Command Palette
Search for a command to run...
Schluss Mit Code-Problemen! Seed-Coder Ermöglicht Effizientes Programmieren; Mixture-of-Thoughts Deckt Daten Aus Mehreren Domänen Ab Und Ermöglicht so Hochwertiges Denken.

Da der Wettbewerb um große Modelle immer härter wird und der Trend zu „Volumentechnologie und Skalierung“ anhält, ist die Frage, wie die tatsächliche Benutzerfreundlichkeit und die Aufgabenleistung des Modells verbessert werden können, zu einem immer wichtigeren Thema geworden. Die Programmierkenntnisse sind dabei ein wichtiger Indikator für die Benutzerfreundlichkeit und Aufgabenleistung großer Modelle. Darauf aufbauend hat das ByteDance Seed-Team ein leichtes, aber leistungsstarkes Open-Source-Code-Modell für große Sprachen veröffentlicht: Seed-Coder-8B-Instruct.
Dieses Modell ist eine optimierte Version der Seed-Coder-Reihe, die auf der Llama 3-Architektur basiert, über 8,2 B-Parameter verfügt und die Kontextverarbeitung mit einer maximalen Länge von 32.000 Token unterstützt.Seed-Coder-8B-Instruct Mit minimalem menschlichen Aufwand kann LLM die Code-Trainingsdaten effizient selbst verwalten und so die Programmierfähigkeiten deutlich verbessern. Durch die eigenständige Generierung und Prüfung hochwertiger Trainingsdaten kann die Fähigkeit zur Modellcodegenerierung erheblich verbessert werden.
Derzeit ist HyperAI Super Neural online 「vLLM+Open WebUI Deployment Seed-Coder-8B-Instruct", komm und probier es aus~
Online-Nutzung:https://go.hyper.ai/BnO32
Termin für die Live-Übertragung
Apples globale Konferenz WWDC25 findet am 10. Juni um 1 Uhr Pekinger Zeit statt. HyperAI Super Neural Video überträgt die Keynote in Echtzeit. Wenn Sie sie nicht verpassen möchten, vereinbaren Sie jetzt einen Termin!

Vom 3. bis 6. Juni gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Hochwertige Tutorials: 13
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 4 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im Juni: 2
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
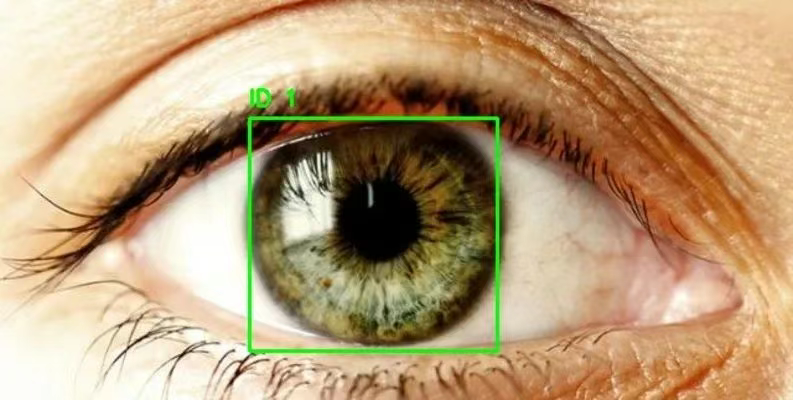
1. Datensatz zur Brillenerkennung mit Augenerkennung
Eye Detection ist ein Datensatz zur Augenerkennung, der fast 2.000 klar gekennzeichnete Bilder der Augenpartie enthält. Mit diesem Datensatz können Zielerkennungsmodelle wie RCNN und YOLO trainiert werden, um Augenpartien zu verfolgen und zu erkennen. Dieser Datensatz kann zum Erstellen von Modellen zur Katarakterkennung, Eye-Tracking-Modellen usw. verwendet werden.
Direkte Verwendung:https://go.hyper.ai/5IUPr
2. Yambda-Datensatz für Musikempfehlungen
Yambda-5B ist ein umfangreicher multimodaler Musikanalyse-Datensatz, der Trainings- und Evaluierungsressourcen für große Sprachmodelle (LLMs) wie Musikempfehlungen, Informationsabruf und Sortierung bereitstellt. Der Datensatz enthält 4,79 Milliarden Interaktionen (einschließlich Anhören, Liken und Nicht-Liken) und deckt 1 Million Benutzer und 9,39 Millionen Titel ab. Er ist derzeit einer der größten öffentlichen Musikempfehlungsdatensätze.
