Command Palette
Search for a command to run...
Im Nature Journal Veröffentlicht! Die Huazhong University of Science and Technology Schlug Ein KI-Modell Mit Fusionsstrategie Vor, Um Eine Genaue Vorhersage Des Sterberisikos Bei Septischem Schock in Mehreren Zentren Und Über Verschiedene Fachgebiete Hinweg Zu Erreichen

Unter infektiösem Schock (auch septischer Schock genannt) versteht man ein durch eine Sepsis hervorgerufenes Syndrom schwerer Durchblutungsstörungen und zellulärer Stoffwechselstörungen, das in seiner klinischen Ausprägung als „Terminalstadium“ der Sepsisentwicklung angesehen werden kann. Der septische Schock weist eine extrem hohe Sterblichkeitsrate auf und ist derzeit eine der tödlichsten Erkrankungen auf Intensivstationen.Einem Forschungsbericht zufolge, der auf der britischen nationalen Datenbank für Intensivmedizin basiert, kann die Sterblichkeitsrate im Krankenhaus bei Patienten mit septischem Schock bis zu 55,5% betragen.
Angesichts dieser fortschreitenden Krankheit mit hoher Sterblichkeitsrate liegt der klinische Schwerpunkt beim septischen Schock auf dem Motto „Zeit ist Leben“ und zur Senkung der Sterblichkeitsrate werden eine frühzeitige Erkennung, ein frühzeitiges Eingreifen und eine frühzeitige Behandlung befürwortet. Jedoch,Aufgrund der Komplexität des Zustands von Patienten mit septischem Schock und der Knappheit klinisch-medizinischer Daten ist es sehr schwierig, frühzeitig vor dem Fortschreiten der Krankheit zu warnen., was zugleich der entscheidende Engpass für eine wirksame Intervention bei der Verschlimmerung einer Sepsis bis hin zum septischen Schock ist.
Mit der zunehmenden Verbreitung der Informationstechnologie in der Intensivmedizin und der wechselseitigen Integration von künstlicher Intelligenz und Intensivmedizin ist die Frühwarnung vor einer Sepsis heute kein Problem mehr, die Forschung zum septischen Schock hinkt jedoch hinterher. Dies liegt daran, dass die meisten Studien kleine Stichprobengrößen aufweisen, auf einem einzigen Algorithmus für maschinelles Lernen beruhen und die Validierung mehrerer Zentren nicht bestanden haben. Dadurch ist es schwierig, sie in die klinische Praxis der frühzeitigen Risikovorhersage für Patienten mit septischem Schock umzusetzen.
Vor diesem Hintergrund haben Professor Ye Qing vom Tongji-Krankenhaus des Tongji Medical College der Huazhong University of Science and Technology und Professor Wu Hong von der School of Medical and Health Management ein Klassifikationsfusionsmodell (TCF) auf Basis von TOPSIS (Technique for Order Preference by Similarity to an Ideal Solution) entwickelt, um das Sterberisiko innerhalb von 28 Tagen bei Patienten mit septischem Schock auf der Intensivstation vorherzusagen.Das Modell integriert 7 Modelle des maschinellen Lernens und verfügt über eine hohe Stabilität und Genauigkeit bei der fachübergreifenden und multizentrischen Validierung.Es bietet Klinikärzten ein zuverlässiges Hilfsmittel zur Frühwarnung vor dem Risiko eines tödlichen septischen Schocks.
Die Forschungsergebnisse wurden in der Nature-Tochterzeitschrift npj Digital Medicine unter dem Titel „Artificial intelligence based multispecialty mortality prediction models for septic shock in a multicenter retrospective study“ veröffentlicht.
Forschungshighlights:
* Die Studie verwendete eine effiziente Fusionsstrategie, um ein Fusionsmodell mit hoher Generalisierungsfähigkeit und Robustheit basierend auf mehreren grundlegenden Klassifizierungsmodellen zu erstellen und so das Problem der schlechten Leistung kleiner Stichprobenkohorten und einzelner Klassifizierungsmodelle in klinischen Szenarien zu überwinden.
* Die Forschungsergebnisse stellen einen Durchbruch bei der Vorhersage des Risikos eines frühen Todes bei septischem Schock dar und bieten Klinikern ein effizientes, stabiles und zuverlässiges Instrument zur klinischen Entscheidungsfindung, das Ärzten hilft, den Krankheitsverlauf der Patienten früher genau zu überwachen und aktivere Behandlungsmaßnahmen zu ergreifen.

Papieradresse:
https://go.hyper.ai/faMLL
Das Open-Source-Projekt „awesome-ai4s“ vereint mehr als 100 AI4S-Papierinterpretationen und stellt umfangreiche Datensätze und Tools bereit:
https://github.com/hyperai/awesome-ai4s
Datensätze: Umfangreiche Daten, präzise Verarbeitung
Um ein Vorhersagemodell für einen septischen Schock mit breiter Anwendbarkeit zu entwickeln,Das Forschungsteam integrierte die klinischen Daten von 4.872 Intensivpatienten mit septischem Schock aus drei Krankenhäusern von Februar 2003 bis November 2023.Die Teilnehmer haben einen komplexen und vielfältigen Hintergrund, was dem Forschungsteam dabei helfen wird, eine multizentrische, fachübergreifende Validierung durchzuführen, um die Gültigkeit und Anwendbarkeit des Modells nachzuweisen. Wie in der folgenden Abbildung dargestellt:
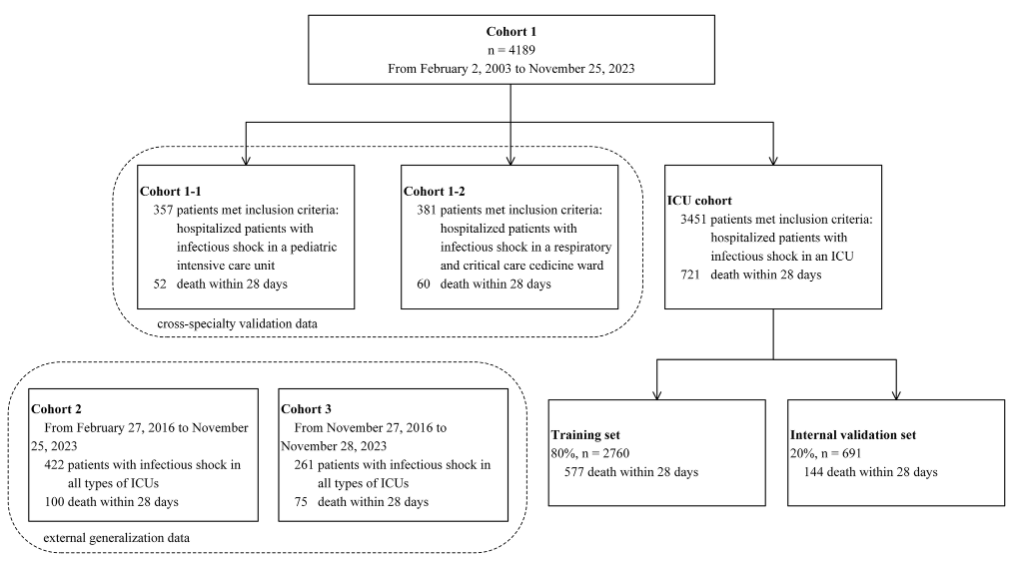
Speziell,Kohorte 1 umfasste 4.189 Teilnehmer.Darunter befanden sich 3.451 Patienten auf der allgemeinen Intensivstation (721 positiv und 2.730 negativ); 357 Patienten auf der pädiatrischen Intensivstation (Kohorte 1-1) (52 positiv); und 381 Patienten auf der Intensivstation für Atemwegserkrankungen (Kohorte 1–2) (60 positiv).
* Positive Ergebnisse sind Teilnehmer, die innerhalb von 28 Tagen nach der Einlieferung in die Intensivstation einen Tod jeglicher Ursache erlitten haben, und Teilnehmer, die keinen Tod jeglicher Ursache erlitten haben, werden als negative Ergebnisse gekennzeichnet (dasselbe gilt unten).
Darunter wurde der allgemeine Datensatz von Intensivpatienten als Hauptforschungspopulation sowie für die Modellkonstruktion und interne Validierung verwendet.Die Trainingsdaten und Validierungsdaten wurden im Verhältnis 8:2 aufgeteilt, mit 2.760 Probanden (577 positiv) bzw. 691 Probanden (144 positiv).Anhand der Datensätze zu pädiatrischen Intensivpatienten und Intensivpatienten mit Atemwegserkrankungen wurden die Anwendbarkeit und Stabilität des Modells in verschiedenen spezialisierten Intensivstationen weiter bewertet.
Kohorte 2 und Kohorte 3 umfassten Patienten mit septischem Schock von verschiedenen Intensivstationen mit 422 Teilnehmern (100 positiv, 322 negativ) bzw. 261 Teilnehmern (75 positiv, 186 negativ).Diese beiden Teile des Datensatzes werden hauptsächlich zur externen Validierung verwendet, um seine Generalisierbarkeit und Wirksamkeit in verschiedenen Zentren zu bewerten.
Um genaue experimentelle Ergebnisse zu erhalten,Das Forschungsteam extrahierte 93 gemeinsame klinische Merkmale.Unter Einbeziehung demografischer Informationen, Krankheits- und Behandlungsverlauf, Informationen zu den Vitalfunktionen usw. wurde der Datensatz schließlich für das Experiment auf 34 Elemente optimiert.
