Command Palette
Search for a command to run...
Über 58.000 Sterne! RAGFlow Integriert Qwen3 Embedding Zur Einfachen Verarbeitung Komplexer Datenformate; Webclick Eröffnet Eine Neue Dimension Des Webseitenverständnisses
Das von Meta im Jahr 2020 vorgeschlagene RAG-Framework (Retrieval-Augmented Generation) verbessert effektiv die Genauigkeit und Zuverlässigkeit der LLM-Ausgabe. Die Technologie hat sich vom anfänglich einfachen Retrieval + Generierung zu einer fortgeschrittenen Form mit Agentenfunktionen wie Multi-Round-Argumentation, Tool-Nutzung und Kontextspeicher weiterentwickelt. Die meisten aktuellen RAG-Engines sind relativ einfach in der Dokumentenanalyse und basieren auf handelsüblicher Retrieval-Middleware, was zu einer geringen Retrievalgenauigkeit führt.
Darauf aufbauend verfügt InfiniFlow über RAGFlow, eine Open-Source-RAG-Engine, die auf tiefem Dokumentenverständnis basiert. Sie löst nicht nur die oben genannten Schwierigkeiten, sondern bietet auch einen vorgefertigten RAG-Workflow. Benutzer müssen den Prozess lediglich Schritt für Schritt befolgen, um schnell ein RAG-System aufzubauen.Nach der Integration mit Qwen3 Embedding ist es möglich, eine lokale Wissensdatenbank, ein intelligentes Frage-Antwort-System und einen Agenten aus einer Hand aufzubauen.
Derzeit wurde auf der offiziellen HyperAI-Website das Tutorial „Building a RAG System: Practice Based on Qwen3 Embedding“ veröffentlicht. Kommen Sie vorbei und probieren Sie es aus ~
