Command Palette
Search for a command to run...
Tutorial Inklusive: Neuer Durchbruch Im Medizinischen VLM! HealthGPT Erreicht Eine Genauigkeit Von 99,7% Beim Verständnis Komplexer MRT-Modalitäten, Und Ein Einzelnes Modell Kann Mehrere Generierungsaufgaben Bewältigen

Moderne medizinische Diagnose und Forschung sind in hohem Maße von der Interpretation und Generierung medizinischer Bilder abhängig. Von der Läsionsidentifikation im Röntgenbild bis zur Bildkonvertierung von MRT zu CT stellt jeder Schritt hohe Anforderungen an die multimodalen Verarbeitungsfähigkeiten von KI-Systemen. Die aktuelle Entwicklung medizinischer visueller Sprachmodelle (LVLMs) stößt jedoch auf zwei Engpässe:Die Besonderheit medizinischer Daten führt dazu, dass groß angelegte, qualitativ hochwertige annotierte Daten knapp sind.Die Größe öffentlich verfügbarer medizinischer Bilddatensätze beträgt in der Regel nur ein Zehntausendstel der allgemeinen Datensätze, was die Notwendigkeit, ein einheitliches Modell von Grund auf neu zu erstellen, kaum unterstützt. AndererseitsDer inhärente Widerspruch zwischen dem Verstehen und dem Generieren von Aufgaben ist schwer zu vereinbaren——Verständnisaufgaben erfordern eine abstrakte semantische Verallgemeinerung, während Generierungsaufgaben eine präzise Beibehaltung von Details erfordern. Herkömmliches Hybridtraining führt häufig zu Leistungseinbußen, da „eine Sache verloren geht, während man sich auf eine andere konzentriert“.
Aus technologischer Sicht konzentrierten sich frühe medizinische LVLMs wie Med-Flamingo und LLaVA-Med hauptsächlich auf visuelle Verständnisaufgaben und erreichten eine semantische Interpretation medizinischer Bilder durch Bild-Text-Ausrichtung, verfügten jedoch nicht über die Fähigkeit zur Generierung von Visualisierungen. Universelle einheitliche LVLMs wie Unified-IO 2 und Show-o bieten zwar Generierungsfunktionen, schneiden aber aufgrund unzureichender medizinischer Datenanpassung bei professionellen Aufgaben schlecht ab. Der Nobelpreis für Chemie 2024 wurde für Durchbrüche auf dem Gebiet der KI-Proteinstrukturvorhersage verliehen. Dies bestätigte indirekt das Potenzial von KI in den Biowissenschaften und machte der akademischen Gemeinschaft klar, dass die Entwicklung medizinischer LVLMs mit Verständnis- und Generierungsfähigkeiten der Schlüssel zur Überwindung des aktuellen Engpasses bei medizinischen KI-Anwendungen ist.
In diesem ZusammenhangDie Zhejiang-Universität und die Universität für elektronische Wissenschaft und Technologie Chinas haben gemeinsam das HealthGPT-Modell vorgeschlagen, durch ein innovatives heterogenes Wissensadaptionsframework,Erfolgreicher Aufbau des ersten groß angelegten visuellen Sprachmodells, das medizinisches multimodales Verständnis und Generierung vereint.Es hat einen neuen Weg für die Entwicklung medizinischer KI eröffnet und entsprechende Ergebnisse wurden für ICML 2025 ausgewählt.
Papieradresse:
Als Antwort auf die beiden größten Herausforderungen – Einschränkung der medizinischen Daten und Aufgabenkonflikte – schlug das Forschungsteam eine dreischichtige progressive Lösung vor:
Zunächst wird die heterogene Low-Rank-Adaption-Technologie (H-LoRA) entwickelt.Durch den Task-Gating-Entkopplungsmechanismus werden das Verständnis und das Generierungswissen in unabhängigen „Plugins“ gespeichert, wodurch das Konfliktproblem der herkömmlichen gemeinsamen Optimierung vermieden wird.
Zweitens: Entwicklung eines Rahmens für die hierarchische visuelle Wahrnehmung (HVP),Nutzen Sie die hierarchische Merkmalsextraktionsfunktion von Vision Transformer, um abstrakte semantische Merkmale zum Verständnis von Aufgaben bereitzustellen und detaillierte visuelle Merkmale für Generierungsaufgaben beizubehalten und so eine Merkmalsregulierung „auf Abruf“ zu erreichen.