Speziell,Die Datenvorverarbeitung besteht aus 5 Teilen:Im ersten Schritt berechnete das Forschungsteam zunächst die Fehlrate und löschte 23 Variablen mit Fehlraten über 30%; im zweiten Schritt wurde die Varianz der Booleschen Merkmale gemäß der Varianzformel von Bernoulli berechnet und die diskreten Zufallsvariablen mit einer Konsistenz über 90% wurden wieder entfernt; im dritten Schritt wurde die Methode der Interpolation fehlender Werte (Logistische Regression, multiple Interpolation) verwendet, um eine weitere Optimierung auf 61 Variablen durchzuführen; Im vierten Schritt wurden die Merkmale mit hoher Korrelation erneut gescreent (Pearson-Korrelationskoeffizient ≥ 0,7), und zu diesem Zeitpunkt waren noch 50 Variablen übrig. Wie in der folgenden Abbildung dargestellt:
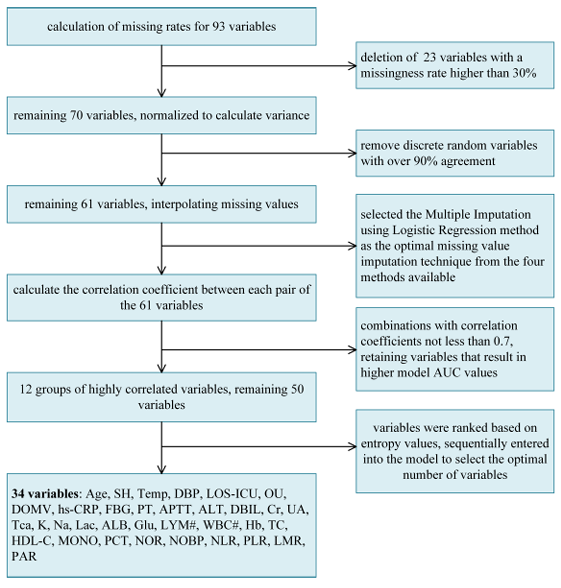
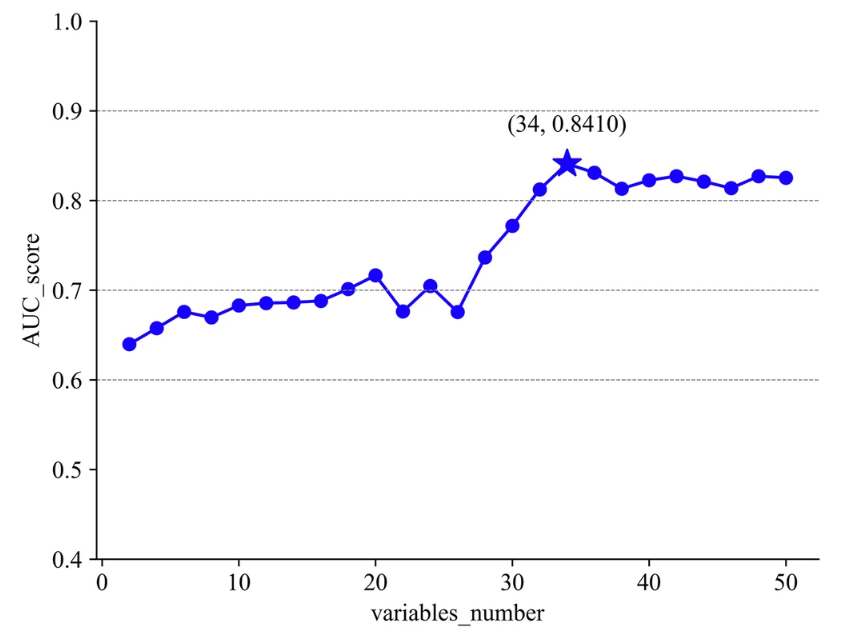
Im fünften Schritt sortierten die Forscher die Variablen nach Informationsentropie (von hoch nach niedrig) und wählten schließlich 34 Schlüsselvariablen für das Experiment aus, darunter wichtige Faktoren wie Alter, Operationsvorgeschichte, Körpertemperatur und diastolischer Blutdruck.
Es ist zu beachten, dass zum Schutz der Privatsphäre der Teilnehmer alle Daten vor der Analyse anonymisiert wurden.
Modellarchitektur: Fusionsmodell, genaue Vorhersage
Die Erforschung des TCF-Modells gliedert sich im Wesentlichen in drei Schritte:Der erste Schritt besteht darin, anhand der Krankenhausdaten von Patienten mit septischem Schock sieben Untermodelle zu erstellen, die jeweils Ergebnisse für sechs Bewertungsindikatoren liefern. Der zweite Schritt besteht darin, die Untermodelle basierend auf der Fusionsstrategie in ein Fusionsmodell zu integrieren und zu überprüfen, ob das Modell anderen Modellen überlegen ist. Der dritte Schritt umfasst das Testen verschiedener Datensätze, um die Leistung des Modells zu überprüfen und eine Interpretierbarkeitsanalyse des Modells durchzuführen (erläutert im Abschnitt „Versuchsergebnisse“).
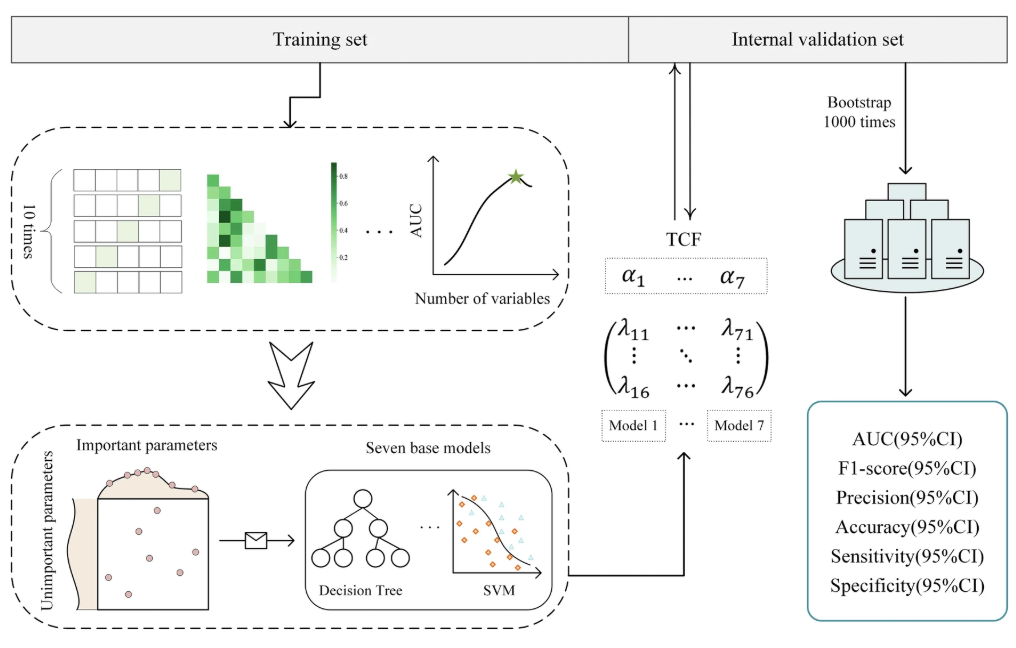
Speziell,Im ersten Schritt trainierte und testete das Forschungsteam zunächst 7 Untermodelle mithilfe des merkmalsverarbeiteten gemeinsamen ICU-Datensatzes.Um die negativen Auswirkungen des Klassenungleichgewichts zu mildern, wurde die Synthetic Minority Over-sampling Technique (SMOTE) gemäß der 1:1-Regel auf den Trainingssatz angewendet. Nach der Min-Max-Normalisierung wurde die optimale Parameterkombination durch fünffache Kreuzvalidierung und Zufallssuche ermittelt und 7 Untermodelle wurden auf dem Trainingssatz trainiert, nämlich Decision Tree (DT), Random Forest (RF), XGBoost (XGB), LightGBM (LGBM), Naive Bayes (NB), Support Vector Machine (SVM) und Gradient Boosted Decision Tree (GBDT).
Abschließend nutzte das Forschungsteam interne Validierungsdaten, um die Testergebnisse zu verifizieren.Die Leistung des Modells wird anhand von 6 Bewertungsindikatoren beurteilt.Dies sind die Fläche unter der ROC-Kurve (AUC), der F1-Score, die Präzision (PRE), die Genauigkeit (ACC), die Sensitivität (SEN) und die Spezifität (SPE).
Im zweiten Schritt integrierte das Forschungsteam diese sieben Untermodelle, jedes mit seinen eigenen Vor- und Nachteilen.Ein TOPSIS-basiertes Klassifikationsfusionsmodell TCF wurde entwickelt, um die Auswertungsergebnisse von sieben Modellen zu kombinieren und ein umfassendes Vorhersageergebnis für die Diagnose eines septischen Schocks zu liefern. Die Gewichte der Untermodelle wurden anhand des TOPSIS-Scores berechnet und die gewichtete Vorhersagewahrscheinlichkeit war die Vorhersagewahrscheinlichkeit von TCF. Die Klassifizierungsergebnisse von TCF wurden mit 0,5 als kritischem Wert abgeleitet.
Der spezifische TCF-Modellfusionsalgorithmus lautet wie folgt:
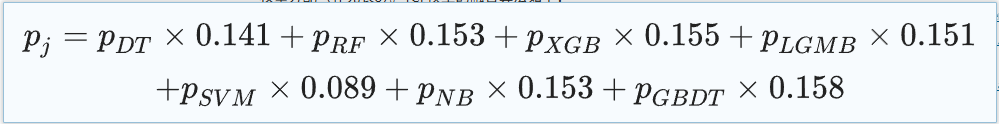
In Bezug auf die statistische Analyse werden für kontinuierliche Merkmale die Statistiken für Median, oberes Quartil und unteres Quartil angegeben. Für diskrete Merkmale wird der Anteil jeder Kategorie angegeben.In dieser Studie ist Kohorte 3 der kleinste Datensatz, und gemäß dem zentralen Grenzwertsatz kann die mittlere Verteilung kontinuierlicher Merkmale als Normalverteilung betrachtet werden.
