Command Palette
Search for a command to run...
Zusammenfassung Der Praktischen vLLM-Tutorials, Von Der Umgebungskonfiguration Bis Zur Bereitstellung Großer Modelle, Chinesische Dokumentation Zur Verfolgung Wichtiger Updates

Während sich das Large Language Model (LLM) immer mehr in Richtung Engineering und großflächiger Bereitstellung bewegt, werden seine Argumentationseffizienz, Ressourcennutzung und Hardware-Anpassbarkeit zu zentralen Themen, die die Implementierung von Anwendungen beeinflussen. Im Jahr 2023 veröffentlichte ein Forschungsteam der University of California, Berkeley, vLLM als Open Source. Es führte den PagedAttention-Mechanismus zur effizienten Verwaltung des KV-Cache ein, verbesserte den Modelldurchsatz und die Reaktionsgeschwindigkeit erheblich und erfreute sich in der Open-Source-Community schnell großer Beliebtheit. Bis jetzt hat vLLM auf GitHub über 46.000 Sterne und ist ein Starprojekt im Rahmen des großen Model Reasoning Frameworks.
27. Januar 2025vLLM-Team hat die Alpha-Version v1 veröffentlicht,Die Kernarchitektur wurde auf Basis der Entwicklungsarbeit der letzten zwei Jahre systematisch neu strukturiert.Der Kern dieser aktualisierten Version v1 ist eine umfassende Rekonstruktion der Ausführungsarchitektur.Der isolierte EngineCore wird eingeführt, um sich auf die Modellausführungslogik zu konzentrieren, eine tiefe Multiprozessintegration zu übernehmen, eine CPU-Aufgabenparallelisierung und eine tiefe Multiprozessintegration durch ZeroMQ zu realisieren und die API-Schicht explizit vom Inferenzkern zu trennen, was die Systemstabilität erheblich verbessert.
Gleichzeitig wird der Unified Scheduler eingeführt, der über die Funktionen einer feinen Planungsgranularität, Unterstützung für spekulative Dekodierung, Chunked Prefill usw. verfügt.Verbessern Sie die Latenzkontrollfunktionen und behalten Sie gleichzeitig einen hohen Durchsatz bei.