Direkte Verwendung:https://go.hyper.ai/VSL3J
3. 4x Satellitenbilddatensatz
Dieser Datensatz ist ein hochauflösender Satellitenbilddatensatz, der Paare von hochauflösenden (HR) und niedrig auflösenden (LR) Satellitenbildern enthält und für die Aufgabe der 4-fachen Superauflösung entwickelt wurde.
Direkte Verwendung:https://go.hyper.ai/TyCeW
4. MedXpertQA-Datensatz zur medizinischen Argumentation
Der Datensatz enthält 4.460 Beispieldaten, darunter Text- und Bilddaten, und deckt Aufgaben wie die Beantwortung medizinischer Fragen, klinische Diagnosen, Empfehlungen für Behandlungspläne und das Verständnis grundlegender medizinischer Kenntnisse ab. Es unterstützt die Erforschung und Entwicklung komplexer medizinischer Entscheidungsfindungsfähigkeiten und eignet sich für die Feinabstimmung und Bewertung mittelgroßer Modelle im medizinischen Bereich.
Direkte Verwendung:https://go.hyper.ai/YGW7J
5. Tiergeräusche Tiergeräusche-Datensatz
Der Datensatz enthält etwa 10.800 Beispiele und deckt Audiodaten von sieben Arten ab, darunter Vögel (wie Schwanzmeisen und Zebrafinken), Hunde, Nilflughunde, Riesenotter, Makaken und Killerwale. Jeder Audioinhalt ist 1–5 Sekunden lang und eignet sich für einfaches Modelltraining und schnelle Experimente.
Direkte Verwendung:https://go.hyper.ai/asUR4
6. GeMS-Datensatz zur chemischen Massenspektrometrie
Der Datensatz enthält Hunderte Millionen Massenspektren (darunter 2 Milliarden im GeMS-C1-Teilsatz), einschließlich strukturierter numerischer Daten (Masse-Ladungs-Verhältnis-Intensitätspaare von Massenspektren) und Metadaten (wie Spektralquellen, experimentelle Bedingungen usw.). Es handelt sich um einen der derzeit größten öffentlich verfügbaren Massenspektrometrie-Datensätze und kann das Training von Modellen im ultragroßen Maßstab unterstützen.
Direkte Verwendung:https://go.hyper.ai/yXI9M
7. DeepTheorem-Theorembeweisdatensatz
DeepTheorem ist ein mathematischer Datensatz, der die mathematischen Argumentationsfähigkeiten großer Sprachmodelle (LLMs) durch informelle Theorembeweise auf Basis natürlicher Sprache verbessern soll. Der Datensatz enthält 121.000 informelle Theoreme und Beweise auf IMO-Ebene aus verschiedenen mathematischen Bereichen. Jedes Theorem-Beweis-Paar ist streng annotiert.
Direkte Verwendung:https://go.hyper.ai/fjnad
8. SynLogic-Inferenzdatensatz
SynLogic zielt darauf ab, die logischen Denkfähigkeiten großer Sprachmodelle (LLMs) durch bestärkendes Lernen mit überprüfbaren Belohnungen zu verbessern. Der Datensatz enthält 35 verschiedene logische Denkaufgaben mit automatischer Verifizierung und eignet sich daher gut für das Training mit bestärkendem Lernen.
Direkte Verwendung:https://go.hyper.ai/iF5f2
9. Datensatz zum Denken nach Gedankenmischungen
Mixture-of-Thoughts ist ein multidomänenbasierter Datensatz, der hochwertige Denkprozesse aus drei Hauptbereichen integriert: Mathematik, Programmierung und Naturwissenschaften. Ziel ist es, große Sprachmodelle (LLMs) für schrittweises Denken zu trainieren. Jedes Beispiel in diesem Datensatz enthält ein Nachrichtenfeld, das den Denkprozess in Form mehrerer Dialogrunden speichert und das Modell beim Erlernen schrittweiser Deduktionsfähigkeiten unterstützt.