Aufbau eines RAG-Systems: Praxis basierend auf Qwen3-Embedding
Online-Nutzung:https://go.hyper.ai/FFA7f
Vom 23. bis 27. Juni gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Hochwertige Tutorial-Auswahl: 6
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 3 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im Juli: 5
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
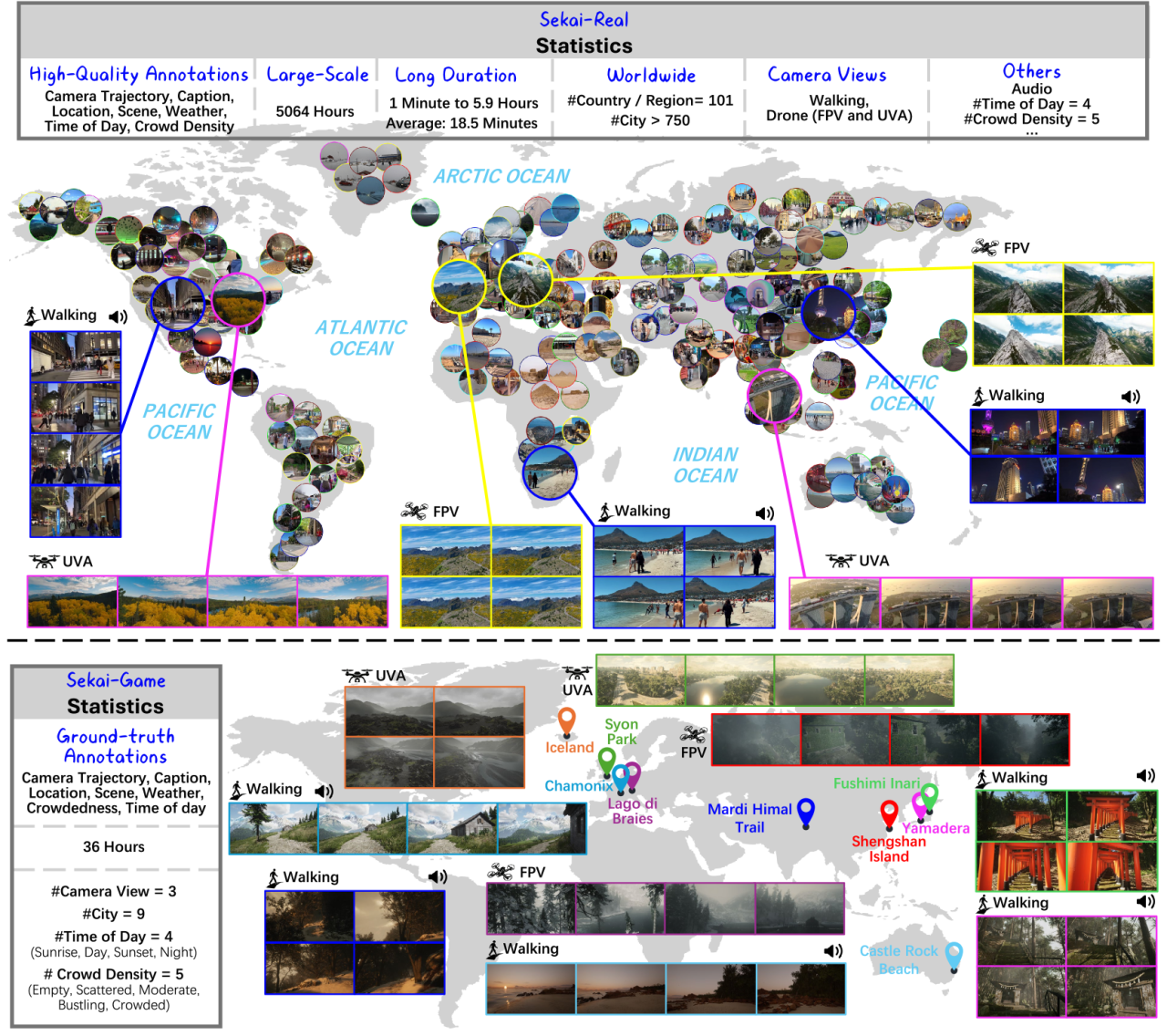
1. Sekai World Video-Datensatz
Sekai ist ein hochwertiger globaler Videodatensatz aus der Ich-Perspektive, der wertvolle Anwendungen in den Bereichen Videoproduktion und Welterkundung inspirieren soll. Der Datensatz konzentriert sich auf die egozentrische Welterkundung und besteht aus zwei Teilen: Sekai-Real und Sekai-Game. Er enthält über 5.000 Stunden Videos aus der Lauf- oder Drohnenperspektive aus über 100 Ländern und Regionen sowie 750 Städten.
Direkte Verwendung:https://go.hyper.ai/YyBKB
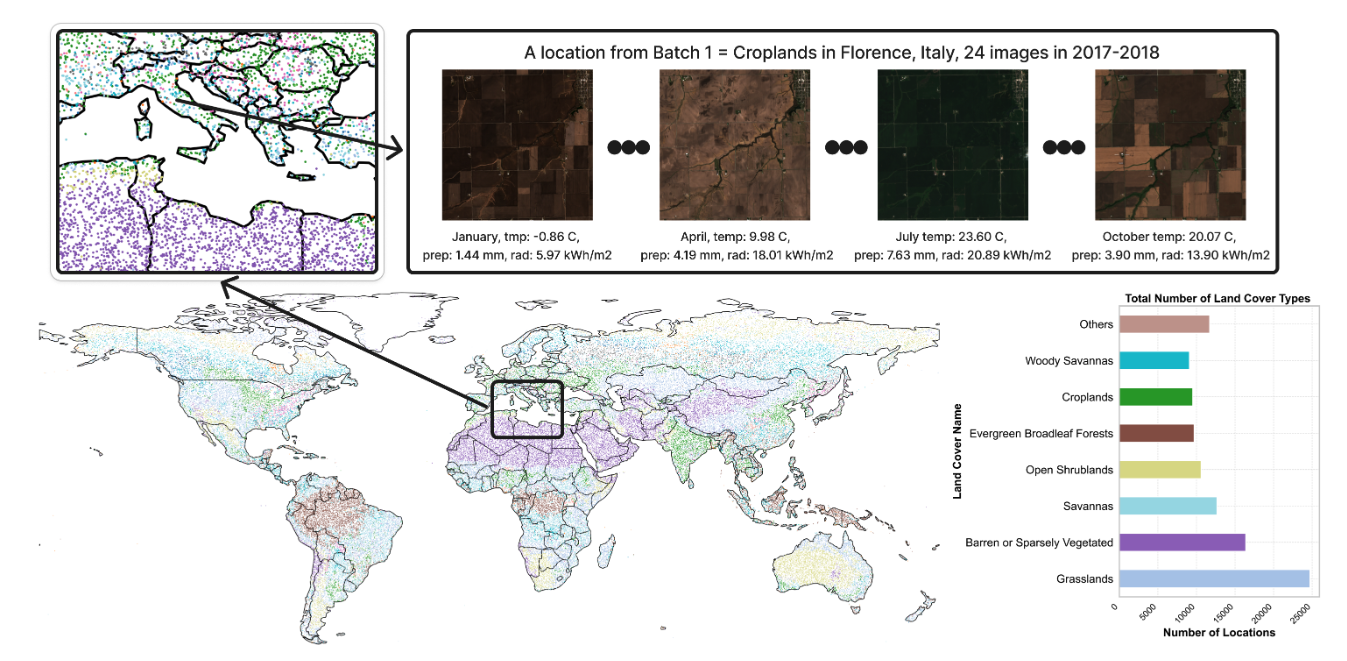
2. Ecomapper-Satellitenbilddatensatz
Der Datensatz enthält mehr als 2,9 Millionen Satellitenbilder, darunter RGB-Bilder und spezifische multispektrale Kanaldaten. Die Daten stammen von der Satellitenmission Copernicus Sentinel und decken verschiedene Landbedeckungsarten und mehrere Zeitpunkte ab. Der Trainingsdatensatz umfasst 98.930 verschiedene geografische Standorte, der Testdatensatz 5.494. Jeder Zeitstempel jedes Bildes wird von relevanten Wettermetadaten wie Temperatur, Sonneneinstrahlung und Niederschlagsinformationen begleitet.
