Command Palette
Search for a command to run...
Ein Team Des West China Hospital Der Sichuan University Entwickelte Ein Dialog-Framework Mit Mehreren Agenten, Das Die Arztkonsultation Simuliert Und so Bei Der Krankheitsdiagnose hilft.

Die Prävalenz seltener Krankheiten ist gering und entsprechendes Fachwissen rar. Darüber hinaus sind die einzelnen Symptome komplex und unterschiedlich, sodass es häufig zu Fehldiagnosen oder verzögerten Diagnosen kommt. In den letzten Jahren haben große Sprachmodelle (LLMs) wie GPT-4 bei der Beantwortung medizinischer Fragen und der Diagnose häufiger Krankheiten gute Ergebnisse erzielt, stehen jedoch bei komplexen klinischen Aufgaben, beispielsweise bei seltenen Krankheiten, immer noch vor Herausforderungen.Um die praktischen Anwendungsmöglichkeiten von LLMs im medizinischen Bereich zu verbessern, haben einige Forscher begonnen, die Anwendung von Multi-Agenten-Systemen (MAS) zu erforschen.
Ein intelligenter Agent ist ein System, das Eingaben empfangen und bestimmte Operationen ausführen kann, um ein bestimmtes Ziel zu erreichen. Wenn wir beispielsweise mit ChatGPT über unseren Gesundheitszustand kommunizieren, führen wir tatsächlich ein Gespräch mit einem einzelnen Agenten.Im Gegensatz dazu erreicht das Multi-Agenten-System durch den Multi-Agenten-Dialog (MAC) eine dynamischere und interaktivere Diagnose. Dieses Modell simuliert den Diskussionsmechanismus eines multidisziplinären Teams (MDT) in der klinischen Praxis und ermöglicht es mehreren Agenten, denselben Fall zu diskutieren und zu analysieren und die Diagnoseergebnisse auszugeben, nachdem ein Konsens erreicht wurde.
Kürzlich beteiligten sich Teams des West China Hospital der Sichuan University, des West China Biomedical Big Data Center, der Zhejiang University School of Medicine, der Beijing University of Posts and Telecommunications usw. daran.Basierend auf GPT-3.5 bzw. GPT-4 wurde ein Multi-Agent-Dialog-Framework (MAC) entwickelt.Das Framework besteht aus Admin Agent, Supervisor Agent und mehreren Doctor Agents, die gemeinsam an der Analyse des Patientenzustands teilnehmen. Die beste MAC-Konfiguration besteht darin, GPT-4 als Basismodell zu verwenden und aus 4 Doctor Agents und 1 Supervisor Agent zu bestehen.
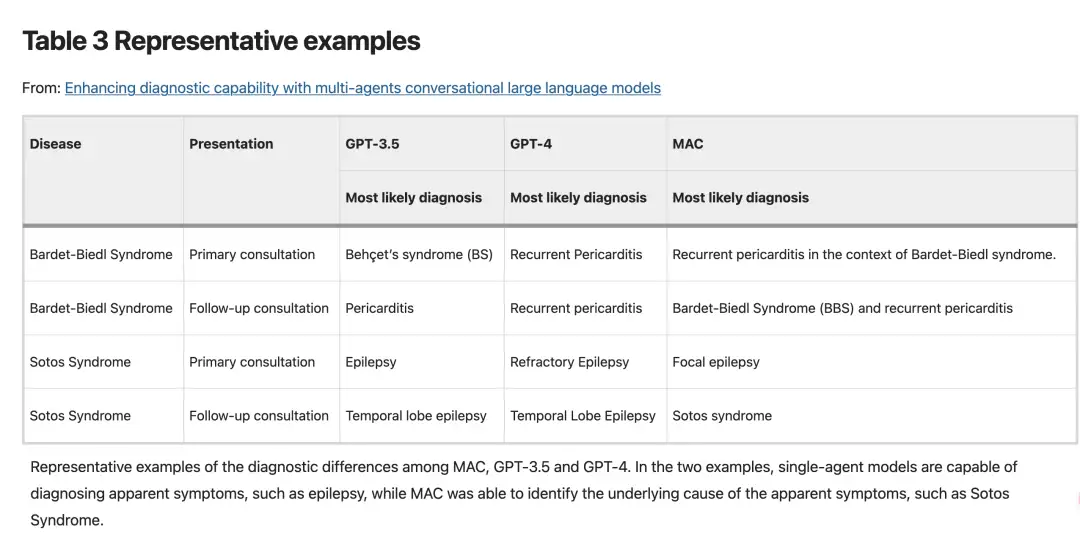
Eine Leistungsbewertung von GPT-3.5, GPT-4 und MAC bei der klinischen Argumentation und der Generierung medizinischen Wissens für 302 seltene Krankheiten liegt vor.MAC übertraf das Einzelagentenmodell sowohl in der Anfangs- als auch in der Folgephase.Darüber hinaus gehen die Diagnosefunktionen von MAC über Methoden wie Chain of Thought (CoT)-Eingabeaufforderungen, Selbstverfeinerung und Selbstkonsistenz hinaus.Kann umfangreichere Diagnoseinhalte ausgeben.Beispielsweise können GPT-3.5 und GPT-4 Perikarditis und Epilepsie anhand des klinischen Erscheinungsbilds identifizieren, MAC kann jedoch durch eine eingehendere Analyse des Gelenkdialogs feststellen, dass die Perikarditis in einem bestimmten Fall durch das Bardet-Biedl-Syndrom verursacht wird.