Direkte Verwendung:https://go.hyper.ai/7Qo2l
10. Llama-Nemotron-Inferenzdatensatz
Der Datensatz enthält etwa 22,06 Millionen mathematische Daten, etwa 10,10 Millionen Codedaten und den Rest aus Bereichen wie Naturwissenschaften und Unterricht. Die Daten werden gemeinsam von mehreren Modellen wie Llama-3.3-70B-Instruct, DeepSeek-R1 und Qwen-2.5 generiert und decken unterschiedliche Denkstile und Problemlösungspfade ab, um den vielfältigen Anforderungen des Trainings groß angelegter Modelle gerecht zu werden.
Direkte Verwendung:https://go.hyper.ai/4V52g
Ausgewählte öffentliche Tutorials
Diese Woche haben wir 4 Kategorien hochwertiger öffentlicher Tutorials zusammengefasst:
*KI für Wissenschafts-Tutorials: 4
* Tutorials zur Bildverarbeitung: 4
*Tutorials zur Codegenerierung: 3
*Tutorials zur Sprachinteraktion: 2
Tutorial: KI für die Wissenschaft
1. Aurora großformatiges atmosphärisches Basismodell Demo
Aurora reduziert den Rechenaufwand erheblich und übertrifft gleichzeitig bestehende operative Prognosesysteme. Dadurch wird ein breiter Zugang zu hochwertigen Klima- und Wetterinformationen ermöglicht. Aurora ist nachweislich etwa 5.000-mal schneller als das fortschrittlichste numerische Prognosesystem, IFS.
In diesem Tutorial wird eine A6000-Einzelkarte als Ressource verwendet. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um zur Weboberfläche zu gelangen.
Online ausführen:https://go.hyper.ai/416Xs
2. Bereitstellung des multimodalen medizinischen KI-Modells MedGemma-4b-it per Mausklick
MedGemma-4b-it ist ein multimodales medizinisches KI-Modell, das speziell für den medizinischen Bereich entwickelt wurde. Es handelt sich um eine befehlsoptimierte Version der MedGemma-Suite. Es verwendet den speziell vortrainierten SigLIP-Bildencoder und verarbeitet Daten anonymisierter medizinischer Bilder, darunter Röntgenaufnahmen des Brustkorbs, dermatologische Bilder, ophthalmologische Bilder und histopathologische Schnitte.
Dieses Tutorial verwendet eine einzelne RTX 4090-Karte als Ressource. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen.
Online ausführen:https://go.hyper.ai/31RKp
3. Bereitstellung des medizinischen Argumentationsmodells MedGemma-27b-text-it mit einem Klick
Der Schwerpunkt dieses Modells liegt auf der Verarbeitung klinischer Texte und eignet sich besonders gut für die Patiententriage und Entscheidungshilfe. Es liefert Ärzten schnelle und wertvolle Informationen zum Zustand der Patienten, um die Formulierung effizienter Behandlungspläne zu erleichtern.
Dieses Tutorial verwendet Dual-SIM-Ressourcen des A6000. Öffnen Sie den unten stehenden Link, um es mit einem Klick bereitzustellen.
Online ausführen:https://go.hyper.ai/2mDmF
4. vLLM+Open WebUI-Bereitstellung II-Medical-8B medizinisches Argumentationsmodell
Das Modell basiert auf dem Qwen/Qwen3-8B-Modell und optimiert die Modellleistung durch die Verwendung von SFT (überwachte Feinabstimmung) unter Verwendung eines medizinspezifischen Inferenzdatensatzes und das Training von DAPO (einer möglichen Optimierungsmethode) auf einem harten Inferenzdatensatz.
Die in diesem Tutorial verwendeten Rechenressourcen sind eine einzelne RTX 4090-Karte.
Online ausführen:https://go.hyper.ai/1Qvwo
Tutorial zur Bildverarbeitung
1. DreamO: ein einheitliches Framework zur Bildanpassung
Basierend auf der DiT-Architektur (Diffusion Transformer) integriert DreamO eine Vielzahl von Bildgenerierungsaufgaben, unterstützt komplexe Funktionen wie Kostümwechsel (IP), Gesichtswechsel (ID), Stilübertragung (Style), Kombination mehrerer Motive und realisiert die Steuerung mehrerer Bedingungen über ein einziges Modell.
Dieses Tutorial verwendet Ressourcen für eine einzelne Karte A6000.