Direkte Verwendung:https://go.hyper.ai/1u8s6
3. NuScenes-Datensatz zum autonomen Fahren
NuScenes ist ein öffentlicher Datensatz zum autonomen Fahren, der etwa 1,4 Millionen Kamerabilder, 390.000 Lidar-Scan-Bilder, 1,4 Millionen Radar-Scan-Bilder und 1,4 Millionen Objektbegrenzungsrahmen in 40.000 Keyframes aus Boston und Singapur enthält.
Direkte Verwendung:https://go.hyper.ai/rgw1k
4. Tahoe-100M-Einzelzellendatensatz
Tahoe‑100M ist der weltweit größte Einzelzelldatensatz. Er bietet eine realistische und strukturierte experimentelle Datengrundlage für große Sprachmodelle (LLMs) mit Interventionsverständnisfunktionen. Der Datensatz enthält über 100 Millionen Zellen, deckt über 60.000 molekulare Interventionsexperimente ab und bildet die Reaktionen von 50 Krebsmodellen auf über 1.100 Arzneimittelbehandlungen ab.
Direkte Verwendung:https://go.hyper.ai/Hfzva
5. Benchmark-Datensatz zum Verständnis von WebClick-Webseiten
WebClick ist ein hochwertiger Benchmark-Datensatz zum Verständnis von Webseiten. Er dient der Bewertung der Fähigkeit multimodaler Modelle und Agenten, Weboberflächen zu verstehen, Benutzerbefehle zu interpretieren und in digitalen Umgebungen präzise Aktionen auszuführen. Der Datensatz enthält 1.639 Screenshots von englischsprachigen Webseiten von über 100 Websites, ergänzt durch präzise annotierte Befehle in natürlicher Sprache und Klickziele auf Pixelebene.
Direkte Verwendung:https://go.hyper.ai/ezz46
6. DeepResearch Bench Deep Research Bench
DeepResearch Bench ist ein Benchmark-Datensatz für Deep-Research-Agenten, der die tatsächliche Verteilung des menschlichen Deep-Research-Bedarfs in verschiedenen Bereichen aufzeigen soll. Der Datensatz enthält 100 Forschungsaufgaben auf Doktorandenniveau, die jeweils sorgfältig von Experten aus 22 verschiedenen Bereichen erstellt wurden.
Direkte Verwendung:https://go.hyper.ai/yVHfH
7. SA-Text-Bildtextdatensatz
SA-Text ist ein umfangreicher Benchmark-Datensatz hochwertiger Szenenbilder, der für textbasierte Bildrestaurierungsaufgaben entwickelt wurde. Der Datensatz enthält 105.330 hochauflösende Szenenbilder mit Textanmerkungen auf Polygonebene, die die Position und Form des Textes im Bild präzise beschreiben. Dadurch kann das Modell die Position und Struktur des Textes im Bild besser verstehen.
Direkte Verwendung:https://go.hyper.ai/ICYIY
8. OCRBench-Texterkennungs-Benchmark-Datensatz
Der Datensatz enthält 1.000 manuell geprüfte und korrigierte Frage-Antwort-Paare aus fünf repräsentativen textbezogenen Aufgaben: Texterkennung, Szenentextzentrierung, Dokumentorientierung, Schlüsselinformationen und handschriftliche mathematische Ausdrücke.
Direkte Verwendung:https://go.hyper.ai/ZcKoD
9. Parse-PBMC-Einzelzell-RNA-Sequenzierungsdatensatz
Parse-PBMC ist ein Open-Source-Einzelzell-RNA-Sequenzierungsdatensatz, der in einem Experiment 10 Millionen Zellen aus 1.152 Proben analysiert und hauptsächlich zur Untersuchung der Genexpressionsmerkmale menschlicher peripherer mononukleärer Blutzellen unter verschiedenen Bedingungen verwendet wird.