Abschließend wird eine dreistufige Lernstrategie (TLS) konstruiert.Von der multimodalen Ausrichtung über die heterogene Plug-in-Fusion bis hin zur Feinabstimmung visueller Anweisungen wird das Modell schrittweise mit spezialisierten multimodalen Verarbeitungsfunktionen ausgestattet.
Datensatz: Multimodaler medizinischer Wissensgraph von VL-Health
Zur Unterstützung des HealthGPT-TrainingsDas Forschungsteam hat den ersten umfassenden VL-Health-Datensatz für medizinisches multimodales Verständnis und Generierung erstellt.Der Datensatz integriert 765.000 Beispiele für Verständnisaufgaben und 783.000 Beispiele für Generierungsaufgaben und deckt 11 medizinische Modalitäten (einschließlich CT, MRT, Röntgen, OCT usw.) und mehrere Krankheitsszenarien (von Lungenerkrankungen bis zu Hirntumoren) ab.
Datensatzadresse:
https://hyper.ai/cn/datasets/40990
Für Verständnisaufgaben integriert VL-Health professionelle Datensätze wie VQA-RAD (radiologische Fragen), SLAKE (Wissenserweiterung durch semantische Annotation) und PathVQA (Beantwortung pathologischer Fragen) und ergänzt umfangreiche multimodale Daten wie LLaVA-Med und PubMedVision, um sicherzustellen, dass das Modell die gesamte Fähigkeitskette von der einfachen Bilderkennung bis hin zu komplexen pathologischen Schlussfolgerungen erlernt. Die Generierungsaufgaben konzentrieren sich hauptsächlich auf vier Hauptbereiche: Modalitätskonvertierung, Superauflösung, Text-Bild-Generierung und Bildrekonstruktion:
* Modale Konvertierung:Basierend auf den CT-MRI-gepaarten Daten von SynthRAD2023 wird die Intermodalitätskonvertierungsfähigkeit des Modells trainiert;
* Superauflösung:Verwendung hochauflösender Gehirn-MRT aus dem IXI-Datensatz, um die Genauigkeit der Bilddetailrekonstruktion zu verbessern;
* Text-Bild-Generierung:Röntgenbilder und -berichte basierend auf MIMIC-CXR, wodurch die Generierung von der Textbeschreibung zum Bild realisiert wird;
* Bildrekonstruktion:Der LLaVA-558k-Datensatz wurde angepasst, um die Bildkodierungs- und -dekodierungsfunktionen des Modells zu trainieren.
Während der Datenverarbeitungsphase führte das Team eine standardisierte Vorverarbeitung medizinischer Bilder durch, darunter Schichtextraktion, Bildregistrierung und Datenverbesserung.Und vereinheitlichen Sie alle Beispiele im "Befehl-Antwort"-Format,Erleichtert die Einweisung nach dem Training des Modells.
Modellarchitektur: Vollständiges Kettendesign von der visuellen Wahrnehmung bis zur autoregressiven Generierung
HealthGPT verwendet eine mehrschichtige Architektur aus „visuellem Encoder-LLM-Kern-H-LoRA-Plug-In“, um eine effiziente Verarbeitung multimodaler Informationen zu erreichen:
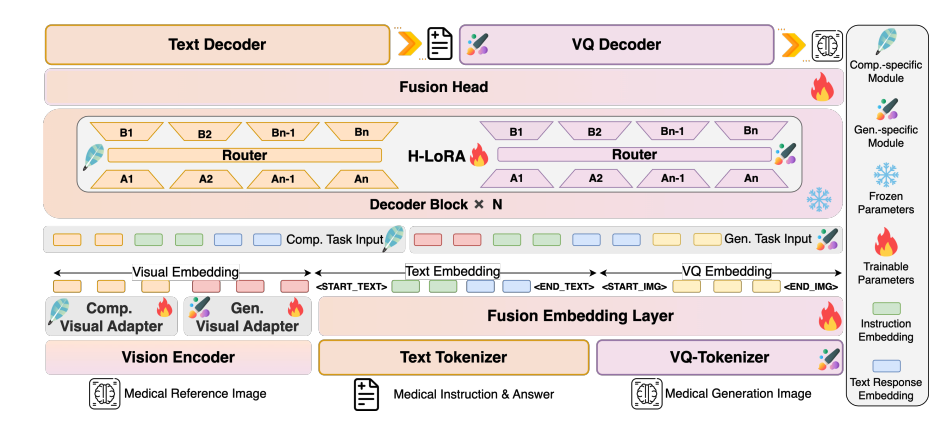
Modellarchitekturdiagramm
Visuelle Kodierungsebene: Hierarchische Merkmalsextraktion
CLIP-L/14 wird als visueller Encoder verwendet, um flache (zweite Ebene) und tiefe (vorletzte Ebene) Merkmale zu extrahieren. Flache Merkmale werden durch einen zweischichtigen MLP-Adapter in spezifische granulare Merkmale umgewandelt, um Bilddetails zu erhalten. Tiefe Merkmale werden vom Adapter in abstrakte granulare Merkmale umgewandelt, um semantische Konzepte zu erfassen. Dieser zweigleisige Merkmalsextraktionsmechanismus bietet eine adaptive visuelle Darstellung für nachfolgende Verständnis- und Generierungsaufgaben.