Online ausführen:https://go.hyper.ai/zGGbh
2. BAGEL: Ein einheitliches Modell für multimodales Verständnis und Generierung
BAGEL-7B-MoT ist für die einheitliche Verarbeitung und Generierung multimodaler Daten wie Texte, Bilder und Videos konzipiert. BAGEL hat umfassende Fähigkeiten in multimodalen Aufgaben wie multimodalem Verständnis und Generierung, komplexer Argumentation und Bearbeitung, Weltmodellierung und Navigation bewiesen. Seine Hauptfunktionen sind visuelles Verständnis, Text-zu-Bild-Generierung, Bildbearbeitung usw.
Dieses Tutorial verwendet die Rechenressourcen der Dual-Card-A6000 und bietet zum Testen die Funktionen „Bildgenerierung“, „Bildgenerierung mit Think“, „Bildbearbeitung“, „Bildbearbeitung mit Think“ und „Bildverständnis“.
Online ausführen:https://go.hyper.ai/76cEZ

3. ComfyUI Flex.2-Vorschau-Workflow-Online-Tutorial
Flex.2-preview kann hochwertige Bilder basierend auf eingegebenen Textbeschreibungen generieren, unterstützt die Texteingabe von bis zu 512 Token und unterstützt das Verständnis komplexer Beschreibungen zur Generierung entsprechender Bildinhalte. Es unterstützt auch das Reparieren oder Ersetzen bestimmter Bildbereiche. Der Benutzer stellt das Reparaturbild und die Reparaturmaske bereit, und das Modell generiert neuen Bildinhalt im angegebenen Bereich.
Dieses Tutorial verwendet eine einzelne RTX 4090-Karte als Ressource und unterstützt nur englische Eingabeaufforderungen.
Online ausführen:https://go.hyper.ai/MH5qY
4. ComfyUI LanPaint Bildwiederherstellungs-Workflow-Tutorial
LanPaint ist ein Open-Source-Tool zur lokalen Bildwiederherstellung. Es nutzt eine innovative Schlussfolgerungsmethode, um sich ohne zusätzliches Training an eine Vielzahl stabiler Diffusionsmodelle (einschließlich benutzerdefinierter Modelle) anzupassen und so eine hochwertige Bildwiederherstellung zu erzielen. Im Vergleich zu herkömmlichen Methoden bietet LanPaint eine leichtere Lösung, die den Bedarf an Trainingsdaten und Rechenressourcen deutlich reduziert.
Dieses Tutorial verwendet eine einzelne RTX 4090-Karte. Sie können das Modell schnell klonen, indem Sie den unten stehenden Link öffnen.
Online ausführen:https://go.hyper.ai/QAuag
Tutorial zur Codegenerierung
1. vLLM+Open WebUI Deployment Seed-Coder-8B-Instruct
Seed-Coder-8B-Instruct ist ein schlankes, aber leistungsstarkes Open-Source-Codesprachenmodell. Es ist eine optimierte Version der Seed-Coder-Befehlsreihe. Mit minimalem Personalaufwand kann LLM Code-Trainingsdaten effektiv und selbstständig verwalten und so die Programmierfähigkeiten erheblich verbessern. Das Modell basiert auf der Llama-3-Architektur, verfügt über 8,2 B Parameter und unterstützt Kontexte mit 32.000 Token.
Die in diesem Tutorial verwendeten Rechenressourcen sind eine einzelne RTX 4090-Karte.
Online ausführen:https://go.hyper.ai/BnO32
2. Mellum-4b-base ist ein Modell, das für die Codevervollständigung entwickelt wurde
Mellum-4b-base ist für Aufgaben zum Verständnis, zur Generierung und zur Optimierung von Code konzipiert. Das Modell zeigt hervorragende Fähigkeiten im gesamten Softwareentwicklungsprozess und eignet sich für Szenarien wie KI-gestützte Programmierung, intelligente IDE-Integration, Entwicklung von Lerntools und Code-Recherche.
Dieses Tutorial verwendet eine einzelne RTX 4090-Karte als Ressource und das Modell wird nur zur Optimierung des Codes verwendet.
Online ausführen:https://go.hyper.ai/2iEWz
3. Ein-Klick-Bereitstellung von OpenCodeReasoning-Nemotron-32B
Dieses Modell ist ein leistungsstarkes Großsprachenmodell, das für die Code-Erkenntnis und -Generierung entwickelt wurde. Es ist die Flaggschiff-Version der OpenCodeReasoning (OCR)-Modellsuite und unterstützt eine Kontextlänge von 32.000 Token.
Die in diesem Tutorial verwendeten Rechenressourcen sind Dual-Card-A6000.
Online ausführen:https://go.hyper.ai/jhwYd
Tutorial zur Sprachinteraktion
1. VITA-1.5: Demo eines multimodalen Interaktionsmodells
ITA-1.5 ist ein multimodales Sprachmodell im großen Maßstab, das Sehen, Sprache und Sprechen integriert und darauf ausgelegt ist, visuelle und sprachliche Interaktion in Echtzeit auf einem ähnlichen Niveau wie GPT-4o zu ermöglichen. VITA-1.5 reduziert die Interaktionslatenz deutlich von 4 Sekunden auf 1,5 Sekunden und verbessert so das Benutzererlebnis deutlich.
Dieses Tutorial verwendet eine A6000 mit einer einzelnen Karte als Ressource. Derzeit unterstützt die KI-Interaktion nur Chinesisch und Englisch.
Online ausführen:https://go.hyper.ai/WTcdM
2. Kimi-Audio: KI soll Menschen verstehen
Kimi-Audio-7B-Instruct ist ein Open-Source-Audioinfrastrukturmodell, das verschiedene Audioverarbeitungsaufgaben in einem einheitlichen Framework bewältigen kann. Es unterstützt verschiedene Aufgaben wie automatische Spracherkennung (ASR), Audio-Frage-Antwort (AQA), automatische Audio-Untertitelung (AAC), Sprachemotionserkennung (SER), Klangereignis-/Szenenklassifizierung (SEC/ASC) und End-to-End-Sprachdialog.
Dieses Tutorial verwendet Ressourcen für eine einzelne Karte A6000.
Online ausführen:https://go.hyper.ai/UBRBP
Die Zeitungsempfehlung dieser Woche
1. Ein Grundlagenmodell für das Erdsystem
In diesem Dokument wird das Aurora-Modell vorgeschlagen, ein groß angelegtes Basismodell, das mit über einer Million Stunden unterschiedlicher geophysikalischer Daten trainiert wurde und bestehende operative Prognosesysteme in Bezug auf Luftqualität, Meereswellen, Zugbahnen tropischer Wirbelstürme und hochauflösende Wettervorhersagen übertrifft.
Link zum Artikel:https://go.hyper.ai/ibyij
2. Paper2Poster: Auf dem Weg zur multimodalen Posterautomatisierung aus wissenschaftlichen Artikeln
Die Erstellung von Postern für wissenschaftliche Arbeiten ist eine kritische und anspruchsvolle Aufgabe in der wissenschaftlichen Kommunikation. Sie erfordert die Komprimierung langer, verschachtelter Dokumente auf eine einzige Seite mit visuell stimmigem Inhalt. Um diese Herausforderung zu meistern, stellt diese Arbeit die erste Benchmark- und Messsuite für die Erstellung von Postern für wissenschaftliche Arbeiten vor, die eine 22-seitige Arbeit in ein finales, editierbares PPTX-Poster umwandeln kann.
Link zum Artikel:https://go.hyper.ai/Q4cQG
3. ProRL: Prolongiertes Reinforcement Learning erweitert die Grenzen des Denkens in großen Sprachmodellen
Ob Reinforcement Learning die Denkfähigkeit des Modells tatsächlich erweitert, ist noch umstritten. Dieses Papier schlägt eine neue Trainingsmethode, ProRL, vor, die KL-Divergenzkontrolle, Referenzrichtlinien-Reset und eine vielfältige Aufgabensuite kombiniert und neue Erkenntnisse für ein besseres Verständnis der Bedingungen liefert, unter denen Reinforcement Learning die Denkgrenzen von Sprachmodellen sinnvoll erweitert.
Link zum Artikel:https://go.hyper.ai/62DUb
4. Unüberwachtes Post-Training für multimodales LLM-Reasoning über GRPO
Diese Studie verwendet GRPO, einen stabilen und skalierbaren Online-Verstärkungslernalgorithmus, um eine kontinuierliche Selbstverbesserung ohne externe Überwachung zu erreichen, und schlägt MM-UPT vor, ein einfaches und effektives unbeaufsichtigtes Post-Training-Framework für multimodale große Sprachmodelle. Experimentelle Ergebnisse zeigen, dass MM-UPT die Denkfähigkeit von Qwen2.5-VL-7B signifikant verbessert.
Link zum Artikel:https://go.hyper.ai/W5nO5
5. Der Entropiemechanismus des bestärkenden Lernens für logische Sprachmodelle
Ziel dieser Arbeit ist es, ein großes Hindernis bei der Verwendung großer Sprachmodelle (LLMs) für das Reasoning im groß angelegten Reinforcement Learning (RL) zu überwinden: den Kollaps der Policy-Entropie. Zu diesem Zweck schlugen die Forscher zwei einfache und effektive Methoden vor: Clip-Cov und KL-Cov. Erstere schneidet Token mit hoher Kovarianz ab, während letztere eine KL-Strafe auf diese Token auferlegt. Experimentelle Ergebnisse zeigen, dass diese Methoden das Explorationsverhalten fördern und so dazu beitragen, dass die Policy dem Entropiekollaps entgeht und eine bessere Downstream-Performance erzielt.
Link zum Artikel:https://go.hyper.ai/rFSoq
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/UuE1o
Interpretation von Gemeinschaftsartikeln
Aufbauend auf den Durchbrüchen der GPT-Reihe im Bereich der Sprache hat ein Forschungsteam des Instituts für Organische Chemie und Biochemie der Tschechischen Akademie der Wissenschaften 700 Millionen MS/MS-Spektren aus dem Global Natural Products Social Molecular Network (GNPS) ausgewertet, erfolgreich den größten Massenspektrometrie-Datensatz der Geschichte, GeMS, erstellt und ein Transformer-Modell DreaMS mit 116 Millionen Parametern trainiert.
Den vollständigen Bericht ansehen:https://go.hyper.ai/P9qvl
Um Spitzenforschung besser mit Anwendungsszenarien zu verknüpfen, veranstaltet HyperAI am 5. Juli in Peking den 7. Meet AI Compiler Technology Salon. Wir haben das Glück, viele hochrangige Experten von AMD, der Peking-Universität, Muxi Integrated Circuit usw. eingeladen zu haben, um ihre Best Practices und Trendanalysen für KI-Compiler zu teilen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/FPxw2
Dr. Liang Haojian vom Institut für Weltrauminformationsinnovation der Chinesischen Akademie der Wissenschaften hielt auf der Akademischen Jahrestagung 2025 des Fachausschusses für Geographische Modelle und Geographische Informationsanalyse der Chinesischen Geographischen Gesellschaft einen Vortrag mit dem Titel „Forschung zu Optimierungsmethoden für die Konfiguration städtischer Feuerwehranlagen auf Basis von hierarchischem Deep Reinforcement Learning“ (DRL). Ausgehend von der Optimierung der Anordnung städtischer Feuerwehranlagen wurden die klassischen Optimierungsmethoden im Bereich der Geodatenoptimierung systematisch untersucht und die Vorteile und das Potenzial von Optimierungsmethoden auf Basis von Deep Reinforcement Learning (DRL) detailliert vorgestellt. Dieser Artikel fasst die wichtigsten Punkte aus Dr. Liang Haojians Vortrag zusammen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/xvnAI
Das Show Lab der National University of Singapore hat am 28. Mai 2025 ein universelles Konsistenz-Plug-in namens OmniConsistency veröffentlicht, das einen groß angelegten Diffusionstransformator (DiT) verwendet. Es handelt sich um ein vollständiges Plug-and-Play-Design, das mit LoRA jedes Stils unter dem Flux-Framework kompatibel ist und auf einem Konsistenzlernmechanismus für stilisierte Bildpaare basiert, um eine robuste Generalisierung zu erreichen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/etmWQ
Beliebte Enzyklopädieartikel
1. DALL-E
2. Mensch-Maschine-Schleife
3. Reverse-Sort-Fusion
4. Bidirektionales Langzeit-Kurzzeitgedächtnis
5. Umfangreiches Multitasking-Sprachverständnis
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Juni-Termin für den Gipfel
S&P 2026 6. Juni 7:59:59
ICDE 2026 19. Juni 7:59:59
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie Folgendes einschließen möchten hyper.ai Wenn Sie auf der offiziellen Website nach Ressourcen suchen, können Sie uns gerne eine Nachricht hinterlassen oder einen Beitrag leisten!
Bis nächste Woche!