Dann,In der Studie wurde der Levene-Test verwendet, um die Homogenität der Merkmale zwischen zwei Datensätzen zu bestimmen.Der Chi-Quadrat-Test wurde verwendet, um die Unterschiede in diskreten Merkmalen zwischen anderen Daten und dem internen Validierungssatz zu vergleichen, und die Unterschiede in kontinuierlichen Merkmalen wurden mit dem T-Test für unabhängige Stichproben oder dem T-Test von Welch getestet, und 1.000 Bootstrap-Stichproben wurden verwendet, um die 95%-Konfidenzintervalle der Bewertungsindikatoren zu berechnen.
Um den Denkprozess des Modells besser zu verstehen, visualisierte das Forschungsteam auch die Merkmalswichtigkeit, indem es eine SHAP-Heatmap der Merkmalswichtigkeit zeichnete. Nehmen Sie als Beispiel das GBDT-Modell mit der besten AUC-Leistung, wie in der folgenden Abbildung dargestellt:
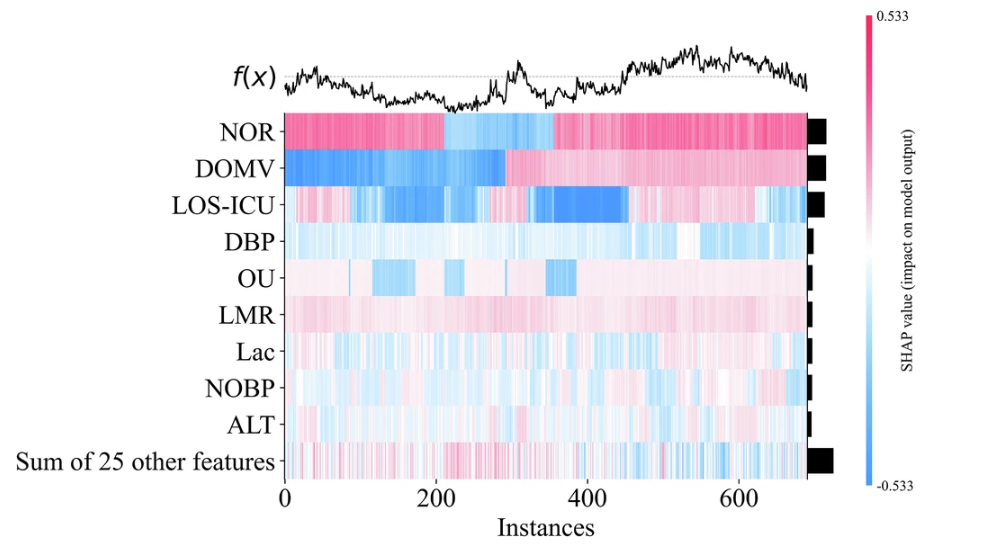
Durch die Einstufung der Merkmalswichtigkeit können nicht nur die Transparenz und Glaubwürdigkeit klinischer Vorhersagemodelle verbessert, sondern auch wertvolle Referenzen für die medizinische Praxis bereitgestellt werden. Auf diese Weise,Das Modell erfüllt nicht nur den Anspruch der Ärzte an Modelltransparenz, sondern quantifiziert auch den klinischen Nettonutzen.Es erreicht sowohl klinische Interpretierbarkeit als auch Praktikabilität und legt den Grundstein für die Anwendung des Modells in der klinischen Praxis.
Experimentelle Ergebnisse: Mehrdimensionale Verifizierung, zuverlässig und einfach zu bedienen
Um die Leistungsfähigkeit des Fusionsmodells (TCF) zu überprüfen, verglich das Forschungsteam es zunächst mit den Untermodellen. Die Ergebnisse sind in der folgenden Abbildung dargestellt:
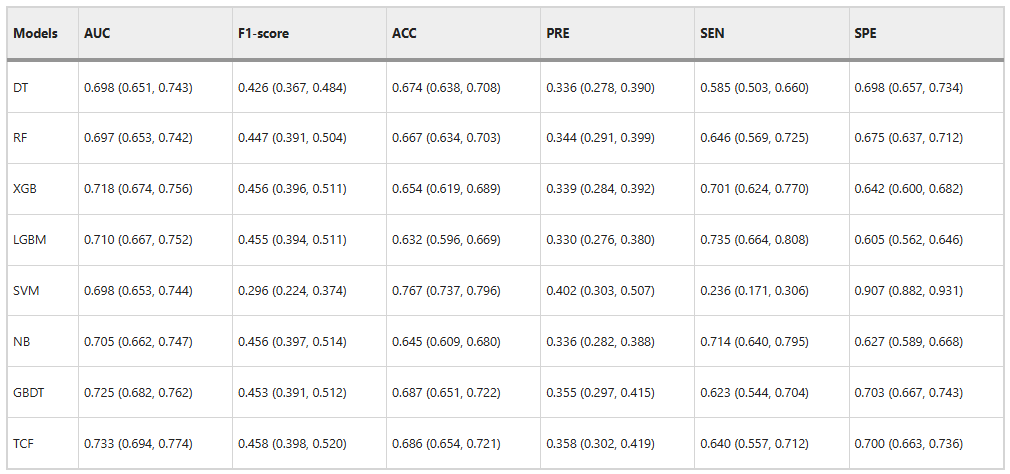
TCF übertrifft die Untermodelle in beiden umfassenden Bewertungsindikatoren des internen Validierungssatzes.Der AUC beträgt 0,733 und der F1-Score beträgt 0,458. Darüber hinaus sind auch ACC mit 0,686 und PRE mit 0,358 höher als bei den meisten Untermodellen. Dies zeigt seine hervorragende Klassifizierungsfähigkeit.