LLM-Kern: Allgemeine Wissensbasis
Basierend auf Phi-3-mini und Phi-4 werden zwei Modelle mit unterschiedlichen Parametern erstellt: HealthGPT-M3 (Modellparametervolumen beträgt 3,8 B) und HealthGPT-L14 (Modellparametervolumen beträgt 14 B). Der LLM-Kern ist nicht nur für das Verständnis und die Generierung von Text verantwortlich, sondern verarbeitet auch visuelle Token-Sequenzen einheitlich über einen autoregressiven Mechanismus – er gibt Textantworten für Verständnisaufgaben und VQGAN-Indexsequenzen für Generierungsaufgaben aus und rekonstruiert anschließend Bilder über den VQGAN-Decoder.
H-LoRA-Plugin: Missionsspezifischer Adapter
Fügen Sie das H-LoRA-Plug-in in jeden Transformer-Block von LLM ein. Es enthält zwei Arten von Untermodulen: Verständnis und Generierung. Jedes Untermodul enthält mehrere LoRA-Experten. Die selektive Aktivierung von Wissen erfolgt durch dynamisches Routing von Aufgabentypen und Eingabe verborgener Zustände. Das Plug-in wird mit den eingefrorenen Gewichten von LLM kombiniert, um einen hybriden Denkmodus aus „Allgemeinwissen + Aufgabenexpertise“ zu bilden.
Experimentelles Fazit: HealthGPT ist bei medizinischen visuellen Verständnis- und Generierungsaufgaben deutlich voraus
Die Mission verstehen: Führend in professionellen Fähigkeiten
Bei der medizinischen visuellen Verständnisaufgabe übertrifft HealthGPT bestehende Modelle deutlich. Ein Vergleich von HealthGPT mit anderen medizinspezifischen und allgemeinen Modellen (wie Med-Flamingo, LLA-VA-Med, HuatuoGPT-Vision, BLIP-2 usw.) zeigt, dassHealthGPT schneidet bei medizinischen visuellen Verständnisaufgaben gut ab und übertrifft andere medizinspezifische und allgemeine Modelle deutlich.
Im VQA-RAD-Datensatz erreichte HealthGPT-L14 eine Genauigkeit von 77,71 TP3T, eine Verbesserung um 29,11 TP3T gegenüber LLaVA-Med. Im OmniMedVQA-Benchmark-Test lag der Durchschnittswert bei 74,41 TP3T und das System erzielte die besten Ergebnisse in sechs der sieben Teilaufgaben, darunter CT, MRT und OCT. Insbesondere die Genauigkeit im Verständnis komplexer MRT-Modalitäten lag bei 99,71 TP3T und belegte damit das tiefe Verständnis hochkomplexer medizinischer Bilder.
Generierungsaufgaben: Durchbrüche bei der Modalitätskonvertierung und Superauflösung
Das Experiment mit generativen Aufgaben zeigt, dass HealthGPT bei der Konvertierung und Optimierung medizinischer Bilder gute Ergebnisse erzielt. Bei der Konvertierungsaufgabe CT-MRT erreichte der SSIM-Index von HealthGPT-M3 79,38 (Brain CT2MRI), was 11,61 TP3T höher ist als bei der herkömmlichen Methode Pix2Pix. Auch die Konvertierungsgenauigkeit in komplexen Bereichen wie dem Becken ist führend. Bei der Superauflösungsaufgabe erreichte der SSIM-Index 78,19 und der PSNR-Index 32,76 und übertraf damit SRGAN, DASR und andere dedizierte Modelle bei der Detailwiederherstellung, insbesondere bei der Feinrekonstruktion von Gehirnstrukturen.
