Command Palette
Search for a command to run...
Die Universität Oxford Und Andere Haben Sich Intensiv Mit Den Gesundheitsdaten Von 7,46 Millionen Erwachsenen Befasst, Um Algorithmen Für Die Früherkennung Zu Entwickeln Und so Eine Frühzeitige Vorhersage Von 15 Krebsarten Auf Der Grundlage Von Blutindikatoren Zu erreichen.

In Großbritannien ist die Überlebensrate bei Krebserkrankungen schon seit langem mit erheblichen Herausforderungen verbunden und die klinischen Ergebnisse gehören zu den niedrigsten in den Industrieländern. Dieser Situation liegt die objektive Tatsache zugrunde, dass sich eine große Zahl von Krebspatienten zum Zeitpunkt der Diagnose bereits im mittleren oder späten Stadium befindet und den besten Zeitpunkt für eine Behandlung verpasst hat. Im Jahr 2011 veröffentlichte der britische National Health Service (NHS) seine Krebsstrategie, in der klar das Ziel formuliert wurde, den Krebs von 75% in einem heilbaren Stadium (Stadium 1 oder 2) zu diagnostizieren und die aktuelle Situation durch die Optimierung des Diagnoseprozesses zu verbessern. Diese Strategie betrachtet die Primärversorgung als Durchbruch, verbessert die Effektivität der Frühdiagnose durch prädiktive Algorithmen und weist die Richtung für die Innovation von Krebsdiagnose- und -behandlungsmodellen.
In diesem Zusammenhang sind Algorithmen zur Krebsvorhersage entstanden, die auf umfangreichen elektronischen Gesundheitsdatenbanken der Primärversorgung basieren, wie etwa das QCancer-Score-Modell.Die absolute Wahrscheinlichkeit, dass eine Person an Krebs erkrankt ist und diese nicht diagnostiziert wurde, wird durch die Berücksichtigung mehrerer Faktoren wie Alter, Geschlecht, Armutsstatus, Rauchen, Alkoholkonsum, Familienanamnese und Symptome ermittelt.Nationale klinische Richtlinien empfehlen, dass Ärzte weitere Tests oder eine Überweisung in Erwägung ziehen, wenn der positive Vorhersagewert für Krebs einen bestimmten Schwellenwert (wie etwa 3%) überschreitet. Diese Algorithmen werden in klinische Computersysteme der Primärversorgung integriert, um das Krebsrisiko der Patienten beim Arztbesuch in Echtzeit zu beurteilen und so die klinische Entscheidungsfindung mit Daten zu unterstützen.
Im Jahr 2020 wurden in England etwas mehr als die Hälfte aller Krebserkrankungen im Stadium 1 oder 2 diagnostiziert. Damit liegt die Diagnose noch immer deutlich unter dem Ziel von 75% bis 2028. Fortschritte in der Bluttesttechnologie der letzten Jahre haben eine neue Richtung für die Überwindung dieses Engpasses aufgezeigt.Zahlreiche Studien haben gezeigt, dass abnorme Veränderungen von Blutwerten wie Hämoglobin, Anzahl weißer Blutkörperchen und Blutplättchen mehrere Jahre vor den klinischen Symptomen auftreten können.Dies deutet auf sein Potenzial als Frühwarn-Biomarker für Krebs hin und veranlasst Forscher dazu, die Einbeziehung von Bluttestdaten in Vorhersagemodelle zu untersuchen, um die Fähigkeit des Algorithmus zu verbessern, Krebserkrankungen ohne Symptome oder mit atypischen Symptomen zu identifizieren.
Auf dieser Grundlage haben das Forschungsteam der Queen Mary University of London und der Oxford University zusammengearbeitet, um zwei neue Algorithmen zur Krebsvorhersage zu entwickeln, die auf den anonymen elektronischen Gesundheitsakten von 7,46 Millionen Erwachsenen in England basieren:Der Basisalgorithmus integriert traditionelle klinische Faktoren und Symptomvariablen und der erweiterte Algorithmus bezieht zusätzlich Blutindikatoren wie ein komplettes Blutbild und Leberfunktionstests mit ein.