Direkte Verwendung:https://go.hyper.ai/CwOMc
10. VIRESET-Videoinstanz-Bearbeitungsdatensatz
VIRESET bietet präzise Annotationsunterstützung für Aufgaben wie das Neuzeichnen von Videoinstanzen und die zeitliche Segmentierung. Der Datensatz enthält zwei Inhalte: SA-V-erweiterte Maskenannotation und 86.000 Videoclips.
Direkte Verwendung:https://go.hyper.ai/5hnGF
Ausgewählte öffentliche Tutorials
Diese Woche haben wir zwei Arten hochwertiger öffentlicher Tutorials zusammengestellt:
*Tutorials zur Bereitstellung großer Modelle: 3
* Tutorials zur Videogenerierung: 3
Große ModellbereitstellungLernprogramm
1. Aufbau eines RAG-Systems: Praxis basierend auf Qwen3-Embedding
RAGFlow ist eine Open-Source-RAG-Engine (Retrieval Augmented Generation), die auf tiefgreifendem Dokumentenverständnis basiert. In Kombination mit LLM bietet sie umfassende Frage-und-Antwort-Funktionen, unterstützt durch zuverlässige Referenzen aus Daten in verschiedenen komplexen Formaten.
Online ausführen:https://go.hyper.ai/FFA7f
2. Stellen Sie QwenLong-L1-32B mit vLLM+Open WebUI bereit
QwenLong-L1-32B ist das erste große Modell für Langtext-Argumentation basierend auf Reinforcement-Learning-Training. Es konzentriert sich auf die Lösung der Probleme von Gedächtnisschwäche und logischer Verwirrung, die bei herkömmlichen großen Modellen bei der Verarbeitung extrem langer Kontexte (z. B. 120.000 Token) auftreten. Es durchbricht die kontextuellen Einschränkungen herkömmlicher großer Modelle und bietet eine kostengünstige, leistungsstarke Lösung für hochpräzise Szenarien wie Finanzen und Recht.
Online ausführen:https://go.hyper.ai/f73C2
3. vLLM+Open WebUI-Bereitstellung Magistral-Small-2506
Magistral-Small-2506 basiert auf Mistral Small 3.1 (2503) mit erweiterten Reasoning-Funktionen, SFT durch Magistral Medium Tracking und Reinforcement Learning. Es handelt sich um ein kleines und effizientes Reasoning-Modell mit 24 Milliarden Parametern, das Long-Chain-Reasoning-Tracking ermöglicht, bevor es Antworten liefert, um komplexe Probleme besser zu verstehen und zu bewältigen und so die Genauigkeit und Rationalität der Antworten zu verbessern.
Online ausführen:https://go.hyper.ai/yLeoh
Tutorial zur Videoerstellung
1. MAGI-1: Das weltweit erste groß angelegte autoregressive Videogenerierungsmodell
Magi-1 ist das weltweit erste groß angelegte autoregressive Videogenerierungsmodell. Es generiert Videos durch autoregressive Vorhersage einer Reihe von Videoblöcken, definiert als Segmente aufeinanderfolgender Frames mit fester Länge. Es erzielt eine hohe Leistung bei Bild-zu-Video-Aufgaben, die auf Textanweisungen basieren, und bietet hohe zeitliche Konsistenz und Skalierbarkeit.
Online ausführen:https://go.hyper.ai/NZ6cc
2. FramePackLoop: Open-Source-Tool zur nahtlosen Video-Looping-Erstellung
FramePackLoop ist ein Tool zur automatisierten Bildsequenzverarbeitung und Loop-Generierung, das die Arbeitsabläufe in der Videoproduktion vereinfacht. Das Tool nutzt eine modulare Architektur für Bildsequenz-Packung, zeitliche Ausrichtung und nahtlose Loop-Synthese. Es kombiniert optische Flussschätzung mit aufmerksamkeitsbasierter zeitlicher Modellierung, um die Kohärenz der Bewegung zwischen den Bildern zu gewährleisten.
Online ausführen:https://go.hyper.ai/WIRoM
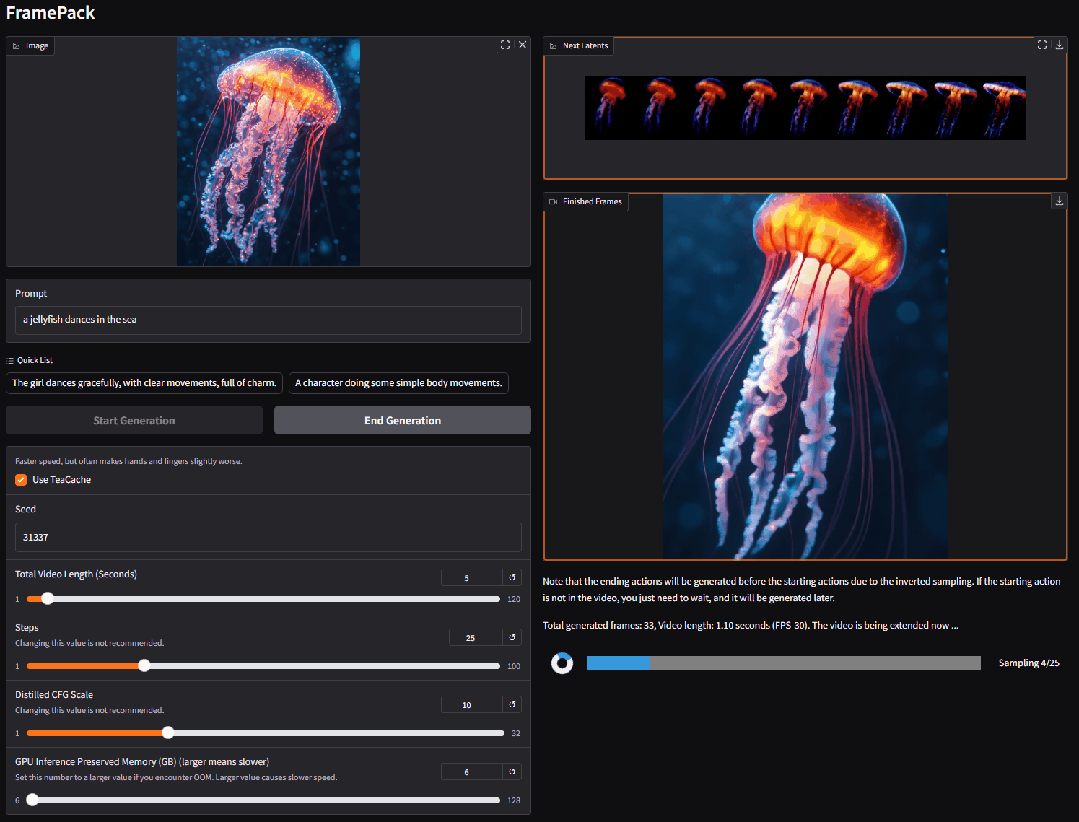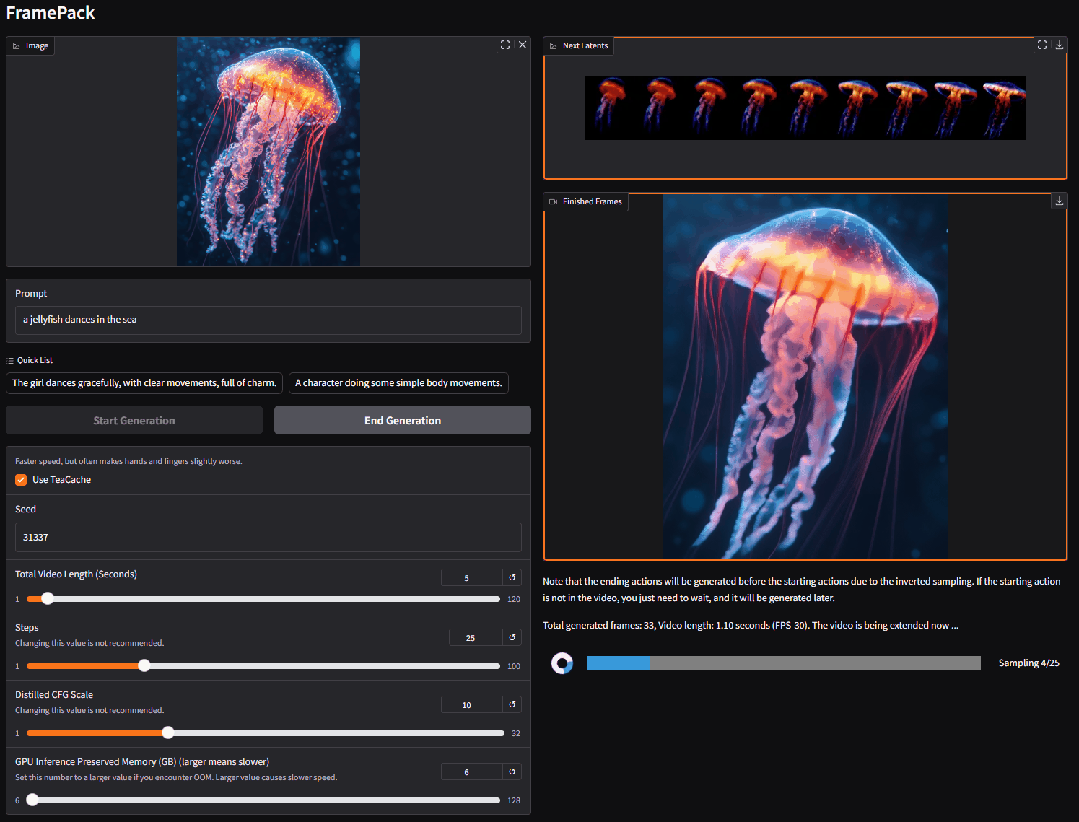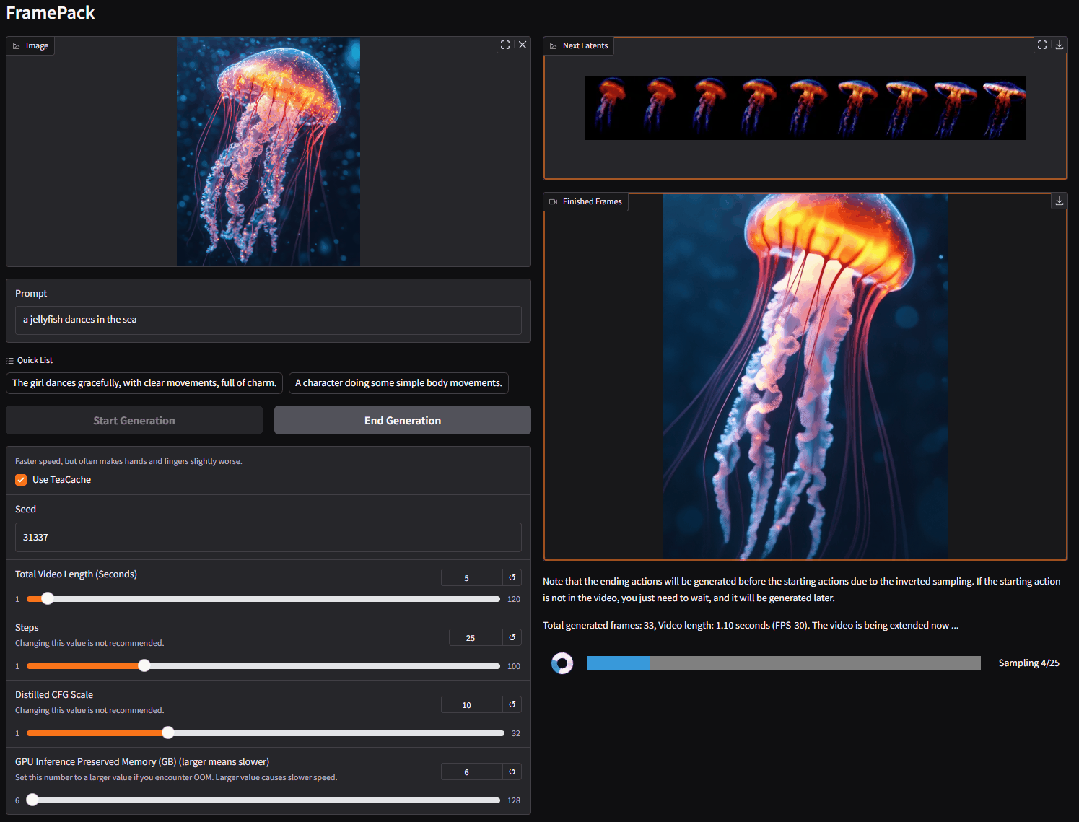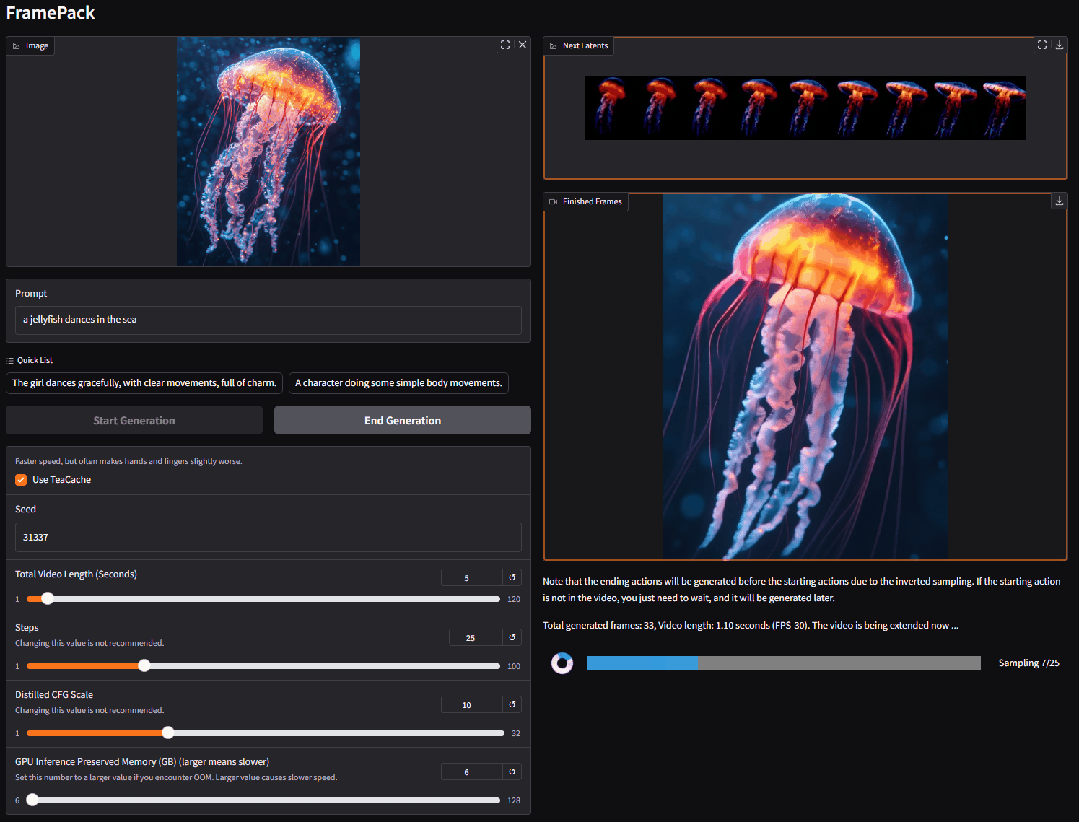
3. VIRES: Skizzen- und Text-geführtes Video-Neuzeichnen
VIRES ist eine Methode zum Neuzeichnen von Videoinstanzen, die Skizzen und Textführung kombiniert und verschiedene Bearbeitungsvorgänge wie das Neuzeichnen, Ersetzen, Generieren und Entfernen von Videoobjekten unterstützt. Diese Methode nutzt das Vorwissen textgenerierter Videomodelle, um die zeitliche Konsistenz sicherzustellen. Experimentelle Ergebnisse zeigen, dass VIRES in vielen Aspekten, darunter Videoqualität, zeitliche Konsistenz, bedingte Ausrichtung und Benutzerbewertungen, gute Ergebnisse liefert.