Es ist erwähnenswert, dassHealthGPT kann mehrere Generierungsaufgaben in einem einzigen Modell verarbeiten.Herkömmliche Methoden erfordern das Trainieren unabhängiger Modelle für jede Teilaufgabe, was den Effizienzvorteil eines einheitlichen Frameworks unterstreicht.
Methodenvalidierung: Der Wert von H-LoRA und die Drei-Phasen-Strategie
Ablationsexperimente bestätigten die Notwendigkeit der Kerntechnologie: Nach dem Entfernen von H-LoRA verringerte sich die durchschnittliche Leistung der Verständnis- und Generierungsaufgaben um 18,71 TP3T; als anstelle der dreistufigen Strategie ein Hybridtraining gewählt wurde, verursachten Aufgabenkonflikte eine Leistungsverschlechterung von 23,41 TP3T.
Der Vergleich zwischen H-LoRA und MoELoRA zeigt, dass die Trainingszeit von H-LoRA bei Verwendung von vier Experten nur 671 TP3T beträgt, die Leistung jedoch um 5,21 TP3T verbessert ist. Dies belegt die Vorteile hinsichtlich Rechenleistung und Aufgabenerfüllung. Die Rolle der mehrschichtigen visuellen Wahrnehmung wurde ebenfalls bestätigt.Die Konvergenzgeschwindigkeit wird um 40% verbessert, wenn abstrakte Merkmale in der Verständnisaufgabe verwendet werden, und die Bildtreue wird um 25% verbessert, wenn spezifische Merkmale in der Generierungsaufgabe verwendet werden.
Potenzial für die klinische Anwendung: Eine Brücke von der Forschung zur Praxis
Im Human Evaluation-Experiment bewerteten fünf Kliniker die Antworten auf 1.000 offene Fragen blind.Der Anteil der HealthGPT-L14-Antworten, die als „beste Antworten“ ausgewählt wurden, erreichte 65,7%,Weit besser als LLaVA-Med (34.08%) und HuatuoGPT-Vision (21.94%).
derzeit,HyperAI Hyper.aiDas Tutorial „HealthGPT: AI Medical Assistant“ ist jetzt im Tutorial-Bereich verfügbar.Laden Sie einfach medizinische Bilder hoch und starten Sie ein Beratungsgespräch, das dem eines professionellen Arztes gleicht. Erleben Sie es selbst!
Link zum Tutorial:
Demolauf
1. Nachdem Sie die Homepage von hyper.ai aufgerufen haben, wählen Sie die Seite „Tutorials“, wählen Sie „HealthGPT: AI Medical Assistant“ und klicken Sie auf „Dieses Tutorial online ausführen“.

2. Klicken Sie nach dem Seitensprung oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
3. Wählen Sie die Bilder „NVIDIA RTX A6000“ und „PyTorch“ aus. Die OpenBayes-Plattform bietet vier Abrechnungsmethoden. Sie können je nach Bedarf zwischen „Pay-as-you-go“ oder „täglich/wöchentlich/monatlich“ wählen. Klicken Sie auf „Weiter“. Neue Benutzer können sich über den unten stehenden Einladungslink registrieren und erhalten 4 Stunden RTX 4090 + 5 Stunden CPU-freie Zeit!
Exklusiver Einladungslink von HyperAI (kopieren und im Browser öffnen):
https://openbayes.com/console/signup?r=Ada0322_NR0n
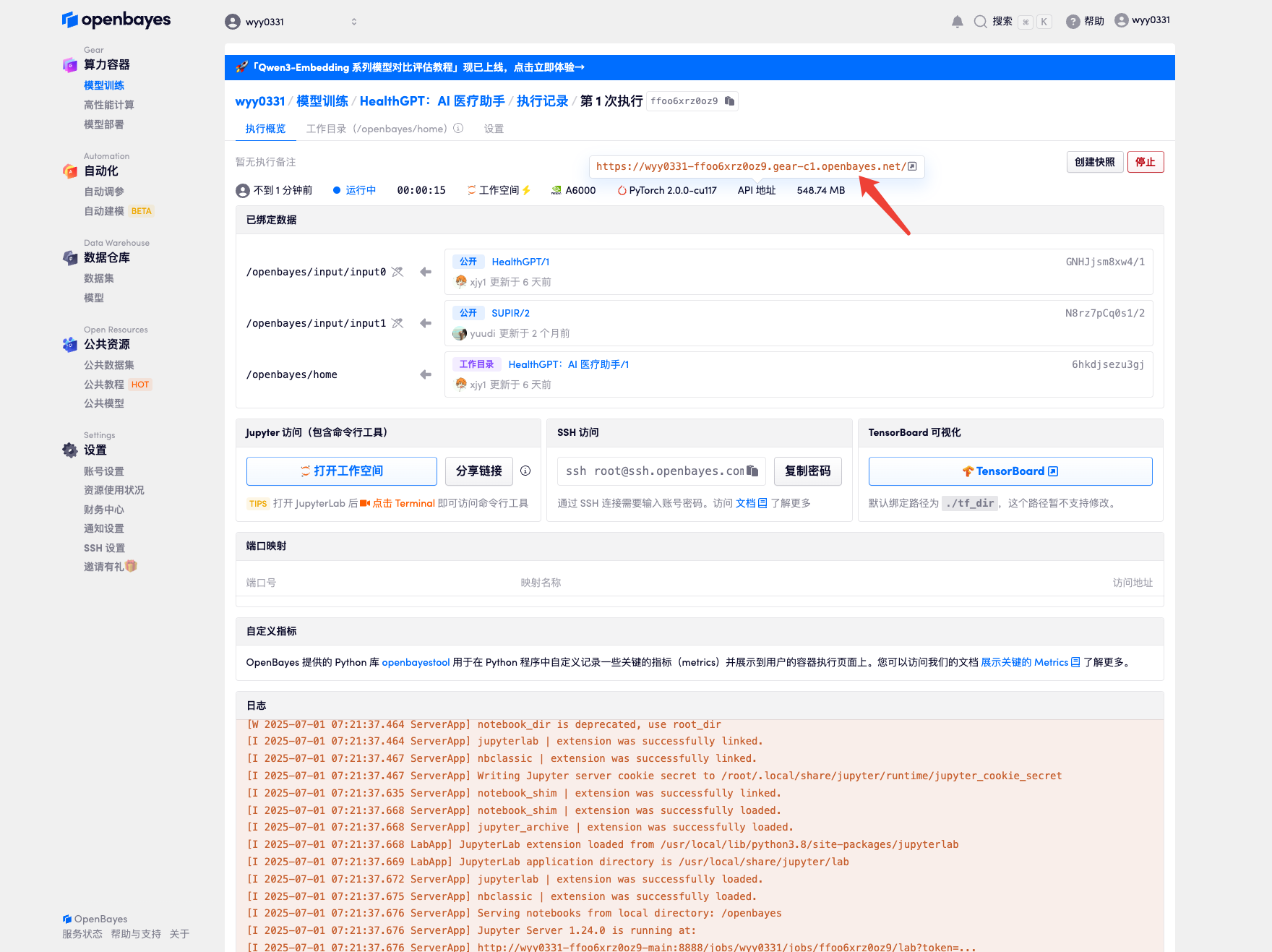
4. Warten Sie, bis die Ressourcen zugewiesen wurden. Der erste Klonvorgang dauert etwa 2 Minuten. Wenn sich der Status in „Läuft“ ändert, klicken Sie auf den Sprungpfeil neben „API-Adresse“, um zur Demoseite zu springen. Da das Modell groß ist, dauert es etwa 3 Minuten, bis die WebUI-Schnittstelle angezeigt wird, andernfalls wird „Bad Gateway“ angezeigt. Bitte beachten Sie, dass Benutzer vor der Verwendung der API-Adresszugriffsfunktion eine Echtnamenauthentifizierung durchführen müssen.
