Command Palette
Search for a command to run...
OmniGen2 – Multimodale Schlussfolgerung Und Selbstkorrektur – Führt Zu Einem Neuen Paradigma Für Die Bildgenerierung; 950.000 Klassifizierungslabels! TreeOfLife-200M Eröffnet Eine Neue Dimension Der Artenerkennung

In den letzten Jahren hat die generative KI-Technologie im Bereich der Bildverarbeitung bedeutende Durchbrüche erzielt. Modelle wie die Stable Diffusion-Reihe und DALL-E3 haben mithilfe von Diffusionsmodellen eine hochwertige Text-zu-Bild-Generierung erreicht. Diesen Modellen fehlt jedoch das umfassende Wahrnehmungsverständnis und die Generierungsfähigkeiten, die für allgemeine Modelle der visuellen Generierung erforderlich sind. OmniGen wurde entwickelt, um eine einheitliche Lösung für verschiedene Generierungsaufgaben basierend auf der Diffusionsmodellarchitektur zu bieten. Es verfügt über Multitasking-Verarbeitungsfunktionen und kann hochwertige Bilder ohne zusätzliche Plug-ins generieren. Es ist unbestreitbar, dass das Modell noch Einschränkungen bei der multimodalen Entkopplung und der Datendiversität aufweist.
Um diese Schwierigkeiten zu überwinden und die Flexibilität und Ausdruckskraft des Systems weiter zu verbessern, ist OmniGen2 ein großer Durchbruch gelungen.Es verfügt über zwei unabhängige Dekodierungspfade für Text- und Bildmodalitäten.Es verwendet nicht freigegebene Parameter und einen separaten Bild-Tagger. Dieses Design ermöglicht es OmniGen2, auf bestehenden multimodalen Verständnismodellen aufzubauen, ohne den Variational-Autoencoder-Eingang neu anzupassen. Dadurch bleiben die ursprünglichen Textgenerierungsfunktionen erhalten.
Derzeit wurde auf der offiziellen HyperAI-Website das Tutorial „OmniGen2: Exploring Advanced Multimodal Generation“ veröffentlicht. Kommen Sie vorbei und probieren Sie es aus ~
OmniGen2: Erforschung fortschrittlicher multimodaler Generierung
Online-Nutzung:https://go.hyper.ai/fKbUP
Vom 30. Juni bis 4. Juli gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Auswahl an hochwertigen Tutorials: 7
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im Juli: 4
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. ShareGPT-4o-Image Bildgenerierungsdatensatz
ShareGPT-4o-Image ist ein umfangreicher, hochwertiger Bildgenerierungsdatensatz, der darauf abzielt, Bildgenerierungsfunktionen auf GPT-4o-Niveau auf Open-Source-Multimodalmodelle zu migrieren. Alle Bilder in diesem Datensatz werden mit der Bildgenerierungsfunktion von GPT-4o generiert und enthalten insgesamt 92.256 Bildgenerierungsbeispiele von GPT-4o.
Direkte Verwendung:https://go.hyper.ai/5G48Y

2. MAD-Cars Multi-View-Autovideo-Datensatz
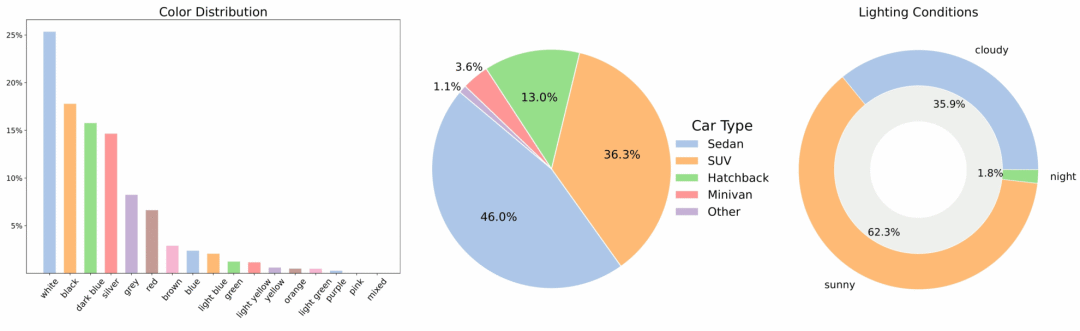
MAD-Cars ist ein umfangreicher Multi-View-Autovideodatensatz, der den Umfang bestehender öffentlicher Multi-View-Autodatensätze deutlich erweitert. Der Datensatz enthält rund 70.000 Autovideoinstanzen mit durchschnittlich 85 Bildern pro Instanz. Die meisten Fahrzeuginstanzen haben eine Auflösung von 1920 × 1080 Pixeln und decken rund 150 Automarken ab, darunter mehrere Modelle, Farben und drei Lichtverhältnisse.
Direkte Verwendung:https://go.hyper.ai/xuB9I
3. Bilddatensatz für Pflanzen und Nutzpflanzen
Der Pflanzen- und Nutzpflanzen-Datensatz ist ein umfassender Bilddatensatz für landwirtschaftliche KI. Er enthält 100.000 standardisierte Bilder von 139 weltweit angebauten Nutzpflanzen. Der Datensatz deckt mehrere Wachstumsstadien von Nutzpflanzen ab, vom Sämling bis zur Blüte und Fruchtbildung. Der Bildinhalt umfasst verschiedene Strukturteile wie Blätter, Stängel und Früchte mit umfangreichen Darstellungsinformationen. Alle Bilder sind auf 224 × 224 Pixel vereinheitlicht, um Größenunterschiede beim Modelltraining zu reduzieren.
Direkte Verwendung:https://go.hyper.ai/PLVJp

4. Multimodal-Textbook-6.5M Multimodaler Lehrbuchdatensatz
Multimodal-Textbook-6.5M zielt darauf ab, das multimodale Vortraining zu verbessern und die Fähigkeit des Modells zur Verarbeitung interlaced visueller und textueller Eingaben zu erweitern. Der Datensatz enthält 6,5 Millionen Bilder und 800 Millionen Textdaten aus Lehrvideos. Alle Bilder und Texte stammen aus Online-Lehrvideos und decken sechs grundlegende Fächer wie Mathematik, Physik und Chemie ab.
Direkte Verwendung:https://go.hyper.ai/q8Iin
5. IndicVault-Datensatz für indische Frage-Antwort-Paare
Indic Vault ist ein Frage-Antwort-Datensatz in indischer Alltagssprache, der sich für die Optimierung von Chatbots und Sprachassistenten eignet. Der Datensatz enthält Frage-Antwort-Paare in der zeitgenössischen Alltagssprache Indiens aus dem Jahr 2025. Er erfasst reale, umgangssprachliche Ausdrücke aus alltäglichen Gesprächen und deckt 20 Kernkategorien ab.
Direkte Verwendung:https://go.hyper.ai/JhEUR
6. Benchmark-Datensatz für DREAM-1K-Videobeschreibungen
Der Datensatz enthält 1.000 kommentierte Videoclips unterschiedlicher Komplexität aus fünf verschiedenen Kategorien. Jeder Clip enthält mindestens ein dynamisches Ereignis, das anhand eines einzelnen Frames nicht eindeutig identifiziert werden kann. Jedes Video ist mit detaillierten manuellen Anmerkungen versehen, die alle Ereignisse, Aktionen und Bewegungen abdecken.
Direkte Verwendung:https://go.hyper.ai/AgOm0
7. Analysedatensatz zur Hirntumorerkennung durch MRT des Gehirns
Die MRT des Gehirns enthält hochwertige Multisequenz-MRT-Aufnahmen verschiedener Patienten. Diese Aufnahmen enthalten T1-gewichtete, T2-gewichtete, FLAIR- und diffusionsgewichtete Bildsequenzen. Dieser Datensatz deckt verschiedene Arten von Hirntumoren ab und wird mit gesunden Kontrollpersonen verglichen. Dadurch eignet er sich für die Entwicklung und Validierung fortschrittlicher Machine-Learning-Modelle und klinischer Forschungsanwendungen.