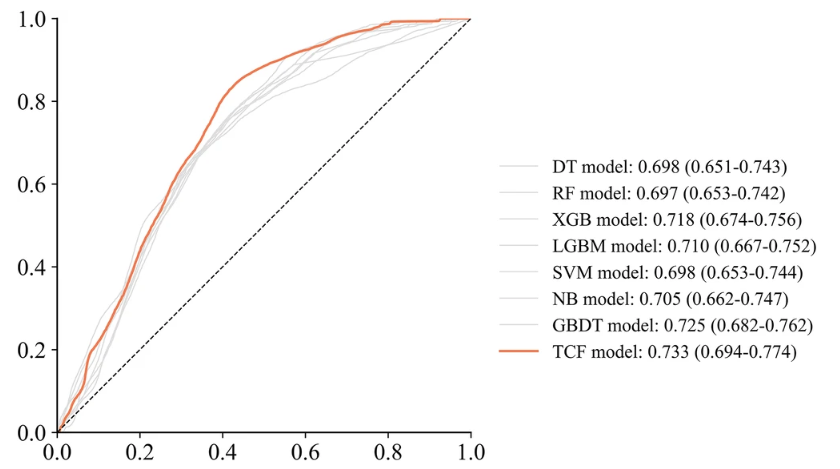
Obwohl die Ergebnisse des TCF-Modells für SEN und SPE nicht so gut sind wie die besten Ergebnisse, die bei 0,640 bzw. 0,700 liegen,Es kann jedoch die Wirkung durch die Abweichung des gesamten Untermodells identifizieren und so die beste Gesamtleistung erzielen.Wie in der Abbildung unten gezeigt.
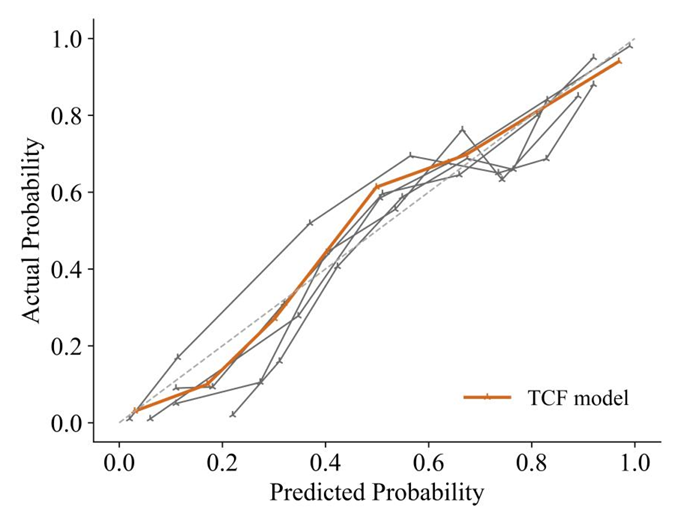
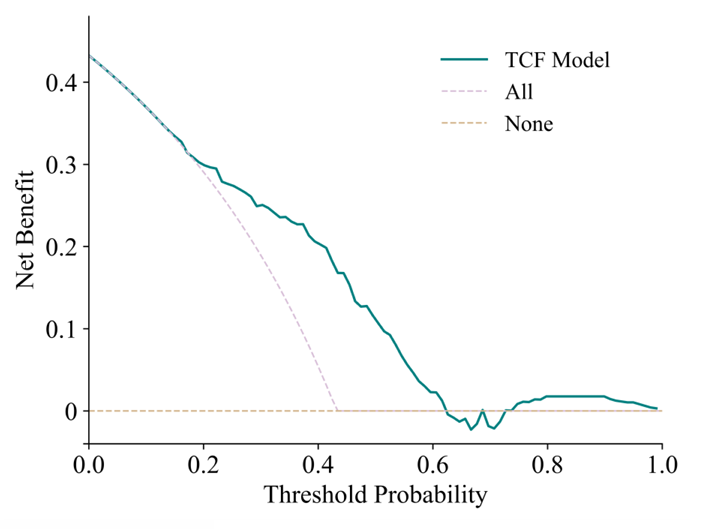
Die Kalibrierungskurve und die Entscheidungskurvenanalyse (DCA) zeigen, dass die vorhergesagten Ergebnisse des TCF-Modells mit den tatsächlichen Ergebnissen übereinstimmen.Erstens liegt die Kalibrierungskurve des TCF-Modells der Diagonalen am nächsten, was darauf hinweist, dass es von allen Modellen die beste Kalibrierungsleistung aufweist. Zweitens ist die Kurve des TCF-Modells unter den meisten Schwellenwahrscheinlichkeiten, insbesondere im Wahrscheinlichkeitsbereich von 0,1 bis 0,5, immer besser als die Strategien „Alle“ und „Keine“, und weist höhere Nettorenditen auf. Dies deutet darauf hin, dass das TCF-Modell innerhalb eines bestimmten Bereichs einen potenziellen klinischen Anwendungswert hat und Klinikern dabei helfen kann, günstigere Entscheidungen zu treffen.
