Command Palette
Search for a command to run...
Die National University of Singapore Hat Eine Detaillierte Patientenkohortenmodellierung Auf Basis Mehrdimensionaler EHR-Daten Implementiert Und Die Genauigkeit Der Krankenhausaufenthaltsvorhersage Um 16,3% erhöht.

Im heutigen Zeitalter der rasanten Entwicklung der medizinischen Informationstechnologie sind elektronische Patientenakten (EHR) zu einem wichtigen Kernbestandteil des medizinischen Systems geworden. Dank ihrer systematischen Architektur speichert die EHR die Krankenakten der Patienten präzise in elektronischer Form.Es deckt alles ab, von grundlegenden demografischen Daten bis hin zu dynamischen, zeitveränderlichen medizinischen Merkmalen.Es bietet eine solide Datenunterstützung für alle Aspekte der medizinischen Praxis und spielt in Schlüsselbereichen wie der Unterstützung klinischer Entscheidungen und der Optimierung des Patientenmanagements eine unersetzliche Rolle.
Im Rückblick auf die klinische Praxis während des Höhepunkts der COVID-19-Pandemie im Jahr 2020 entdeckten Ärzte durch die Bildung von Patientenkohorten verschiedener Altersgruppen wichtige Muster: Patienten im Alter von 50 bis 70 Jahren zeigten häufiger schwere Symptome wie Dyspnoe und kognitiven Abbau, während Patienten im Alter von 20 bis 40 Jahren meist leichte oder asymptomatische Symptome aufwiesen. Diese kohortenbasierte Vergleichsanalyse liefert nicht nur eine direkte Grundlage für die Formulierung von Diagnose- und Behandlungsplänen, sondern enthüllt auch das lange vernachlässigte Kernelement des EHR-Repräsentationslernens – Patientenkohorten.
Als Basiseinheit der medizinischen Forschung identifizieren Kohorten Patientengruppen mit ähnlichen klinischen Merkmalen anhand gemeinsamer Merkmale. Ihr Wert geht weit über die einfache Ansammlung individueller Daten hinaus: Sie können nicht nur Krankheitsmuster spezifischer Populationen aufdecken, wie beispielsweise den Zusammenhang zwischen Fiebersymptomen und einer COVID-19-Infektion, sondern auch gezielte Hinweise für präzise medizinische Interventionen liefern. Traditionelle Methoden der Kohorteneinteilung weisen jedoch zahlreiche Einschränkungen auf und erfüllen die Anforderungen einer verfeinerten ePA-Datenverarbeitung nur schwer.Wenn keine feinkörnige Warteschlangenaufteilung erreicht werden kann, kommt es leicht zu Störungen und wertvolle Informationen innerhalb und zwischen den Warteschlangen können nicht vollständig genutzt werden.
In diesem ZusammenhangDie National University of Singapore und die Zhejiang University haben gemeinsam die innovative Methode NeuralCohort vorgeschlagen, die einen neuen Weg für das EHR-Repräsentationslernen eröffnet.Dank seiner einzigartigen Dual-Modul-Architektur dürfte diese Methode bestehende Schwierigkeiten überwinden, das Potenzial von EHR-Daten voll ausschöpfen und der medizinischen Analyse entscheidende Impulse verleihen. Ihre Anwendungsaussichten im medizinischen Bereich haben große Aufmerksamkeit erregt. Es wird erwartet, dass sie die medizinische Datenanalyse und klinische Entscheidungsmodelle grundlegend verändern und die medizinische Industrie zu einer intelligenteren und präziseren Entwicklung anregen wird.
Die entsprechenden Forschungsergebnisse wurden für ICML 2025 unter dem Titel „NeuralCohort: Cohort-aware Neural Representation Learning for Healthcare Analytics“ ausgewählt.
Forschungshighlights:
* NeuralCohort, das in dieser Studie vorgeschlagen wird, ist eine warteschlangenbewusste Methode zum Lernen neuronaler Darstellungen, die sich auf die Unterstützung der feinkörnigen Warteschlangengenerierung konzentriert
* NeuralCohort nutzt auf innovative Weise sowohl lokale Informationen innerhalb der Kohorte als auch globale Informationen zwischen Kohorten. Dies sind Schlüsselelemente, die in früheren Studien zur Analyse elektronischer Gesundheitsakten nicht ausreichend berücksichtigt wurden.
* Der Vorteil von NeuralCohort liegt in seiner hervorragenden Kompatibilität und der nahtlosen Integration in verschiedene Backbone-Modelle. Es kann als vielseitiges Plug-in verwendet werden, um Kohorteninformationen in die medizinische Analyse einzubeziehen und so die Gesamtleistung zu verbessern.

Papieradresse:
https://openreview.net/forum?id=bqQVa6VRvm
Weitere Artikel zu den Grenzen der KI:
https://go.hyper.ai/owxf6
EHR-Datensystem: Mehrdimensionale Integration medizinischer Informationen und Unterstützung klinischer Forschungsdatensätze
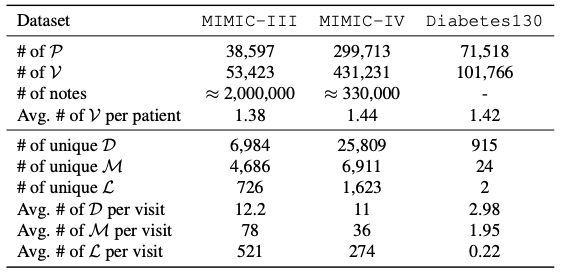
Das Kerndatensystem dieser Studie basiert auf elektronischen Gesundheitsakten (EHR).Seine Datenstruktur integriert die medizinischen Informationen des gesamten Patientenzyklus.Die Datenbank umfasst detaillierte Aufzeichnungen von Krankenhausaufenthalten, ambulanten Behandlungen und Notfällen sowie mehrdimensionale Informationen wie klinische Diagnose, Behandlungsplan, Medikamentenverlauf, Testergebnisse, Bildgebungsberichte und klinische Notizen. So entsteht eine strukturierte Datenbank, die den Gesundheitszustand von Patienten longitudinal verfolgt und umfassende Datenunterstützung für klinische Entscheidungen, personalisierte Medizin und Bevölkerungsgesundheitsforschung bietet. Wie in der folgenden Tabelle dargestellt, umfasst die in dieser Studie verwendete Datenbasis:
Der MIMIC-III-Datensatz ist eine wichtige öffentlich zugängliche medizinische Ressource und umfasst 53.423 einzigartige Krankenhausaufzeichnungen.Es handelt sich um erwachsene Patienten ab 16 Jahren, die zwischen 2001 und 2012 auf der Intensivstation des Beth Israel Dekaney Medical Center eingeliefert wurden. Außerdem enthält es 2.083.180 anonymisierte klinische Notizen, die tiefe Einblicke in die Krankheitsentwicklung der Patienten, den Behandlungsverlauf und die klinische Entscheidungsfindung bieten.
Der MIMIC-IV-Datensatz konzentriert sich auf Patientenaufnahmeinformationen, die zwischen 2008 und 2022 erfasst wurden.Es verwendet eine modulare Datenorganisationsstruktur, die die Rückverfolgbarkeit und Unabhängigkeit der Datenquellen betont, sodass Forscher je nach Bedarf flexibel auf verschiedene Datenquellen und deren gemeinsame Daten zugreifen können.
Der Diabetes130-Datensatz sammelt klinische Versorgungsdaten von 130 US-amerikanischen Krankenhäusern und integrierten Gesundheitsnetzwerken zwischen 1999 und 2008., mit Schwerpunkt auf Musteranalysen im Bereich der Diabetesbehandlung. Seine einzigartigen Datenthemen und die langfristige Datensammlung bieten genaue Datenunterstützung für die eingehende Erforschung historischer Diabetesbehandlungsmuster, die Optimierung von Behandlungsplänen für Diabetiker und die Bereitstellung sicherer und personalisierter medizinischer Dienste.
NeuralCohort-Modell: ein dualmodulgesteuertes, kohortenbewusstes EHR-Darstellungslernframework
Um Patientenkohorten effektiv zu integrieren und den Repräsentationslerneffekt von Daten elektronischer Gesundheitsakten (EHR) zu verbessern, besteht NeuralCohort aus zwei Kernmodulen: dem Pre-context Cohort Synthesis Module und dem Biscale Cohort Learning Module.
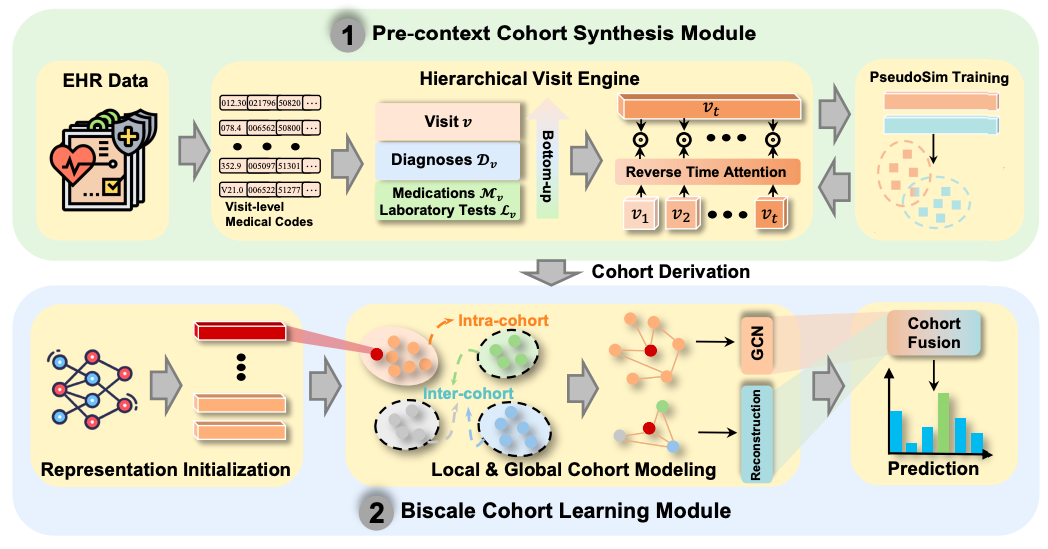
Im Pre-Context Queue Synthesis-ModulDas NeuralCohort-Modell führte erstmals eine hierarchische Besuchsmaschine ein.Es kann komplexe Ontologiestrukturen diagnostischer Codes verarbeiten, wie beispielsweise das Baumsystem der ICD-9. Durch die Kombination von Pfaddarstellung und semantischer Ähnlichkeitsmessung kann das Modul medizinische Begriffe mit hierarchischen Assoziationen, wie beispielsweise die verschiedenen Codes für Diabetes und seine Komplikationen, effektiv unterscheiden. Gleichzeitig kann das Modell die hierarchischen Merkmale von Diagnose-, Medikamenten- und Testcodes integrieren.Und verwenden Sie den Reverse Time Attention-Mechanismus (Reverse Time Attention),Die historischen Besuchsinformationen werden dynamisch mit dem aktuellen Besuch als Ankerpunkt aggregiert, um die zeitliche Abhängigkeit der Besuchssequenz zu erfassen.
Um die Ineffizienz der herkömmlichen manuellen Annotation von Patientenähnlichkeiten zu beheben, führte das Modul die innovative PseudoSim-Trainingsaufgabe ein, generierte Pseudolabels anhand von Diagnosecodes und optimierte die Patientendarstellung durch neuronale Schätzung auf Grundlage gegenseitiger Information. Abschließend wurde die Kohortenableitung mithilfe der Jensen-Shannon-Divergenz und der Student-t-Verteilung erreicht, wodurch ein strukturiertes Patientengruppierungsschema für die anschließende Analyse bereitgestellt wurde.
Das Dual-Scale-Queue-Lernmodul ist auf die Ermittlung gemeinsamer Merkmale innerhalb der Warteschlange und der unterschiedlichen Merkmale zwischen verschiedenen Warteschlangen ausgerichtet..Bei der lokalen Kohortenmodellierung behandelt das Modell jede Kohorte als Graphstruktur und erstellt eine Adjazenzmatrix unter Verwendung der Kosinusähnlichkeit der Patientendarstellungen. Das Graph-Neuralnetz aggregiert Knoteninformationen Schicht für Schicht, um die Interaktionsmuster von Patienten derselben Kohorte zu erfassen.
Global Cohort Modeling verwendet eine Encoder-Decoder-Architektur, um die semantische Integrität der Kohorte durch Rekonstruktionsverlust aufrechtzuerhalten, während Kontrastverlust kombiniert wird, um die Merkmalstrennung verschiedener Kohorten zu stärken und die Unterscheidbarkeit zwischen Kohorten sicherzustellen.