Zusammenfassend lässt sich sagen, dass MAC die diagnostischen Fähigkeiten von LLMs erheblich verbessert, die Lücke zwischen theoretischem Wissen und klinischer Praxis schließt und voraussichtlich zu einem wichtigen Hilfsmittel für Ärzte werden wird.Die Studie mit dem Titel „Verbesserung der Diagnosefähigkeit mit multiagentenbasierten Konversationsmodellen für große Sprachen“ wurde in npj Digital Medicine, einem Nature-Journal, veröffentlicht.

Papieradresse:
https://www.nature.com/articles/s41746-025-01550-0#Tab6
Das Open-Source-Projekt „awesome-ai4s“ vereint mehr als 200 AI4S-Papierinterpretationen und stellt umfangreiche Datensätze und Tools bereit:
https://github.com/hyperai/awesome-ai4s
Datensatz: Screening von 302 seltenen Krankheiten
In dieser Studie wurden 302 seltene Krankheiten aus der Orphanet-Datenbank als Forschungsobjekte gescreent. Die Orphanet-Datenbank ist eine umfassende, von der Europäischen Kommission kofinanzierte Datenbank für seltene Krankheiten, die mehr als 7.000 Krankheiten 33 Typen umfasst.
Laden Sie den Datensatz mit 302 Fällen seltener Krankheiten herunter:
https://go.hyper.ai/EETet
Nachdem das Forschungsteam die Zielkrankheit identifiziert hatte, durchsuchte es die Medline-Datenbank nach klinischen Fallberichten, die nach Januar 2022 veröffentlicht wurden. Durch die Extraktion strukturierter Daten aus diesen Fallberichten sammelten wir detaillierte Informationen zu Patientendemografie, klinischen Manifestationen, Anamnese, Ergebnissen körperlicher Untersuchungen und verschiedenen Ergebnissen zusätzlicher Untersuchungen (einschließlich genetischer Tests, pathologischer Biopsien und radiologischer Untersuchungen) und zeichneten die endgültigen Diagnoseinformationen auf.
Um den Anwendungswert großer Sprachmodelle (LLM) in klinischen Umgebungen umfassend zu bewerten, entwickelte das Forschungsteam ein zweistufiges Simulationsexperiment für klinische Konsultationen, bei dem jeder Fall in den Einstellungen der Erstkonsultation und der Folgekonsultation getestet wurde:
* Die erste Phase simuliert das Szenario der Erstkonsultation (Erstdiagnose),Der Hauptzweck besteht darin, die Leistung von LLM bei Patienten zu untersuchen, die sich zum ersten Mal vorstellen und über begrenzte klinische Informationen verfügen. Die Aufgabe von LLMs besteht darin, eine wahrscheinlichste Diagnose, mehrere mögliche Diagnosen und weitere Diagnosen zu ermitteln.
* Die zweite Stufe simuliert das Szenario einer Folgekonsultation (erneute Untersuchung).Um die diagnostische Fähigkeit von LLM nach Erhalt vollständiger Patienteninformationen (einschließlich verschiedener Untersuchungsergebnisse) zu bewerten. Die Aufgabe von LLMs besteht darin, eine wahrscheinlichste Diagnose und mehrere mögliche Diagnosen zu ermitteln.
