Command Palette
Search for a command to run...
Online-Tutorial: OpenAudio S1 Aktualisiert Das TTS-Modell SOTA Und Basiert Auf 2 Millionen Stunden Audiodaten, Um Emotionen Und Sprachdetails Zu verstehen.

In den letzten Jahren hat das TTS-Modell (Text-to-Speech) eine Weiterentwicklung von der Synthese verknüpfter Sprache zur Synthese statistischer Parameter und schließlich zum neuronalen Netzwerk-TTS (Neural TTS) durchlaufen. Auf technischer Ebene zeigt sich ein Trend zur End-to-End- und Modulfusion, und auf Anwendungsebene zeigt sich eine verbesserte Mehrsprachigkeit, hohe Natürlichkeit und umfassende emotionale Veränderungen.
Da TTS-Modelle in virtuellen Sprachassistenten, digitalen Menschen, KI-Synchronisation, intelligentem Kundenservice und anderen Bereichen weit verbreitet sind, steigt die Nachfrage der Branche nach Echtzeit-Feedback allmählich an.Dann kommt es zum Kompromiss zwischen Inferenzgeschwindigkeit und Modellparametern.Letzteres begrenzt in gewissem Maße die Bereitstellungskosten und Anwendungsszenarien des TTS-Modells.
In Anbetracht dessenFish Audio hat ein neues Open-Source-TTS-Modell auf den Markt gebracht: OpenAudio S1.Es umfasst zwei Versionen: OpenAudio-S1 und OpenAudio-S1-mini. Laut der offiziellen Dokumentation wurde OpenAudio S1 anhand eines umfangreichen Datensatzes von über 2 Millionen Stunden Audio trainiert. Das Team erweiterte die Modellparameter auf 4 Milliarden und führte einen selbst entwickelten Mechanismus zur Belohnungsmodellierung ein. Gleichzeitig wurde Reinforcement Learning basierend auf menschlichem Feedback (RLHF, unter Verwendung der GRPO-Methode) angewendet.
Auf dieser Grundlage eliminiert OpenAudio S1 erfolgreich die Artefakte und das falsche Vokabular, die durch Informationsverlust entstehen, wenn die meisten anderen Modelle rein semantische Modelle verwenden, und übertrifft somit frühere Modelle in Bezug auf Audioqualität, emotionalen Ausdruck und Sprecherähnlichkeit bei weitem.Mit nur 10 bis 30 Sekunden Sprachbeispieleingabe kann eine hochwertige TTS-Ausgabe generiert werden.Es liegt derzeit an der Spitze der HuggingFace TTS-Arena-V2-Rangliste für subjektive menschliche Bewertungen und erreicht bei Seed-TTS Eval eine niedrige CER (Zeichenfehlerrate) von etwa 0,4% und eine WER (Wortfehlerrate) von etwa 0,8%.
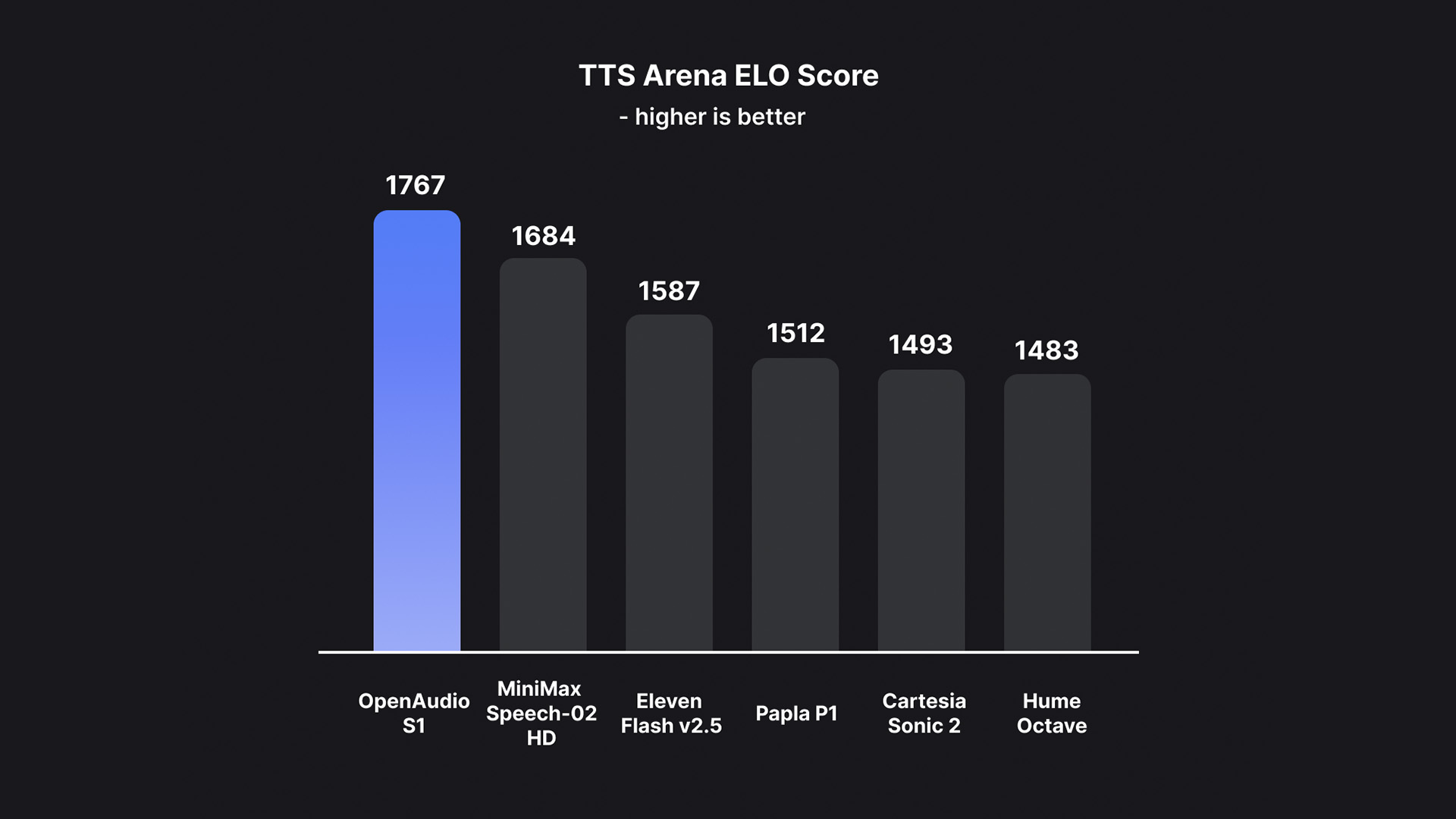
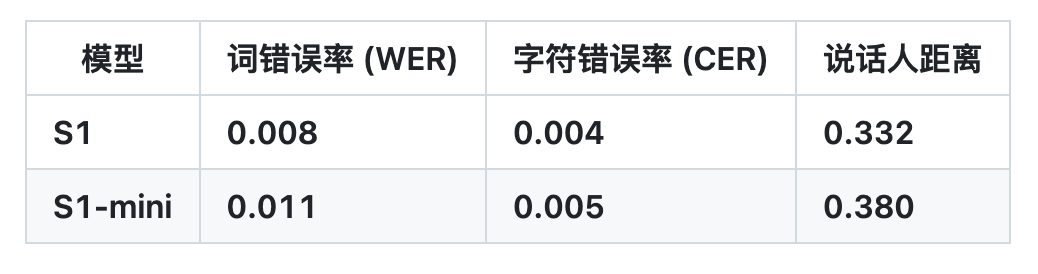
Laut dem TeamWas OpenAudio S1 wirklich einzigartig macht, ist seine Fähigkeit, menschliche Emotionen und Sprachdetails genau zu verstehen und auszudrücken.Es unterstützt eine Vielzahl von Tags für die präzise Steuerung synthetisierter Sprache. Um das TTS-Modell auf Anweisungen zu trainieren, entwickelte das Team außerdem ein Spracherkennungsmodell (das in Kürze veröffentlicht wird), das Untertitel für Audiodateien mit Emotionen, Betonung, Sprecherinformationen usw. generieren kann. Über 100.000 Stunden Audio wurden basierend auf diesem Modell zufällig annotiert, um OpenAudio S1 zu trainieren.
Aus diesem Grund unterstützt OpenAudio S1 verschiedene Emotionen, Betonungen und spezielle Markierungen zur Verbesserung der Sprachsynthese. Neben grundlegenden Emotionen wie Wut, Überraschung und Freude werden auch fortgeschrittene Emotionen wie Verachtung, Sarkasmus und Zögern unterstützt. In Bezug auf die Betonung unterstützt es Flüstern, Schreien, Schluchzen usw. Als Sprachen werden derzeit Englisch, Chinesisch und Japanisch unterstützt.
Erwähnenswerter ist, dass im Hinblick auf das Gleichgewicht zwischen Leistung und BereitstellungskostenDas Team behauptet, dies sei das erste SOTA-Modell, das nur 15 US-Dollar pro Million Bytes kostet ($15/Million Bytes, etwa 0,8 US-Dollar/Stunde).
Damit jeder die leistungsstarke Leistung von OpenAudio S1 schneller erleben kann,Im Tutorial-Bereich der offiziellen Website von HyperAI (hyper.ai) wurde jetzt „OpenAudio-s1-mini: Effizientes Tool zur Text-to-Speech-Generierung“ veröffentlicht.
Link zum Tutorial:https://go.hyper.ai/rVvkS
Für neu registrierte Nutzer bieten wir außerdem die kostenlose Nutzung der RTX 4090-Ressourcen an. Nutzen Sie den unten stehenden Einladungscode, um sich zu registrieren und hochwertige TTS-Modelle kostenlos zu testen.
Exklusiver Einladungslink von HyperAI (kopieren und im Browser öffnen):
https://openbayes.com/console/signup?r=Ada0322_NR0n
Demolauf
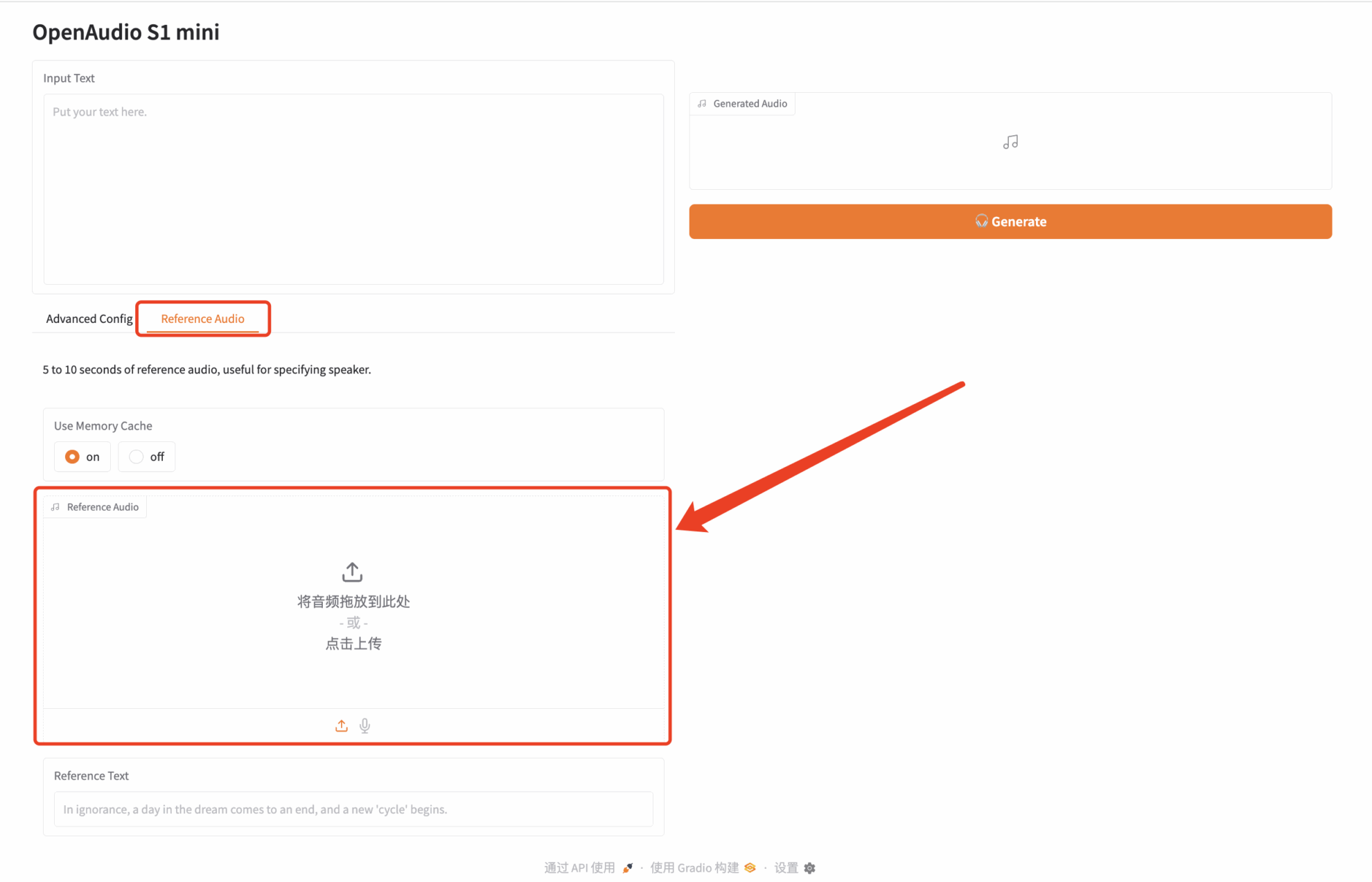
1. Nachdem Sie die Homepage von hyper.ai aufgerufen haben, wählen Sie die Seite „Tutorial“, wählen Sie „OpenAudio-s1-mini: Effizientes Tool zur Text-to-Speech-Generierung“ und klicken Sie auf „Dieses Tutorial online ausführen“.
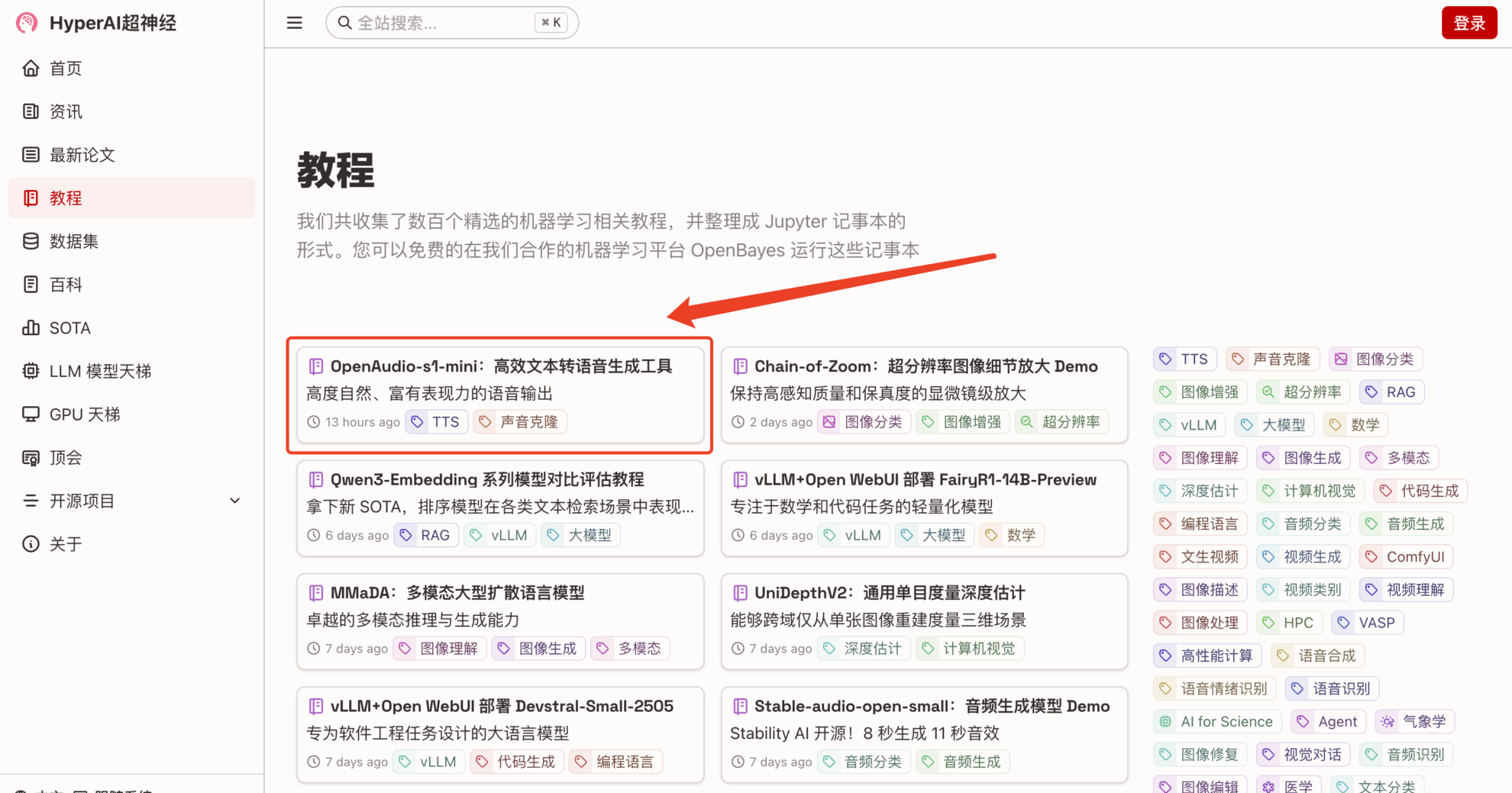
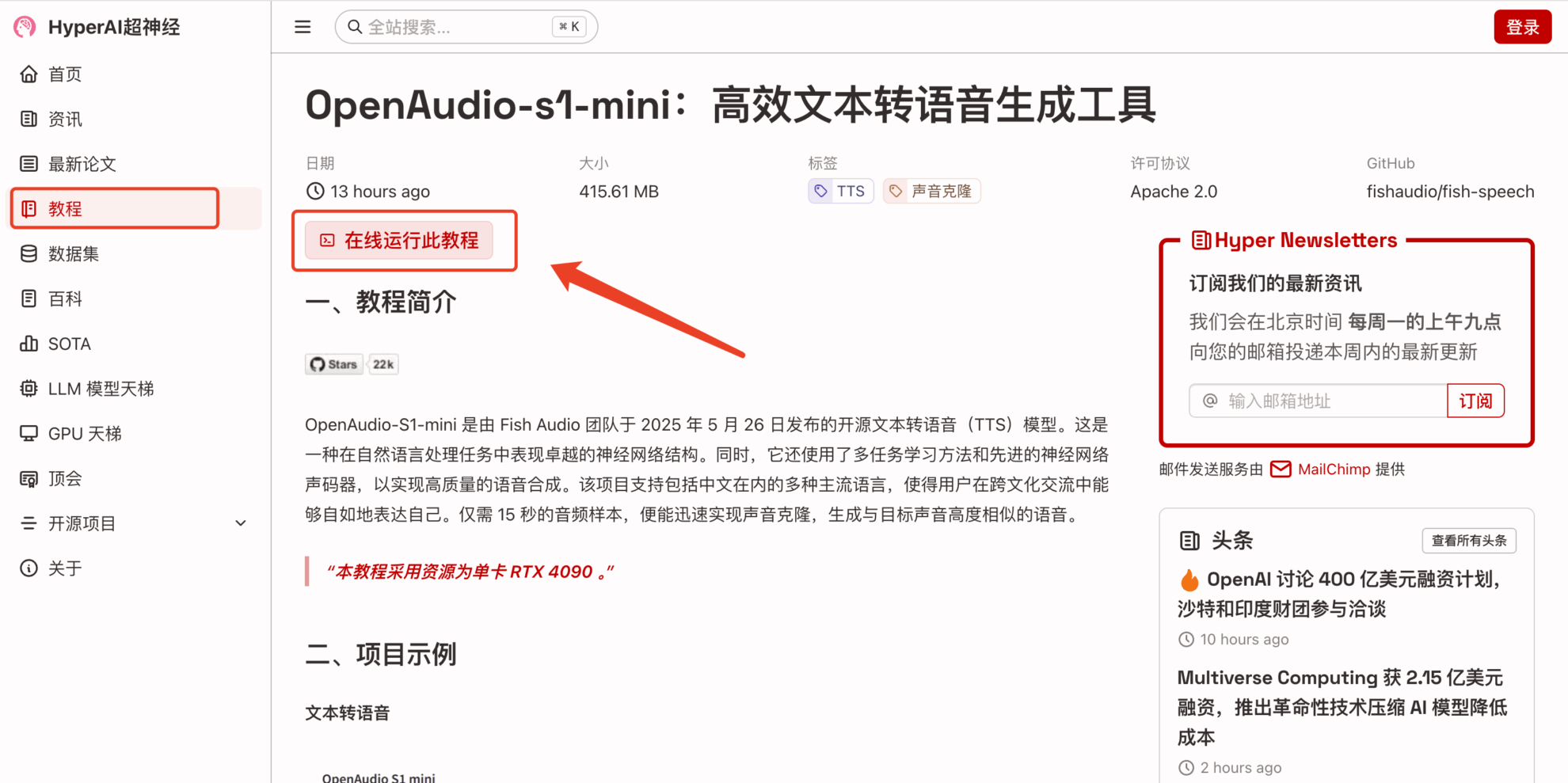
2. Klicken Sie nach dem Seitensprung oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
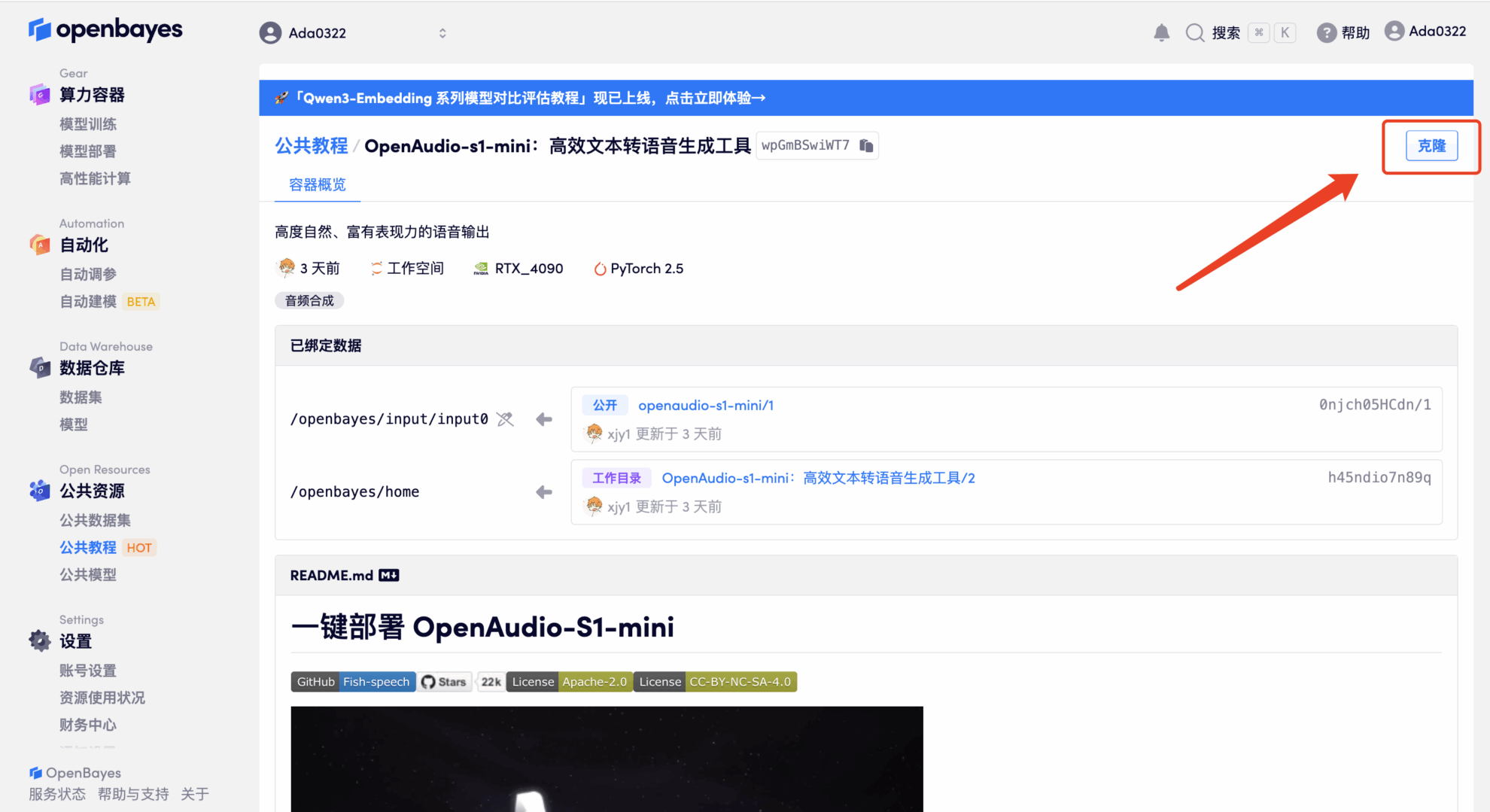
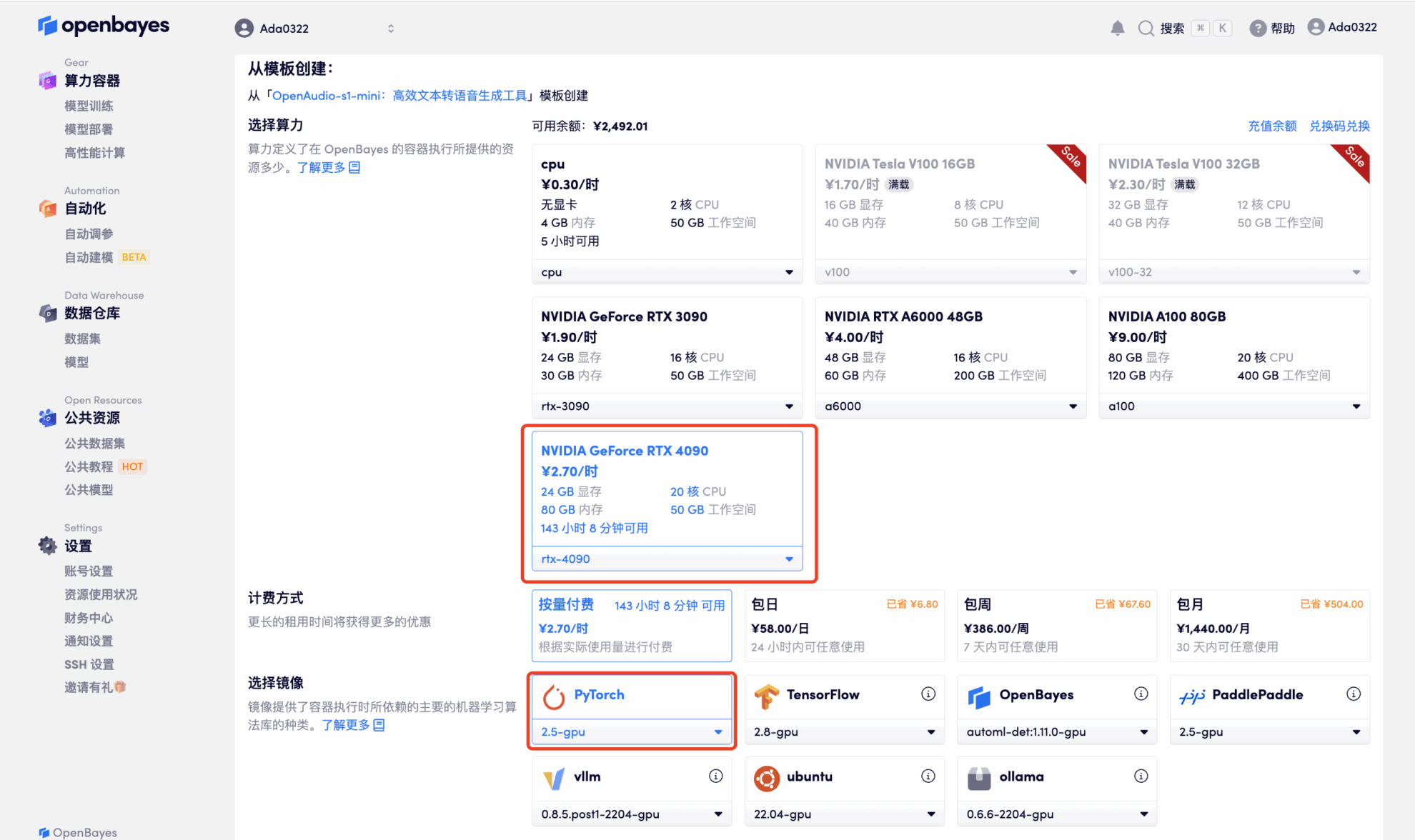
3. Wählen Sie die Bilder „NVIDIA RTX 4090“ und „PyTorch“ aus. Die OpenBayes-Plattform bietet vier Abrechnungsmethoden. Sie können je nach Bedarf zwischen „Pay as you go“ oder „Pay per day/week/month“ wählen. Klicken Sie auf „Weiter“. Neue Benutzer können sich über den unten stehenden Einladungslink registrieren und erhalten 4 Stunden RTX 4090 + 5 Stunden CPU-freie Zeit!
Exklusiver Einladungslink von HyperAI (kopieren und im Browser öffnen):
https://openbayes.com/console/signup?r=Ada0322_NR0n
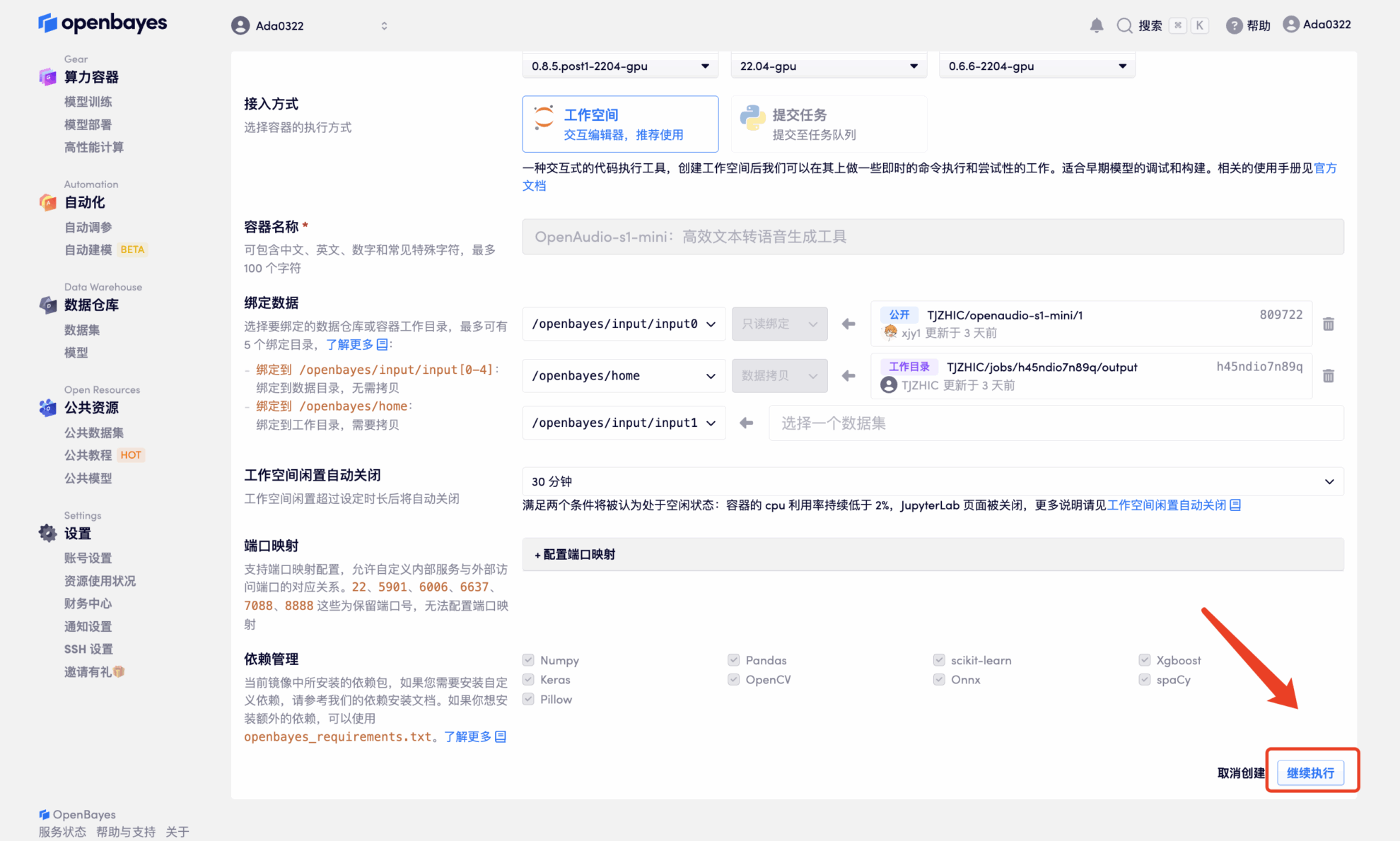
4. Warten Sie, bis die Ressourcen zugewiesen wurden. Der erste Klonvorgang dauert etwa 2 Minuten. Wenn sich der Status in „Läuft“ ändert, klicken Sie auf den Sprungpfeil neben „API-Adresse“, um zur Demoseite zu springen. Da das Modell groß ist, dauert es etwa 3 Minuten, bis die WebUI-Schnittstelle angezeigt wird, andernfalls wird „Bad Gateway“ angezeigt. Bitte beachten Sie, dass Benutzer vor der Verwendung der API-Adresszugriffsfunktion eine Echtnamenauthentifizierung durchführen müssen.
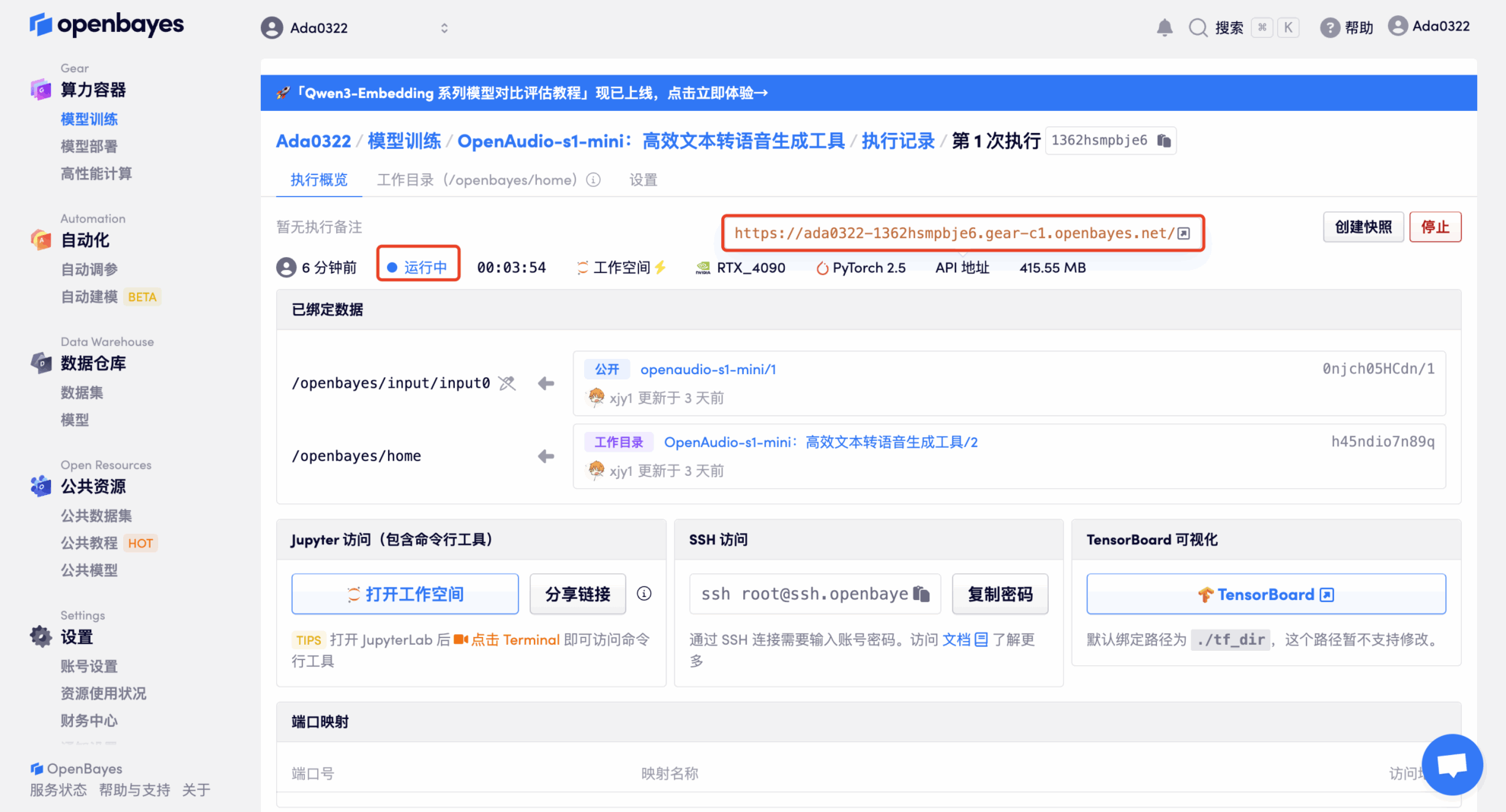
Effektdemonstration
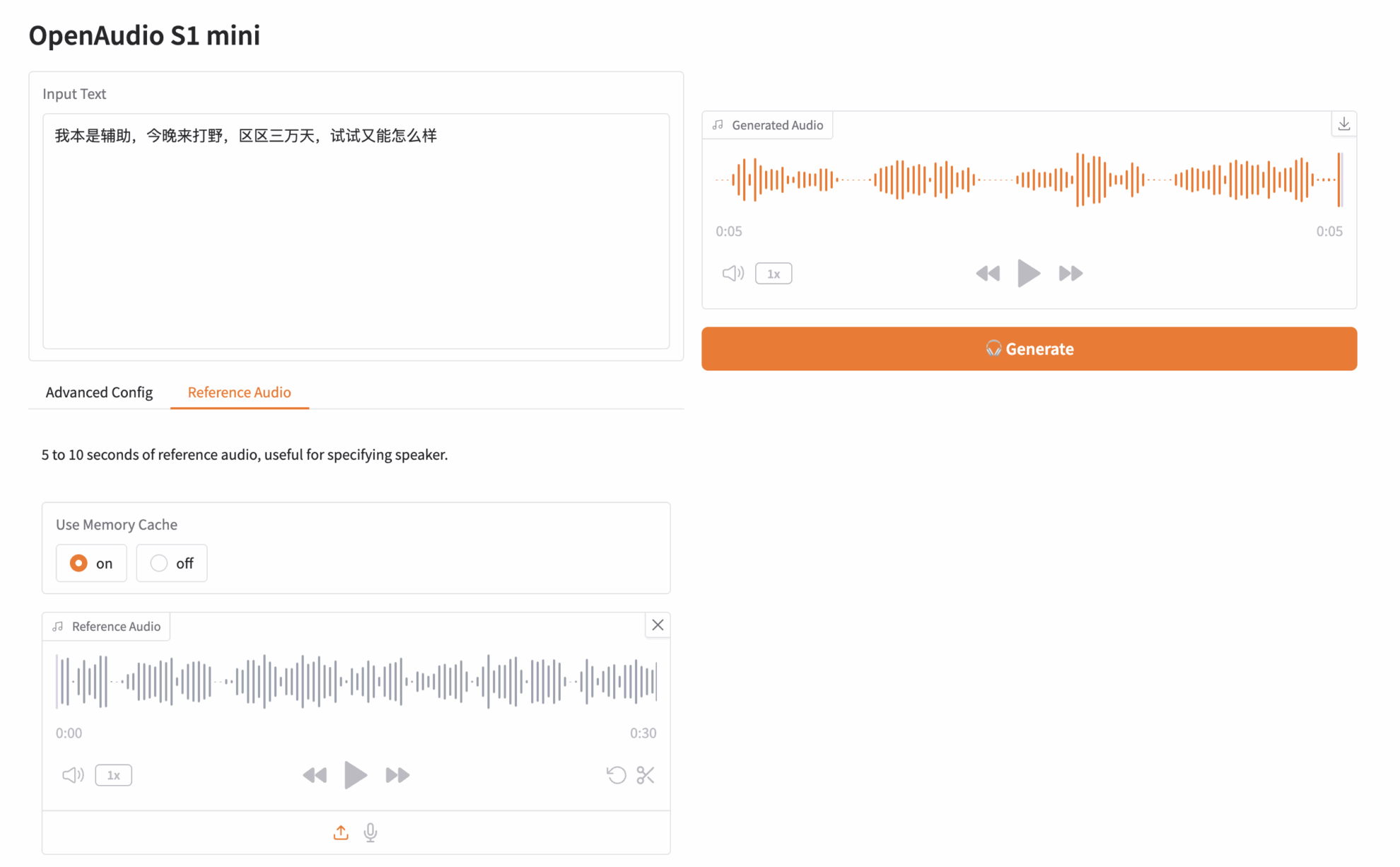
Klicken Sie auf „API-Adresse“, um das Modell zu testen. Ich habe einen Audioclip von „Paimon“, einer Figur aus Genshin Impact, hochgeladen. Der Eingabetext lautet wie folgt:
Ich war ursprünglich Support, bin aber heute Abend gekommen, um Jungle zu spielen. Es sind nur 30.000 Tage, also was spricht dagegen, es mal zu versuchen?
Klicken Sie dann rechts auf „Generieren“, um das Audio zu generieren:
Das obige Tutorial wird dieses Mal von HyperAI empfohlen. Sie können es gerne online ausprobieren:








