Command Palette
Search for a command to run...
Ein Sprung in Der Denkfähigkeit! GLM-4.1V-Thinking Fördert Die Entwicklung Kognitiver Intelligenz; 5 Millionen Schritt-für-Schritt-Denkdatenbeispiele! MathX-5M Eröffnet Eine Neue Dimension Des Mathematischen Denkens

Derzeit entwickeln sich multimodale Großmodelle von der „perzeptuellen Intelligenz“ zur „kognitiven Intelligenz“. Frühere Studien haben versucht, die Denkfähigkeit visueller Sprachmodelle zu verbessern, waren jedoch meist auf bestimmte Bereiche beschränkt. Obwohl entsprechende Forschungen laufen, fehlt noch immer ein universelles multimodales Denkmodell.
In diesem Zusammenhang haben Zhipu AI und die Tsinghua-Universität gemeinsam GLM-4.1V-Thinking vorgeschlagen, ein visuelles Sprachmodell (VLM), das ein allgemeines multimodales Verständnis und Denken fördern soll.Die Kerninnovation liegt in der Strategie „Reinforcement Learning with Curriculum Sampling (RLCS)“.Es erreicht nicht nur die stärkste Leistung des visuellen Sprachmodells auf der 10B-Parameterebene,In 18 der Listenaufgaben verfügt der Qwen-2.5-VL-72B über die gleichen oder sogar mehr als das 8-fache der Parameter.Darüber hinaus wird ein großer Fortschritt bei den dynamischen kognitiven Fähigkeiten multimodaler Modelle erzielt – eine Weiterentwicklung von der passiven „Bilderkennung“ zum aktiven „Denken“, wodurch die Schwachstellen des logischen Denkens gelöst werden und gleichzeitig die Vorteile einer leichtgewichtigen Bereitstellung erhalten bleiben.
Derzeit wurde auf der offiziellen HyperAI-Website das Tutorial „GLM-4.1V-Thinking: Vielseitiges multimodales Denken durch skalierbares bestärkendes Lernen“ veröffentlicht. Kommen Sie vorbei und probieren Sie es aus ~
GLM-4.1V-Denken: Vielseitiges multimodales Denken durch skalierbares bestärkendes Lernen
Online-Nutzung:https://go.hyper.ai/B3Vzs
Vom 7. bis 11. Juli gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Auswahl an hochwertigen Tutorials: 7
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im Juli: 4
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. VisDrone-Drohnenerkennungsdatensatz
VisDrone ist ein umfangreicher Benchmark-Datensatz zur visuellen Zielerkennung und -verfolgung durch Drohnen. Er wurde entwickelt, um Computer-Vision-Aufgaben wie Zielerkennung, Objektverfolgung und Bildsegmentierung zu entwickeln und zu bewerten. Der Datensatz enthält hochauflösende Bilder und Videos, die mit Drohnen in städtischen und vorstädtischen Umgebungen verschiedener Städte Chinas aufgenommen wurden und sechs Kategorien (wie Menschen, Fahrzeuge, Gebäude, Tiere usw.) abdecken.
Direkte Verwendung:https://go.hyper.ai/hQ5lh

2. MathX-5M-Datensatz für mathematisches Denken
MathX ist ein mathematischer Datensatz, der für die anweisungenbasierte Modelloptimierung und Feinabstimmung bestehender Modelle zur Verbesserung der Denkfähigkeiten entwickelt wurde. Dieser Datensatz ist das bisher größte und umfassendste öffentliche Datenkorpus für mathematisches Denken und umfasst 5 Millionen sorgfältig ausgewählte Beispiele für schrittweises Denken. Jedes Beispiel enthält eine Problemstellung, einen detaillierten Denkprozess und eine verifizierte korrekte Lösung.
Direkte Verwendung:https://go.hyper.ai/h0eLq
3. Fruchtklassifizierung Fruchtklassifizierung Bilddatensatz
Fruit Classification ist ein Bilddatensatz zur Obstklassifizierung, der zum Training von Machine-Learning- und Deep-Learning-Modellen zur Obsterkennung und -klassifizierung entwickelt wurde. Der Datensatz umfasst 101 Obstarten. Jede Kategorie enthält etwa 400 Bilder zum Training, 50 Bilder zur Validierung und 50 Bilder zum Testen.
Direkte Verwendung:https://go.hyper.ai/a8gfG

4. Bilddatensatz zu Hunderassen
„Dog Breeds Image“ ist ein Datensatz mit Bildern verschiedener Hunderassen, der zum Trainieren und Bewerten von Klassifizierungsmodellen für Hunderassen dient. Dieser Datensatz enthält Tausende (über 17.000) Bilder verschiedener Hunderassen, mehr als 100 Rassen (Terrier, Jagdhunde, Mastiffs, Spaniels, Bichon Frisé usw.), und dient der Entwicklung von Systemen zur Erkennung von Hunderassen.
Direkte Verwendung:https://go.hyper.ai/DoFA3

5. Pilzarten Datensatz zur Identifizierung von Pilzarten
„Mushroom“ ist ein Datensatz zur Pilzartenerkennung. Der Datensatz enthält Bilder von über 100 Pilzarten. Die Daten enthalten die physikalischen Merkmale jedes Pilzes, wie Farbe, Form, Geruch, Oberflächenbeschaffenheit usw., und geben an, ob jeder Pilz giftig oder essbar ist. Diese Bilder zeigen die Morphologie von Pilzen in verschiedenen Wachstumsstadien und unter verschiedenen Wachstumsbedingungen und eignen sich daher ideal für detaillierte Klassifizierungsaufgaben.
Direkte Verwendung:https://go.hyper.ai/ws0pi

6. Text-to-Image-2M Text-to-Image-Trainingsdatensatz
Text-to-Image-2M ist ein hochwertiger Text-Bild-Paar-Datensatz zur Feinabstimmung von Text-Bild-Modellen. Der Datensatz enthält etwa 2 Millionen Beispiele und ist in zwei Kernteilmengen unterteilt: data_512_2M (2 Millionen Bilder und Anmerkungen in der Auflösung 512 × 512) und data_1024_10K (10.000 hochauflösende Bilder und Anmerkungen in der Auflösung 1024 × 1024). Dadurch werden flexible Optionen für das Modelltraining mit unterschiedlichen Genauigkeitsanforderungen geboten.
Direkte Verwendung:https://go.hyper.ai/lTBaT
7. CIFAKE-Datensatz zur synthetischen Bilderkennung
CIFAKE ist ein synthetischer Datensatz zur Identifizierung KI-generierter Bilder. Es handelt sich um einen binären Klassifizierungsbilddatensatz mit wichtigem praktischem Anwendungswert zur Verbesserung der Robustheit der Bildverarbeitungstechnologie und der Erkennungsfähigkeit KI-generierter Inhalte, insbesondere in den Bereichen Nachrichtenverbreitung und Social-Media-Monitoring. Der Datensatz enthält 60.000 reale und 60.000 KI-generierte Bilder und dient der Bewertung der Fähigkeit von Computer-Vision-Modellen zur Identifizierung KI-generierter Bilder.
Direkte Verwendung:https://go.hyper.ai/wxeA3

8. II-Medical SFT Öffentlicher medizinischer Begründungsdatensatz
II-Medical SFT ist ein öffentlicher Datensatz für medizinisches Denken, der die überwachte Feinabstimmung großer Sprachmodelle (LLMs) für medizinische Denkaufgaben unterstützt. Der Datensatz enthält rund 2,2 Millionen Beispiele, deckt medizinische Szenarien mit mehreren Quellen ab und erfüllt die Feinabstimmungsanforderungen komplexer medizinischer Modelle. Er soll die Modelle bei der Entwicklung wichtiger Fähigkeiten wie Differentialdiagnose, evidenzbasierter Entscheidungsfindung, Patientenkommunikation und leitlinienbasierter Behandlungspläne unterstützen.
Direkte Verwendung:https://go.hyper.ai/TGMjl
9. Verkehrszeichenerkennung Verkehrszeichenerkennungsdatensatz
Traffic Sign Detection ist ein Datensatz zur Verkehrszeichenerkennung, der sich für die Verkehrszeichenerkennungsforschung im Bereich autonomes Fahren, Fahrerassistenzsysteme und Smart Cities eignet. Der Datensatz enthält rund 9.000 klar beschriftete Verkehrszeichenbilder und rund 4.969 Straßenansichten, die verschiedene Szenen in mehreren Ländern abdecken. Die Bilder umfassen mehrere Kategorien und sind in Trainings-, Validierungs- und Testsätze unterteilt, die präzise Bounding-Box-Annotationen liefern.
Direkte Verwendung:https://go.hyper.ai/VfwUw

10. UniMate Mechanical Metamaterials Benchmark Dataset
Der UniMate-Datensatz ist ein Benchmark-Datensatz für mechanische Metamaterialien und enthält 15.000 Proben. Jede Probe enthält eine dreidimensionale topologische Struktur, Dichteinformationen und die entsprechenden homogenisierten mechanischen Eigenschaften und deckt Szenarien mit geringer Dichte (ρ=0,1) bis mittlerer Dichte (ρ=0,5) ab. Die topologische Struktur erfüllt kubische Symmetrie und Periodizität.
Direkte Verwendung:https://go.hyper.ai/1ki2l
Ausgewählte öffentliche Tutorials
Diese Woche haben wir 3 Arten hochwertiger öffentlicher Tutorials zusammengefasst
*Tutorial zur Bereitstellung großer Modelle: 1
*KI für Wissenschafts-Tutorials: 2
*Multimodale Tutorials: 4
Tutorial zur Bereitstellung großer Modelle
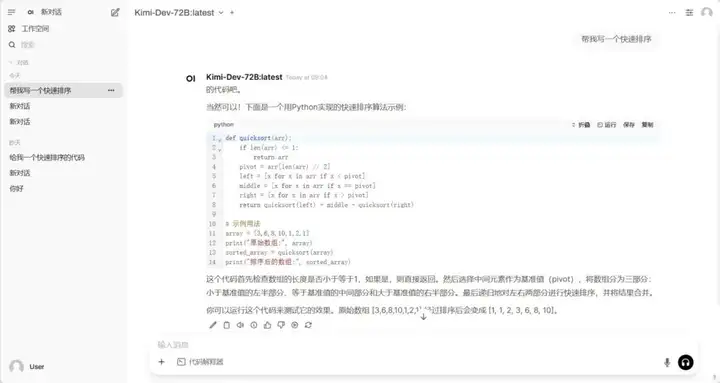
1. Ollama+Open WebUI stellt Kimi-Dev-72B-GGUF bereit
Kimi-Dev-72B ist ein Open-Source-Modell für große Sprachen, das für Softwareentwicklungsaufgaben entwickelt wurde. Es umfasst hauptsächlich Funktionen wie Codereparatur, Testcodegenerierung (TestWriter), automatisierten Entwicklungsprozess und Integration von Entwicklungstools.
Online ausführen:https://go.hyper.ai/t6ps1
Tutorial: KI für die Wissenschaft
1. Verwenden Sie State, um Zellstörungsreaktionen in verschiedenen Situationen vorherzusagen
Das State-Modell kann die Reaktion von Stammzellen, Krebszellen und Immunzellen auf Medikamente, Zytokine oder genetische Eingriffe vorhersagen. Experimentelle Ergebnisse zeigen, dass das Modell bei der Vorhersage von Transkriptomveränderungen nach Eingriffen deutlich besser abschneidet als gängige Methoden.
Online ausführen:https://go.hyper.ai/4AM6P
2. HealthGPT: KI-gestützter medizinischer Assistent
HealthGPT ist ein medizinisches großes visuelles Sprachmodell (Med-LVLM), das mithilfe heterogener Wissensanpassungstechnologie ein einheitliches Framework für medizinische Aufgaben zum visuellen Verständnis und zur Generierung implementiert. Es verwendet innovative heterogene Low-Rank-Adaption (H-LoRA)-Technologie, um das Wissen über Aufgaben zum visuellen Verständnis und zur Generierung in unabhängigen Plug-Ins zu speichern und so Konflikte zwischen Aufgaben zu vermeiden.
Online ausführen:https://go.hyper.ai/KiBWB
Multimodales Tutorial
1. GLM-4.1V-Denken: Vielseitiges multimodales Denken durch skalierbares bestärkendes Lernen
GLM-4.1V-Thinking ist ein visuelles Sprachmodell (VLM), das das allgemeine multimodale Verständnis und Denken fördern soll. Durch die Kombination von Reinforcement Learning mit Curriculum Sampling (RLCS) erreicht es eine umfassende Leistungssteigerung in verschiedenen Aufgabenbereichen, darunter MINT-Problemlösung, Videoverständnis, Inhaltserkennung, Programmierung, Koreferenzauflösung, GUI-basierte Agenten und das Verstehen langer Dokumente.
Online ausführen:https://go.hyper.ai/qPF8a
2. EX-4D: Freie Sicht aus monokularem Video generieren
EX-4D ist ein neues Framework zur 4D-Videogenerierung, das aus monokularem Videoeingang hochwertige 4D-Videos aus extremen Blickwinkeln generieren kann. Das Framework basiert auf einer einzigartigen Deep Waterproof Mesh (DW-Mesh)-Darstellung, die sichtbare und verdeckte Bereiche explizit modelliert, um die geometrische Konsistenz auch bei extremen Kamerapositionen zu gewährleisten. Das Framework nutzt eine simulierte Okklusionsmaskenstrategie zur Generierung effektiver Trainingsdaten auf Basis monokularer Videos und einen leichten LoRA-basierten Videodiffusionsadapter zur Synthese physikalisch konsistenter und zeitlich kohärenter Videos. EX-4D übertrifft bestehende Methoden aus extremen Blickwinkeln deutlich und bietet eine neue Lösung für die 4D-Videogenerierung.
Online ausführen:https://go.hyper.ai/WyAPN

3. MonSter: Das Potenzial monokularer Tiefen- und Stereosicht freisetzen
MonSter integriert monokulare Tiefen- und Stereoanpassung in eine zweigliedrige Architektur, um sich gegenseitig iterativ zu verbessern. Die iterative gegenseitige Verbesserung ermöglicht es MonSter, sich von groben Objektstrukturen zu pixelgenauer Geometrie zu entwickeln und so das Potenzial der Stereoanpassung voll auszuschöpfen.
Online ausführen:https://go.hyper.ai/a9Ekd
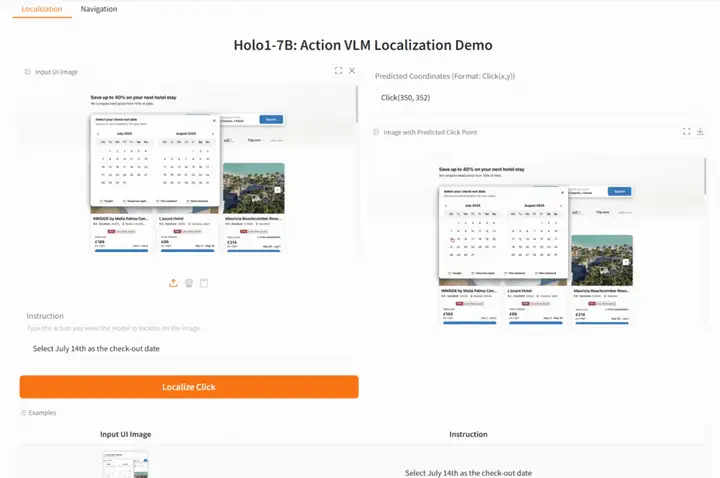
4. Holo1-7B: Natürlichsprachliche, präzise Positionierung von UI-Elementen
Holo1-7B ist ein Action Visual Language Model (VLM) für das Webagentensystem Surfer-H. Es ist für die Interaktion mit Weboberflächen wie ein menschlicher Benutzer konzipiert. Als Teil einer umfassenderen Agentenarchitektur kann Holo1 als Richtlinienmodell, Lokalisierungsmodell oder Verifizierungsmodell fungieren und Agenten dabei helfen, digitale Umgebungen zu verstehen und zu manipulieren.
Online ausführen:https://go.hyper.ai/6oQuF

Die Zeitungsempfehlung dieser Woche
1. MemOS: Ein Speicherbetriebssystem für KI-Systeme
Dieses Dokument stellt MemOS vor, ein Speicherbetriebssystem, das Speicher als verwaltbare Systemressource betrachtet. Es vereint Klartext, aktivierungsbasierte und parameterbasierte Speicherdarstellung, -planung und -entwicklung und ermöglicht so kostengünstige Speicherung und Abfrage. Als Basiseinheit kapselt MemCube Speicherinhalte und deren Metadaten, wie z. B. Herkunfts- und Versionsinformationen. MemCubes können kombiniert, migriert und im Laufe der Zeit fusioniert werden, was eine flexible Konvertierung zwischen verschiedenen Speichertypen und die Verknüpfung des Abrufs mit parameterbasiertem Lernen ermöglicht. MemOS etabliert ein speicherzentriertes Systemframework, das LLMs Steuerbarkeit, Plastizität und Evolvierbarkeit verleiht und so die Grundlage für deren kontinuierliches Lernen und personalisierte Modellierung legt.
Link zum Artikel:https://go.hyper.ai/PgtHH
2. SingLoRA: Low-Rank-Anpassung mithilfe einer einzelnen Matrix
Diese Arbeit schlägt die neue Methode SingLoRA vor, die die Low-Rank-Adaption neu definiert, indem Gewichtsaktualisierungen als Zerlegung einer einzelnen Low-Rank-Matrix und ihrer Transponierten dargestellt werden. Dieses einfache Design eliminiert automatisch den Skalenkonflikt zwischen Matrizen, gewährleistet die Stabilität des Optimierungsprozesses und reduziert die Parameteranzahl um etwa die Hälfte. Die Forscher analysierten SingLoRA im Rahmen von neuronalen Netzwerken mit unendlicher Breite und zeigten, dass sein Design die Stabilität des Merkmalslernens automatisch gewährleistet. Diese Vorteile wurden durch umfangreiche Experimente bestätigt.
Link zum Artikel:https://go.hyper.ai/kUu4u
3. Sollten wir Encoder weiterhin mit maskierter Sprachmodellierung vortrainieren?
Untersuchungen haben gezeigt, dass mit kausalen Sprachmodellen (CLMs) vortrainierte Decodermodelle effektiv für Encoderaufgaben wiederverwendet werden können. Der Grund für die Leistungssteigerung ist jedoch unklar. Diese Arbeit untersucht diese Frage anhand einer Reihe groß angelegter, sorgfältig kontrollierter Ablationsexperimente vor dem Training. Sie zeigt experimentell, dass eine zweistufige Trainingsstrategie – zuerst CLM und dann MLM – die beste Leistung bei einem festen Rechenressourcenbudget erzielen kann. Diese Strategie ist attraktiver, wenn sie mit vortrainierten CLM-Modellen aus dem bestehenden Ökosystem großer Sprachmodelle initialisiert wird.
Link zum Artikel:https://go.hyper.ai/eN7kf
4. Eine Untersuchung zum latenten Denken
Um die Erforschung des latenten Denkens zu fördern, bietet diese Arbeit einen umfassenden Überblick über das aufstrebende Forschungsgebiet des latenten Denkens. Durch die Untersuchung der grundlegenden Rolle neuronaler Netzwerkschichten als Rechenmatrix für das latente Denken, die Untersuchung verschiedener Methoden des latenten Denkens und die Diskussion fortgeschrittener Paradigmen (wie z. B. latentes Denken unbegrenzter Tiefe durch maskierte Diffusionsmodelle) soll der konzeptionelle Rahmen des latenten Denkens geklärt und zukünftige Forschungsrichtungen im Bereich der LLM-Kognition aufgezeigt werden.
Link zum Artikel:https://go.hyper.ai/kIuD8
5.Agent KB: Domänenübergreifende Erfahrung für die agentenbasierte Problemlösung nutzen
Dieses Papier stellt Agent KB vor, ein hierarchisches Erfahrungsframework, das die Lösung komplexer Agentenprobleme durch eine neuartige Reason-Retrieve-Refine-Pipeline ermöglicht. Unsere Ergebnisse zeigen, dass Agent KB eine modulare und frameworkunabhängige Infrastruktur bietet, die es Agenten ermöglicht, aus vergangenen Erfahrungen zu lernen und erfolgreiche Strategien auf neue Aufgaben zu übertragen.
Link zum Artikel:https://go.hyper.ai/2wJPd
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
Das Forschungsteam der Shanghai Jiao Tong University hat gemeinsam mit der Shanghai University of Sport und der Tsinghua University das weltweit erste intelligente VR-Sportinterventionssystem „Spirit Realm“ zur Gewichtskontrolle übergewichtiger oder adipöser Jugendlicher entwickelt. Es nutzt einen virtuellen Trainer-Zwillingsagent, der durch Deep Reinforcement Learning gesteuert wird und auf der Transformer-Architektur basiert, um eine sichere und immersive Sportanleitung zu bieten. Seine biomechanische Leistung und die Reaktion der Herzfrequenz beim Training unterscheiden sich nicht wesentlich von denen vergleichbarer Sportarten in der realen Welt.
Den vollständigen Bericht ansehen:https://go.hyper.ai/Q3KKv
Kürzlich wurde aufgedeckt, dass Forschungsarbeiten von 14 Universitäten weltweit versteckte Anweisungen enthielten, die KI-Gutachter zu positiven Bewertungen anleiteten. Dieser Bericht löste hitzige Diskussionen in der akademischen Gemeinschaft aus und lenkte die Aufmerksamkeit auf die Risiken und ethischen Herausforderungen des Einsatzes von KI-Gutachtern. Auch Xie Sainings Team wurde vorgeworfen, positive Kommentare in seiner Arbeit zu verbergen. Daraufhin veröffentlichte er einen langen Artikel, in dem er die Entwicklung der wissenschaftlichen Forschungsethik im KI-Zeitalter beleuchtete.
Den vollständigen Bericht ansehen:https://go.hyper.ai/LZ0TJ
Die National University of Singapore und die Zhejiang University haben gemeinsam eine innovative NeuralCohort-Methode entwickelt, die einen neuen Weg für das Lernen von EHR-Repräsentationen eröffnet und das Potenzial von EHR-Daten voll ausschöpft. Sie nutzt gleichzeitig lokale Intra-Kohorten- und globale Inter-Kohorten-Informationen – Schlüsselelemente, die in früheren Studien zur Analyse elektronischer Patientenakten nicht vollständig berücksichtigt wurden.
Den vollständigen Bericht ansehen:https://go.hyper.ai/1b8lG
Der 7. 2025 Meet AI Compiler Technology Salon ging am 5. Juli in Beijing Zhongguancun erfolgreich zu Ende. Zhang Ning, KI-Architekt von AMD, hielt einen Vortrag mit dem Titel „Unterstützung der Open-Source-Community, Analyse des AMD Triton Compilers“. Er konzentrierte sich auf die technischen Beiträge des Unternehmens zur Open-Source-Community und erläuterte systematisch die Kerntechnologie, die zugrunde liegende Architekturunterstützung und die ökologischen Konstruktionserfolge des AMD Triton Compilers. Entwicklern bot er so eine umfassende Perspektive für ein tiefgreifendes Verständnis der Hochleistungs-GPU-Programmierung und Compileroptimierung. Dieser Artikel fasst die wichtigsten Punkte aus Zhang Nings Vortrag zusammen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/jJLD8
In einer von sozialen Medien und visuellen Inhalten geprägten Ära hat sich die Bildbearbeitung von einer reinen Designfähigkeit zu einem alltäglichen Bedürfnis entwickelt. Der Wunsch der Nutzer nach komfortablen und effizienten Tools ist ungebrochen, und mit dem rasanten technologischen Fortschritt wird die Bildbearbeitung in einem Satz immer mehr Realität. Das kürzlich als Open Source veröffentlichte FLUX.1-Kontext-dev erreicht eine hohe Leistung, die mit einer Reihe von Closed-Source-Modellen wie GPT-image-1 mit nur 12 Milliarden Parametern vergleichbar ist.
Den vollständigen Bericht ansehen:https://go.hyper.ai/EJIIa
Beliebte Enzyklopädieartikel
1. DALL-E
2. Reziproke Sortierfusion RRF
3. Pareto-Front
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kontrastives Lernen
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:

Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