Die Studie verwendete ein multinomiales logistisches Regressionsmodell, um die männlichen und weiblichen Gruppen getrennt zu modellieren, nicht nur um die allgemeine Wahrscheinlichkeit von Krebs vorherzusagen,Darüber hinaus ermöglicht es erstmals eine individuelle Risikobewertung für 15 Krebsarten, darunter Leberkrebs und Mundhöhlenkrebs.In 5 Millionen unabhängigen Validierungen zeigte der neue Algorithmus eine bessere Unterscheidung, Kalibrierung und Empfindlichkeit als bestehende Modelle und bietet damit eine wissenschaftliche Grundlage für die Optimierung klinischer Entscheidungsprozesse und die Förderung einer frühzeitigen Krebsdiagnose. Darüber hinaus schlägt das Team vor, dass diese Methode der erste Algorithmus ist, der in der Primärversorgung verwendet wird, um die Wahrscheinlichkeit von Leberkrebs abzuschätzen, der derzeit nicht diagnostiziert ist.
Die entsprechenden Forschungsergebnisse wurden in der international renommierten Fachzeitschrift Nature Communications unter dem Titel „Entwicklung und externe Validierung von Vorhersagealgorithmen zur Verbesserung der Krebsfrühdiagnose“ veröffentlicht.

Papieradresse:
Das Open-Source-Projekt „awesome-ai4s“ vereint mehr als 100 AI4S-Papierinterpretationen und stellt umfangreiche Datensätze und Tools bereit:
https://github.com/hyperai/awesome-ai4s
Duale Datenbank und Multi-Kohorten-Studie: Stichprobengröße übersteigt eine Million, Datenunterstützung in allen Aspekten
Die Daten für diese Studie wurden aus zwei elektronischen Patientendatenbanken bezogen: QResearch (Version 48) und Clinical Practice Research Datalink (CPRD Gold).Ersteres basiert auf dem EMIS-System und deckt England ab, während Letzteres auf dem Vision-System basiert und Klinikdaten in Nordirland, Schottland und Wales umfasst. Dadurch wird eine geografisch unabhängige externe Validierungskohorte gebildet, um die Datenvielfalt und Repräsentativität sicherzustellen.
Was die Studienpopulation betrifft, wurden die Daten der QResearch-Klinik in England, wie in der folgenden Abbildung dargestellt, zufällig in eine Entwicklungskohorte mit 7.464.507 Personen, darunter 129.715 neue Krebsfälle, eine Validierungskohorte mit 2.637.184 Personen, darunter 44.984 neue Krebsfälle, und eine CPRD-Validierungskohorte mit 2.736.726 Personen, darunter 32.328 neue Krebsfälle, aufgeteilt.
Die Stichprobengröße der drei Kohorten überstieg jeweils eine Million und umfasste Personen im Alter von 18 bis 84 Jahren.Hierzu zählen hämatologische Malignome, die bei jungen Menschen häufig auftreten, Brustkrebs sowie häufige Krebsarten bei Menschen mittleren und höheren Alters. Der Zeitraum erstreckt sich vom 1. Januar 2015 bis zum 31. März 2023 mit einer Nachbeobachtungszeit von 2 Jahren. Der Schwerpunkt liegt auf Patienten, bei denen zum Zeitpunkt der Aufnahme in die Studie kein Krebs diagnostiziert wurde, und gewährleistet die Genauigkeit neuer Krebsdaten, indem Patienten mit „Warnsymptomen“ innerhalb der letzten 12 Monate vor der Aufnahme ausgeschlossen werden. Die Daten umfassen Aspekte wie Alter, Geschlecht, Armutsstatus, Rauchen, Trinken, Familienanamnese, Symptome und Blutuntersuchungen (großes Blutbild, Leberfunktionstests). Mit Ausnahme der englischen Kohorte, bei der die selbstberichteten Daten zu Rasse, Rauchverhalten, Alkoholkonsum und BMI etwas vollständiger waren, waren die Basismerkmale jeder Kohorte im Allgemeinen konsistent und boten eine ausgewogene Datenbasis für die Modellentwicklung.
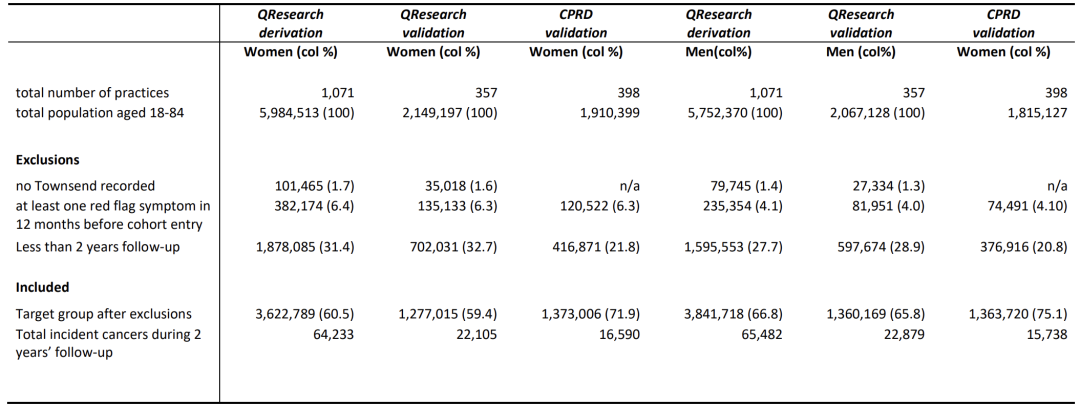
Die Studie basiert auf vier Hauptdatenquellen: Allgemeinmediziner, Krankenhäuser, Sterberaten und Krebsregister. Es identifiziert 13 Krebsarten, die bereits in QCancer enthalten sind (Lungenkrebs, Dickdarmkrebs usw.) und neu hinzugefügte Leberkrebs, Mund-Rachen-Krebs usw., insgesamt 15 Arten.Aufgrund von Datenbeschränkungen basierte die CPRD-Kohorte ausschließlich auf von Allgemeinmedizinern erfassten Diagnosen, was zu einem abgestuften Validierungssystem führte. Charakteristisch für diese Daten sind der große Stichprobenumfang, die große geografische Ausdehnung, der lange Zeitraum, mehrere prädiktive Faktoren und eine hohe klinische Relevanz. Durch die Entwicklung einer Kohorte zum Aufbau eines Vorhersagemodells und die Verwendung von Validierungskohorten aus verschiedenen Regionen und Systemen (insbesondere der externen CPRD-Kohorte) zur Bewertung der Universalität und Zuverlässigkeit des Modells können wir die Wirksamkeit und Stabilität des Algorithmus in realen klinischen Szenarien sicherstellen und Datenunterstützung für die Frühdiagnose von Krebs bereitstellen.
Entwicklung eines Krebsvorhersagemodells: multinomiale logistische Regressionsmodellierung und multidimensionale Validierung
Bei der Modellentwicklung wurden im Rahmen der Studie auf der Grundlage vorhandener Algorithmen und der Literatur mögliche Prädiktorvariablen untersucht, die demografische Merkmale, Rauch- und Trinkgewohnheiten, Krebserkrankungen in der Familie, Komorbiditäten sowie Symptome und Bluttestergebnisse abdecken. Die Symptome wurden in „Warnsymptome (starker Zusammenhang mit Krebs, Grund für eine dringende Überweisung gemäß den klinischen Richtlinien)“ und unspezifische Symptome unterteilt. In die Blutuntersuchungen wurden die Aufzeichnungen der Kohorte der letzten zwei Jahre einbezogen, um mögliche Signale zu erfassen.
Um die Wissenschaftlichkeit und Genauigkeit des Modells zu gewährleisten,Bei der Modellierung verwendeten die Forscher eine multinomiale logistische Regression, um die Koeffizienten der Vorhersagevariablen für jede Krebsart zu schätzen, und passten die Modelle für Männer und Frauen an.Fehlende Werte bei Trinkverhalten, Rauchverhalten und Blutindikatoren wurden mittels multipler Imputation mit Kettengleichungen (jeweils 5 Imputationen für Männer und Frauen + Zusammenführung der Rubin-Regel) ergänzt und binäre Variablen entsprechend den Diagnoseaufzeichnungen der Allgemeinärzte in dichotomen Kategorien kodiert. Bei der Anpassung des Modells wurden Variablen mit einem Signifikanzniveau von ≤ 0,01 beibehalten und Koeffizienten mit einem Hazard Ratio von 0,80–1,20 und keiner Signifikanz auf Null gesetzt. Durch die Kombination von P-Wert und Effektgröße wurde ein prägnantes Modell erstellt, um eine automatische Variablenauswahl ausschließlich auf Grundlage der statistischen Signifikanz zu vermeiden und die klinische Relevanz sicherzustellen.
Bruchpolynome wurden verwendet, um nichtlineare Beziehungen zwischen kontinuierlichen Variablen zu modellieren und die Interaktion zwischen Prädiktorvariablen und Alter zu testen. Bei der Bewertung des Optimismus des Modells verwendeten die Forscher einen heuristischen Schrumpfungsfaktor, um den Optimismus des Modells zu beurteilen, und die Schrumpfungswerte beider Modelle lagen bei > 0,99, was bestätigte, dass keine Überanpassung vorlag. Schließlich wurden Modell A (klinische Faktoren + Symptome) und Modell B (Modell A + Bluttestergebnisse) abgeleitet. Letzteres zielt darauf ab, die Vorhersagegenauigkeit durch das Hinzufügen neuer krebsbezogener Signale zu verbessern.
Die Modellbewertung wurde in zwei unabhängigen Validierungskohorten durchgeführt. Neben der Berechnung von AUROC zur Bewertung der Unterscheidungsfähigkeit,Die Forscher führten einen mehrkategorischen Diskriminierungsindex (PDI, 12 Kategorien für Männer/14 Kategorien für Frauen, einschließlich einer Kategorie „krebsfrei“) ein, um die allgemeine Klassifizierungsleistung zu messen (je näher der PDI bei 1 liegt, desto genauer ist die Diskriminierung).Die Übereinstimmung zwischen der vorhergesagten Wahrscheinlichkeit und dem tatsächlichen Wert wurde anhand der Kalibrierungskurve, der Steigung und des Achsenabschnitts getestet. Die spezielle Analyse von Krebs im Frühstadium konzentriert sich auf Fälle aus den Jahren 2015 bis 2020, wobei Stadium 1/Stadium 2 als frühe Definition verwendet wird, und stratifiziert und bewertet Untergruppen wie geografische Regionen, Rassen und Altersgruppen, um die Universalität des Modells in verschiedenen Populationen zu überprüfen.
Anwendung des Krebsvorhersagemodells: Leberkrebs und Mundkrebs wurden erstmals einbezogen und die Beziehung zwischen Blutindikatoren und Krebsrisiko analysiert
In der Modellanwendungs- und experimentellen VerifizierungsphaseIn dieser Studie wurde eine mehrdimensionale Überprüfung der Variablenassoziation, der Unterscheidungsfähigkeit, des Kalibrierungseffekts und des klinischen Werts des neuen Vorhersagemodells durchgeführt.Im Vergleich zum bestehenden QCancer-Algorithmus fügt das neue Modell vier neue Erkrankungen hinzu: Leberzirrhose, Hepatitis B, Hepatitis C (im Zusammenhang mit Leberkrebs) und AIDS (im Zusammenhang mit Blutkrebs und Nierenkrebs), ergänzt den Zusammenhang mit der familiären Vorbelastung mit Lungenkrebs/Blutkrebs und sieben krebsübergreifende Symptome wie Juckreiz, Blutergüsse und Knoten im Bauch.
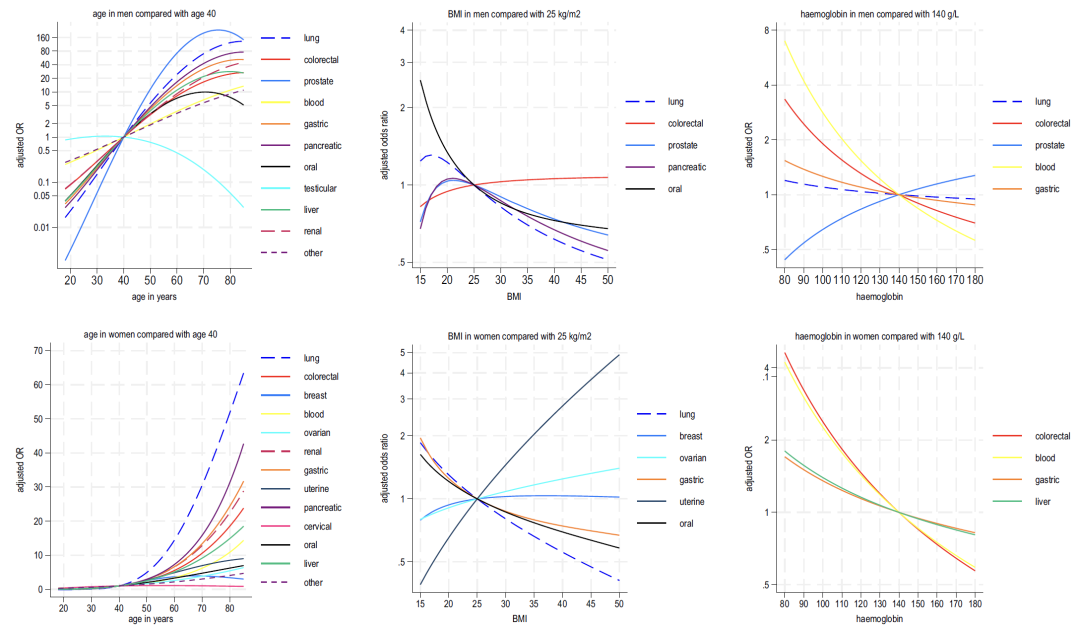
Es gab geschlechtsspezifische Unterschiede im Zusammenhang zwischen Alter und Symptomen:Bei Männern ist das Risiko für die meisten Krebsarten in jüngeren Jahren höher, bei Frauen ist es umgekehrt.Die Analyse von Alter und BMI zeigte, dass mit Ausnahme von Hodenkrebs und Gebärmutterhalskrebs das Risiko für alle Krebsarten mit dem Alter zunimmt. Ein niedrigerer BMI korrelierte positiv mit mehreren Krebsarten, und das Risiko von Gebärmutterkrebs und Eierstockkrebs bei Frauen stieg mit einem höheren BMI.