Online ausführen:https://go.hyper.ai/GeZxZ

💡Wir haben außerdem eine Austauschgruppe für Tutorials zur stabilen Diffusion eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~

Die Zeitungsempfehlung dieser Woche
1. Drag-and-Drop-LLMs: Zero-Shot-Prompt-to-Weights
Dieses Dokument stellt Drag-n-Drop Large Language Models (DnD) vor, einen promptbasierten Parametergenerator, der das Training pro Task überflüssig macht, indem er eine kleine Anzahl unbeschrifteter Task-Prompts direkt auf LoRA-Gewichtsaktualisierungen abbildet. Ein leichtgewichtiger Textencoder verfeinert jeden Prompt-Batch in bedingte Einbettungen, die dann von einem kaskadierten Hyperkonvolutionsdecoder in einen vollständigen Satz von LoRA-Matrizen umgewandelt werden.
Link zum Artikel:https://go.hyper.ai/hAO8y
2. Licht der Normalen: Einheitliche Merkmalsdarstellung für universelles photometrisches Stereo
In dieser Arbeit schlagen wir eine neuartige Universal Photometric Stereo (UniPS)-Methode vor, um das Problem der Wiederherstellung hochpräziser Oberflächennormalen unter beliebigen Lichtbedingungen zu lösen. Experimentelle Ergebnisse zeigen, dass LINO-UniPS in öffentlichen Benchmarks die Leistung bestehender, hochmoderner Universal Photometric Stereo-Methoden übertrifft und starke Generalisierungsmöglichkeiten für unterschiedliche Materialeigenschaften und Beleuchtungsszenarien aufweist.
Link zum Artikel:https://go.hyper.ai/oTFMo
3. Vision-geführtes Chunking ist alles, was Sie brauchen: Verbesserung von RAG durch multimodales Dokumentenverständnis
Dieses Dokument schlägt eine neuartige multimodale Methode zur Dokumenten-Chunking-Methode vor. Diese nutzt große multimodale Modelle (LMMs) zur Stapelverarbeitung von PDF-Dokumenten unter Wahrung semantischer Kohärenz und struktureller Integrität. Die Methode verarbeitet Dokumente in konfigurierbaren Seitenstapeln und bewahrt Kontextinformationen über alle Stapel hinweg. Dies ermöglicht die präzise Verarbeitung von Tabellen, eingebetteten visuellen Elementen und seitenübergreifenden Verfahrensinhalten.
Link zum Artikel:https://go.hyper.ai/IZA15
4. OmniGen2: Erkundung der fortschrittlichen multimodalen Stromerzeugung
Dieses Dokument stellt OmniGen2 vor, ein vielseitiges Open-Source-Generativmodell, das eine einheitliche Lösung für verschiedene Generativaufgaben bietet, darunter Text-zu-Bild-Generierung, Bildbearbeitung und Kontextgenerierung. Im Gegensatz zu OmniGen v1 entwickelt OmniGen2 zwei unabhängige Dekodierungspfade für Text- und Bildmodalitäten unter Verwendung nicht gemeinsam genutzter Parameter und separater Bild-Tokenizer. Dieses Design ermöglicht es OmniGen2, auf bestehenden multimodalen Verständnismodellen aufzubauen, ohne VAE-Eingaben neu anzupassen, wodurch die ursprünglichen Textgenerierungsfunktionen erhalten bleiben.
Link zum Artikel:https://go.hyper.ai/iCFzp
5. PAROAttention: Musterbewusste Neuordnung für effiziente spärliche und quantisierte Aufmerksamkeit in visuellen Generierungsmodellen
Dieses Dokument schlägt eine neue musterbasierte Tag-Neuordnungstechnik (PARO) vor, die verschiedene Aufmerksamkeitsmuster zu hardwarefreundlichen Blockmustern zusammenfasst. Diese Vereinheitlichung vereinfacht und verstärkt die Effekte von Sparsifizierung und Quantisierung erheblich. Mit dieser Methode erreicht PARO Attention die Video- und Bildgenerierung nahezu ohne Metrikverlust und erzielt nahezu dieselben Ergebnisse wie die vollpräzise Basislinie bei deutlich reduzierter Dichte und Bitbreite. Die End-to-End-Latenz wird um das 1,9- bis 2,7-Fache beschleunigt.
Link zum Artikel:https://go.hyper.ai/sScNH
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
Google DeepMind hat das AlphaGenome-Modell veröffentlicht, das Tausende molekulare Eigenschaften im Zusammenhang mit ihrer regulatorischen Aktivität vorhersagen und die Auswirkungen von Genvariationen oder -mutationen durch den Vergleich der Vorhersageergebnisse von varianten und nicht-varianten Sequenzen bewerten kann. Ein wichtiger Durchbruch von AlphaGenome ist die Fähigkeit, Spleißstellen direkt aus Sequenzen vorherzusagen und diese zur Vorhersage von Varianteneffekten zu nutzen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/o8E1F
Professor Li Dong, Direktor des Medical Data Science Center des Tsinghua Chang Gung Hospital, hielt auf der Beijing Zhiyuan Conference 2025 einen Sondervortrag zum Thema „Nutzung medizinischer Daten zur Durchführung innovativer Forschung im Zeitalter der intelligenten Gesundheitsversorgung“ und stellte dabei die Innovationen vor, die große Modelle im Zeitalter der intelligenten Gesundheitsversorgung mit sich bringen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/rAabv
Die gemeinnützige Forschungsorganisation Arc Institute hat in Zusammenarbeit mit Forschungsteams der UC Berkeley, Stanford und anderer Universitäten das virtuelle Zellmodell STATE entwickelt, das die Reaktion von Stammzellen, Krebszellen und Immunzellen auf Medikamente, Zytokine oder genetische Eingriffe vorhersagen kann. Experimentelle Ergebnisse zeigen, dass State die gängigen Methoden bei der Vorhersage von Transkriptomveränderungen nach Eingriffen deutlich übertrifft.
Den vollständigen Bericht ansehen:https://go.hyper.ai/B3Rc6
Beliebte Enzyklopädieartikel
1. DALL-E
2. Reziproke Sortierfusion RRF
3. Pareto-Front
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kontrastives Lernen
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Juli-Frist für den Gipfel
2. Juli 7:59:59 VLDB 2026
11. Juli 7:59:59 POPL 2026
15. Juli 7:59:59 SODA 2026
18. Juli 7:59:59 SIGMOD 2026
19. Juli 7:59:59 ICSE 2026
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