Direkte Verwendung:https://go.hyper.ai/oZWNu
8. AceReason-1.1-SFT-Datensatz zum mathematischen Code-Argumentieren
Dieser Datensatz dient als SFT-Trainingsdaten für das Mathematik- und Code-Reasoning-Modell AceReason-Nemotron-1.1-7B. Alle Antworten im Datensatz werden von DeepSeek-R1 generiert. Der AceReason-1.1-SFT-Datensatz enthält 2.668.741 mathematische Beispiele und 1.301.591 Codebeispiele und deckt Daten aus mehreren Datenquellen ab. Der Datensatz wurde bereinigt und Beispiele mit 9-Gramm-Überschneidungen mit Testbeispielen in den Mathematik- und Code-Benchmarks wurden herausgefiltert.
Direkte Verwendung:https://go.hyper.ai/WGl1k
9. TreeOfLife-200M-Datensatz zum biologischen Sehen
TreeOfLife-200M ist der größte und vielfältigste öffentliche, maschinenlernfähige Datensatz für biologische Computervisionsmodelle. Der Datensatz enthält fast 214 Millionen Bilder, die 952.000 Artenkategorien abdecken, und integriert Bilder und Metadaten von vier zentralen Anbietern von Biodiversitätsdaten.
Direkte Verwendung:https://go.hyper.ai/UKC0H
10. VL-Health-Datensatz zur Generierung medizinischer Begründungen
VL-Health ist der erste umfassende Datensatz für multimodales medizinisches Verständnis und Generierung. Der Datensatz integriert 765.000 Beispiele für Verständnisaufgaben und 783.000 Beispiele für Generierungsaufgaben und deckt elf medizinische Modalitäten und mehrere Krankheitsszenarien ab.
Direkte Verwendung:https://go.hyper.ai/GvKlu
Ausgewählte öffentliche Tutorials
Diese Woche haben wir drei Arten hochwertiger öffentlicher Tutorials zusammengestellt:
*Tutorials zur Bilderzeugung und -bearbeitung: 3
*Tutorials zur 3D-Generierung: 2
* Tutorials zur Audiogenerierung: 2
Tutorial zur Bilderzeugung und -bearbeitung
1. OmniGen2: Erforschung fortschrittlicher multimodaler Generierung
OmniGen2 bietet eine einheitliche Lösung für verschiedene Generierungsaufgaben, darunter Text-zu-Bild-Generierung, Bildbearbeitung und Kontextgenerierung. Durch die Verwendung nicht gemeinsam genutzter Parameter und separater Bild-Tokenizer kann OmniGen2 auf bestehenden multimodalen Verständnismodellen aufbauen, ohne VAE-Eingaben neu anpassen zu müssen. Die ursprünglichen Textgenerierungsfunktionen bleiben erhalten.
Online ausführen:https://go.hyper.ai/fKbUP

2. FLUX.1-Kontext-dev: Textbasierte Bildbearbeitung mit einem Klick
Die Bildbearbeitung von FLUX.1 Kontext ist eine Bildbearbeitung im weitesten Sinne, die nicht nur die lokale Bildbearbeitung (gezielte Änderung bestimmter Elemente im Bild ohne Beeinträchtigung des Rests) unterstützt, sondern auch die Charakterkonsistenz (Beibehaltung eindeutiger Elemente im Bild wie Referenzcharaktere oder -objekte, um deren Konsistenz in mehreren Szenen und Umgebungen zu gewährleisten) erreicht.
Online ausführen:https://go.hyper.ai/PqRGn

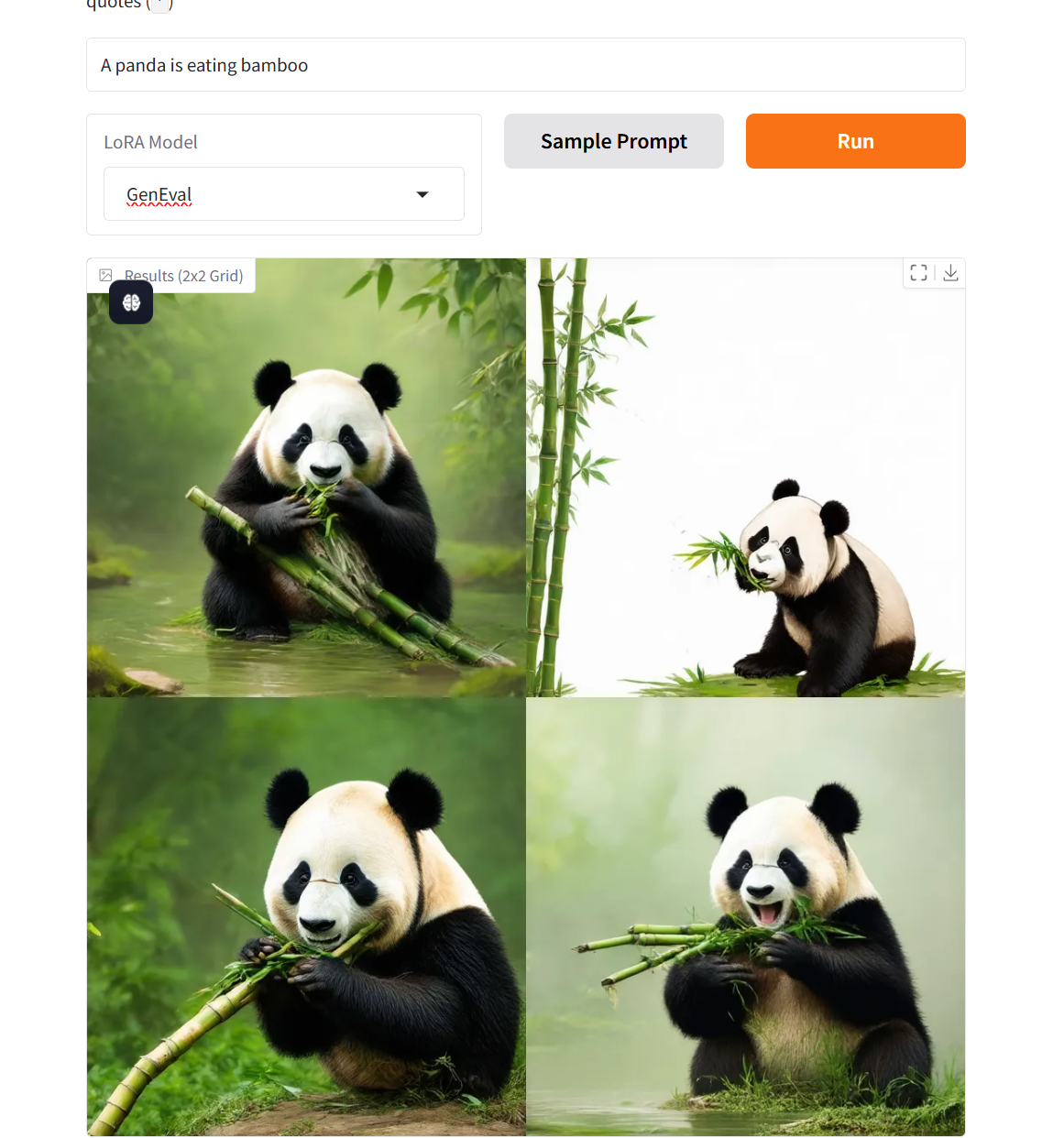
3. Flow-GRPO-Flow-Matching-Textgraphenmodell-Demo
Dieses Modell war ein Vorreiter bei der Integration eines Online-Reinforcement-Learning-Frameworks und der Flow-Matching-Theorie und erzielte im GenEval 2025-Benchmark-Test bahnbrechende Fortschritte: Die kombinierte Generierungsgenauigkeit des SD 3.5 Medium-Modells sprang vom Benchmark-Wert von 63% auf 95% und der Bewertungsindex für die Generierungsqualität übertraf erstmals GPT-4o.
Online ausführen:https://go.hyper.ai/v7xkq
Tutorial zur 3D-Generierung
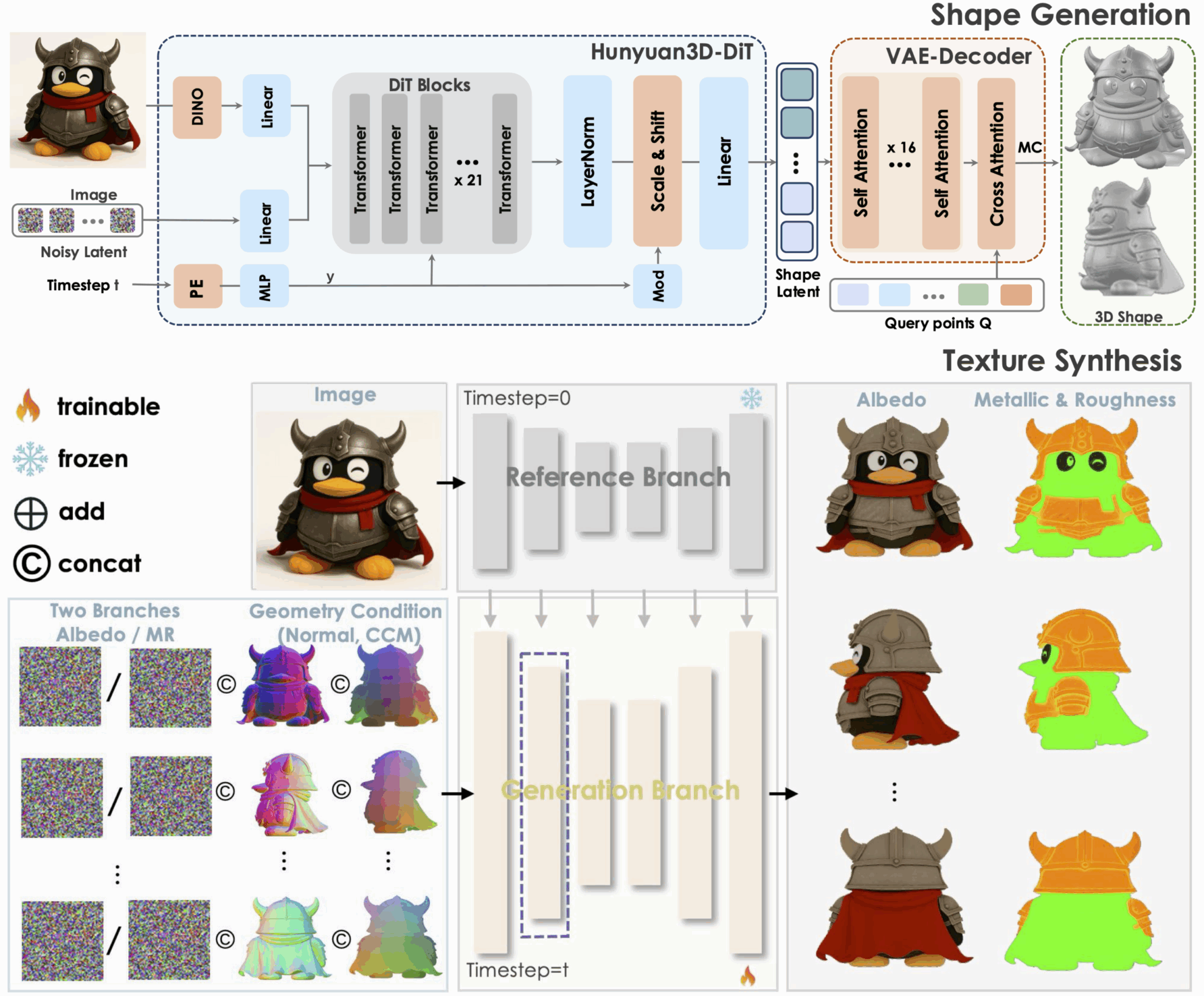
1. Hunyuan3D-2.1: 3D-generatives Modell, das physikalische Rendering-Texturen unterstützt
Tencent Hunyuan3D-2.1 ist ein industrietaugliches Open-Source-3D-Generierungsmodell und ein skalierbares System zur Erstellung von 3D-Assets. Es fördert die Entwicklung modernster 3D-Generierungstechnologie durch zwei Schlüsselinnovationen: ein vollständig Open-Source-Framework und eine physikbasierte Rendering-Textursynthese. Gleichzeitig ermöglicht es die vollständige Öffnung von Datenverarbeitung, Trainings- und Reasoning-Codes usw. und bietet so eine reproduzierbare Grundlage für die akademische Forschung und reduziert die wiederkehrenden Entwicklungskosten für die industrielle Umsetzung.
Online ausführen:https://go.hyper.ai/0H91Z
2. Direct3D‑S2: Ein Framework für hochauflösendes 3D-Rendering
Direct3D-S2 ist ein Framework zur hochauflösenden 3D-Generierung, das die Rechenleistung des Diffusionstransformators deutlich verbessert und den Trainingskosten durch spärliche Volumendarstellung und einen innovativen räumlichen Mechanismus zur spärlichen Aufmerksamkeit deutlich reduziert. Das Framework übertrifft bestehende Methoden sowohl in der Generierungsqualität als auch in der Effizienz und bietet umfassende technische Unterstützung für die Erstellung hochauflösender 3D-Inhalte.
Online ausführen:https://go.hyper.ai/67LQM

Tutorial zur Audiogenerierung
1. PlayDiffusion: Open Source-Modell zur lokalen Audiobearbeitung
PlayDiffusion kodiert Audio in diskrete Token-Sequenzen, maskiert die zu ändernden Teile und verwendet ein Diffusionsmodell, um die maskierten Bereiche des aktualisierten Textes zu entrauschen und so eine hochwertige Audiobearbeitung zu erreichen. Es bewahrt nahtlos den Kontext, stellt die Kohärenz und Natürlichkeit der Sprache sicher und unterstützt eine effiziente Text-to-Speech-Synthese bei hoher zeitlicher Konsistenz und Skalierbarkeit.
Online ausführen:https://go.hyper.ai/WTlI4
2. OuteTTS: Sprachgenerierungs-Engine
OuteTTS ist ein Open-Source-Projekt zur Text-to-Speech-Synthese. Die Kerninnovation liegt in der Verwendung reiner Sprachmodellierungsmethoden zur Generierung hochwertiger Sprache, ohne auf komplexe Adapter oder externe Module herkömmlicher TTS-Systeme angewiesen zu sein. Zu den Hauptfunktionen gehören Text-to-Speech-Synthese und Stimmklonierung.
Online ausführen:https://go.hyper.ai/eQVHL
💡Wir haben außerdem eine Austauschgruppe für Tutorials zur stabilen Diffusion eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~

Die Zeitungsempfehlung dieser Woche
1. GLM-4.1V-Denken: Auf dem Weg zu vielseitigem multimodalem Denken mit skalierbarem Verstärkungslernen
Dieses Papier stellt GLM-4.1V-Thinking vor, ein visuelles Sprachmodell (VLM), das das allgemeine multimodale Verständnis und Denken fördern soll. Wir schlagen eine Methode vor, die Reinforcement Learning mit Curriculum Sampling kombiniert, um das Potenzial des Modells voll auszuschöpfen und so umfassende Fähigkeiten für so unterschiedliche Aufgaben wie MINT-Problemlösung, Videoverständnis, Inhaltserkennung, Programmierung, Koreferenzauflösung, GUI-basierte Agenten und das Verständnis langer Dokumente zu erreichen. GLM-4.1V-9B-Thinking erreicht die höchste Leistung unter Open-Source-Modellen gleicher Größe und zeigt auch bei anspruchsvollen Aufgaben wie dem Verständnis langer Dokumente und MINT-Denken eine vergleichbare oder bessere Leistung als Closed-Source-Modelle wie GPT-4o.
Link zum Artikel:https://go.hyper.ai/5UuYG
2. Technischer Bericht zu Ovis-U1
Dieses Dokument stellt Ovis-U1 vor, ein einheitliches Modell mit 3 Milliarden Parametern, das multimodales Verständnis, Text-zu-Bild-Generierung und Bildbearbeitung integriert. Aufbauend auf den Grundlagen der Ovis-Familie kombiniert Ovis-U1 einen diffusen visuellen Decoder und einen bidirektionalen Tagging-Refiner und ist damit bei Bildgenerierungsaufgaben mit führenden Modellen wie GPT-4o vergleichbar. Ovis-U1 erreicht im multimodalen akademischen Benchmark von OpenCompass 69,6 Punkte und übertrifft damit aktuelle Spitzenmodelle wie Ristretto-3B und SAIL-VL-1.5-2B.
Link zum Artikel:https://go.hyper.ai/7Q8JV
3. BlenderFusion: 3D-basierte visuelle Bearbeitung und generatives Compositing
Dieses Dokument stellt BlenderFusion vor, ein Framework für generative visuelle Synthese, das neue Szenen durch die Neukombination von Objekten, Kameras und Hintergründen synthetisiert. Das Framework folgt einer Layer-Edit-Synthesis-Pipeline: Visuelle Eingaben werden segmentiert und in editierbare 3D-Objekte umgewandelt, mit 3D-basierten Steuerelementen in Blender bearbeitet und mithilfe eines generativen Compositors zu einer zusammenhängenden Szene verschmolzen. Experimentelle Ergebnisse zeigen, dass BlenderFusion bei komplexen Aufgaben zur Bearbeitung zusammengesetzter Szenen bisherige Methoden deutlich übertrifft.
Link zum Artikel:https://go.hyper.ai/YoirX
4. SciArena: Eine offene Evaluationsplattform für Grundlagenmodelle in wissenschaftlichen Literaturaufgaben
Dieses Dokument stellt SciArena vor, eine offene und kollaborative Plattform zur Bewertung von Basismodellen für wissenschaftliche Literaturaufgaben. Im Gegensatz zu herkömmlichen Benchmarks für das Verständnis und die Synthese wissenschaftlicher Literatur bezieht SciArena die Forschungsgemeinschaft direkt ein und verwendet eine ähnliche Bewertungsmethode wie Chatbot Arena, bei der Modelle durch Community-Voting verglichen werden. Derzeit unterstützt die Plattform 23 Open-Source- und proprietäre Basismodelle und hat über 13.000 Stimmen von renommierten Forschern aus verschiedenen wissenschaftlichen Bereichen erhalten.
Link zum Artikel:https://go.hyper.ai/oPbpP
5. SPIRAL: Selbstspiel bei Nullsummenspielen fördert das Denken durch Multi-Agent-Multi-Turn-Reinforcement-Learning
Dieser Artikel stellt SPIRAL vor, ein Selbstspiel-Framework, in dem Modelle durch mehrrunde Nullsummenspiele gegen sich selbst lernen, die sich kontinuierlich verbessern. Menschliche Überwachung ist dabei nicht erforderlich. Um groß angelegtes Selbstspiel-Training zu ermöglichen, implementierten die Forscher ein vollständig online verfügbares, mehrrundes, Multi-Agenten-Bestärkendes Lernsystem und schlugen eine rollenbedingte Vorteilsschätzung zur Stabilisierung des Multi-Agenten-Trainings vor. Selbstspiel-Training für Nullsummenspiele mit SPIRAL kann weit übertragbare Denkfähigkeiten hervorbringen.
Link zum Artikel:https://go.hyper.ai/n7J4m
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
Ein Forschungsteam der Virginia Tech und Meta AI schlug ein einheitliches Modell namens UNIMATE vor, das die wichtigsten Engpässe im aktuellen KI-Design von Metamaterialien durch eine innovative Modellarchitektur löst. Es ermöglicht zudem erstmals die einheitliche Modellierung und kollaborative Verarbeitung der drei Kernelemente des Metamaterialdesigns: dreidimensionale topologische Struktur, Dichtebedingungen und mechanische Eigenschaften.
Den vollständigen Bericht ansehen:https://go.hyper.ai/1x8iJ
Die Zhejiang-Universität hat in Zusammenarbeit mit Teams der University of Electronic Science and Technology of China und anderen Institutionen das HealthGPT-Modell vorgeschlagen. Mithilfe eines innovativen heterogenen Wissensadaptionsrahmens gelang es ihnen, das erste groß angelegte visuelle Sprachmodell zu entwickeln, das medizinisches multimodales Verständnis und Generierung vereint und damit einen neuen Weg für die Entwicklung medizinischer KI eröffnet. Die entsprechenden Ergebnisse wurden für ICML 2025 ausgewählt.
Den vollständigen Bericht ansehen:https://go.hyper.ai/F7W6a
In seiner Rede mit dem Titel „Aufbau und Anwendung eines intelligenten Protein-Computersystems“ erläuterte Professor Zhang Shugang von der Fakultät für Informatik der Ocean University of China systematisch die innovativen Durchbrüche der intelligenten Computertechnologie. Dabei konzentrierte er sich auf die traditionellen Herausforderungen der Proteinforschung und die Forschungsergebnisse des Teams in den Bereichen Funktionsannotation, Interaktionsidentifikation und Designoptimierung. Dieser Artikel ist eine Abschrift der Rede von Professor Zhang Shugang.
Den vollständigen Bericht ansehen:https://go.hyper.ai/rTgSi
Ein Team der Technischen Universität München und der Universität Zürich hat eine neue Methode zur Generierung von Satellitenbildern mit Stable Diffusion 3 (SD3) entwickelt, die auf geografischen Klimadaten basiert. Mit EcoMapper erstellte es den bislang größten und umfassendsten Fernerkundungsdatensatz. Der Datensatz umfasst über 2,9 Millionen RGB-Satellitenbilddaten von 104.424 Standorten weltweit von Sentinel-2, die 15 Landbedeckungstypen und entsprechende Klimadaten abdecken. Er bildet die Grundlage für zwei Methoden zur Generierung von Satellitenbildern mithilfe eines optimierten SD3-Modells.
Den vollständigen Bericht ansehen:https://go.hyper.ai/1zpeD
Science veröffentlichte einen Exklusivbericht, in dem es heißt, dass die Finanzierung von CASP durch die National Institutes of Health (NIH) erschöpft sei. Obwohl die University of California, Davis (UC Davis), die für die Verwaltung der Projektmittel zuständig ist, Notfallhilfe bereitgestellt habe, werde auch diese am 8. August erschöpft sein, und CASP stehe vor der Krise der Aussetzung.
Den vollständigen Bericht ansehen:https://go.hyper.ai/3kTMU
Beliebte Enzyklopädieartikel
1. KAN
2. Sigmoidfunktion
3. Mensch-Maschine-Schleife HITL
4. Retrieval-Verbesserung generiert RAG
5. Feinabstimmung der Verstärkung
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Juli-Frist für den Gipfel
11. Juli 7:59:59 POPL 2026
15. Juli 7:59:59 SODA 2026
18. Juli 7:59:59 SIGMOD 2026
19. Juli 7:59:59 ICSE 2026
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








