA Target in der Tuning-Phase hinzu. Fügen Sie schließlich Unterstützung für CodeGenMACA hinzu und kompilieren Sie MACAC-Code.
Darüber hinaus wird tvm.Device um die Verwendung von MACA Device und MACA Runtime API erweitert, einschließlich Speicheroperationen auf MACA Device und Kernelstart zur Laufzeit.
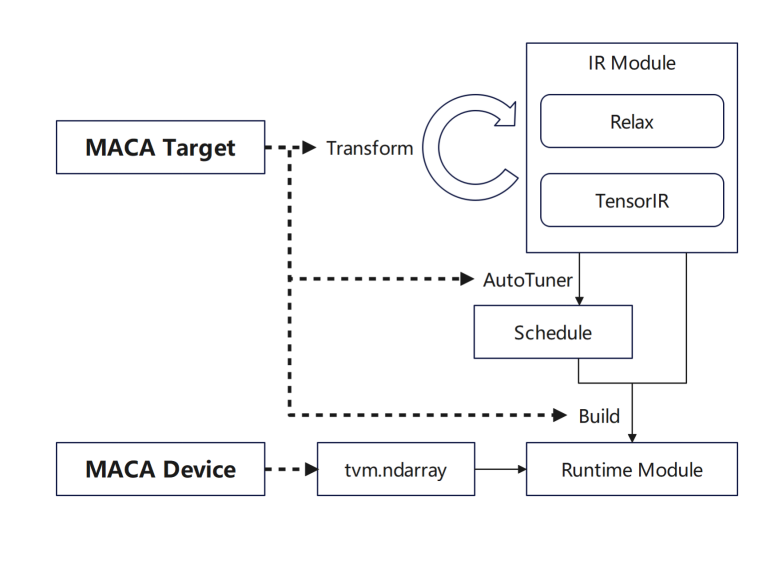
Viele unserer Produkte unterstützen mittlerweile Untergeräte auf TVM-Ebene, und das Backend führt Optimierungsaktionen für verschiedene Produkte basierend auf Untergeräten durch.Bei verschiedenen Produkten wählt der Compiler basierend auf den unterschiedlichen Gerätetypen automatisch die entsprechende Anpassungslösung aus.Gleichzeitig versuchen wir in Batch-Kompilierungsszenarien, feste Auswahlkonfigurationen für verschiedene Architekturen zu erstellen.Während der allgemeinen Kompilierungsphase passt der Compiler funktionsbezogene Kompilierungsregeln für verschiedene Architekturen basierend auf der spezifischen Konfiguration dynamisch an.
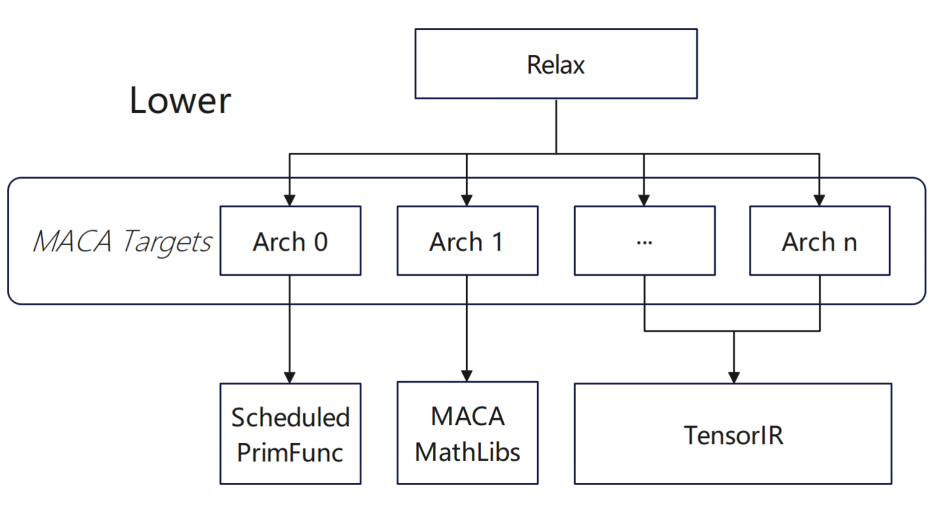
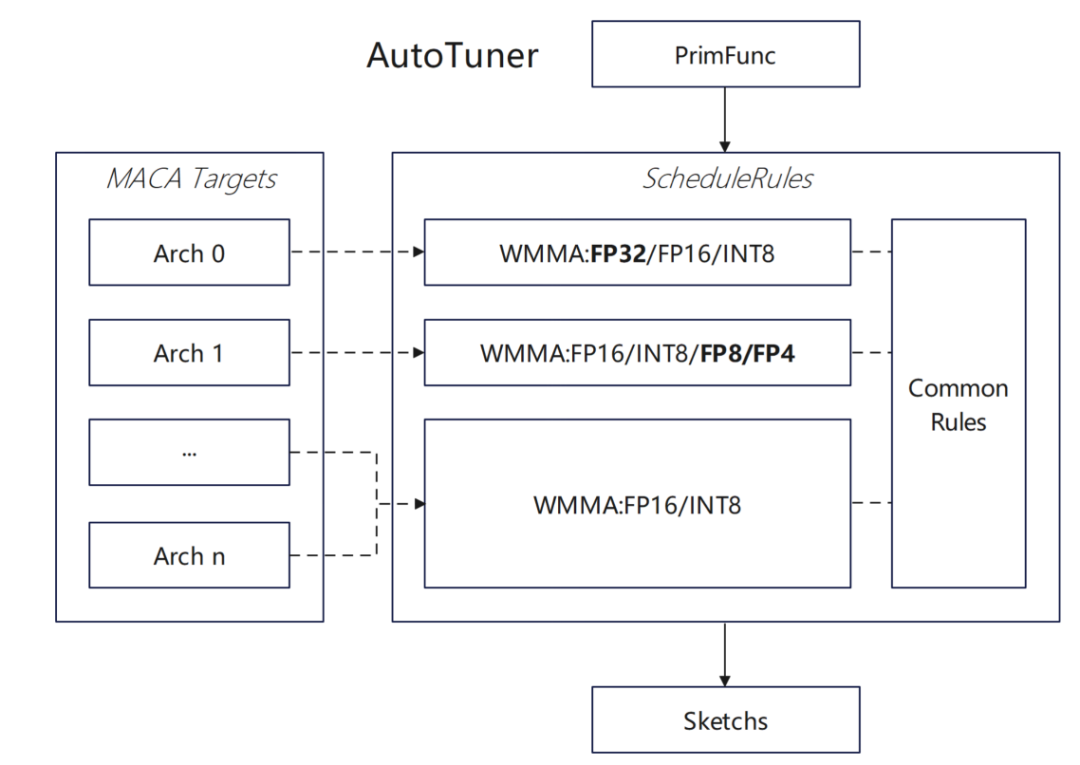
Im Hinblick auf die Bedieneranpassung haben wir eine Konfiguration auf höherer Ebene vorgenommen, die im Wesentlichen Folgendes umfasst:
* Fügen Sie im unteren Zeitplan den Zeitplan zu PrimFunc über das TIR-Planungsprimitiv hinzu
* Fügen Sie im Split Mixed Module Ziel- und andere Informationen hinzu, fügen Sie integriertes Maca ein und fügen Sie Synchronisierungsanweisungen für MACA hinzu
* Schließen Sie bei CodeGenMACA die Header-Dateien ein, von denen MACA abhängt, generieren Sie die Verwendung der Maca-WMMA-API aus tir.mma-bezogenen Anweisungen und deklarieren und verwenden Sie Variablen verschiedener Typen.
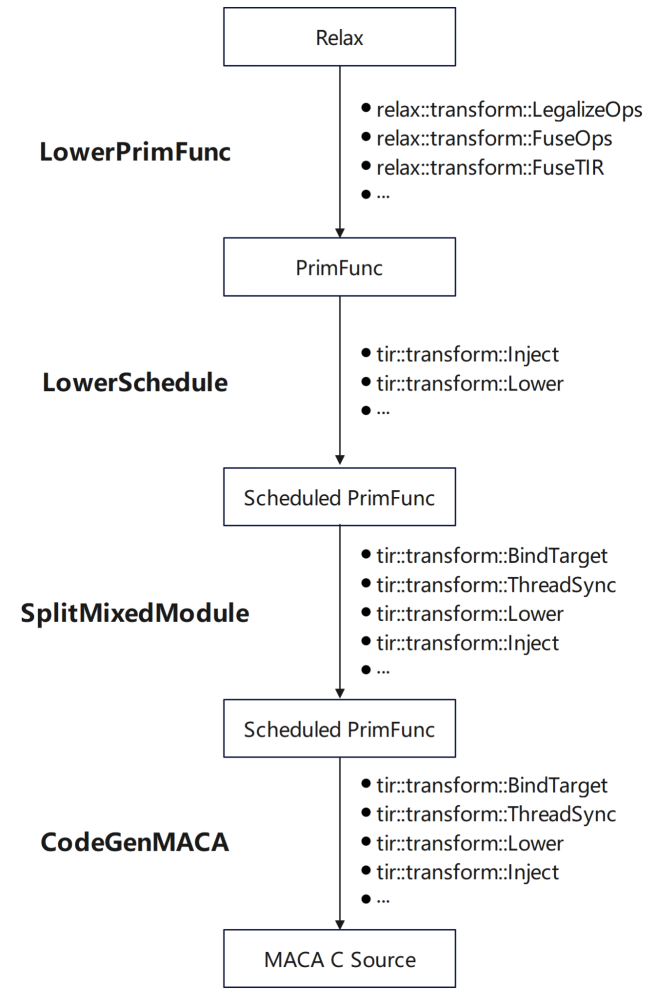
Um während des Anpassungsprozesses eine bessere Leistung zu erzielen, haben wir basierend auf seinen Eigenschaften eine spezielle Verarbeitung durchgeführt:
* Tensorisieren kann während der Optimierung nicht aktiviert werden: Die Parametergruppe des Operators conv2d ist nicht 1 und die Implementierung der MACA-Operatorbibliothek wird direkt in TOPI verwendet.
* Angepasste Operatoren nach dem Import des onnx-Modells: Der Multi Head AttentionV1-Operator ist in der MACA onnx-Laufzeitumgebung hochoptimiert. Der Aufruf des Operators ist in Contrib gekapselt, sodass TVM nach dem Import des onnx-Modells die manuell optimierte Implementierung des Hochleistungsoperators direkt verwenden kann.
Für uns,Benutzerdefinierte Optimierungsoperatoren von Anbietern werden eher in Python und MAC A implementiert:
* In der Python-Schnittstelle wird Relax.Function durch die Kombination grundlegender Operatoren definiert. tir.PrimFunc verwendet tir, um die Implementierung des Operators zu definieren und bei Bedarf Zeitpläne hinzuzufügen.
* In der MACA C-Schnittstelle kapselt tir.call_packed die Implementierung der Hochleistungsoperatorbibliothek und verwendet sie; tir.call_kernel verwendet den in MACA C implementierten Kernelcode und kompiliert ihn über den TVM-Stack in einen PackedFunc-Aufruf.
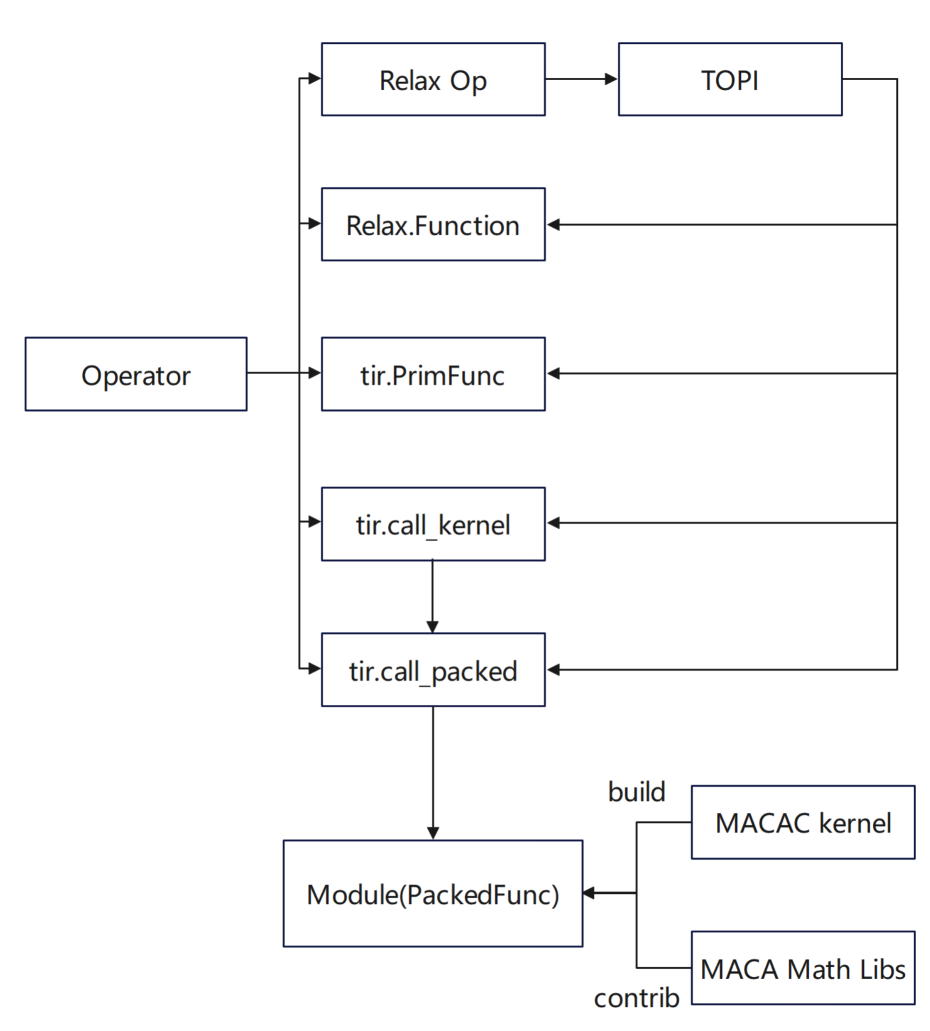
Um die Hardwareeigenschaften der Muxi-GPU voll auszunutzen,Das Team hat den TVM-Planungsalgorithmus umfassend optimiert:
* Unterstützung für WMMA-Float32-Typ für MACA-Ziel hinzugefügt:
Unterstützen Sie zunächst die WMMA-API vom Typ Float32 in MACA, fügen Sie in MACA ScheduleRules eine automatische Tensorisierungsregel vom Typ Float32 hinzu, damit TVM Hardware-WMMA automatisch identifizieren und verwenden kann, und fügen Sie im Dlight-Optimierungsframework eine entsprechende Tensorisierungsoptimierung von Float32 hinzu, um die Effizienz des Matrixbetriebs zu verbessern.
* Bewerten Sie die Auswirkungen des asynchronen Kopierens auf den Planungsalgorithmus:
Optimieren Sie mehrere WMMA-Berechnungen vom Laden einer Gruppe und Berechnen einer Gruppe bis zum asynchronen Laden der nächsten Datengruppe und synchronen Berechnen der aktuellen Datengruppe, verbessern Sie die Pipeline-Effizienz und aktivieren Sie die Software-Pipeline-Optimierungslogik in MACA ScheduleRules und fügen Sie asynchrone Kopierbefehlsinjektion und Codegenerierung für MACA-Ziel hinzu
Wir haben auch einige Versuche unternommen, neue Datentypen zu unterstützen:Aktivieren Sie die MACA-Zielanpassung im DataType-System. Unterstützen Sie die automatische Tensorisierungslogik des Typs Float8 in MACA ScheduleRules und erweitern Sie die TVM-Unterstützung für benutzerdefinierte Datentypen wie Float8. Implementieren Sie die Unterstützung für die Konvertierung des Float8-Typs und die Generierung von Operationscode in CodeGenMACA und ergänzen Sie zugehörige Operationsdefinitionen in maca_half_t.h.
TVM-Anwendung auf Muxi-GPU
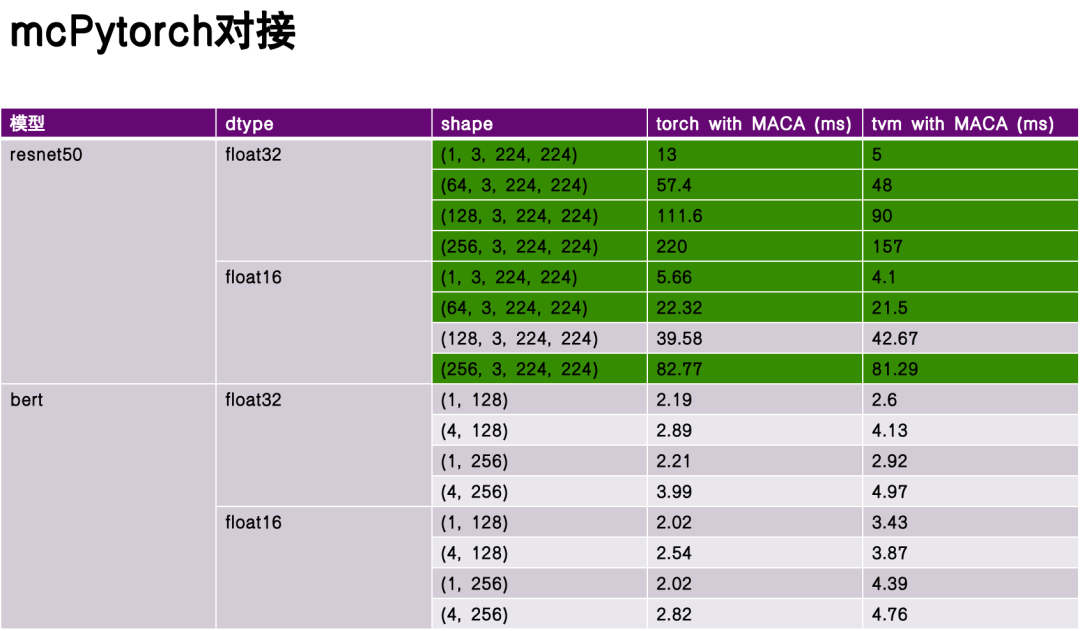
Im Hinblick auf das Framework-Design implementierte das Team zwei Zugriffsmethoden:Eine Möglichkeit besteht darin, das Torch-Modell direkt zu importieren und im Relay-Frontend auszuführen, und die andere besteht darin, torch.compile zu verwenden, um TVM als Backend zu verwenden.Es erreicht eine effiziente Verbindung zwischen dem Framework der oberen Ebene und der darunter liegenden Hardware.
In der Leistungsbewertungsphase habe ich ReseNet50 und Bert als Benchmark-Modelle ausgewählt und die Leistung der Kompilierung und Ausführung von Torch und TVM ohne tiefgreifende Optimierung verglichen.Experimentelle Daten zeigen, dass TVM in einigen Aspekten erhebliche Vorteile bietet und in manchen Szenarien eine bessere Leistung als Taschenlampen bietet.Dies liegt an der Flexibilität der TVM-Zwischendarstellung (IR) und ihrer gezielten Optimierung auf Hardwareeigenschaften.
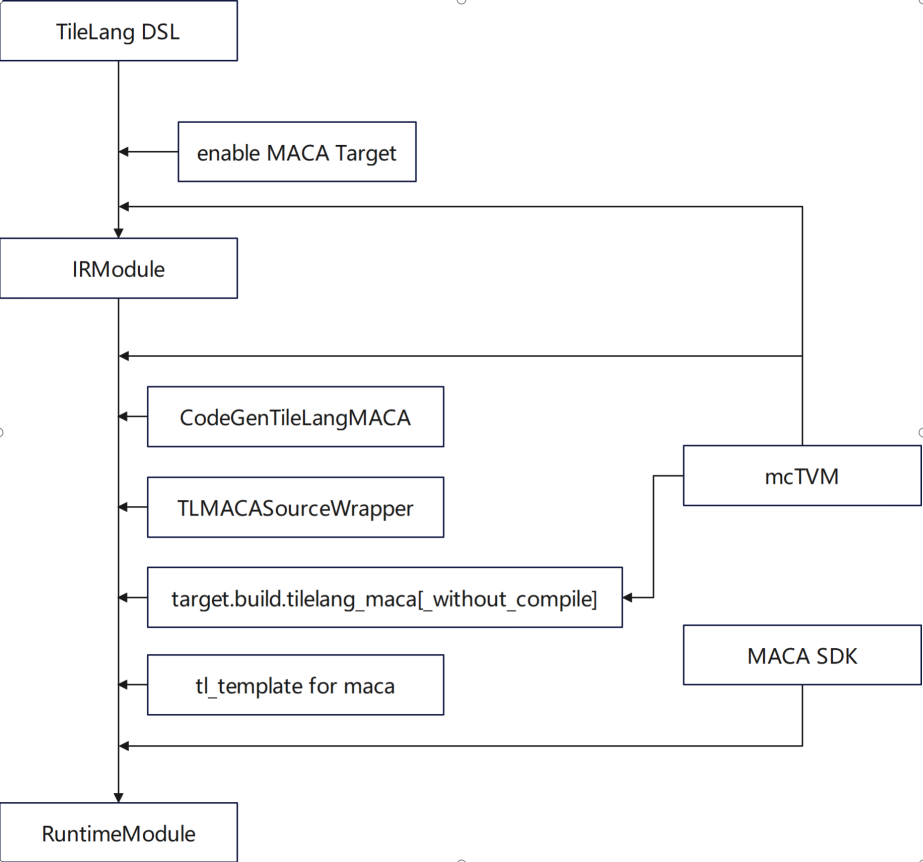
TileLang ist eine domänenspezifische Sprache (DSL) im TVM-Ökosystem, die sich auf die verfeinerte Optimierung des Tensor-Computing konzentriert.Unser Team hat in folgenden Aspekten eine umfassende Funktionsanpassung durchgeführt:* Unterstützt die Verwendung von MACA-Zielen * Fügen Sie CodeGenTileLangMACA hinzu, um MACA-C-Kernelcode zu generieren * Ersetzen und verwenden Sie mcTVM als Abhängigkeit * Fügen Sie die Verarbeitungslogik des MACA-Ziels in libgen, Adapter und Wrapper hinzu * Fügen Sie eine MACA-Zieldefinition mit gemm in tl_template hinzu
In Bezug auf die Optimierung dreht sich die Arbeit hauptsächlich um die Implementierung von Gemm in tl_template und die Implementierung von Algorithmen, die sich an die Eigenschaften der Muxi-GPU anpassen.
Im Hinblick auf die Interaktion zwischen Anbietern und der Community müssen Design und Entwicklung von TileLang drei Hauptprinzipien berücksichtigen:
In Bezug auf das SprachdesignAls erstes muss das Gleichgewicht zwischen Abstraktion und hoher Leistung gelöst werden.Insbesondere bei mehreren Recheneinheiten sollte der Compiler einen flexiblen Strategieauswahlmechanismus bieten. So können Entwickler mit tiefem Verständnis der zugrunde liegenden Hardwareeigenschaften spezifische Codegenerierungspfade festlegen und gleichzeitig normale Entwickler durch abstrakte Schnittstellen effizient programmieren, ohne sich um die zugrunde liegenden Details kümmern zu müssen. Dieses Gleichgewicht ist das Kernelement, auf das sich TileLang als DSL in der Entwurfsphase konzentrieren muss.
Zweitens,Dabei müssen die individuellen Konfigurationen des Anbieters und die Standardisierung der DSL berücksichtigt werden.Der Compiler sollte die Konfiguration mehrstufiger Optimierungsoptionen unterstützen, sodass fortgeschrittene Benutzer beispielsweise die zugrunde liegenden Kompilierstrategien wie den Schleifenentrollungsgrad und den vererbten Druck über Parameter anpassen können, um bessere Codegenerierungsergebnisse zu erzielen. Gleichzeitig muss der Compiler für unterschiedliche Hardwarearchitekturen gezielte Optimierungstipps und Annotationsmechanismen bereitstellen, um Entwickler bei der Auswahl des optimalen Kompilierpfads entsprechend den Hardwareeigenschaften zu unterstützen und die Entwicklungseffizienz zu verbessern.
dritte,Die Schnittstellenkontinuität zwischen Produktgenerationen muss gewährleistet sein.Während des Iterationsprozesses von Compilern und Sprach-Toolchains sollte die Abwärtskompatibilität des Schnittstellendesigns sichergestellt werden. Die Kompilierlogik und der generierte Code der aktuellen Version können auch in der nächsten Hardwaregeneration noch effektiv ausgeführt werden, um durch Architekturiterationen entstehende Kosten für die Coderekonstruktion zu vermeiden. Diese Kontinuität bildet die Grundlage für eine ökologische Konstruktion, die eine additive Akkumulation von Compiler-Toolchain-Funktionen anstelle von subtraktiven Verlusten durch Inkompatibilität ermöglicht. Gleichzeitig reduziert sie den Lern- und Migrationsaufwand des Benutzers und vermeidet Nutzungsunklarheiten.
Herausforderungen und Chancen
Abschließend möchte ich auf die Herausforderungen und Chancen eingehen, die sich aus der aktuellen Entwicklung der Branche ergeben.Die Herausforderungen spiegeln sich vor allem in folgenden Aspekten wider:
Der erste ist, dass sich Frameworks und anwendungsbasierte Algorithmen schnell ändern.Mit der rasanten Entwicklung in Bereichen wie Deep Learning werden die Aktualisierungszyklen von Frameworks und Algorithmen höherer Ebenen immer kürzer und die zunehmende Funktionalität und Leistungsfähigkeit führt zu einem erhöhten Druck auf die Compiler-Anpassung. Die Compiler-Community muss einen effizienten Anpassungsmechanismus etablieren, um schnell auf die Unterstützungsanforderungen neuer Operatoren und neuer Computermodelle reagieren zu können.
Zweitens entwickelt sich die Hardwarearchitektur ständig weiter.Derzeit unterstützt der Compiler die Funktionen einiger GPU-Architekturen. Sollten in Zukunft neue Hardwarearchitekturfunktionen hinzukommen, muss der Compiler auch heterogene Hardwarefunktionen berücksichtigen können.
Der dritte Grund ist, dass sich Programmierparadigmen ständig weiterentwickeln.Vom traditionellen C/C++ bis hin zu den aufkommenden funktionalen Programmier- und heterogenen Programmiermodellen ist die Definition der ökologischen Kette im Zusammenhang mit Python eine große Herausforderung.
Letztendlich ist es ein Gleichgewicht zwischen Genauigkeit, Leistung und Stromverbrauch.In praktischen Anwendungen müssen Compiler nicht nur auf die Codeleistung achten, sondern auch auf den ebenso wichtigen Stromverbrauch der Hardware. Diese Faktoren stehen im Zusammenhang mit der nachfolgenden Befehlsauswahl und dem Architekturdesign.
Zukunft,Wir möchten gemeinsam mit der Community Folgendes aufbauen:
Im Rahmen unserer Open-Source-Strategie planen wir, die Kernkomponenten des Frameworks und der Operatorbibliothek, einschließlich wichtiger Computermodule wie FlashMLA, zu öffnen. Durch das Open-Source-Modell fördern wir die iterative Optimierung der Compiler-Toolchain und erzielen einen ökologischen Skaleneffekt.
Zweitens hoffen wir, dass es in der Branche engere Kooperationsmöglichkeiten für Anwendungen, Frameworks, Operatorbibliotheken, Compiler und Hardwarearchitekturen geben wird. Durch regelmäßigen technischen Austausch (z. B. in Branchenforen) werden wir uns auf Kernthemen wie Schwierigkeiten bei der Kompilierungsoptimierung und Operatorplanungsstrategien konzentrieren, die domänenübergreifende Zusammenarbeit fördern und technologische Innovationen erkunden.
Muxi konzentriert sich auch auf die gemeinsame Entwicklung von Ökosystemen. Zu den Entwicklungsinitiativen gehören der Aufbau eines technischen Community-Forums für Entwickler-Feedback und Problemberichte zu Compiler-Toolchains, die Durchführung von Themenwettbewerben für Operatoren und Frameworks, die Bereitstellung von Benchmarks sowie die gemeinsame Entwicklung fachspezifischer Test-Suites und Benchmarks mit der Community.