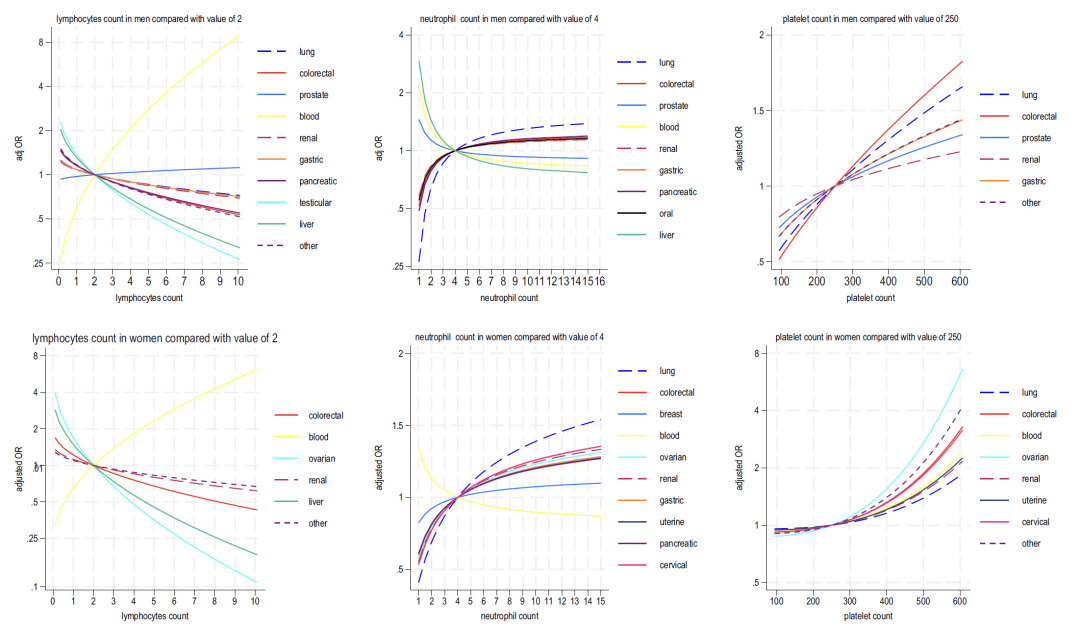
Wie in den Abbildungen 2–4 unten dargestellt, zeigt die Analyse der in Modell B enthaltenen Blutindikatoren Folgendes:
* Hämoglobin: Ein Rückgang dieses Indikators wird mit Lungenkrebs und Dickdarmkrebs bei Männern und mit Dickdarmkrebs und Leberkrebs bei Frauen in Verbindung gebracht;
* Lymphozyten: negativ korreliert mit den meisten Krebsarten und stark positiv korreliert mit Blutkrebs;
* Neutrophile: Bei Frauen wird ein Anstieg dieses Indikators häufig mit Krebs in Verbindung gebracht (Lungenkrebs ist am bedeutendsten), während er bei Männern „bidirektional assoziiert ist (hohe Werte werden mit 6 Krebsarten in Verbindung gebracht und niedrige Werte mit Leberkrebs und Prostatakrebs)“;
* Thrombozyten: Eine erhöhte Thrombozytenzahl korreliert positiv mit mehreren Krebsarten bei Männern und Frauen (am stärksten mit Dickdarmkrebs bei Männern und Eierstockkrebs bei Frauen) und ist synergistisch mit erhöhten Neutrophilen und verringerten Lymphozyten verbunden;
* Leberfunktion: Ein verringerter Albuminspiegel und eine erhöhte alkalische Phosphatase weisen im Allgemeinen auf ein Krebsrisiko hin, während ein erhöhter Bilirubinspiegel eng mit Leberkrebs und Blutkrebs zusammenhängt.
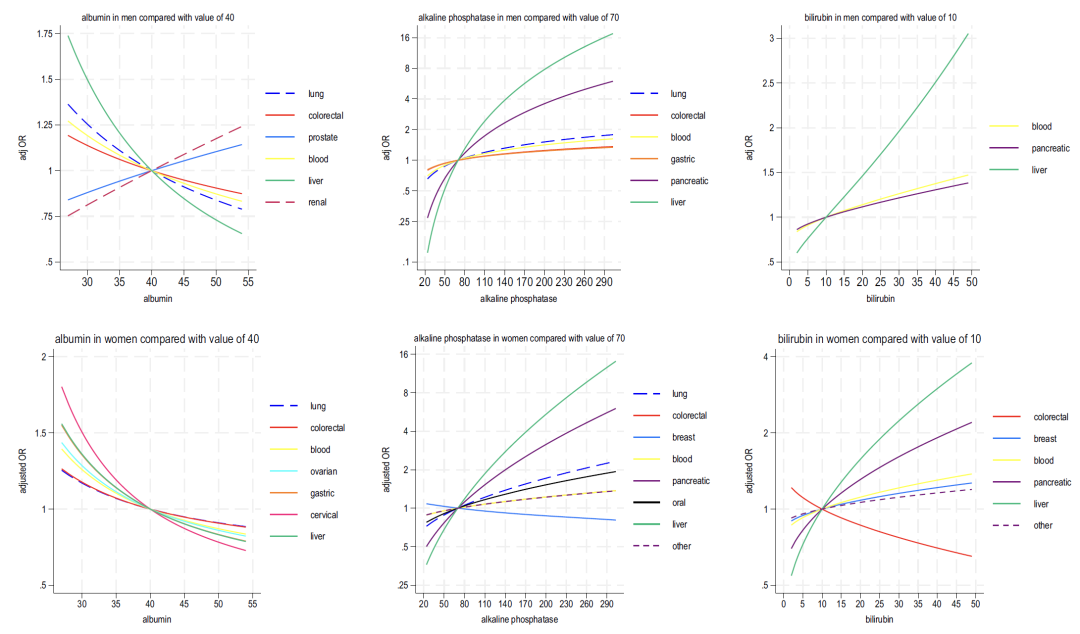
Bei der Bewertung der Unterscheidungsfähigkeit ist die c-Statistik (AUROC) von Modell B (einschließlich Blutuntersuchung) insgesamt besser als die von Modell A, wie in der folgenden Abbildung dargestellt. Die allgemeine Unterscheidungseffizienz von Männern (0,876) ist höher als die von Frauen (0,844). Die meisten c-Werte der 15 Krebsarten liegen bei > 0,8, lediglich Mundhöhlenkrebs (0,747) und Gebärmutterhalskrebs (0,694) bei Frauen liegen etwas darunter. Der Multi-Category Discrimination Index (PDI) zeigte, dass Modell B in seiner Fähigkeit, zwischen Männern und Frauen zu unterscheiden (0,323 für Männer und 0,266 für Frauen), Modell A überlegen war und eine hervorragende Klassifizierungsleistung bei Hodenkrebs (PDI 0,641 für Männer) und Gebärmutterkrebs (PDI 0,439 für Frauen) aufwies. Die Untergruppenanalyse zeigte, dassDie Leistung des Modells war über verschiedene Rassen, Altersgruppen und geografische Regionen hinweg stabil, mit leichten Schwankungen bei seltenen Krebsarten aufgrund der geringen Anzahl von Ereignissen.
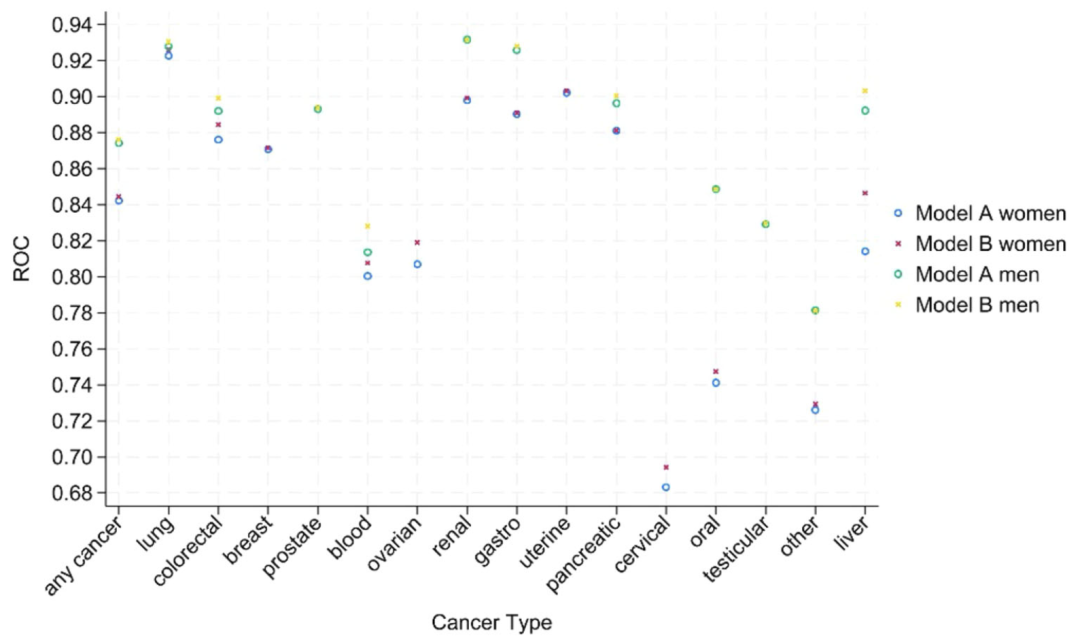
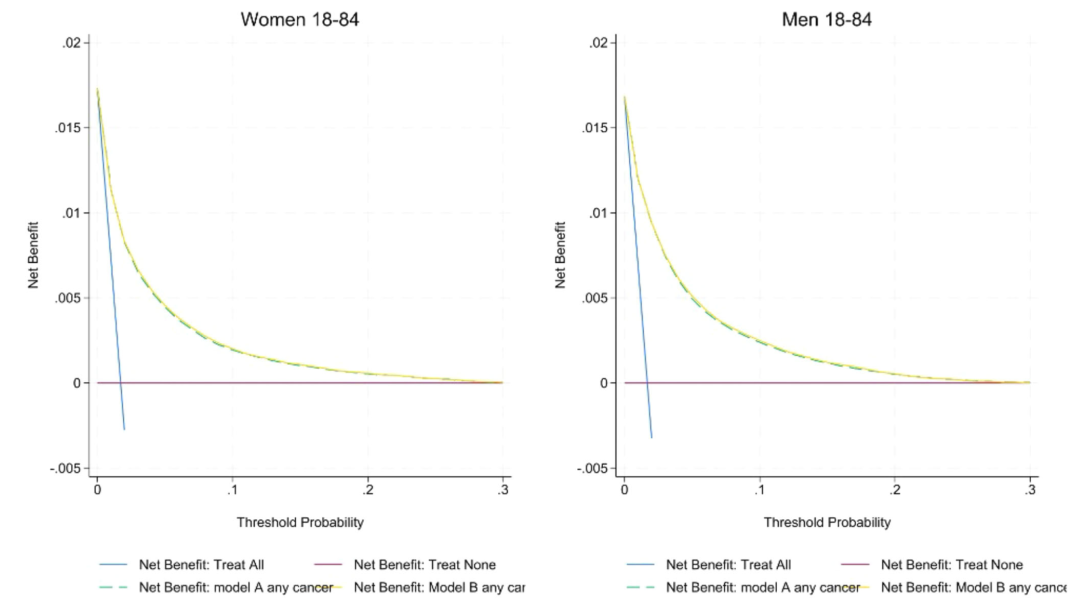
In Bezug auf die Kalibrierungsfähigkeit liegt, wie in der folgenden Abbildung gezeigt, die Kalibrierungssteigung von Modell A/B in der englischen Kohorte nahe 1 (1,00 für Frauen und 0,99 für Männer), und der Achsenabschnitt nähert sich Null; Allerdings kommt es in der externen CPRD-Kohorte zu einer gewissen Überschätzung der Krebswahrscheinlichkeit für Männer und Frauen. Die Entscheidungskurve zeigt, dass der Nettonutzen von Modell B höher ist als der von Modell A und QCancer, insbesondere bei der Überweisungsschwelle von 3%. Die Empfindlichkeit von Modell A/B gegenüber männlichem Krebs (82,6%) ist höher als die von QCancer (78,1%), und die Empfindlichkeit gegenüber weiblichem Krebs steigt von 66,0% auf über 77%. Die Fähigkeit, Krebs im Frühstadium 1/2 zu identifizieren, ist mit der aller Stadien vergleichbar (75% für Frauen und 81% für Männer). Die Neuklassifizierungsanalyse ergab, dassIm Vergleich zu QCancer stuft Modell A mehr ältere Menschen als Hochrisikopatienten und jüngere Menschen als Niedrigrisikopatienten ein und optimiert so die Genauigkeit der klinischen Ressourcenzuweisung.
Globale Krebsvorhersagealgorithmen und Frühdiagnose: Interdisziplinärer Fortschritt in der universitären Forschung und Unternehmensinnovation
Im Bereich der Krebsvorhersagealgorithmen und Frühdiagnose fördern wissenschaftliche Forschungsteams von Universitäten auf der ganzen Welt sowie Technologieunternehmen durch interdisziplinäre Innovationen die beschleunigte Umsetzung theoretischer Forschung in klinische Anwendungen.
Zum Beispiel das MuMo-Modell, das vom Team von Dong Bin und Shen Lin von der Peking-Universität entwickelt wurde,Integrieren Sie Bildgebungs-, Pathologie- und klinische Daten von HER2-positiven Magenkrebspatienten, um genaue Vorhersagen für eine individualisierte Behandlung zu ermöglichen.Das Computer Network Information Center der Chinesischen Akademie der Wissenschaften hat das SuRe-Transformer-Modell auf Basis des Supercomputersystems „Dongfang“ unter Verwendung der Transformer-Architektur erstellt.Verbessern Sie die HRD-Vorhersagegenauigkeit von Brustkrebs-Pathologiebildern durch 21%;Die Forschungsgruppe von Li Shao an der Tsinghua-Universität verwendete das schwach überwachte Lernframework HistoCell.Erreichen Sie eine unbeaufsichtigte Inferenz räumlicher Assoziationsnetzwerke von Zellen in pathologischen Bildern.Bereitstellung neuer Werkzeuge für die Erforschung des Tumormikromilieus.
Das CHIEF-Modell, das von der Harvard Medical School und der Stanford University entwickelt wurde,Diagnose von 19 Krebsarten mit einer Genauigkeit von 94%,Außerdem können anhand pathologischer Bilder die Überlebensraten von Patienten vorhergesagt werden. Das von der Universität Cambridge entwickelte Deep-Learning-Modell ResNetRS50 sagt Blutkrebs durch die Analyse von Blutdaten voraus – mit höherer Genauigkeit, Geschwindigkeit und geringerer Fehlerrate als fortschrittlichere Modelle.
Bei Innovationen im Unternehmenssektor liegt der Schwerpunkt eher auf der Integration von Technologieimplementierung und klinischer Praxis. Die AI for Health-Plattform von Microsoft integriert Genome und elektronische Gesundheitsakten, um eine individuelle Krebsrisikokarte mit einer Vorhersagegenauigkeit von 89% für Menschen mit hohem Brustkrebsrisiko zu erstellen. Das AlphaScan-System von Google DeepMind hat eine Genauigkeit von 96% bei der Früherkennung von Lungenkrebs; Die KI-Lösung für die Lungenbildgebung des KI-Medizintechnikunternehmens InferRead, ein auf Deep Learning basierendes System zur Erkennung von Lungenknötchen, wurde in der klinischen CT eingesetzt und verbessert so die diagnostische Effizienz erheblich.
Insgesamt entwickelt sich der Bereich der Algorithmen zur Krebsvorhersage und Frühdiagnose vom Screening einzelner Krebsarten zum Pan-Cancer-Frühscreening für mehrere Krebsarten: Der Galleri-Test von Grail in den USA prüft 50 Krebsarten und lokalisiert die primäre Läsion durch Blutmethylierungsanalyse, und die PanSeer®-Technologie des chinesischen Unternehmens Xunyuan Biotechnology ermöglicht ein effektives Frühscreening für fünf häufige Krebsarten. Durch die umfassende Integration künstlicher Intelligenz und Big Data dürften Algorithmen zur Krebsvorhersage in der medizinischen Grundversorgung populär werden. Sie fördern den Wandel von Diagnose- und Behandlungsmodellen von der „empirischen Medizin“ zur „Präzisionsdatenmedizin“ und legen den Grundstein für eine „Früherkennung und Frühintervention“.
Referenzlinks:
1.https://bda.pku.edu.cn/info/1003/2824.htm
2.https://www.cas.cn/syky/202505/t20250522_5069507.shtml
3.https://mp.weixin.qq.com/s/s1JyOTPChdoMipmTzBBqvw
4.https://mp.weixin.qq.com/s/4fhMJ25xVAThAFTdmZyt9w