Anschließend führte das Forschungsteam eine multizentrische Validierung durch, die die Vorhersageleistung des TCF-Modells und die Heterogenität zwischen verschiedenen Datensätzen genauer nachweisen konnte. Wie in der folgenden Abbildung dargestellt:
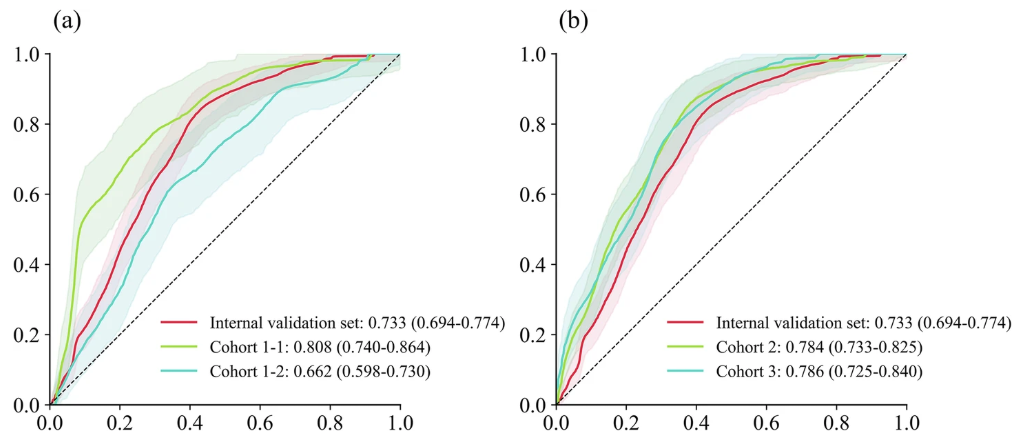
Es ist ersichtlich, dass im Gegensatz zu den meisten Studien, bei denen der multizentrische Vorhersageeffekt etwas niedriger ist als der des Trainingsdatensatzes und des internen Validierungsdatensatzes, in dieser Studie, abgesehen von einer leichten Abnahme der AUC (0,662) der Kohorte 1-2 (Datensatz von Intensivpatienten mit Atemwegserkrankungen),Die AUCs der Kohorte 1-1 (Datensatz pädiatrischer Intensivpatienten), Kohorte 2 und Kohorte 3 verbesserten sich alle.Sie betragen 0,808, 0,784 bzw. 0,786.
Aufgrund der begrenzten Anzahl multizentrischer ProbenDas Forschungsteam kombinierte zur Vorhersage gezielt 4 externe Validierungsdatensätze (1.421 Patientendaten, darunter 287 positive Fälle).Seine AUC betrug 0,7705, was darauf hindeutet, dass das TCF-Modell Patienten mit geringen Risikofaktoren für septischen Schock effektiv unterscheiden konnte und über eine gute Kalibrierungsfähigkeit verfügte.
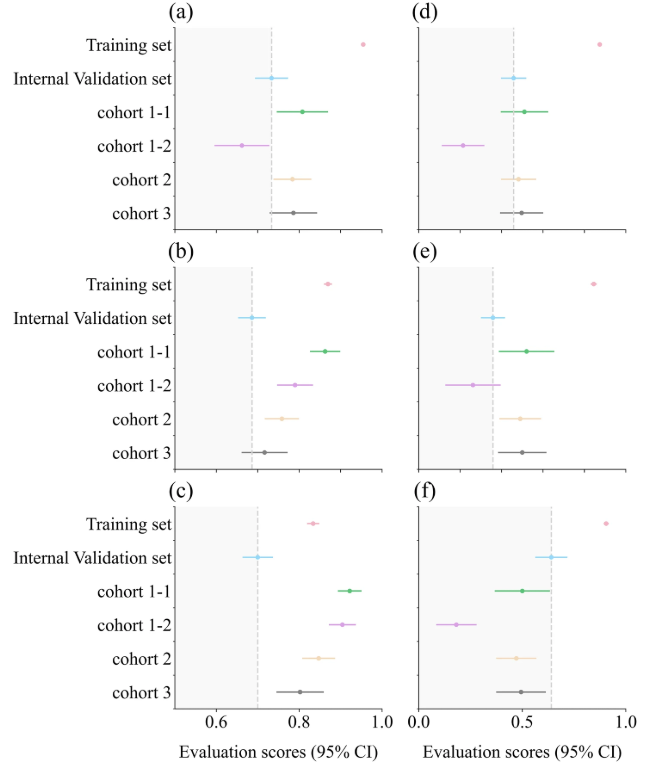
Darunter ist a das AUC-Boxplot; b ist das ACC-Boxplot; c ist das SPE-Boxplot; d ist das F1-Score-Boxplot; e ist das PRE-Boxplot; und f ist das SEN-Boxplot. Die graue gestrichelte Linie zeigt die Ergebnisse des internen Validierungssatzes an, und die Bewertungsergebnisse der anderen Datensätze liegen im dunkelgrauen Bereich, was auf eine Leistungsminderung im Vergleich zum internen Validierungssatz hinweist.