Dieses stufenweise Studiendesign kann nicht nur die anfängliche Urteilsfähigkeit von LLM unter Bedingungen unvollständiger Informationen testen, sondern auch seine medizinische Argumentation und endgültige diagnostische Genauigkeit nach vollständiger Beherrschung der klinischen Daten systematisch bewerten und so das praktische Anwendungspotenzial von LLM in der klinischen Entscheidungsunterstützung umfassend widerspiegeln.

Das MAC-Framework basierend auf GPT-4 und mit 4 Doctor Agents schnitt am besten ab
Mithilfe der von Autogen bereitgestellten Struktur entwickelte das Forschungsteam zwei Multi-Agent Conversation Frameworks (MAC) auf Basis von GPT-3.5-Turbo und GPT-4, um Arztkonsultationen zu simulieren. Wie in der Abbildung unten gezeigt,Der Admin-Agent stellt Patienteninformationen bereit, der Supervisor-Agent initiiert und überwacht das gemeinsame Gespräch und die drei Doctor-Agents besprechen gemeinsam den Zustand des Patienten.Der Dialog wird fortgesetzt, bis die Agenten einen Konsens erzielen oder die voreingestellte maximale Anzahl von Dialogrunden (in dieser Studie auf 13 Runden festgelegt) erreicht ist und das endgültige Diagnoseergebnis ausgegeben wird.
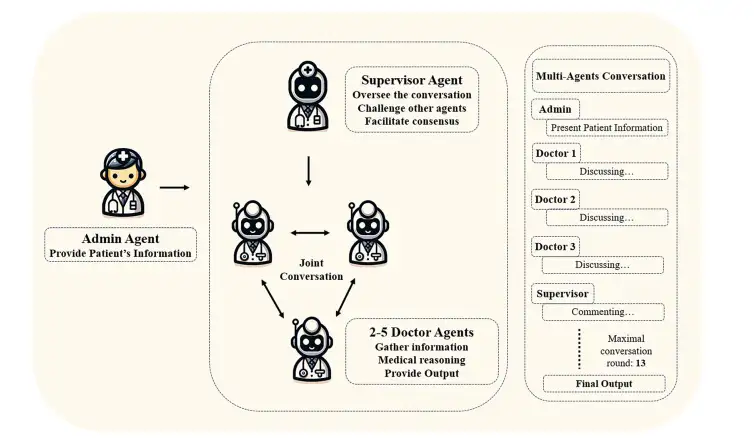
Supervisor Agent übernimmt die Rolle der Qualitätskontrolle und Prozessoptimierung.Zu seinen Aufgaben gehören: (1) die Überwachung und Bewertung der Empfehlungen und Entscheidungen der Arztvertreter; (2) Überprüfung der Diagnosepläne und der vorgeschlagenen Untersuchungsgegenstände, um wichtige Punkte zu ermitteln, die möglicherweise übersehen wurden; (3) Koordinierung der Diskussionen zwischen den Arztvertretern, um die Verbesserung der Diagnosepläne zu fördern; (4) Förderung der Konsensfindung der behandelnden Ärzte hinsichtlich der endgültigen Diagnose und des Untersuchungsplans; und (5) den Dialogprozess zeitnah zu beenden, nachdem ein Konsens erreicht wurde.
Zu den Aufgaben der Arztvertreter gehören:(1) Bereitstellung diagnostischer Begründungen und klinischer Beratung auf der Grundlage ärztlicher Fachkenntnisse; (2) die Meinungen anderer Akteure systematisch zu bewerten und zu kommentieren und wissenschaftlich fundierte und nachvollziehbare Argumente und Beweise vorzubringen; (3) Integrieren und optimieren Sie das Feedback anderer Agenten, um die Diagnoseergebnisse kontinuierlich zu verbessern.
Anhand echter klinischer Fallberichte aus der Medline-Datenbank bewerteten die Forscher das Wissen und die diagnostischen Möglichkeiten von GPT-3.5, GPT-4 und MAC für 302 seltene Krankheiten. Darüber hinaus wird der Einfluss verschiedener Einstellungen auf die MAC-Leistung untersucht.
Beispielsweise verglich das Forschungsteam die Leistungsunterschiede, wenn das MAC-Framework GPT-4 und GPT-3.5 als Basismodell verwendete.Die Ergebnisse zeigen, dass MAC mit GPT-3.5 oder GPT-4 als Basismodell eine deutlich bessere Leistung erbringt als die jeweiligen unabhängigen Versionen. Mit anderen Worten: Die diagnostische Fähigkeit von MAC ist im Vergleich zum Einzelagentenmodell erheblich verbessert.Darüber hinaus zeigt sich, dass GPT-4 bei Verwendung als Basismodell für MAC GPT-3.5 übertrifft, was bedeutet, dass ein leistungsfähigeres Basismodell zu einer besseren Gesamtleistung führen kann.
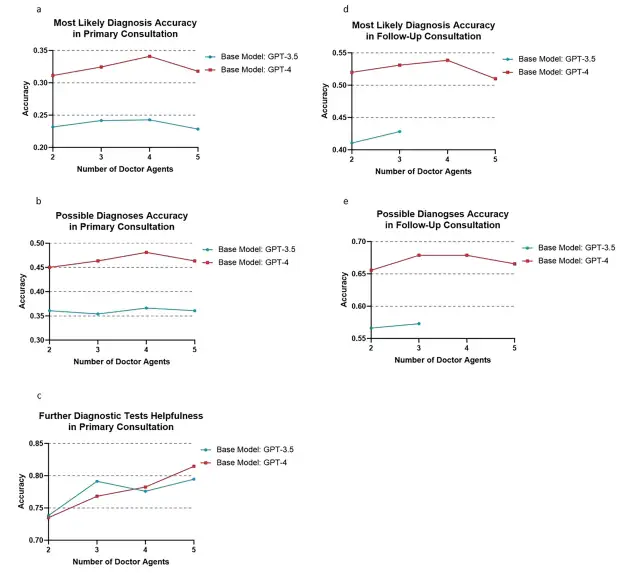
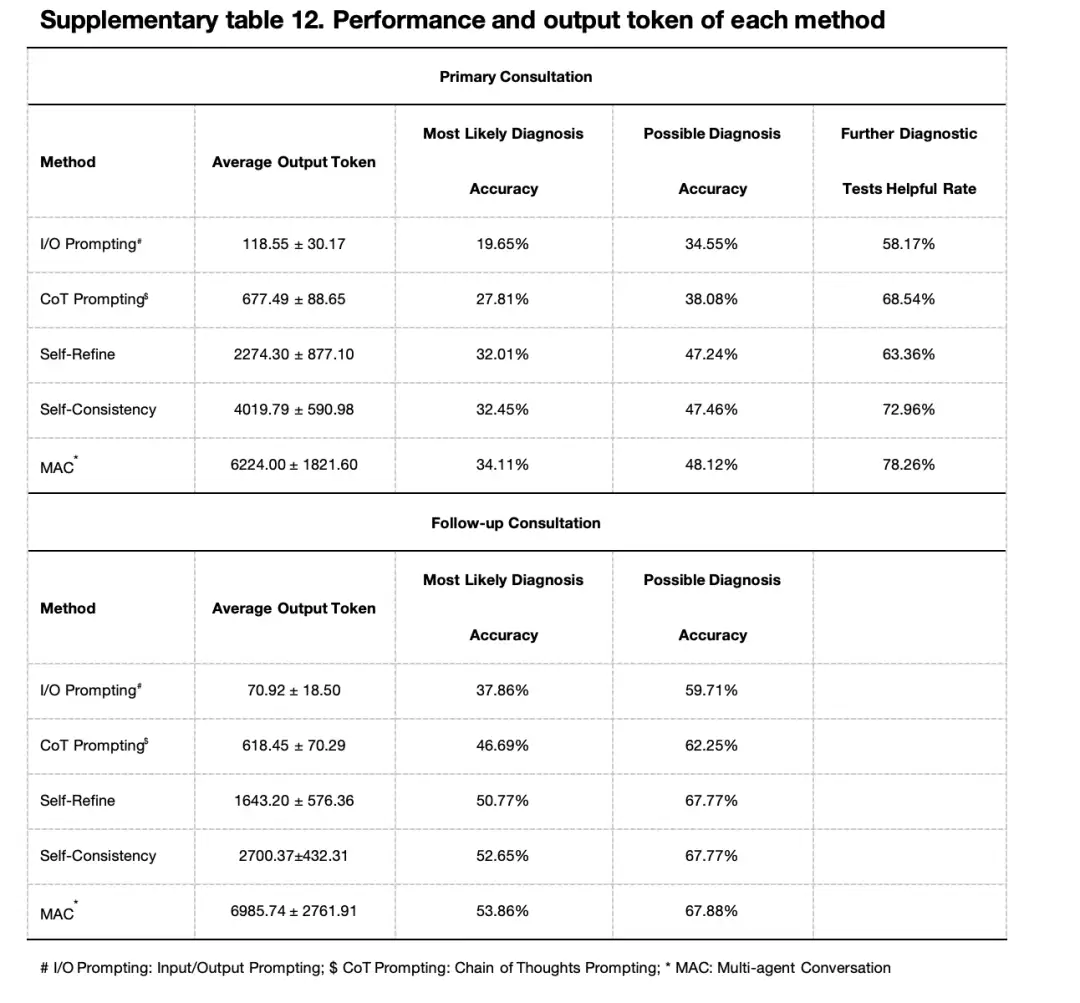
Auch,Die Forscher untersuchten auch die Auswirkungen der Anzahl der Arztagenten auf die Leistung des Multiagenten-Frameworks.Die experimentellen Ergebnisse auf Grundlage des GPT-4-Modells zeigten, dass die wahrscheinlichste diagnostische Genauigkeit bei 4 Wirkstoffen einen Spitzenwert von 34,111 TP3T erreichte, während sie bei 5 Wirkstoffen leicht auf 31,791 TP3T sank. Ein ähnliches Muster wurde bei der Genauigkeit der möglichen Diagnose beobachtet, wobei die Genauigkeit der Agenten 2, 3, 4 und 5 51,99%, 53,31%, 53,86% bzw. 50,99% betrug. Auch im Experiment auf Basis des GPT-3.5-Modells zeigten die vier Doctor Agents die beste Performance. Insgesamt unterscheidet sich die Leistung von 3 Agenten jedoch nicht wesentlich von der von 4 Agenten.
Darüber hinaus wurde in einem simulierten Erstkonsultationsszenario mit vier ArztagentenDas auf GPT-4 basierende MAC-Framework erzielte bei vielen Schlüsselindikatoren eine bessere Leistung: Die Genauigkeit der wahrscheinlichsten Diagnose erreichte 34,11% (GPT-3.5 ist 24,28%), die Genauigkeit der möglichen Diagnose erreichte 48,12% (GPT-3.5 ist 36,64%) und die Nützlichkeit weiterer Diagnosetests erreichte 78,26% (GPT-3.5 ist 77,37%). Auch hinsichtlich der diagnostischen Leistung bei Folgekonsultationen schnitt das GPT-4-basierte MAC-Framework mit der Teilnahme von 4 Arztagenten am besten ab.
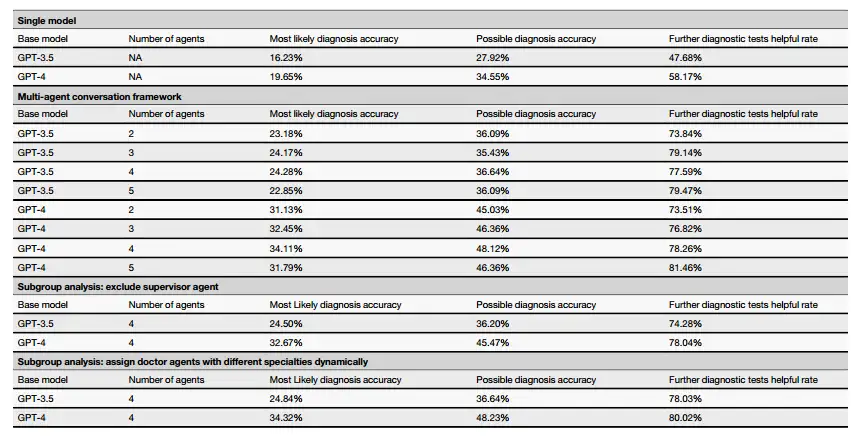
Die Forscher bewerteten auch die möglichen Auswirkungen der Entfernung des Supervisor Agent auf die Gesamtleistung des MAC. Die Ergebnisse zeigen, dass, wenn der Supervisor-Agent entfernt wird, im Szenario der Erstberatung, das mit 4 Arzt-Agenten simuliert wurde,Die Daten des auf GPT-4 basierenden MAC-Frameworks hinsichtlich der wahrscheinlichsten diagnostischen Genauigkeit, der möglichen diagnostischen Genauigkeit und der Nützlichkeit weiterer diagnostischer Tests lagen bei 32,67%, 45,47% bzw. 78,04% und sind damit alle niedriger als im nicht entfernten Zustand.Im Szenario der Folgekonsultation wies das MAC-Framework mit entferntem Supervisor-Agent eine geringere wahrscheinliche und mögliche Diagnosegenauigkeit auf als wenn es nicht entfernt worden wäre.Dies zeigt, dass Supervisor Agent die Effektivität des Frameworks verbessert.