Abschließend werden die initiale Darstellung des Backbone-Netzwerks, die lokale Darstellung innerhalb der Warteschlange und die globale Darstellung zwischen den Warteschlangen durch den domänenübergreifenden Aufmerksamkeitsmechanismus zu einer finalen Darstellung mit mehrstufigen Warteschlangeninformationen zusammengeführt. Während des Modelltrainings integriert die Verlustfunktion den Trainingsverlust durch Pseudoähnlichkeit, den Verlust durch Warteschlangenableitung, den Verlust durch Warteschlangenvergleich und den Verlust durch nachgelagerte Aufgaben. Durch die Anpassung der Gewichtsparameter wird eine mehrzielige Optimierung erreicht. Dadurch kann NeuralCohort nicht nur feingranulare individuelle Patientenmerkmale erlernen, sondern auch klinisch interpretierbare Warteschlangengruppenmuster erfassen. Dies bietet eine Lösung, die Genauigkeit und Interpretierbarkeit für medizinische Datenanalyseaufgaben vereint und voraussichtlich die wissenschaftliche und präzise medizinische Entscheidungsfindung fördert.
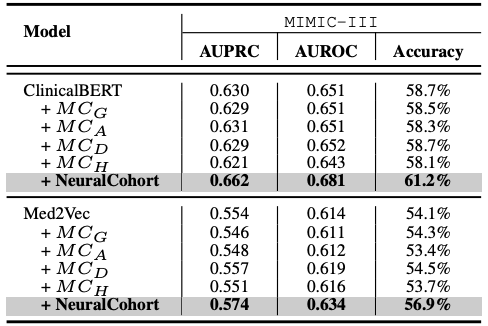
Mehrdimensionale experimentelle Verifizierung: Die Genauigkeit des NeuralCohort-Modells wurde um 16,31 TP3T erhöht, was die Entscheidungsfindung im Patientenmanagement deutlich verbessert
Um den Optimierungseffekt von NeuralCohort auf das Lernen der Darstellung elektronischer Patientenakten (EHR) zu bewerten, hat das Forschungsteam einen umfassenden experimentellen Rahmen erstellt.
Die Forscher wählten Med2Vec, MiME und ClinicalBERT, drei repräsentative Modelle im Bereich der medizinischen Datenanalyse, als Benchmark-Frameworks. Um einen effektiven Vergleich zu ermöglichen, wurden gleichzeitig sieben traditionelle Kohortenintegrationsalgorithmen wie KNN und K-Means als Vergleichsmethoden in das Experiment einbezogen.
Das experimentelle Design konzentriert sich auf zwei wichtige medizinische Vorhersageaufgaben: die Vorhersage von Krankenhauswiederaufnahmen und die Vorhersage von Langzeitaufenthalten (LOS).Diese beiden Aufgaben sind für das medizinische Ressourcenmanagement und die Verbesserung der Qualität der Patientenversorgung von großer Bedeutung. Um die Leistung des Modells umfassend zu bewerten, verwendeten die Forscher drei allgemein anerkannte Bewertungsindikatoren – AUPRC, AUROC und Genauigkeit – und führten fünf Runden wiederholter Experimente durch, um stabile und zuverlässige statistische Ergebnisse zu erhalten und so die Generalisierungsfähigkeit des Modells systematisch zu bewerten.
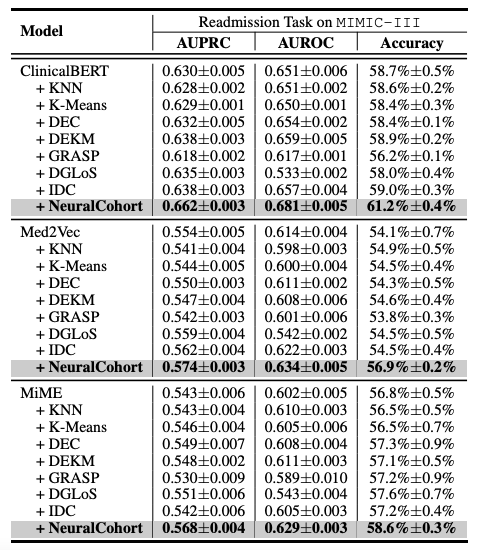
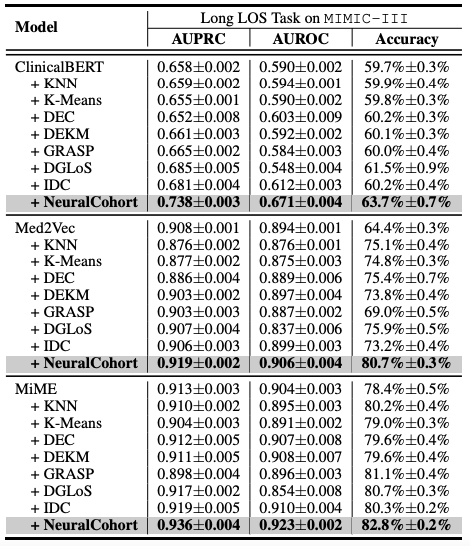
Die gesamten experimentellen Ergebnisse sind in der folgenden Tabelle dargestellt. NeuralCohort schneidet bei zwei Vorhersageaufgaben des MIMIC-III-Datensatzes gut ab. Im Vergleich zum traditionellen BasismodellDer AUPRC-Indikator wurde um bis zu 8,0% verbessert, der AUROC-Indikator um 8,1% und die Genauigkeit war um 16,3% deutlich höher.
Weitere Analysen ergaben, dass mit dem Basismodell keine konsistenten Leistungssteigerungen erzielt werden konnten.Der Hauptgrund besteht darin, dass es nicht ausreicht, detaillierte Warteschlangeninformationen zu modellieren.Beispielsweise arbeiten KNN- und K-Means-Algorithmen nicht in einem ähnlichkeitsbewussten Merkmalsraum, der von DGLoS erstellte globale Graph ist grobkörnig, GRASP konzentriert sich ausschließlich auf die Modellierung zwischen Kohorten, und DEC, DEKM und IDC können medizinische Semantik nicht effektiv modellieren. Diese Mängel führen dazu, dass das Basismodell Patientenähnlichkeiten schlecht simuliert und sogar Rauschen in das Backbone-Modell einbringt, was die Gesamtleistung mindert.
Im Vergleich zu herkömmlichen Methoden zur Kohortenbildung bietet NeuralCohort erhebliche Vorteile. Traditionelle Methoden unterteilen Kohorten üblicherweise anhand begrenzter Merkmale wie Geschlecht, Alter, Diabetes- und Bluthochdruckdiagnose. Die mit dieser Methode generierten Kohorten sind relativ grobkörnig, was den Anforderungen des Kohortenmuster-Minings nur schwer gerecht wird. Zudem können unterschiedliche Patienten leicht in derselben Kohorte zusammengefasst werden, was zu Störungen führt. NeuralCohort hingegen nutzt die sequentielle Darstellung der Patientenbesuche innerhalb und zwischen Kohorten, um auf einer feinkörnigen Ebene zu arbeiten.Dies verbesserte die klinische Ähnlichkeit der Patienten in der Kohorte im MIMIC-III-Datensatz um 23,5%.
Vergleich der traditionellen Kohorte und der NeuralCohort im MIMIC-III-Datensatz
Die Interpretierbarkeitsanalyse verdeutlicht die Vorteile von NeuralCohort. Der Calinski-Harabasz-Score zeigt, dass die von NeuralCohort generierte Kohorte den CH-Score in der Langzeit-LOS-Aufgabe im Vergleich zu Methoden wie K-Means um 18,7%–25,4% verbessert. Die visuelle Analyse basierend auf t-SNE zeigt zudem, dass die direkt vom Basismodell ausgegebene Darstellung eine signifikante Clusterüberlappung aufweist, während NeuralCohort, wie in der folgenden Abbildung dargestellt, Kohorteninformationen einfügt.Die Unterscheidung der acht Zielkohorten wurde um 41,2% verbessert, wobei die charakteristischen Grenzen klinisch typischer Gruppen wie der Kohorte mit Herz-Kreislauf-Erkrankungen und der Kohorte mit chronischen Stoffwechselerkrankungen besonders deutlich waren.

In klinischer HinsichtNeuralCohort ist in der Lage, kohortenspezifische Merkmale zu identifizieren, die in direktem Zusammenhang mit klinischen Ergebnissen stehen, und so die Patientenbehandlung deutlich zu verbessern.Beispielsweise deckten die einzigartigen Merkmale der vier durch T-Tests ermittelten Kohorten unterschiedliche Patientengruppen ab, etwa mit Herz-Kreislauf-Erkrankungen, chronischen Stoffwechsel- und Bluterkrankungen, Nieren- und Harnwegsproblemen sowie komplexen chronischen und akuten Erkrankungen.
Durch die Identifizierung dieser Merkmale können Krankenhäuser Ressourcen gezielter zuweisen (z. B. Telemetriebetten, kardiologische Sprechstunden, Diabetesberater, Nierenteams usw.) und entsprechende Interventionsmaßnahmen formulieren (z. B. rechtzeitige Gabe von Diuretika, Insulintitration und Planung von bildgebenden Untersuchungen). Dadurch werden die Effizienz des Krankenhauses und die Qualität der Patientenversorgung deutlich verbessert.
Zusammenarbeit zwischen Industrie und Forschung, wechselseitig gesteuertes EHR-Innovationsökosystem
Im Bereich des Lernens der Darstellung elektronischer Patientenakten (EHR) und der Kohortenanalyse fördern die akademischen und geschäftlichen Gemeinschaften weltweit die umfassende Freisetzung des Werts medizinischer Daten durch bahnbrechende Technologien und Innovationen in der klinischen Praxis und verleihen der Entwicklung der Präzisionsmedizin neue Impulse.
Das von Professor Wang Xiaolis Team an der Xiamen-Universität vorgeschlagene MHGRL-Modell integriert die interne Struktur der EHR mit externem medizinischen Wissen durch die Konstruktion eines multimodalen heterogenen Graphen.Die Genauigkeit der Krankheitsvorhersage wurde bei Datensätzen wie MIMIC-III erheblich verbessert.Der von diesem Modell übernommene Reverse-Time-Aufmerksamkeitsmechanismus verstärkt die Korrelation zwischen dem aktuellen Besuch und dem historischen Datensatz, was in der technischen Logik dem Pre-Context-Warteschlangensynthesemodul von NeuralCohort entspricht, und beide spiegeln die Betonung auf der Modellierung von Zeitreiheninformationen wider.
Das vom Team der Cornell University erstellte GEMS-Modell basiert auf 8 Millionen echten EHR-Daten.Die Studie demonstrierte die direkte Anwendung der Kohortenanalyse in der klinischen Entscheidungsfindung. Sie erfasste den 104-dimensionalen Merkmalsvektor von Patienten mit fortgeschrittenem Lungenkrebs mithilfe eines Graph-Neural-Network-Encoders und kombinierte ihn mit einem Clustering-Modul, um drei Subphänotypen mit signifikanten Überlebensunterschieden zu identifizieren. Der C-Index zur Vorhersage des Gesamtüberlebens erreichte 0,665 und übertraf damit das traditionelle Basismodell deutlich. Der technische Ansatz entspricht methodisch weitgehend dem dualen Kohortenlernmodul von NeuralCohort, und beide konzentrieren sich auf die Gewinnung klinisch relevanter Kohortenmerkmale aus komplexen Daten.
Auch die Wirtschaft hat bemerkenswerte Ergebnisse erzielt und setzt Spitzentechnologien aus der Wissenschaft in praktische klinische Anwendungswerkzeuge um. Ein Beispiel hierfür ist das PATH-Programm, eine Zusammenarbeit zwischen dem britischen NHS und Hippocratic AI.Durch die automatisierte Anamneseerfassung und Überweisungsprüfung durch Gesprächsagenten kann die Wartezeit für Facharztkonsultationen um 35% verkürzt werden.Dieses EHR-basierte intelligente Triage-System verfügt über ein integriertes Kohortenanalysemodul, das Hochrisikopatientengruppen in Echtzeit identifizieren kann. Beispielsweise kann es komplexe Merkmale wie „chronisch obstruktive Lungenerkrankung mit akuter Exazerbation“ durch natürliche Sprachverarbeitung aus klinischen Notizen extrahieren und die Patientenprioritäten dynamisch anpassen.
Zusammenfassend lässt sich sagen, dass die akademische Gemeinschaft durch algorithmische Innovationen präzisere Kohortenmodelle entwickelt und so die Tiefe und Breite des medizinischen Data Mining kontinuierlich erweitert hat. Die Wirtschaft hingegen hat diese Spitzentechnologien mithilfe ihrer technologischen Transformationsfähigkeiten in praxistaugliche klinische Instrumente umgewandelt und so die Effizienz und Qualität medizinischer Leistungen verbessert. Dieses wechselseitig getriebene Innovationsökosystem soll Ärzten nicht nur zu präziseren Diagnosen verhelfen, sondern auch Frühwarnsignale für individuelle Risiken anhand von Gruppenmerkmalen erkennen, die Transformation medizinischer Dienstleistungsmodelle von der Krankheitsbehandlung zum Gesundheitsmanagement fördern und die Optimierung und Modernisierung des globalen medizinischen Systems nachhaltig unterstützen.
Referenzartikel:
1.https://cdmc.xmu.edu.cn/info/1002/3683.htm
2.https://mp.weixin.qq.com/s/Z1Wl0FIPHpwrvnNDCE5KwA
3.https://mp.weixin.qq.com/s/neCUoGm75mTPwjvlND5_sg