Zusammenfassend lässt sich sagen, dass das TCF-Modell sowohl beim internen Datensatz als auch beim externen Validierungssatz eine konsistente und gute Leistung erzielte und bei der Vorhersage des Sterberisikos innerhalb von 28 Tagen bei Patienten mit septischem Schock eine bessere Leistung als Einzelmodelle zeigte.Dieses Modell bietet Intensivmedizinern ein zuverlässiges und einfach zu verwendendes Vorhersagetool, insbesondere in den kritischen Frühstadien der Verschlechterung des Zustands eines Patienten. Es kann Ärzten dabei helfen, wirksame und personalisierte Behandlungsinterventionen für verschiedene Patienten bereitzustellen und die Patientenprognose zu verbessern.
Künstliche Intelligenz spielt eine große Rolle bei der Behandlung von Sepsis/septischem Schock
Mit der kontinuierlichen Entwicklung von Wissenschaft und Technologie ist die wechselseitige Integration von künstlicher Intelligenz und Intensivmedizin für die einschlägigen Forscher schon lange zu einem Bereich geworden, der ihnen große Sorgen bereitet. Diese Studie ist zweifellos eine Erkundung mit bahnbrechendem Wert. Wie bereits erwähnt, stellt Sepsis bzw. septischer Schock eine globale Krise der öffentlichen Gesundheit mit hoher Mortalität und Morbidität dar. Um die Überlebensrate der Patienten zu verbessern, sind eine frühzeitige Erkennung und Intervention dringend erforderlich.
In der Vergangenheit hat die Forschung zu Frühwarnmodellen für Sepsis bereits große Fortschritte gemacht und viele Labore haben entsprechende Forschungsergebnisse vorgelegt.
Beispielsweise eine Studie mit dem Titel „Maschinelles Lernen zur Früherkennung von Sepsis: eine interne und zeitliche Validierungsstudie“, die von Armando D. Bedoya et al. veröffentlicht wurde. von der Duke University in den Vereinigten Staaten.Es führt ein auf Deep Learning (Multi-Output-Gauß-Prozess und rekurrentes neuronales Netzwerk) basierendes Vorhersagemodell MGP-RNN ein und verifiziert es.Im Vergleich mit drei Methoden des maschinellen Lernens, darunter Random Forest, Cox-Regression und bestrafte logistische Regression, sowie drei klinischen Scores übertraf das Modell andere Modelle und klinische Scores bei allen Indikatoren und kann eine Sepsis 5 Stunden im Voraus erkennen.
Papieradresse:
https://pmc.ncbi.nlm.nih.gov/articles/PMC7382639
Darüber hinaus gab auch ein Team des kalifornischen Unternehmens Dascena seine Erkenntnisse in einer Studie bekannt, bei der eine retrospektive Forschungsmethode zum Einsatz kam.Anhand der Daten von 32.000 Patienten aus der klinischen Datenbank MIMIC II wurde durch die Korrelation von neun gängigen Vitalzeichenmessungen ein Frühwarnalgorithmus für Sepsis namens InSight entwickelt.Die Ergebnisse zeigten, dass der Algorithmus eine Sensitivität von 0,90 und eine Spezifität von 0,81 bei der Vorhersage einer Sepsis 3 Stunden vor dem Beginn des anhaltenden systemischen Entzündungsreaktionssyndroms (SIRS) aufwies und damit bestehende Methoden zur Biomarker-Erkennung übertraf. Die Forschungsarbeit wurde unter dem Titel „Ein rechnergestützter Ansatz zur Früherkennung von Sepsis“ veröffentlicht.
Papieradresse:
https://www.sciencedirect.com/science/article/abs/pii/S0010482516301123?via%3Dihub
Durch die Integration künstlicher Intelligenz und Intensivmedizin ist eine frühzeitige Warnung vor einer Sepsis nicht mehr schwierig. Diese Studie füllt zweifellos die Lücke, die durch die fehlende rechtzeitige Warnung entsteht, wenn sich eine Sepsis zu einem kritischen Stadium entwickelt, und stellt eine Untersuchung mit größerem medizinischen Wert dar. Wichtiger ist natürlich die in dieser Studie erwähnte Fusionsstrategie, die die Gesamtleistung des gesamten Modells verbessert, indem sie die Sensitivitäts- und Spezifitätsvorteile der Untermodelle ausgleicht. Dies ebnet den Weg für die Lösung ähnlicher Probleme durch die Integration mehrerer Modelle in der Zukunft und regt zu weiterer Forschung an, um praktische Schwierigkeiten in medizinischen Szenarien durch ähnliche Methoden zu lösen.