Experimentelle Schlussfolgerung: MAC kann die Grundursache der Krankheit direkt identifizieren und verfügt über stärkere diagnostische Fähigkeiten
Das Forschungsteam bewertete die Leistung der GPT-3.5-, GPT-4- und MAC-Frameworks bei der Generierung von Wissen über seltene Krankheiten, einschließlich Krankheitsdefinition, Epidemiologie, klinische Merkmale, Ätiologie, Diagnosemethoden, Differentialdiagnose, pränatale Diagnose, genetische Beratung, Behandlungsmanagement und Prognose. Die Ergebnisse zeigen, dass diese Modelle in allen Bewertungsdimensionen gut abschneiden und für jeden Indikator Werte von über 4 Punkten erreichen, wie in der folgenden Abbildung dargestellt. Auch,Sie zeigten ein hohes Maß an inhaltlicher Genauigkeit (unangemessener/falscher Inhalt), Informationsvollständigkeit (Auslassungen), Sicherheit (Wahrscheinlichkeit und Ausmaß eines möglichen Schadens) und Objektivität (Voreingenommenheit).
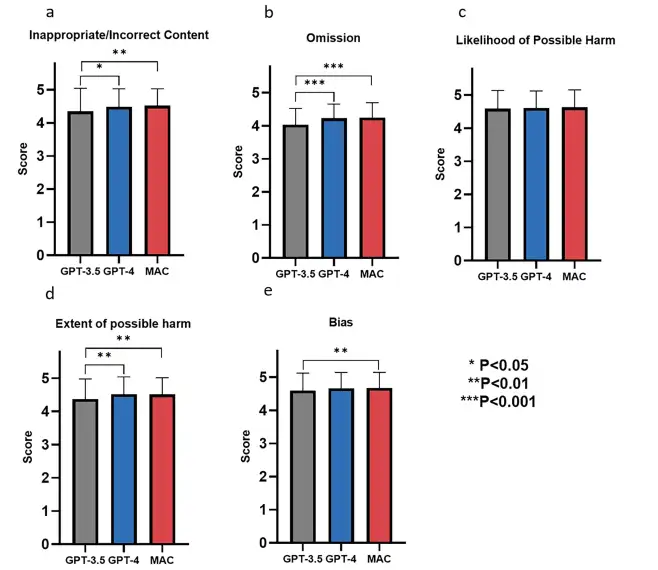
Bei der Diagnose spezifischer Krankheitsfälle, wie in der Abbildung unten dargestellt, stellten die Forscher fest, dass GPT-3.5 und GPT-4 zwar in der Lage waren, Krankheiten auf der Grundlage offensichtlicher Symptome zu diagnostizieren, wie etwa die Identifizierung von Perikarditis und Epilepsie anhand klinischer Manifestationen, jedoch nicht ausreichten, um die Grundursachen der Krankheit zu erforschen.Im Gegensatz dazu ermöglicht das MAC-Framework durch einen gemeinsamen Dialog eine tiefergehende Analyse, die feststellen kann, ob die Perikarditis im Einzelfall durch das Bardet-Biedl-Syndrom verursacht wird.
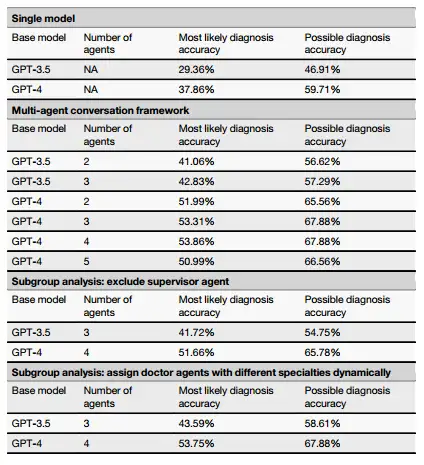
Die Forscher verglichen MAC mit Input/Output-(I/O)-Hinweisen, Gedankenketten-Hinweisen (CoTs), Selbstoptimierung und Selbstkonsistenzmethoden. Wie in der Abbildung unten gezeigt,Sowohl bei der Erst- als auch bei der Folgeuntersuchung schnitt MAC hinsichtlich der wahrscheinlichsten Diagnose, der möglichen Diagnose und der Wirksamkeit weiterer Diagnosetests am besten ab.
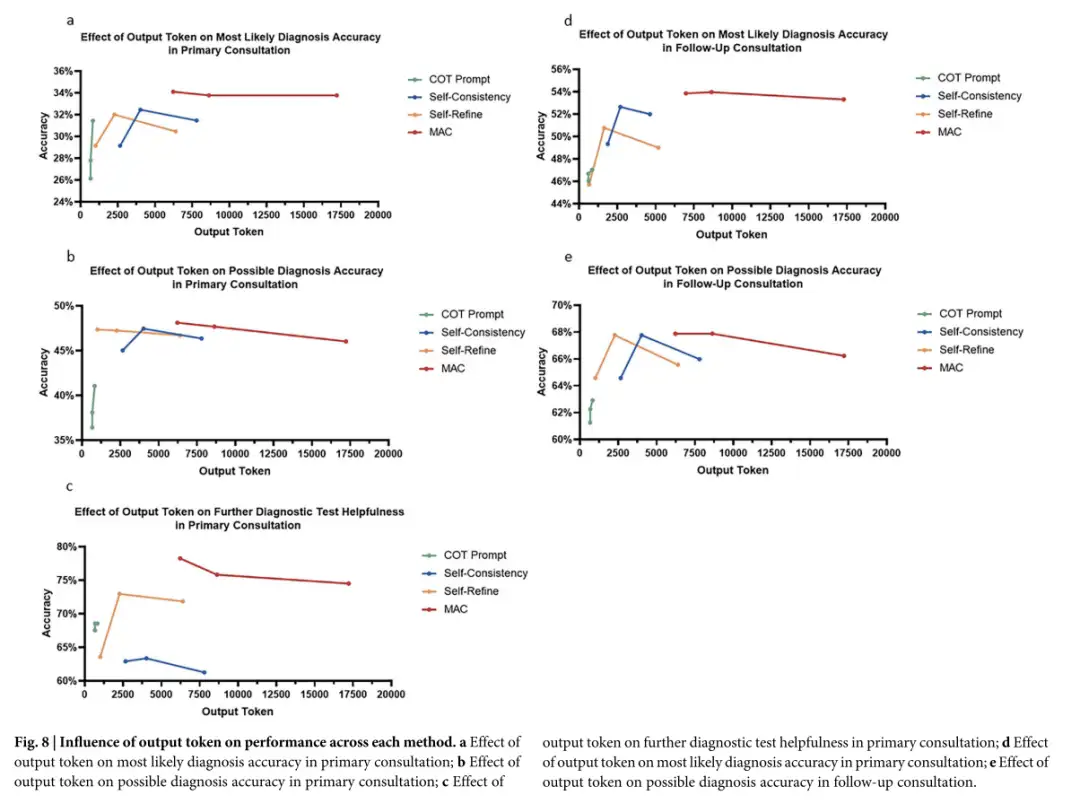
Darüber hinaus gibt MAC mehr Token aus. Die gesteigerte Leistung hilft nicht nur dabei, andere Denkansätze zu erkunden, sondern ermöglicht auch die Reflexion und Korrektur früherer Ergebnisse, wodurch die Analysetiefe erhöht und die Fähigkeit zur Identifizierung der Grundursachen vernachlässigter Krankheiten verbessert werden kann. Allerdings zeigt die Forschung auch, dassObwohl die MAC-Leistung durch eine Erhöhung der Anzahl von LLM-Aufrufen und die damit verbundene Generierung von mehr Token verbessert werden kann, ist das Ausmaß dieser Verbesserung durch die Art der Aufgabe und die verwendete Verfeinerungsmethode begrenzt.