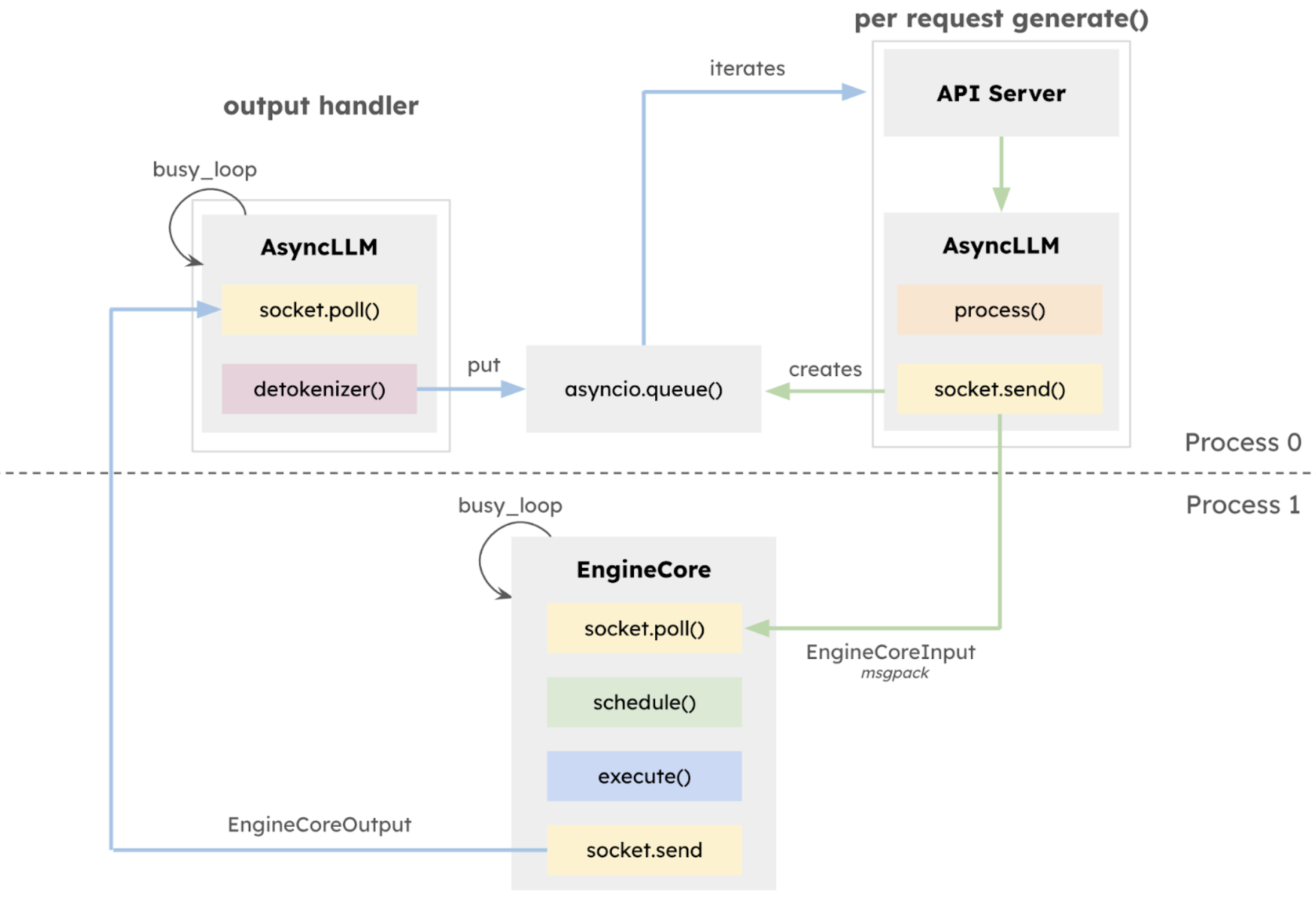
Auch,vLLM v1 verwendet ein bahnbrechendes stufenloses Planungsdesign.Die Verarbeitung von Benutzereingaben und Modellausgabetoken wurde optimiert und die Planungslogik vereinfacht. Der Scheduler unterstützt nicht nur Chunked Prefill und Präfix-Caching, sondern kann auch spekulative Dekodierung durchführen und so die Inferenzeffizienz effektiv verbessern.
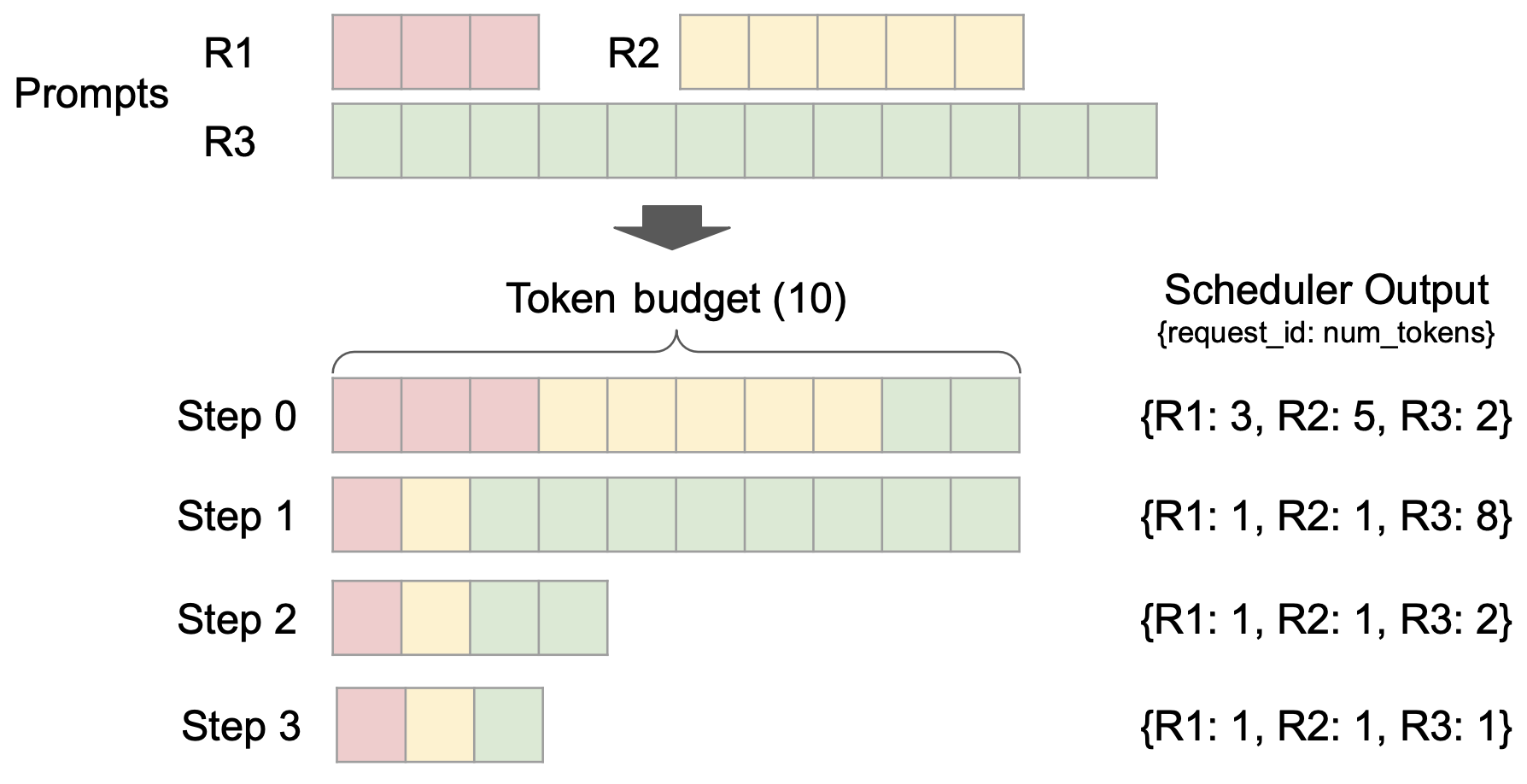
Ein weiteres Highlight ist die Optimierung des Cache-Mechanismus. vLLM v1 implementiert Präfix-Caching ohne Overhead.Selbst in Szenarien mit langen Textschlüssen und extrem niedrigen Cache-Trefferquoten können wiederholte Berechnungen effektiv vermieden und die Konsistenz und Effizienz des Schlussfolgerns verbessert werden.
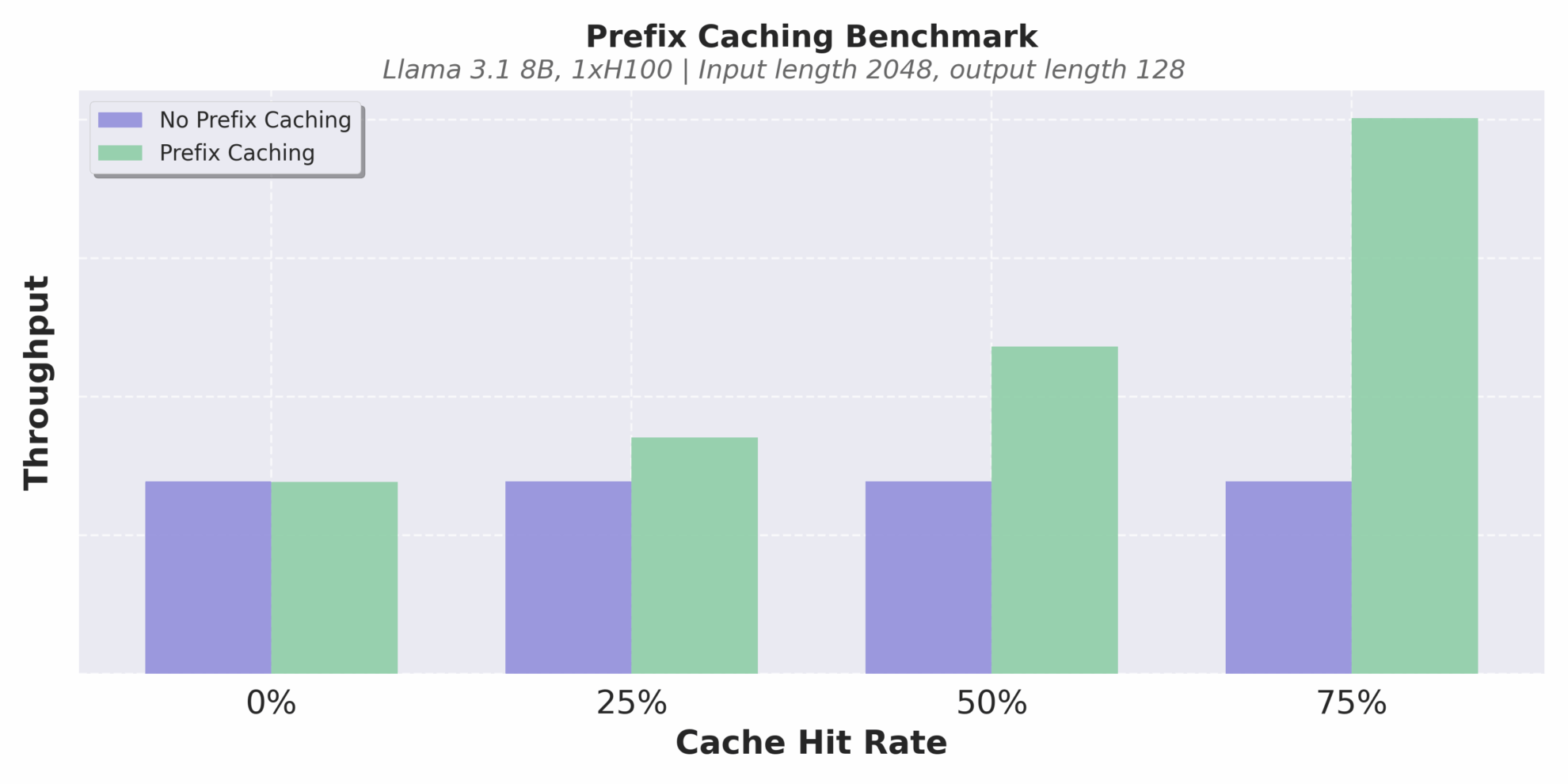
Durchsatz bei unterschiedlichen Cache-Trefferraten
Wie aus der folgenden Abbildung ersichtlich ist, erhöht sich der Durchsatz von vLLM v1 im Vergleich zu v0 um das bis zu 1,7-fache, insbesondere bei hohem QPS ist die Leistungsverbesserung deutlicher. Es ist zu beachten, dass sich vLLM v1 als Alpha-Version noch in der aktiven Entwicklung befindet und möglicherweise Stabilitäts- und Kompatibilitätsprobleme aufweist. Die Richtung der architektonischen Entwicklung weist jedoch eindeutig auf hohe Leistung, hohe Wartbarkeit und hohe Modularität hin und legt damit eine solide Grundlage für nachfolgende Teams, um schnell neue Funktionen zu entwickeln.
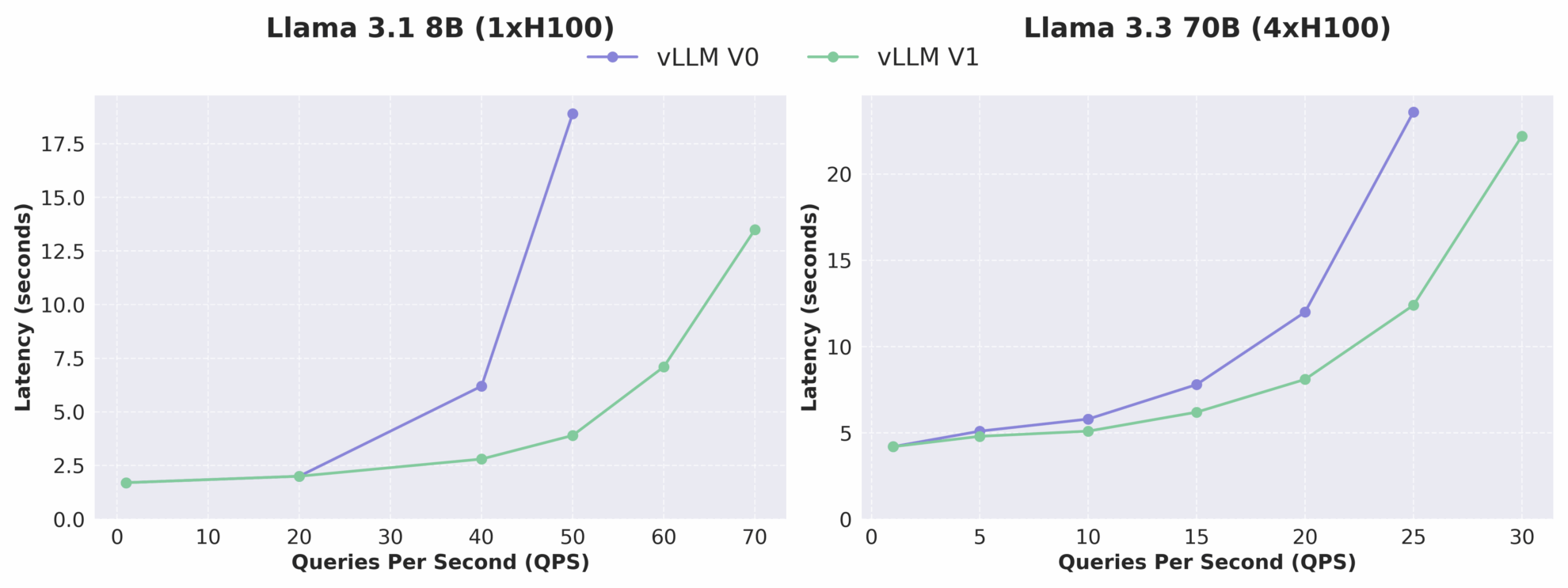
Vergleich der Latenz-QPS-Beziehung zwischen vLLM V0 und V1
Erst letzten Monat hat das vLLM-Team außerdem ein kleineres Versionsupdate durchgeführt, bei dem der Schwerpunkt auf der Verbesserung der Modellkompatibilität und der Argumentationsstabilität lag. Diese aktualisierte Version vLLM v0.8.5 bietet ab sofort Unterstützung für Qwen3- und Qwen3MoE-Modelle, fügt eine fusionierte FP8_W8A8 MoE-Kernelkonfiguration hinzu, behebt kritische Fehler in multimodalen Szenarien und verbessert die Leistungsrobustheit in Produktionsumgebungen weiter.
Um Ihnen den Einstieg in vLLM zu erleichtern, hat der Herausgeber eine Reihe praktischer Tutorials und Modellfälle zusammengestellt, die den gesamten Prozess von der Grundinstallation bis zur Inferenzbereitstellung abdecken.Helfen Sie allen, schnell loszulegen und ein tiefgreifendes Verständnis zu erlangen. Interessierte Freunde, kommt und erlebt es!
Weitere chinesische vLLM-Dokumente und Tutorials finden Sie unter:
Grundlegendes Tutorial
1 . vLLM-Tutorial: Eine Schritt-für-Schritt-Anleitung für Anfänger
* Online ausführen:https://go.hyper.ai/Jy22B
Dieses Lernprogramm zeigt Schritt für Schritt, wie vLLM konfiguriert und ausgeführt wird. Es bietet eine vollständige Anleitung zum Einstieg in die Installation von vLLM, zur Modellinferenz, zum Starten des vLLM-Servers und zum Stellen von Anfragen.
2 . Verwenden von vLLM zum Nachdenken über Qwen2.5
* Online ausführen:https://go.hyper.ai/SwVEa
Dieses Tutorial zeigt detailliert, wie Sie Reasoning-Aufgaben an einem großen Sprachmodell mit 3B-Parametern durchführen, einschließlich Modellladen, Datenvorbereitung, Optimierung des Reasoning-Prozesses sowie Extraktion und Auswertung der Ergebnisse.
3 . Laden großer Modelle mit vLLM , Führen Sie ein Lernen mit wenigen Beispielen durch
* Online ausführen:https://go.hyper.ai/OmVjM
Dieses Tutorial verwendet vLLM, um das Qwen2.5-3B-Instruct-AWQ-Modell für Few-Shot-Learning zu laden. Es wird ausführlich erklärt, wie Trainingsdaten abgerufen werden, um ähnliche Fragen zum Aufbau von Dialogen zu erhalten, das Modell zum Generieren verschiedener Ausgaben zu verwenden, Missverständnisse zu erkennen und verwandte Methoden für eine integrierte Rangfolge usw. zu kombinieren, um einen vollständigen Prozess von der Datenaufbereitung bis zur Ergebnisübermittlung zu erreichen.
4 . Kombination von LangChain mit vLLM , Lernprogramm
* Online ausführen:https://go.hyper.ai/Y1EbK
Dieses Tutorial konzentriert sich auf die Verwendung von LangChain mit vLLM und zielt darauf ab, die Entwicklung intelligenter LLM-Anwendungen zu vereinfachen und zu beschleunigen. Es deckt ein breites Spektrum an Inhalten ab, von grundlegenden Einstellungen bis hin zu erweiterten funktionalen Anwendungen.
Große Modellbereitstellung
1 . Stellen Sie Qwen3-30B-A3B mit vLLM bereit
* Ausstellende Behörde:Alibaba Qwen Team
* Online ausführen:https://go.hyper.ai/6Ttdh
Qwen3-235B-A22B zeigte in Benchmarktests wie Code, Mathematik und allgemeinen Fähigkeiten vergleichbare Fähigkeiten wie DeepSeek-R1, o1, o3-mini, Grok-3 und Gemini-2.5-Pro . Es ist erwähnenswert, dass die Anzahl der aktivierten Parameter von Qwen3-30B-A3B nur 10% von QwQ-32B beträgt, aber seine Leistung ist besser. Sogar ein kleines Modell wie Qwen3-4B kann die Leistung von Qwen2.5-72B-Instruct erreichen.
2 . Stellen Sie GLM-4-32B mit vLLM bereit
* Ausstellende Behörde:Zhipu AI, Tsinghua-Universität
* Online ausführen:https://go.hyper.ai/HJqqO
GLM-4-32B-0414 erzielte gute Ergebnisse in den Bereichen Code-Engineering, Artefaktgenerierung, Funktionsaufruf, suchbasierte Fragebeantwortung und Berichterstellung. Insbesondere bei mehreren Benchmarks wie der Codegenerierung oder bestimmten Frage-und-Antwort-Aufgaben erreicht GLM-4-32B-Base-0414 eine vergleichbare Leistung wie größere Modelle wie GPT-4o und DeepSeek-V3-0324 (671B).
3 . Bereitstellung mit vLLM , DeepCoder-14B-Vorschau
* Ausstellende Behörde:Agentica Team, Together AI
* Online ausführen:https://go.hyper.ai/sYwfO
Das Modell basiert auf DeepSeek-R1-Distilled-Qwen-14B und wird durch verteiltes Verstärkungslernen (RL) feinabgestimmt. Es verfügt über 14 Milliarden Parameter und erreichte im LiveCodeBench v5-Test eine Pass@1-Genauigkeit von 60,6%, die mit dem o3-mini von OpenAI vergleichbar ist.
4 . Bereitstellung mit vLLM , Gemma-3-27B-IT
* Ausstellende Behörde:MetaGPT-Team
* Online ausführen:https://go.hyper.ai/0rZ7j
Gemma 3 ist ein großes multimodales Modell, das Text- und Bildeingaben verarbeiten und Textausgaben generieren kann. Sowohl die vortrainierten als auch die auf Anweisungen abgestimmten Varianten bieten offene Gewichte für eine Vielzahl von Aufgaben zur Textgenerierung und zum Bildverständnis, einschließlich der Beantwortung von Fragen, Zusammenfassungen und Schlussfolgerungen. Ihre relativ geringe Größe ermöglicht ihren Einsatz in Umgebungen mit begrenzten Ressourcen. Dieses Tutorial verwendet gemma-3-27b-it als Demonstration für die Modellinferenz.
Weitere Anwendungen
1 .OpenManus + QwQ-32B , Implementierung eines KI-Agenten
* Ausstellende Behörde:MetaGPT-Team
* Online ausführen:https://go.hyper.ai/RqNME
OpenManus ist ein Open-Source-Projekt, das im März 2025 vom MetaGPT-Team gestartet wurde. Ziel ist es, die Kernfunktionen von Manus zu replizieren und Benutzern eine intelligente Agentenlösung bereitzustellen, die ohne Einladungscode lokal bereitgestellt werden kann. QwQ ist das Argumentationsmodell der Qwen-Reihe. Im Vergleich zu herkömmlichen Modellen zur Befehlsoptimierung verfügt QwQ über Denk- und Argumentationsfähigkeiten und kann bei nachgelagerten Aufgaben, insbesondere bei schwierigen Problemen, erhebliche Leistungsverbesserungen erzielen. Dieses Tutorial bietet Inferenzdienste für OpenManus basierend auf dem QwQ-32B-Modell und gpt-4o.
2 .RolmOCR – Szenarioübergreifende ultraschnelle OCR , Neuer Open-Source-Identifikations-Benchmark
* Ausstellende Behörde:Reducto AI
* Online ausführen:https://go.hyper.ai/U3HRH
RolmOCR ist ein Open-Source-OCR-Tool, das auf Basis des visuellen Sprachmodells Qwen2.5-VL-7B entwickelt wurde. Es kann Text schnell und mit geringem Speicherverbrauch aus Bildern und PDFs extrahieren und übertrifft damit ähnliche Tools wie olmOCR. RolmOCR ist nicht auf PDF-Metadaten angewiesen, rationalisiert den Prozess und unterstützt eine breite Palette von Dokumenttypen, wie handschriftliche Notizen und wissenschaftliche Arbeiten.
Das Obige ist das vom Herausgeber erstellte vLLM-bezogene Tutorial. Wenn Sie Interesse haben, kommen Sie vorbei und erleben Sie es selbst!
Um inländischen Benutzern zu helfen, vLLM besser zu verstehen und anzuwenden,Freiwillige der HyperAI-Community haben zusammengearbeitet, um das erste chinesische vLLM-Dokument fertigzustellen, das jetzt vollständig auf hyper.ai verfügbar ist.Der Inhalt umfasst Modellprinzipien, Bereitstellungstutorials und Versionsinterpretationen und bietet chinesischen Entwicklern einen systematischen Lernpfad und praktische Ressourcen.
Weitere chinesische vLLM-Dokumente und Tutorials finden Sie unter:https://vllm.hyper.ai








