Command Palette
Search for a command to run...
AMD AI-Architekt Zhang Ning: Analyse Des AMD Triton Compilers Aus Mehreren Perspektiven, Um Beim Aufbau Eines Open-Source-Ökosystems Zu Helfen

Am 5. Juli fand der 7. Meet AI Compiler Technology Salon von HyperAI wie geplant statt. Trotz der sengenden Hitze des Hochsommers war die Begeisterung des Publikums ungebrochen. Der Veranstaltungsort war voll, und viele standen sogar auf, um den einzelnen Diskussionsrunden zuzuhören. Zahlreiche Dozenten von AMD, Muxi Integrated Circuits, ByteDance und der Peking-Universität betraten abwechselnd die Bühne und präsentierten tiefgreifende Brancheneinblicke und Trendanalysen – von der grundlegenden Kompilierung bis zur tatsächlichen Implementierung – voller praktischer Informationen!
Folgen Sie dem öffentlichen WeChat-Konto „HyperAI Super Neuro“ und antworten Sie auf das Schlüsselwort „0705 AI Compiler“, um die PPT mit der Rede des autorisierten Dozenten zu erhalten.




Als Programmiersprache zur Vereinfachung der Entwicklung leistungsstarker GPU-Kernel hat sich Triton durch die Vereinfachung komplexer paralleler Computerprogrammierung zu einem wichtigen Werkzeug im LLM-Reasoning- und Trainings-Framework entwickelt. Ihr Hauptvorteil liegt in der Balance zwischen Entwicklungseffizienz und Hardwareleistung. Sie vermeidet die Offenlegung zugrunde liegender Hardwaredetails und kann durch Compileroptimierung GPU-Rechenleistung freisetzen. Diese Funktion hat Triton in der Open-Source-Community schnell populär gemacht.
Als führendes Unternehmen im GPU-Bereich unterstützt AMD die Triton-Sprache und stellt der Open-Source-Community relevanten Code zur Verfügung, um die herstellerübergreifende Kompatibilität des Triton-Ökosystems zu fördern. Dieser Schritt stärkt nicht nur AMDs technischen Einfluss im Bereich des Hochleistungsrechnens, sondern bietet Entwicklern weltweit durch ein Open-Source-Kollaborationsmodell flexiblere GPU-Programmieroptionen, insbesondere in umfangreichen Modelltrainings- und -schlussfolgerungsszenarien, und eröffnet so neue Wege zur Optimierung der Rechenleistung.
In einer Rede mit dem Titel „Unterstützung der Open-Source-Community, Analyse des AMD Triton-Compilers“ interpretierte Zhang Ning, ein KI-Architekt von AMD, systematisch die Kerntechnologie, die zugrunde liegende Architekturunterstützung und die ökologischen Konstruktionserfolge des AMD Triton-Compilers und konzentrierte sich dabei auf die technischen Beiträge des Unternehmens zur Open-Source-Community.Es bietet Entwicklern eine umfassende Perspektive für ein tiefgreifendes Verständnis der Hochleistungs-GPU-Programmierung und Compileroptimierung.
HyperAI hat die Rede von Professor Zhang Ning zusammengestellt und zusammengefasst, ohne die ursprüngliche Absicht zu verletzen. Im Folgenden finden Sie die Abschrift der Rede.
Triton: effiziente Programmierung, Echtzeitkompilierung, flexible Iteration
Triton wurde von OpenAI vorgeschlagen und ist eine Open-Source-Programmiersprache und ein Open-Source-Compiler, der die Entwicklung leistungsstarker GPU-Kernel vereinfachen soll.Es wird häufig in gängigen LLM-Trainingsrahmen verwendet. Zu den Kernfunktionen gehören:
* Effiziente Programmierung kann die Kernel-Entwicklung vereinfachen und es Entwicklern ermöglichen, effizient GPU-Code zu schreiben, ohne die komplexe zugrunde liegende GPU-Architektur gründlich verstehen zu müssen;
* Echtzeitkompilierung, die Just-in-Time-Kompilierung unterstützt, kann GPU-Code dynamisch generieren und optimieren, um ihn an unterschiedliche Hardware- und Aufgabenanforderungen anzupassen;
* Eine flexible Iterationsraumstruktur, die auf einem Blockprogramm und einem Skalar-Thread basiert, verbessert die Flexibilität des Iterationsraums, erleichtert die Handhabung spärlicher Operationen und optimiert die Datenlokalität.
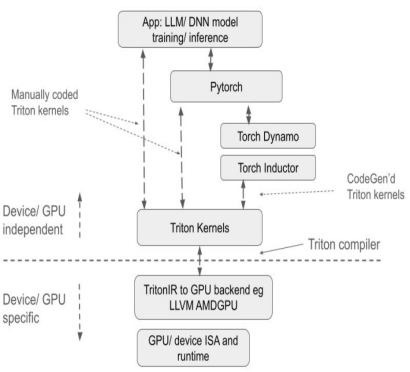
Im Vergleich zu herkömmlichen Lösungen bietet Triton erhebliche Vorteile:
Erste,Als Open-Source-Projekt bietet Triton eine Python-basierte Programmierumgebung. Benutzer können den GPU-Kernel implementieren, indem sie Python-Triton-Code entwickeln, ohne sich um die Details der zugrunde liegenden GPU-Architektur kümmern zu müssen. Dies reduziert den Entwicklungsaufwand erheblich und verbessert die Produktentwicklungseffizienz im Vergleich zu anderen GPU-Programmiermethoden wie AMD HIP deutlich. Der Compiler nutzt verschiedene Optimierungsstrategien basierend auf den Merkmalen der GPU-Architektur, um Python-Code in optimierten GPU-Assemblercode umzuwandeln, Tensoroperationen höherer Ebene automatisch in zugrunde liegende GPU-Anweisungen zu kompilieren und einen effizienten Codebetrieb auf der GPU sicherzustellen.
Zweitens,Triton bietet eine gute Hardware-Kompatibilität. Derselbe Code kann theoretisch auf unterschiedlicher Hardware ausgeführt werden, darunter NVIDIA- und AMD-GPUs sowie inländische GPUs, die Triton unterstützen. In Bezug auf Leistung und Flexibilität bietet es eine bessere Performance und Optimierungsflexibilität als Plattformen wie PyTorch und kann im Vergleich zu CUDA die zugrunde liegenden GPU-Operationsdetails verbergen, sodass sich Entwickler stärker auf die Algorithmusimplementierung konzentrieren können.
Im Vergleich zur PyTorch-API konzentriert es sich stärker auf die spezifische Implementierung von Rechenoperationen und ermöglicht Entwicklern die flexible Definition von Thread-Blocksegmentierungsmethoden, das Lesen und Schreiben von Daten auf Block-/Kachelebene sowie die Ausführung hardwarebezogener Rechenprimitive. Es eignet sich besonders für die Entwicklung von Strategien zur Leistungsoptimierung wie Operatorfusion und Parameteroptimierung.
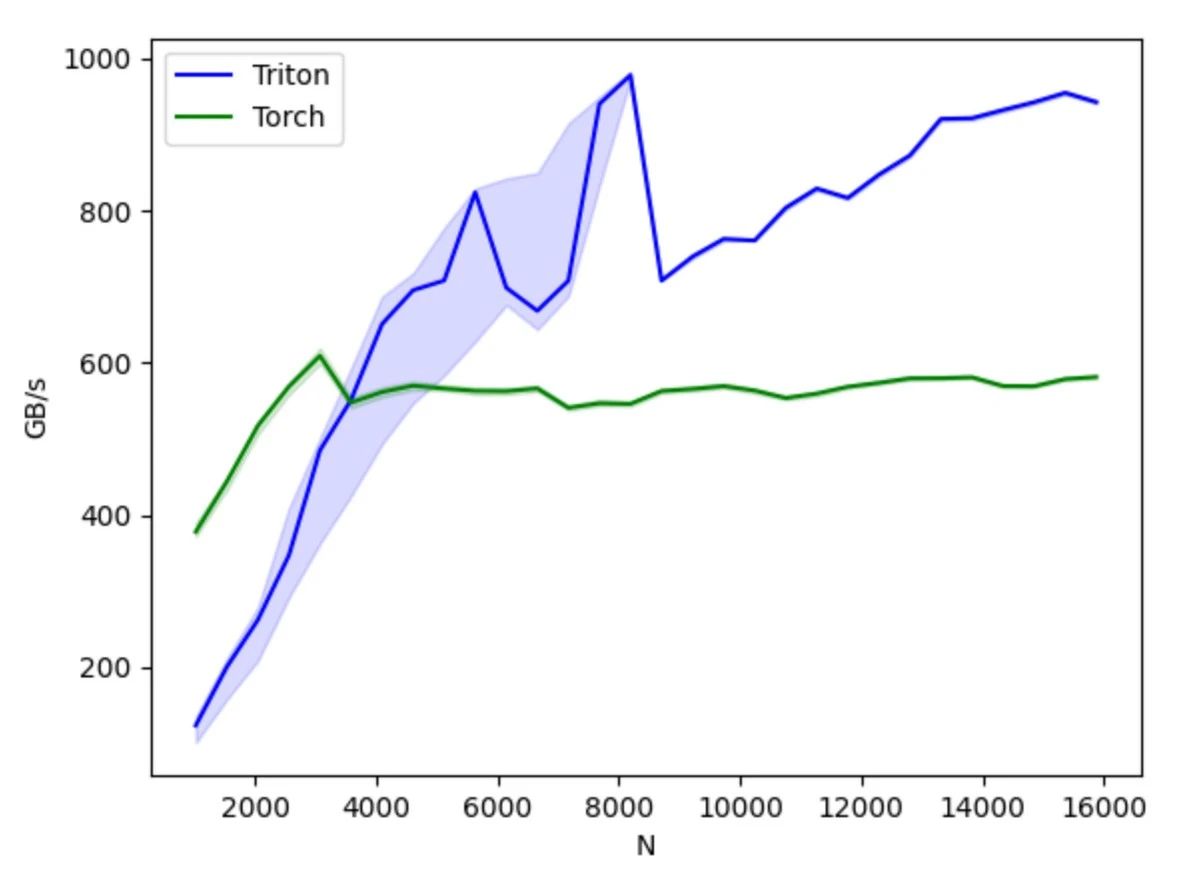
Im Vergleich zu CUDA verbirgt Triton die Steuerung der Thread-Ebene und überlässt stattdessen dem Compiler die automatische Übernahme von Details wie gemeinsam genutztem Speicher, Thread-Parallelität, zusammengeführtem Speicherzugriff und Tensor-Layout. Dies reduziert den Schwierigkeitsgrad des parallelen Programmiermodells und verbessert gleichzeitig die Effizienz der GPU-Code-Entwicklung. So wird ein effektives Gleichgewicht zwischen Entwicklungseffizienz und Programmleistung erreicht. Entwickler können sich auf den Entwurf und die Implementierung des Algorithmus konzentrieren, ohne sich zu viele Gedanken über die zugrunde liegenden Hardwaredetails und Programmieroptimierungstechniken machen zu müssen. Sofern sie einfache Prinzipien der parallelen Programmierung verstehen, können sie schnell GPU-Code mit besserer Leistung entwickeln.
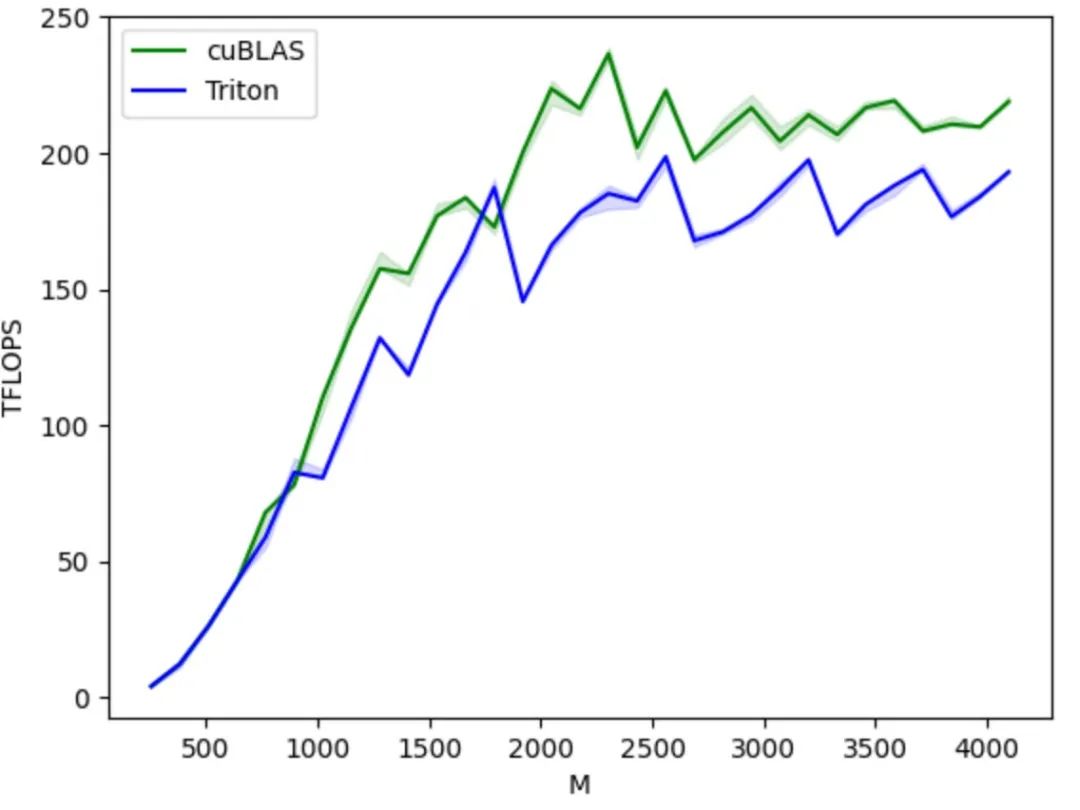
Aus ökologischer Sicht basiert es auf der Python-Sprachumgebung und verwendet den von PyTorch definierten Tensor-Datentyp. Seine Funktionen können nahtlos in das PyTorch-Ökosystem integriert werden. Im Vergleich zum geschlossenen CUDA erleichtern der Open-Source-Code und das offene Ökosystem von Triton den Herstellern von KI-Chips zudem die Portierung auf ihre eigenen Chips und die Nutzung der Open-Source-Community zur Verbesserung ihrer Toolchain, was wiederum die gesunde Entwicklung des Triton-Ökosystems fördert.
AMD Triton Compiler-Prozess
Der Triton-Compiler besteht aus drei Hauptmodulen: dem Front-End-Modul, dem Optimierungsmodul und dem Back-End-Modul zur Maschinencodegenerierung, wie in der folgenden Abbildung dargestellt:
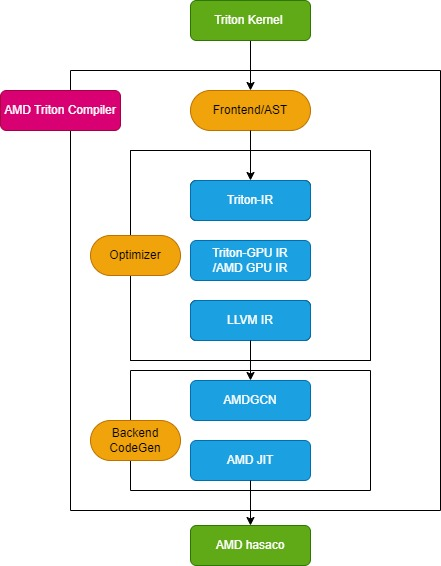
Frontend-Modul
Das Frontend-Modul durchläuft den abstrakten Syntaxbaum (AST) der Python-Triton-Kernelfunktion, um die Triton-Zwischendarstellung (Triton-IR) zu erstellen, und seine Kernelfunktion wird in Triton-IR konvertiert.Beispielsweise wird die mit dem Dekorator @triton.jit gekennzeichnete Kernelfunktion add_kernel in diesem Modul in die entsprechende IR konvertiert. Die JIT-Dekorator-Eintragsfunktion prüft zunächst den Wert der Umgebungsvariable TRITON_INTERPRET. Ist die Variable True, wird InterpretedFunction aufgerufen, um den Triton-Kernel im interpretierten Modus auszuführen; ist sie False, wird JITFunction ausgeführt, um den Triton-Kernel auf dem tatsächlichen Gerät zu kompilieren und auszuführen.
Der Einstiegspunkt für die Kernelkompilierung ist die Triton-Kompilierungsfunktion, die mit den Informationen zum Zielgerät und den Kompilierungsoptionen aufgerufen wird. Dieser Prozess erstellt den Kernel-Cache-Manager, startet die Kompilierungspipeline und füllt die Kernel-Metadaten. Darüber hinaus lädt er Backend-spezifische Dialekte wie TritonAMDGPUDialect für AMD-Plattformen und Backend-spezifische LLVM-Module, die die LLVM-IR-Kompilierung übernehmen. Wenn alle Vorbereitungen abgeschlossen sind, wird die Funktion ast_to_ttir aufgerufen, um die Triton-IR-Datei für den Kernel zu generieren.
Optimierermodul
Das Optimierungsmodul ist in drei Kernteile unterteilt: Triton-IR-Optimierung, Triton-GPU-IR-Optimierung und LLVM-IR-Optimierung.
* Triton-IR-Optimierung
Auf AMD-Plattformen wird die Triton-IR-Optimierungspipeline durch die Funktion make_ttir definiert. In dieser Phase sind die Optimierungen hardwareunabhängig und umfassen Inlining, Eliminierung gemeinsamer Teilausdrücke, Normalisierung, Eliminierung von totem Code, schleifeninvariante Codebewegung und Schleifenentrollung.
* Triton-GPU IR-Optimierung
Auf der AMD-Plattform wird der Triton-IR-Optimierungsprozess durch die Funktion make_ttgir definiert, um die GPU-Leistung zu verbessern. Basierend auf den Eigenschaften von AMD-GPUs und unserer Optimierungserfahrung haben wir außerdem einen spezifischen Optimierungsprozess entwickelt, wie in der folgenden Abbildung dargestellt:
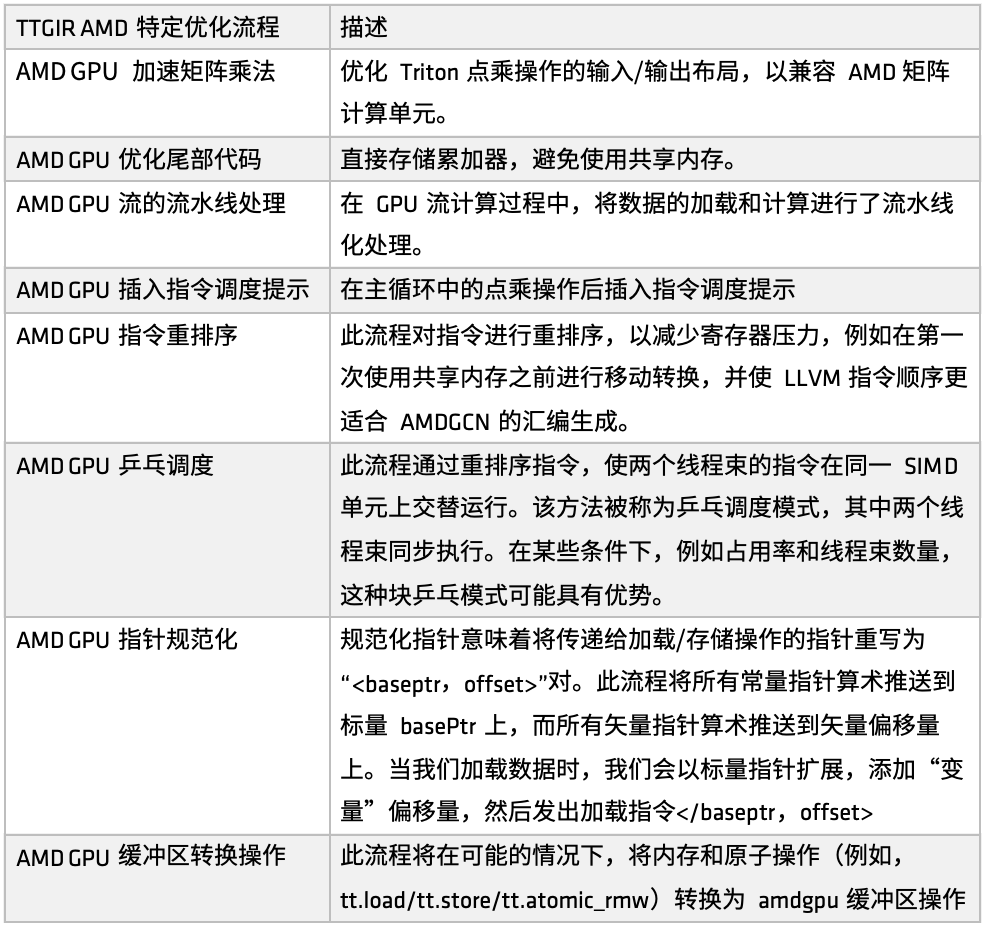
Erstens: beschleunigte Matrixmultiplikation für AMD-GPUs,Die Optimierung konzentriert sich auf das Ein-/Ausgabe-Layout der Punktmultiplikation in Triton, um die Kompatibilität mit AMDs Matrix-Rechnereinheiten (wie Matrix) zu verbessern. Diese Optimierung erfordert umfangreiche Anpassungsprozesse für die CDNA-Architektur, die einen relativ großen Teil der gesamten Implementierung ausmachen. Wenn Sie den von Triton generierten Code auf der AMD-Plattform gründlich optimieren möchten, lohnt es sich, sich auf diesen Teil der Implementierung zu konzentrieren.
Zweitens, in der Schwanzverarbeitungsphase,Die Optimierungsstrategie besteht darin, den Akkumulator direkt zu speichern, wodurch die Verwendung des gemeinsam genutzten Speichers vermieden, der Zugriffsdruck des gemeinsam genutzten Speichers verringert und die Gesamteffizienz verbessert wird.
Als nächstes wurde im GPU-Stream-Computing-Prozess die Pipeline-Verarbeitung des Ladens und Berechnens eingeführt.Das heißt, während die vorherige Aufgabe ausgeführt wird, wird der entsprechende Speicher zum Laden von Daten aufgerufen, wodurch ein Modus für die parallele Ausführung von Laden und Berechnen entsteht. Dieser Mechanismus hat in vielen Anwendungsszenarien gute Ergebnisse erzielt. Basierend auf der Pipeline-Optimierung werden zudem Hinweise zur Befehlsplanung eingeführt, um den Befehlsfluss nach Abschluss der Recheneinheit oder des Remote-Vorgangs zu steuern und so die Reaktionseffizienz auf Befehlsebene zu verbessern.
Anschließend implementierte AMD mehrere Sätze zur Neuanordnung von Anweisungen für unterschiedliche Zwecke.Einschließlich: Entlastung des Registerdrucks, Vermeidung redundanter Ressourcenzuweisung und -freigabe, Optimierung der Verbindung zwischen Lade- und Berechnungsprozess usw. Ein Teil der Neuanordnung ist eng in den Pipeline-Mechanismus integriert, und der andere Teil konzentriert sich auf die Anpassung der Befehlsreihenfolge von LLVM IR, um den Generierungsregeln der AMDGCN-Assemblierung besser zu entsprechen.
Zusätzlich zu den Hinweisen zur Neuanordnung und Planung von Anweisungen,Wir haben außerdem eine weitere Strategie zur Planungsoptimierung eingeführt: die Ping-Pong-Planung.Durch den Mechanismus der zirkulären Planung werden zwei Thread-Warps abwechselnd auf derselben SIMD-Einheit ausgeführt, um Leerlauf und Wartezeiten zu vermeiden und so die Nutzung der Rechenressourcen zu verbessern.
Darüber hinaus hat AMD Optimierungen bei der Zeigernormalisierung und Pufferoperationskonvertierung vorgenommen.Das Hauptziel dieser Optimierung besteht darin, Anweisungen effektiv bestimmten Geschäftsanwendungen zuzuordnen und eine effizientere atomare Befehlsausführung zu erreichen.
Diese Optimierungsprozesse konvertieren zunächst Triton-IR in Triton-GPU IR. Dabei werden Layoutinformationen in die IR eingebettet. Die folgende Abbildung dient als Beispiel, in der der Tensor in Form eines #blocked-Layouts dargestellt wird.

Wenn wir ein weiteres Beispiel für die Triton-Matrixmultiplikation ausprobieren, führt der obige Optimierungsablauf einen gemeinsamen Speicherzugriff zur Verbesserung der Leistung ein, was eine gängige Optimierungslösung für die Matrixmultiplikation ist, während das für den AMD MFMA-Beschleuniger entwickelte amd_mfma-Layout verwendet wird.
endlich,Bei der experimentellen Verifizierung habe ich eine komplexere Matrixmultiplikationsschicht als Beispiel verwendet. Im Zuge der Bestätigung der GPR-Zuordnung (General Purpose Register) wurden zahlreiche hardwarebezogene Anweisungen eingefügt, wie z. B. MFMA, Transposition, Shared-Memory-Aufrufe usw. Durch die Reduzierung von Bankkonflikten, die Anwendung von Swizzled-Operationen und die Kombination von Anweisungen zur Neuordnung und Pipeline-Verarbeitung werden all diese Optimierungen während des Triton-IR-Konvertierungsprozesses automatisch hinzugefügt, um eine stärkere Hardwareanpassung und Leistungsverbesserung zu erreichen.

* LLVM-IR-Optimierung
Auf AMD-Plattformen wird der Optimierungsprozess durch die Funktion make_llir definiert. Diese Funktion umfasst zwei Teile: Optimierung auf IR-Ebene und Konfiguration des AMD-GPU-LLVM-Compilers. Für die Optimierung auf IR-Ebene umfasst der AMD-GPU-spezifische Optimierungsprozess LDS-/Shared-Memory-bezogene Optimierungen und allgemeine Optimierungen auf LLVM-IR-Ebene, wie in der folgenden Abbildung dargestellt:
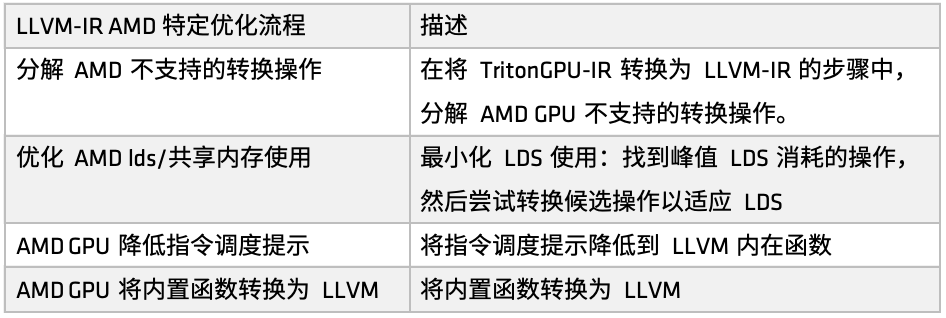
Erste,Zerlegen Sie einige Konvertierungsvorgänge, die AMD nicht unterstützt. Wenn wir beispielsweise bei der Konvertierung von Triton GPU IR in LLVM-IR auf derzeit nicht unterstützte Konvertierungspfade stoßen, zerlegen wir diese Vorgänge in grundlegendere Untervorgänge, um einen reibungslosen Abschluss des gesamten Konvertierungsprozesses zu gewährleisten.
Wenn Sie den AMD GPU LLVM-Compiler konfigurieren, initialisieren Sie zuerst die LLVM-Zielbibliothek und den Kontext, legen Sie die Kompilierungsparameter im LLVM-Modul fest, legen Sie dann die Aufrufkonvention für den AMD GPU HIP-Kernel fest und konfigurieren Sie einige LLVM-IR-Eigenschaften wie amdgpu-flat-work-group-size, amdgpu-waves-per-eu und denormal-fp-math-f32. Führen Sie abschließend LLVM-Optimierungen aus und legen Sie die Optimierungsstufe auf OPTIMIZE_O3 fest.
Referenzdokumentation zur Eigenschaftenkonfiguration:
https://llvm.org/docs/AMDGPUUsage.html
Backend-Modul zur Maschinencodegenerierung
Das Backend-Maschinencode-Generierungsmodul ist hauptsächlich für die Konvertierung des Zwischencodes in eine Binärdatei verantwortlich, die auf der Hardware ausgeführt werden kann. Diese Phase ist im Wesentlichen in zwei Schritte unterteilt: Generierung des AMDGCN-Assemblercodes und Erstellen der endgültigen AMD hsaco ELF-Datei.
Rufen Sie zunächst die Funktion translateLLVMIRToASM auf, um AMD-Assemblercode in der Phase make_amdgcn zu generieren. Dieser Prozess vervollständigt die Zuordnung vom Zwischencode zum Befehlssatz der Zielarchitektur und legt damit den Grundstein für die nachfolgende Binärgenerierung. Anschließend verwendet der Compiler die Funktion assemble_amdgcn und das ROCm-Linkmodul, um in der Phase make_hsaco eine AMD hsaco ELF-Binärdatei (Executable and Linkable Format) zu generieren. Diese Datei ist die finale Binärdatei, die direkt auf der AMD-GPU ausgeführt werden kann und vollständige geräteseitige Anweisungen und Metadaten enthält.
Durch diese beiden Schritte konvertiert der Compiler die Zwischendarstellung auf hoher Ebene effizient in ausführbaren GPU-Code auf niedriger Ebene und stellt so sicher, dass das Programm auf GPUs wie der AMD Instinct-Serie reibungslos ausgeführt werden kann und die Leistung der zugrunde liegenden Hardware voll ausnutzt.
AMD GPU-Entwickler-Cloud
AMD öffnet seine leistungsstarke GPU-Cloud-Plattform, AMD Developer Cloud, offiziell für globale Entwickler und Open-Source-Communitys.Ziel ist es, jedem Entwickler ungehinderten Zugriff auf erstklassige Computerressourcen zu ermöglichen, bequem auf GPU-Ressourcen der AMD Instinct MI-Serie zuzugreifen und schnell mit KI- und Hochleistungscomputeraufgaben zu beginnen.
In der AMD Developer Cloud können Entwickler Rechenressourcen flexibel entsprechend ihren Anforderungen auswählen:
* Klein: 1 GPU der MI-Serie (192 GB VRAM)
* Groß: 8 GPUs der MI-Serie (1536 GB VRAM)
Die Plattform minimiert den Konfigurationsaufwand, und Nutzer können das cloudbasierte Jupyter Notebook ohne komplizierte Installation sofort starten. Die Konfiguration lässt sich ganz einfach mit einem GitHub-Konto oder per E-Mail abschließen. Darüber hinaus bietet die AMD Developer Cloud vorkonfigurierte Docker-Container mit integrierten gängigen KI-Software-Frameworks. Dies minimiert den Zeitaufwand für die Einrichtung der Umgebung und bietet gleichzeitig ein hohes Maß an Flexibilität, sodass Entwickler den Code an spezifische Projektanforderungen anpassen können.
Entwickler sind herzlich eingeladen, die AMD Developer Cloud persönlich kennenzulernen, ihren Code auszuführen und ihre Ideen zu verifizieren. Die Plattform bietet Ihnen stabile, leistungsstarke und flexible Rechenleistung, um Innovation und Implementierung zu beschleunigen.
AMD Developer Cloud-Link:
https://www.amd.com/en/developer/resources/cloud-access/amd-developer-cloud.html
Holen Sie sich die PPT:Folgen Sie dem öffentlichen WeChat-Konto „HyperAI Super Neuro“ und antworten Sie auf das Schlüsselwort „0705 AI Compiler“, um die PPT mit der Rede des autorisierten Dozenten zu erhalten.