Zusammenfassend lässt sich sagen, dass im Rahmen dieser Studie erfolgreich ein Multi-Agent-Dialograhmen (MAC) für die Krankheitsdiagnose entwickelt wurde, der wertvolle Diagnosevorschläge liefern und in verschiedenen Phasen der klinischen Konsultation weitere Diagnosen empfehlen kann und auf alle Arten seltener Krankheiten anwendbar ist. Darüber hinaus im Vergleich zu bestehenden Methoden wie Chain of Thought (CoT), Selbstoptimierung und Selbstkonsistenz,MAC verfügt nicht nur über eine höhere Diagnosegenauigkeit, sondern generiert auch umfangreichere und umfassendere Diagnoseinhalte.Dieses Framework verbessert die klinischen Diagnosefunktionen großer Sprachmodelle erheblich.
Multi-Agenten-Systeme haben großes Anwendungspotenzial im medizinischen Bereich
In den letzten Jahren haben Multi-Agenten-Systeme im Bereich der medizinischen Entscheidungsfindung und Diagnose vielversprechende Fortschritte gezeigt. Es sind mehrere wichtige Frameworks entstanden, die unterschiedliche Strategien zur Nutzung großer Sprachmodelle zur Durchführung klinischer Aufgaben übernommen haben. Beispielsweise hat die Shanghai Jiao Tong University MedAgents vorgeschlagen, ein multidisziplinäres Kooperationsframework für den medizinischen Bereich. Dieses Framework ermöglicht LLM-basierten Agenten, mehrere Runden gemeinsamer Diskussionen in einer Rollenspielumgebung durchzuführen, wodurch die Leistung von LLM bei der Beantwortung medizinischer Fragen ohne Stichproben erheblich verbessert wird. Die Forschungsergebnisse wurden auf arXiv unter dem Titel „MedAgents: Large Language Models as Collaborators for Zero-shot Medical Reasoning“ veröffentlicht.
Papieradresse:
https://arxiv.org/abs/2311.10537
Anders als MedAgents und andere Plattformen, die sich auf medizinische Fragen und Antworten konzentrieren,Das MAC-Framework konzentriert sich auf Diagnoseaufgaben und fordert mehrere Agenten auf, im selben klinischen Kontext zu analysieren, interaktiv zu diskutieren und offene Diagnosevorschläge zu unterbreiten.In Bezug auf das Architekturdesign des intelligenten Agenten enthält MAC mehrere Doctor Agents und einen Supervisor Agent, während andere Frameworks andere Einstellungen übernehmen, z. B. das Erstellen separater Agents für Fragen und Antworten. Die Rahmenwerke unterscheiden sich auch in der Art und Weise, wie sie einen Konsens erreichen. Beispielsweise verfeinern MedAgents ihre Antworten kontinuierlich durch iterative Überarbeitungen, bis alle Experten zu einem Konsens gelangen, während MAC vom Supervisor Agent bestimmt wird, wenn die Doctor Agents einen ausreichenden Konsens erreicht haben.
Obwohl diese Multiagentensysteme hinsichtlich Konfiguration und Zielsetzung ihre eigenen Merkmale aufweisen, verfügen sie über ein großes Anwendungspotenzial im medizinischen Bereich. Um ihre tatsächliche Rolle im klinischen Umfeld vollständig zu erforschen und zu optimieren, bedarf es auch in Zukunft weiterer Forschung.
Das Forschungsteam des oben erwähnten Multi-Agenten-Dialograhmens konzentriert sich auf die Erforschung modernster Technologien an der Schnittstelle zwischen generativer künstlicher Intelligenz und klinischer Medizin.Es verfügt über umfangreiche klinische Datenressourcen und modernste Computerhardware und seine Forschungsergebnisse wurden in hochrangigen internationalen Fachzeitschriften veröffentlicht.
Das Team hat sich der praktischen Anwendung künstlicher Intelligenztechnologie verschrieben und möchte das Modell und Ökosystem der klinischen medizinischen Diagnose und Behandlung grundlegend verändern. Wir laden akademische Einrichtungen und Unternehmen herzlich zur Projektzusammenarbeit ein. Wir freuen uns über die Bewerbung herausragender Doktoranden, die sich für dieses Gebiet interessieren. Gleichzeitig suchen wir engagierte wissenschaftliche Mitarbeiter zur Verstärkung unseres Teams. Interessierte Parteien können sich an [email protected] wenden.