Effektdemonstration
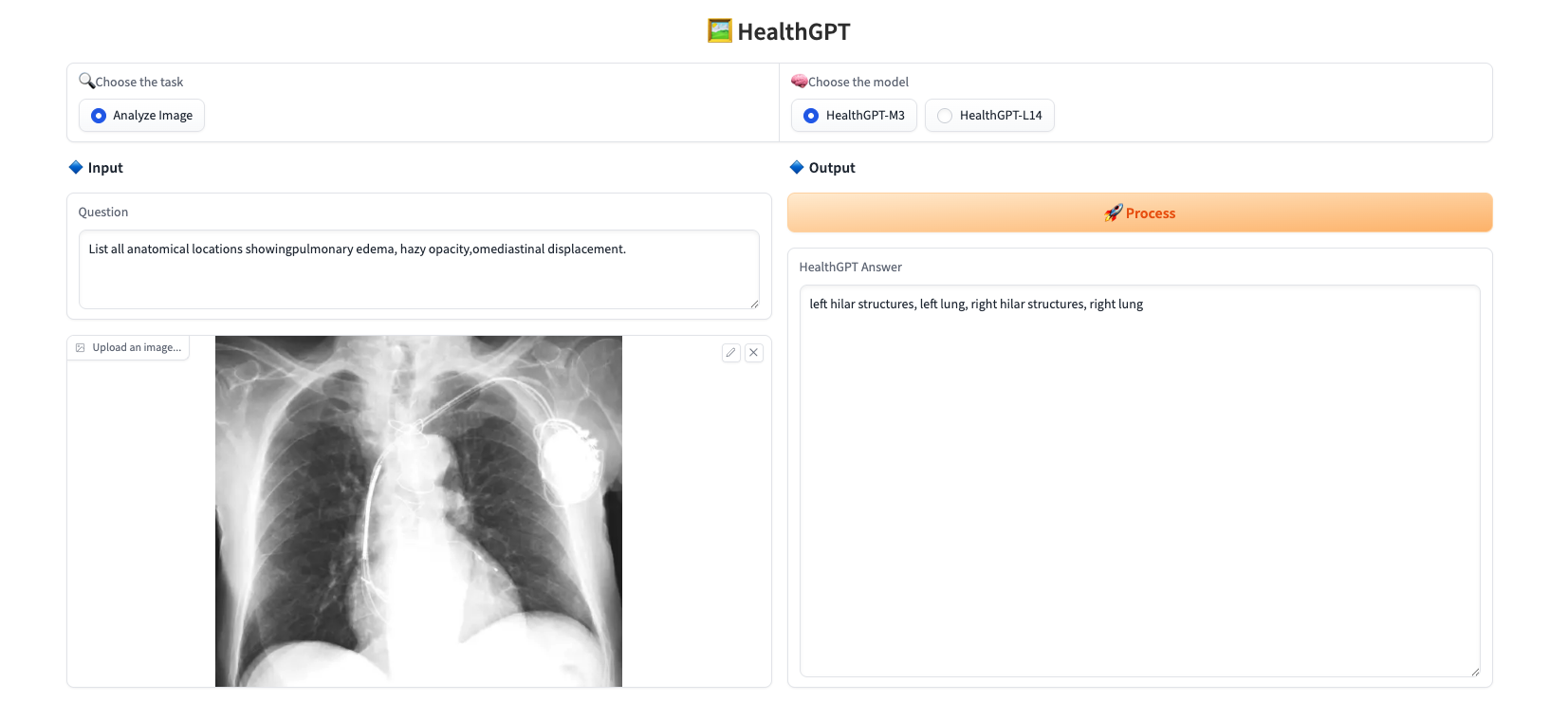
Laden Sie ein Bild hoch, geben Sie unter „Frage“ die gewünschte Frage ein, wählen Sie unter „Modell auswählen“ das Modell aus und klicken Sie auf „Bearbeiten“, um die Frage in Echtzeit zu beantworten. Dieses Projekt bietet zwei Modelle:
* HealthGPT-M3: Eine kleinere Version, optimiert für Geschwindigkeit und reduzierten Speicherverbrauch.
* HealthGPT-L14: Eine größere Version, die für höhere Leistung und komplexere Aufgaben entwickelt wurde.
Das Antwortbeispiel wird unten angezeigt:
Das obige Tutorial wird von HyperAI empfohlen. Interessierte Leser sind herzlich eingeladen, es auszuprobieren ⬇️
Link zum Tutorial:








