Command Palette
Search for a command to run...
EasyControl, Ein Tool Zum Erstellen Von Gemälden Im Ghibli-Stil, Wird Mit Einem Klick Gestartet; Ein Einzelnes Bild Kann in Sekundenschnelle in Ein 3D-Modell Umgewandelt werden. TripoSG Revolutioniert Die 3D-Asset-Generierung

Bilder im Ghibli-Stil haben in letzter Zeit die sozialen Medien im Sturm erobert. Wenn Menschen Filmen oder Fernsehserien Filter im Animationsstil von Hayao Miyazaki hinzufügen, ist es, als würden sie in eine Märchenwelt voller Fantasie versetzt. Für viele Benutzer, die selbst Bilder im Ghibli-Stil erstellen möchten, weisen die vorhandenen Generationsmodelle jedoch häufig Probleme auf, wie beispielsweise eine komplexe Bedienung, eine hohe Nutzungsschwelle oder unbefriedigende Generationseffekte.
EasyControl senkt mit seiner fortschrittlichen Technologie und der einfachen und benutzerfreundlichen Benutzeroberfläche die Hürde für die Erstellung erheblich.Es führt eine leichte bedingte Injektion ein LoRA-Modul, ortsbezogenes Trainingsparadigma undKausaler AufmerksamkeitsmechanismusUnd KV Cache-Technologie, wodurch die Modellkompatibilität erheblich verbessert wird und Plug-and-Play-Funktionalität sowie zerstörungsfreie Stilkontrolle unterstützt werden.
derzeit,HyperAIDas Tutorial „Demo zur Bildgenerierung im EasyControl Ghibli-Stil“ wurde gestartet.Demo verwendet das stilisierte Img2Img-Steuerungsmodell, um ein Porträt inMiyazaki-StilKunstwerke, kommen Sie und probieren Sie es aus~
Online-Nutzung:https://go.hyper.ai/jWm9j
Vom 21. bis 25. April gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Hochwertige Tutorials: 12
* Community-Artikelauswahl: 4 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im April: 1
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Spanischer Verkehrsluftbilddatensatz
Der Datensatz enthält 15.070 von unbemannten Luftfahrzeugen (UAVs) aufgenommene Bildrahmen und deckt eine Vielzahl von Verkehrsszenarien ab, darunter Regionalstraßen, städtische Kreuzungen, Landstraßen und verschiedene Arten von Kreisverkehren. In den Bildern sind 155.328 Objekte annotiert, davon 137.602 Autos und 17.726 Motorräder. Diese Bilder sind YOLO-FormatDie Speicherung eignet sich gut zum Trainieren von Bildverarbeitungsalgorithmen auf Basis von Convolutional Neural Networks.
Direkte Verwendung:https://go.hyper.ai/VJoXE

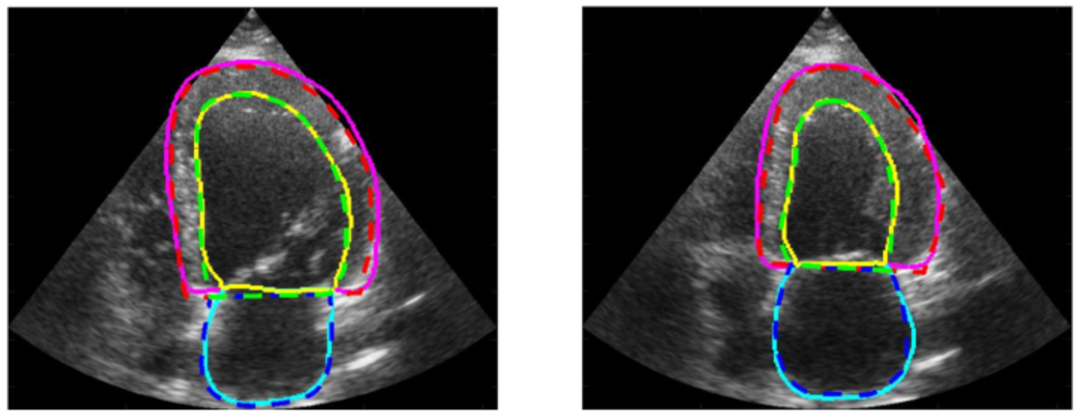
2. CAMUS Herzultraschall-Bilddatensatz
Der Datensatz enthält 2D-apikale Vierkammer- und Zweikammer-Ansichtssequenzen von 500 Patienten, die am Universitätsklinikum Saint-Étienne in Frankreich gesammelt und vollständig anonymisiert wurden, um die Privatsphäre der Patienten und die Datenkonformität zu gewährleisten. Jedes Bild wurde von medizinischem Fachpersonal sorgfältig kommentiert und enthält die Konturinformationen des linken Ventrikelendokards, des linken Ventrikelepikards und des linken Vorhofs. Diese ausführlichen Anmerkungen bieten Forschern umfangreiche Schulungs- und Überprüfungsressourcen.
Direkte Verwendung:https://go.hyper.ai/iYtn2
Dieser Datensatz enthält 26,9.000 Bilder mit nur der Bildkategorie „Schiff“. Diese Bilder sind speziell für die Schiffserkennung sorgfältig kommentiert. Die Begrenzungsrahmenanmerkungen werden im YOLO-Format dargestellt, wodurch Schiffe in den Bildern genau und effizient erkannt werden können.
Direkte Verwendung:https://go.hyper.ai/s03Tk

4. SkyCity Aerial City Landscape Stadtlandschafts-Luftbilddatensatz
Dieser Datensatz ist ein ausgewählter Datensatz zur Klassifizierung von Landschaften aus der Luft mit insgesamt 8.000 Bildern, darunter 10 verschiedene Kategorien. Jede Kategorie enthält 800 qualitativ hochwertige Bilder mit einer Auflösung von 256 × 256 Pixeln. Dieser Datensatz vereint Stadtlandschaften aus den öffentlich verfügbaren AID- und NWPU-Resisc45-Datensätzen und soll die Analyse von Stadtlandschaften erleichtern.
Direkte Verwendung:https://go.hyper.ai/eCRdN

5. 302 Datensätze zu seltenen Krankheiten
Der Datensatz enthält 302 seltene Krankheiten, wobei aus jeder Kategorie 1 bis 9 seltene Krankheiten zufällig ausgewählt wurden. Diese seltenen Krankheiten wurden aus über 7.000 seltenen Krankheiten 33 Typen in der Orphanet-Datenbank ausgewählt, einer umfassenden Datenbank für seltene Krankheiten, die von der Europäischen Kommission kofinanziert wird.
Direkte Verwendung:https://go.hyper.ai/LwqME
6. DRfold2-RNA-Strukturtestdatensatz
Dieser Datensatz ist ein unabhängiger Testdatensatz, der erstellt wurde, um die Leistung von DRfold2 in dieser Studie objektiv zu bewerten. Es enthält 28 RNA-Strukturen mit einer Sequenzlänge von weniger als 400 nts und stammt aus den folgenden 3 Kategorien: die neuesten RNA-Puzzles-Zielsequenzen; RNA-Zielsequenzen im CASP15-Wettbewerb; und die neuesten veröffentlichten RNA-Strukturen in der Protein Data Bank (PDB)-Datenbank mit Stand 1. August 2024.
Direkte Verwendung:https://go.hyper.ai/shkp6
7. HMC-QU kardialer medizinischer Bilddatensatz
Der Datensatz enthält zweidimensionale echokardiografische (Echo-)Aufzeichnungen der apikalen Vierkammeransichten (A4C) und der apikalen Zweikammeransichten (A2C), die in den Jahren 2018 und 2019 aufgenommen wurden. Die Aufzeichnungen wurden mit Geräten verschiedener Hersteller (z. B. Ultraschallgeräten von Phillips und GE Vivid) mit einer zeitlichen Auflösung von 25 Bildern/s und einer räumlichen Auflösung von 422 × 636 bis 768 × 1024 Pixeln aufgenommen.
Direkte Verwendung:https://go.hyper.ai/gQN8a
8. Reasoning-v1-20m-Argumentationsdatensatz
Reasoning-v1-20m enthält etwa 20 Millionen Reasoning-Traces und deckt komplexe Probleme in mehreren Bereichen wie Mathematik, Programmierung und Naturwissenschaften ab. Dieser Datensatz soll dem Modell dabei helfen, komplexe Denklogik zu erlernen und seine Leistung bei mehrstufigen Denkaufgaben zu verbessern, indem er umfangreiche Beispiele des Denkprozesses liefert.
Direkte Verwendung:https://go.hyper.ai/c2RqP
9. II-Thought-RL-v0 Multi-Task-Fragen-Antwort-Datensatz
II-Thought-RL-v0 ist ein umfangreicher Multitasking-Datensatz, der für bestärkendes Lernen und Problembeantwortung entwickelt wurde. Es enthält hochwertige Frage-Antwort-Paare, die in mehreren Schritten streng gefiltert wurden und mehrere Bereiche wie Mathematik, Programmierung und Naturwissenschaften abdecken. Die Fragenpaare im Datensatz stammen nicht nur aus öffentlichen Datensätzen, sondern enthalten auch maßgeschneiderte Fragenpaare hoher Qualität, um die Vielfalt und Praktikabilität der Daten sicherzustellen.
Direkte Verwendung:https://go.hyper.ai/9eSSq
10. AM-DeepSeek-R1-Distilled-1.4M Großer Datensatz für allgemeine Denkaufgaben
Der Datensatz enthält ungefähr 1,4 Millionen Dateneinträge und decken eine Vielzahl von Fragetypen ab, darunter Mathematik, Code, wissenschaftliche Fragen und Antworten und allgemeiner Chat. Diese Daten wurden sorgfältig ausgewählt, semantisch dedupliziert und streng bereinigt, um die hohe Qualität und Relevanz der Daten sicherzustellen. Jeder Eintrag im Datensatz enthält ausführliche Denkspuren, die dem Modell nicht nur Beispiele für den Denkprozess liefern, sondern dem Modell auch dabei helfen, komplexe Denkaufgaben besser zu verstehen und Lösungen dafür zu generieren.
Direkte Verwendung:https://go.hyper.ai/2PSxR
Ausgewählte öffentliche Tutorials
1. YOLOE: Alles in Echtzeit sehen
YOLOE ist ein neues visuelles Echtzeitmodell, das von einem Forschungsteam der Tsinghua-Universität im Jahr 2025 vorgeschlagen wurde und das Ziel erreichen soll, „alles in Echtzeit zu sehen“. Es übernimmt die Echtzeit- und Effizienzeigenschaften der YOLO-Modellreihe und integriert auf dieser Grundlage Zero-Shot-Learning und multimodale Eingabeaufforderungsfunktionen umfassend und kann die Zielerkennung und -segmentierung in mehreren Szenarien wie Text, Sicht und stiller Eingabeaufforderung unterstützen.
Die relevanten Modelle und Abhängigkeiten dieses Projekts wurden bereitgestellt. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen.
Online ausführen:https://go.hyper.ai/rOIS1

2. Ein-Klick-Bereitstellung von R1-OneVision
R1-OneVision ist ein großes multimodales Denkmodell, das von einem Team der Zhejiang-Universität veröffentlicht wurde. Das Modell wird basierend auf Qwen2.5-VL auf dem R1-Onevision-Datensatz feinabgestimmt. Es eignet sich gut für die Bewältigung komplexer visueller Denkaufgaben und die nahtlose Integration visueller und textueller Daten. Es eignet sich gut für Bereiche wie Mathematik, Naturwissenschaften, tiefes Bildverständnis und logisches Denken und kann als leistungsstarker KI-Assistent zur Lösung verschiedener Probleme dienen.
In diesem Tutorial wird R1-Onevision-7B als Demonstration verwendet und die Rechenressource verwendet RTX 4090. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen.
Online ausführen:https://go.hyper.ai/7I2pi
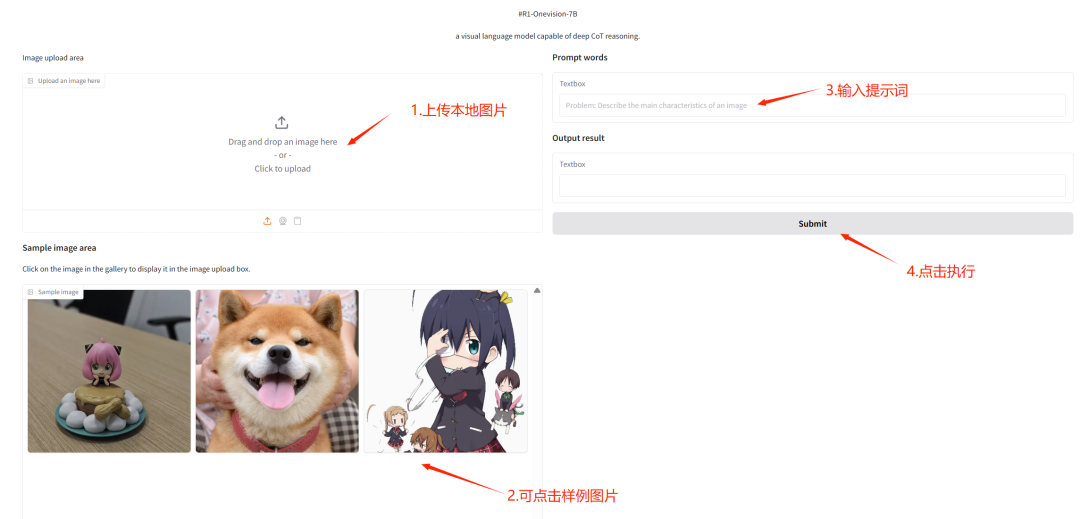
3. UNO: Universelle kundenspezifische Bildgenerierung
Das UNO-Projekt kann sowohl die Bildgenerierung für einzelne als auch für mehrere Motive unterstützen, indem es mehrere Aufgaben mit einem Modell vereint und starke Generalisierungsfähigkeiten demonstriert.
Dieses Projekt basiert auf FLUX.1-dev-fp 8 und kann schnell Text erkennen und Bilder basierend auf Textbeschreibungen generieren.
Online ausführen:https://go.hyper.ai/r8JZo
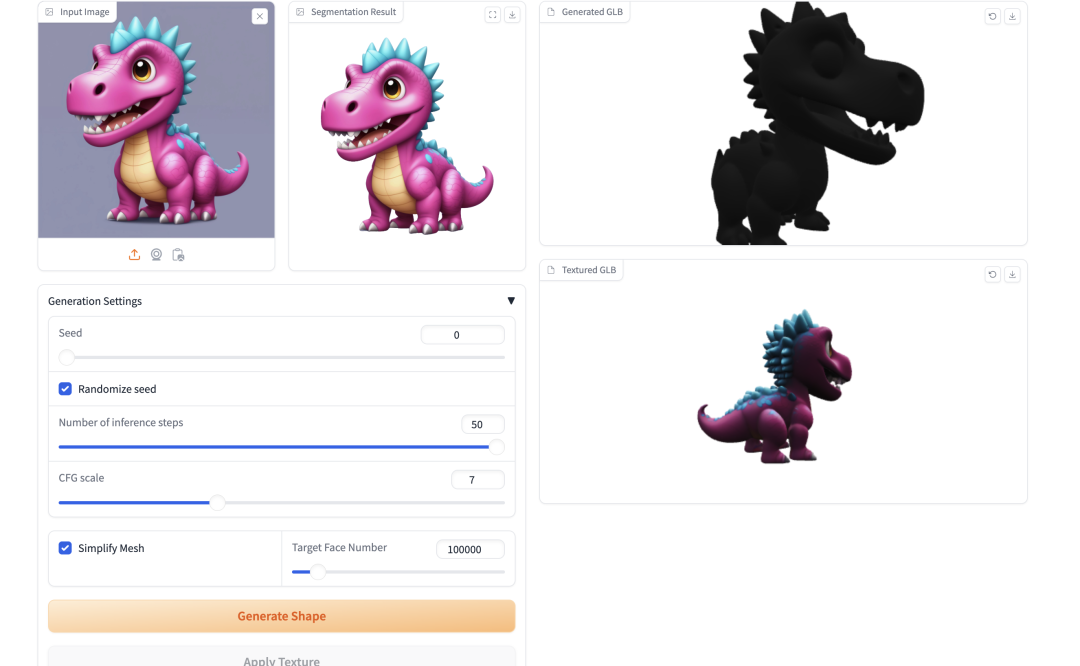
4. TripoSG: Verwandeln Sie ein einzelnes Bild in Sekundenschnelle in hochauflösendes 3D
TripoSG ist ein fortschrittliches generatives Bild-zu-3D-Basismodell mit hoher Wiedergabetreue, hoher Qualität und hoher Allgemeingültigkeit. Es nutzt groß angelegte gleichgerichtete Transformatoren, hybrides überwachtes Training und hochwertige Datensätze, um eine hochmoderne Leistung bei der 3D-Formgenerierung zu erzielen.
Die relevanten Modelle und Abhängigkeiten dieses Projekts wurden bereitgestellt. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen.
Online ausführen:https://go.hyper.ai/rcWwu
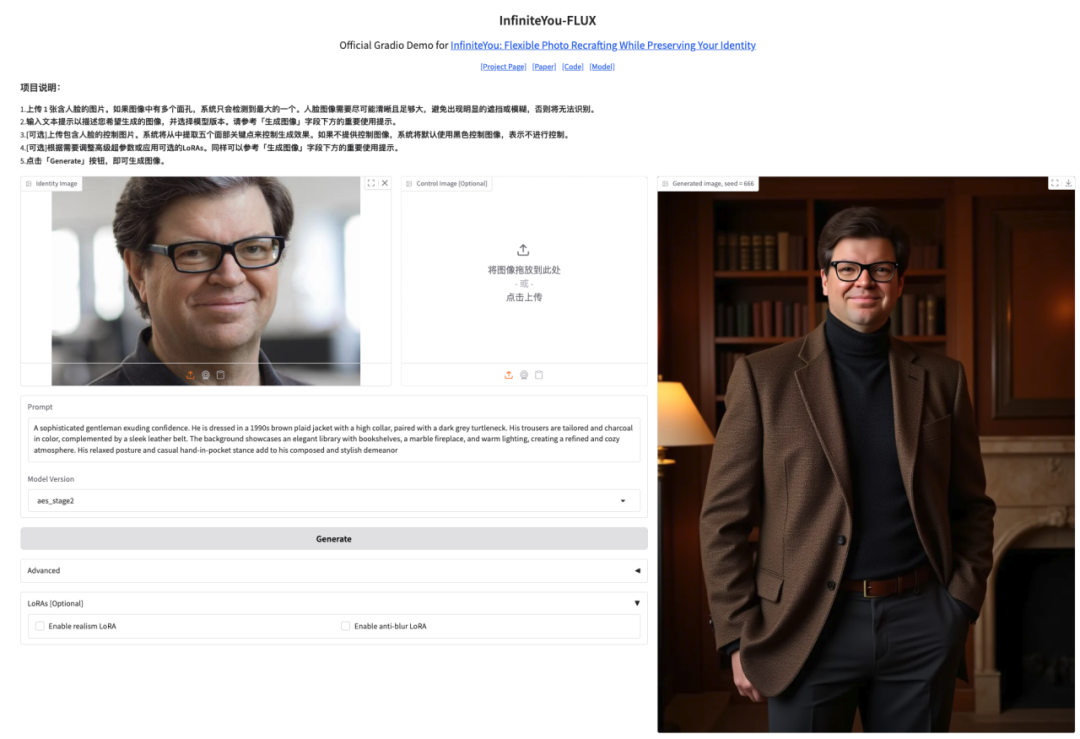
5. InfiniteYou High-Fidelity-Bildgenerierungsdemo
InfiniteYou, abgekürzt InfU, ist ein identitätserhaltendes Framework zur Bildgenerierung auf Basis von Diffusion Transformers (wie FLUX), das 2025 vom intelligenten Erstellungsteam von ByteDance eingeführt wurde. Durch fortschrittliche Technologie ist es in der Lage, die Konsistenz der Identität der Person bei der Bildgenerierung aufrechtzuerhalten und so die Mängel bestehender Methoden hinsichtlich Identitätsähnlichkeit, Text-Bild-Ausrichtung und Generierungsqualität zu beheben.
Dieses Tutorial verwendet InfiniteYou-FLUX v1.0 als Demonstration und die Rechenleistungsressource ist A6000. Klicken Sie auf den Link unten, um das Modell schnell zu klonen.
Online ausführen:https://go.hyper.ai/K5Yl5
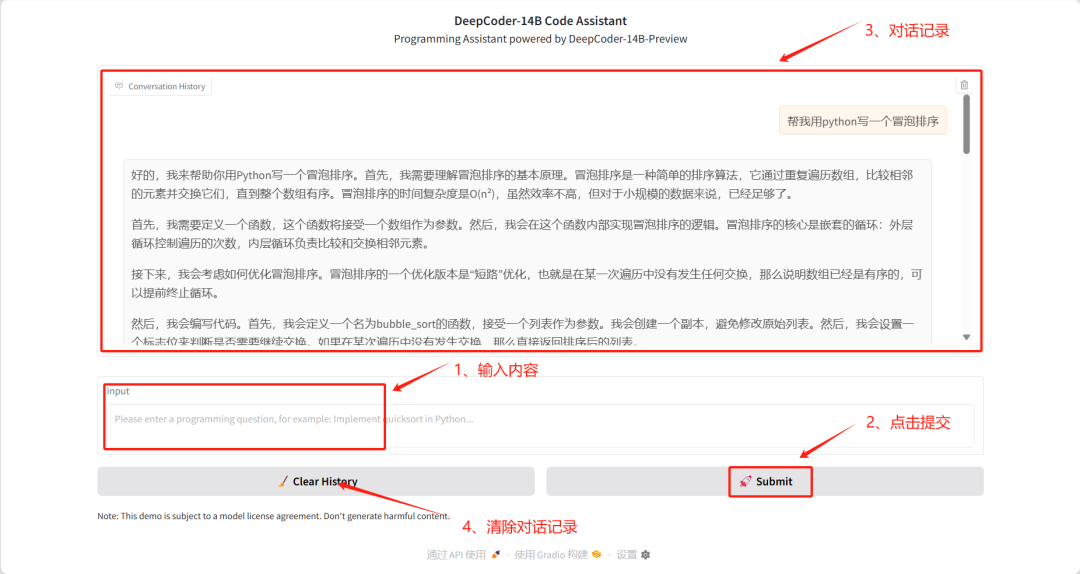
6. Ein-Klick-Bereitstellung von DeepCoder-14B-Preview
Das DeepCoder-14B-Preview-Projekt ist ein 14B-Kodierungsmodell, das am 8. April 2025 von AGENTICA veröffentlicht wurde. Das Modell wurde für die Code-Reasoning-Analyse mit DeepSeek-R1-Distilled-Qwen-14B LLM optimiert und lässt sich mithilfe von Distributional Reinforcement Learning (RL) auf große Kontextlängen skalieren. Das Modell erreicht eine Pass@1-Genauigkeit von 60,6% auf LiveCodeBench v5 (01.08.24-01.02.25), eine Verbesserung von 8% gegenüber dem Basismodell (53%), und erreicht eine ähnliche Leistung wie OpenAIs o3-mini mit nur 14B Parametern.
Dieses Tutorial verwendet das DeepCoder-14B-Preview-Modell als Demonstrationsfall und übernimmt die von Bitsandbytes bereitgestellte 8-Bit-Quantisierungsmethode, um die Nutzung des Videospeichers zu optimieren.
Online ausführen:https://go.hyper.ai/17aD2
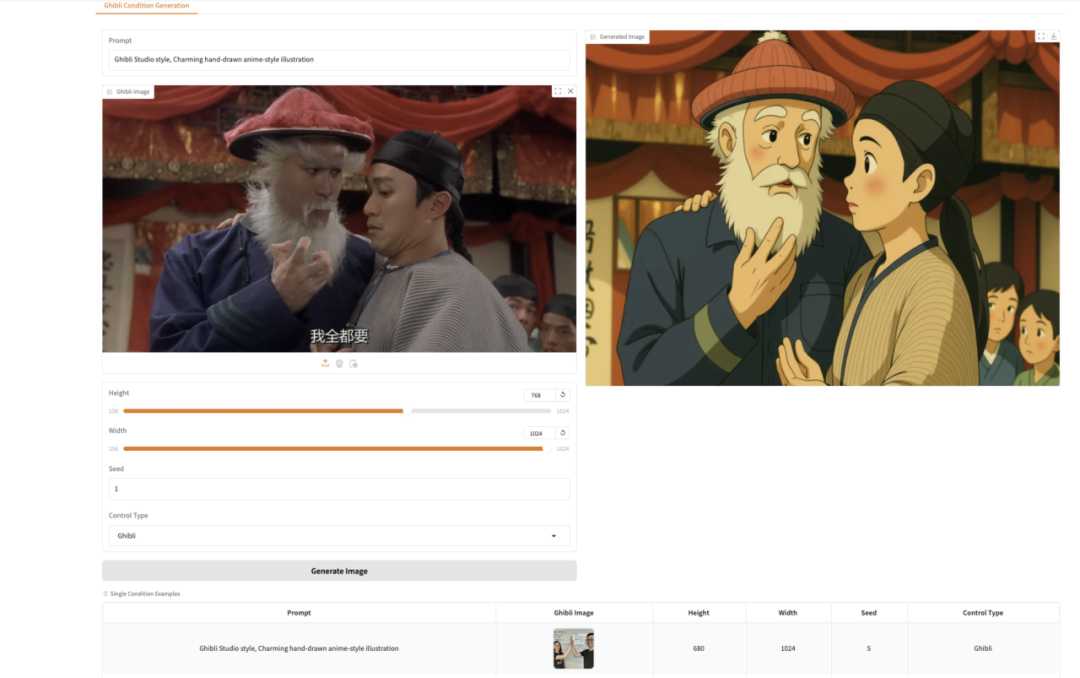
7. EasyControl Ghibli-Stil-Demo zur Bildgenerierung
EasyControl ist ein Projekt, dessen Ziel darin besteht, dem Diffusion Transformer eine effiziente und flexible Steuerung hinzuzufügen. Das Projekt verbessert die Modellkompatibilität erheblich, indem es leichte LoRA-Module mit bedingter Injektion und ortsabhängige Trainingsparadigmen einführt und Mechanismen der kausalen Aufmerksamkeit mit KV-Cache-Technologie kombiniert, wodurch Plug-and-Play-Funktionalität und verlustfreie Stilkontrolle unterstützt werden.
In diesem Tutorial wird das Modell „Stylized Img2Img Controls“ verwendet, mit dem ein Porträt in ein Kunstwerk im Stil von Hayao Miyazaki umgewandelt werden kann, wobei die Gesichtszüge erhalten bleiben und die ikonische Anime-Ästhetik angewendet wird.
Online ausführen:https://go.hyper.ai/jWm9j
8. Qwen2.5-0mni: Vollständige Modusunterstützung zum Lesen, Hören und Schreiben
Qwen2.5-Omni ist das neueste durchgängige multimodale Flaggschiffmodell, das vom Tongyi Qianwen-Team von Alibaba herausgebracht wurde. Es ist für eine umfassende multimodale Wahrnehmung konzipiert und verarbeitet nahtlos verschiedene Eingaben, darunter Text, Bilder, Audio und Video, während es die Streaming-Textgenerierung und die Ausgabe durch natürliche Sprachsynthese unterstützt.
Dieses Tutorial verwendet Qwen2.5-Omni als Demonstration und die Rechenressourcen sind A6000.
Online ausführen:https://go.hyper.ai/eghWg
9. Ein-Klick-Bereitstellung von Qwen2.5-VL-32B-Instruct
Qwen2.5-VL-32B-Instruct ist ein Open-Source-multimodales Großmodell, das vom Alibaba Tongyi Qianwen-Team entwickelt wurde. Dieses auf der Qwen2.5-VL-Reihe basierende Modell wird durch Reinforcement-Learning-Technologie optimiert und erzielt mit einer 32B-Parameterskala einen Durchbruch bei den multimodalen Fähigkeiten.
Dieses Tutorial verwendet Qwen2.5-VL-32B als Demonstration und die Rechenressourcen betragen A6000*2. Zu den Funktionen gehören Textverständnis, Bildverständnis und Videoverständnis.
Online ausführen:https://go.hyper.ai/Dp2Pd
10. Ein-Klick-Bereitstellung Qwen2.5-VL-32B-Instruct-AWQ
Qwen2.5-VL-32B-Instruct-AWQ ist eine quantisierte Version von Qwen2.5-VL-32B-Instruct, die die Programmier- und mathematischen Rechenfähigkeiten erheblich verbessert. Das Modell unterstützt Interaktionen in 29 Sprachen, kann lange Texte mit 128.000 Token verarbeiten und verfügt über Kernfunktionen wie strukturiertes Datenverständnis und JSON-Generierung. Es wurde auf Grundlage der Transformer-Architektur entwickelt, ermöglicht eine effiziente Bereitstellung durch Quantisierungstechnologie und eignet sich für groß angelegte KI-Anwendungsszenarien.
Die relevanten Modelle und Abhängigkeiten dieses Projekts wurden bereitgestellt. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen.
Online ausführen:https://go.hyper.ai/fAYEK
Seit seiner Veröffentlichung hat DeepCoder-14B-Preview auf GitHub über 3.000 Sterne für seine herausragende Leistung beim Codeverständnis und bei Schlussfolgerungsaufgaben erhalten. Das Modell hat in mehreren Bewertungen mit denen von o3-mini vergleichbare Fähigkeiten bewiesen und verfügt über eine effiziente Argumentationsleistung und gute Skalierbarkeit.
Um Entwicklern dabei zu helfen, das Modell schnell kennenzulernen und einzusetzen, wurde im Tutorial-Bereich der offiziellen Website von HyperAl das Tutorial „Ein-Klick-Bereitstellung von DeepCoder-14B-Preview“ gestartet. Klicken Sie auf den Link unten, um schnell zu beginnen.
Online ausführen:https://go.hyper.ai/V42RT
Um die Anwendung und Entwicklung des KI-Protein-Engineerings zu fördern, hat die Forschungsgruppe von Professor Hong Liang von der Shanghai Jiao Tong University eine offene One-Stop-Plattform namens VenusFactory entwickelt, die speziell auf das Protein-Engineering zugeschnitten ist. Forscher können problemlos über 40 hochmoderne Protein-Deep-Learning-Modelle aufrufen, ohne komplexe Codes schreiben zu müssen.
Derzeit wurde auf der offiziellen Website von HyperAI ein Ein-Klick-Bereitstellungstutorial für die „VenusFactory Protein Engineering Design Platform“ veröffentlicht. Klicken Sie auf „Klonen“, um es mit einem Klick zu starten.
Online ausführen:https://go.hyper.ai/TnskV
Community-Artikel
Das Shanghai Artificial Intelligence Laboratory und mehrere Universitäten schlugen vor MaMI-Modell, führte auf innovative Weise einen kontinuierlichen Modalparameteradapter ein, der die Beschränkungen der traditionellen Einzelmodalität durchbricht und es dem einheitlichen Modell ermöglicht, sich in Echtzeit an mehrere Eingabemodalitäten wie Röntgen und CT anzupassen. Bei der Auswertung anhand von 11 öffentlichen medizinischen Bilddatensätzen zeigte MaMI eine hochmoderne Reidentifizierungsleistung und bietet eine starke Unterstützung für die genaue und dynamische Abfrage historischer Bilder in der personalisierten Medizin. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe der Forschungsergebnisse.
Den vollständigen Bericht ansehen:https://go.hyper.ai/e8Eat
Phaseshift Technologies, ein kanadisches Unternehmen für fortschrittliche Materialien, setzt auf den Einsatz von KI-Technologie und Multiskalensimulation zur Entwicklung von Legierungen und Verbundwerkstoffen der nächsten Generation. Mit der Rapid Alloy Design (RAD™)-Plattform können maßgeschneiderte Legierungen für spezielle Anforderungen und Szenarien in verschiedenen Branchen entwickelt werden. Dadurch wird die Geschwindigkeit der Materialentwicklung im Vergleich zu herkömmlichen Methoden auf das Hundertfache erhöht und gleichzeitig die Kosten um 90% gesenkt. Dieser Artikel ist ein ausführlicher Bericht über das Unternehmen.
Den vollständigen Bericht ansehen:https://go.hyper.ai/da4VH
Professor Luo Xiaozhou vom Shenzhen Institute of Advanced Technology der Chinesischen Akademie der Wissenschaften hielt auf dem „Future Has Come“ AI Protein Design Summit der Shanghai Jiao Tong University einen ausführlichen Vortrag zum Thema „Enzym-Engineering auf Basis künstlicher Intelligenz“. Aus mehreren Perspektiven wie dem UniKP-Framework und der ProEnsemble-Maschine werden die innovativen Anwendungen der KI in der Enzymtechnik und ihren Bioherstellungspraktiken erläutert. Dieser Artikel ist eine Abschrift der Ausführungen von Professor Luo Xiaozhou.
Den vollständigen Bericht ansehen:https://go.hyper.ai/de1KW
Teams von Spitzenuniversitäten wie MIT/UC Berkeley/Harvard/Stanford haben gemeinsam den innovativen Algorithmus DRAKES vorgeschlagen. Durch die Einführung eines Rahmens für bestärkendes Lernen realisierten sie erstmals die differenzierbare Belohnungs-Backpropagation der komplett generierten Trajektorie in einem diskreten Diffusionsmodell, wodurch die Leistung nachgelagerter Aufgaben erheblich verbessert wurde, während die Natürlichkeit der Sequenz erhalten blieb. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe des Forschungspapiers.
Den vollständigen Bericht ansehen:https://go.hyper.ai/YyEof
Beliebte Enzyklopädieartikel
1. DALL-E
2. Reziproke Sortierfusion RRF
3. Pareto-Front
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kontrastives Lernen
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:








