Command Palette
Search for a command to run...
Online-Tutorial | Hier Kommt Der CSM, Geh Aus Dem Weg! Lebendigere Sprachwiedergabe, Keine Verzögerte, Langweilige Und Mechanische Sprache Mehr

Beim Chatten mit dem KI-Sprachassistenten habe ich immer das Gefühl, dass etwas komisch ist. Sie beantworteten Fragen problemlos, aber es fehlte ihnen ein wenig an „Menschlichkeit“. Der Tonfall ist dumpf, die Pausen sind abrupt und gelegentlich friert die Stimme an unerklärlichen Stellen ein. Dieses unmenschliche und unmenschliche Gefühl ist eigentlich der „Uncanny Valley-Effekt“ am Werk. Wenn die KI-Stimme der menschlichen Stimme sehr ähnlich, aber nicht vollkommen konsistent ist, fühlen sich die Benutzer unwohl.
Unter den vielen Sprachmodellen ist vor Kurzem das vom Sesame-Team eingeführte Sprachgenerierungsmodell CSM (Conversational Speech Model) hervorgestochen.Das Modell verwendet die Llama-Backbone-Architektur und einen leichten Audiodecoder, kombiniert mit einem End-to-End-Transformer-Framework, um RVQ-Audiocodes basierend auf Text- und Audioeingaben zu generieren und dann flüssige, natürliche und emotionale Sprache auszugeben.Erstellen Sie einen Sprachassistenten, der die emotionalen Bedürfnisse der Benutzer erfüllen kann.
Im Vergleich zu herkömmlichen KI-Modellen zur Sprachgenerierung leistet CSM viel mehr als nur die Generierung von Audio:
*Stärkeres emotionales Verständnis:Kann den Kontext gründlich analysieren und Ton und Intonation flexibel anpassen.
*Natürlicherer Gesprächsrhythmus:Optimieren Sie Details wie Pausen, Betonungen, Unterbrechungen usw., um Gespräche flüssiger zu gestalten.
*Fast verzögerungsfreies Erlebnis:Durch die effiziente Inferenzarchitektur kommt die Sprachgenerierung der Echtzeit näher und verbessert die Interaktionseffizienz.
Das Tutorial „CSM Conversational Speech Generation Model Demo“ ist jetzt auf der offiziellen HyperAI-Website verfügbar. Kommen Sie und sehen Sie es sich an!
Adresse des Tutorials:
Demolauf
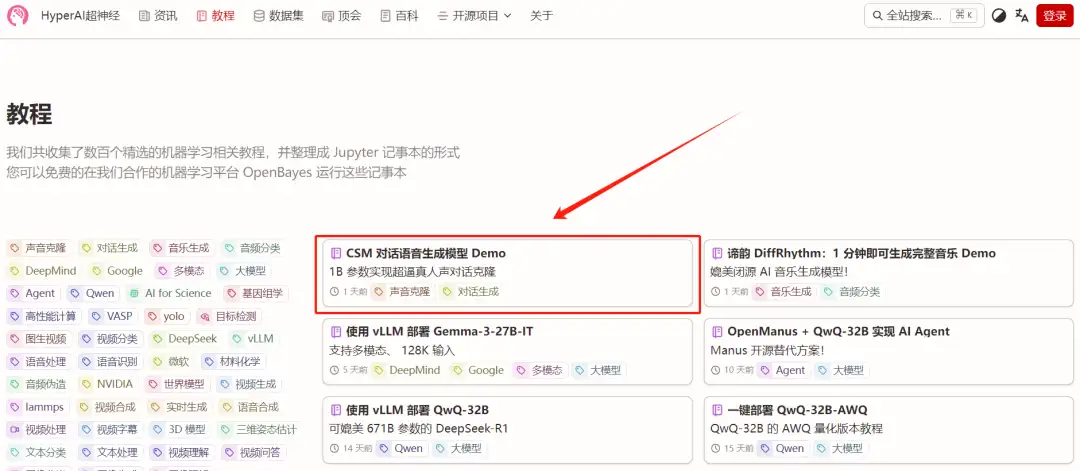
1. Melden Sie sich bei hyper.ai an, gehen Sie zur Seite „Tutorials“, wählen Sie „CSM Conversational Speech Generation Model Demo“ und klicken Sie auf „Dieses Tutorial online ausführen“.
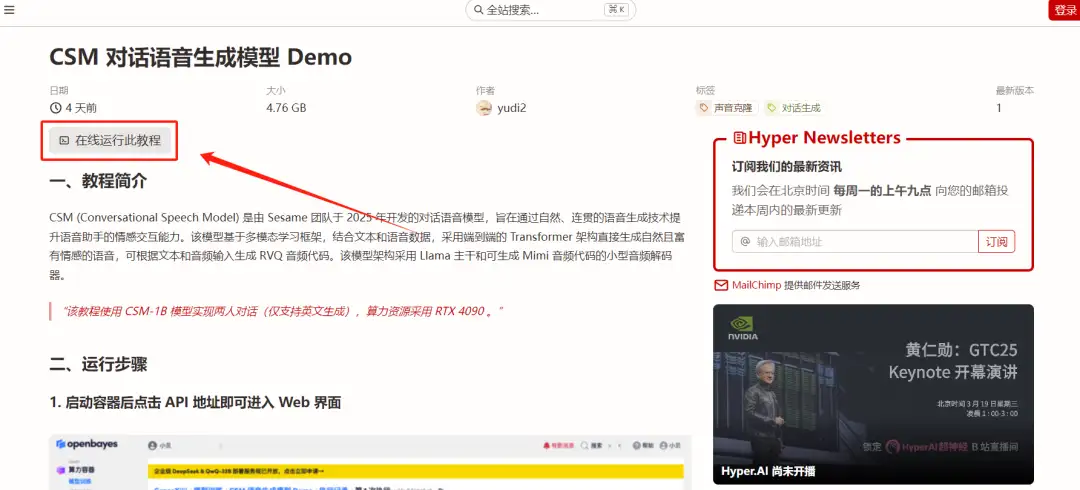
2. Klicken Sie nach dem Seitensprung oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
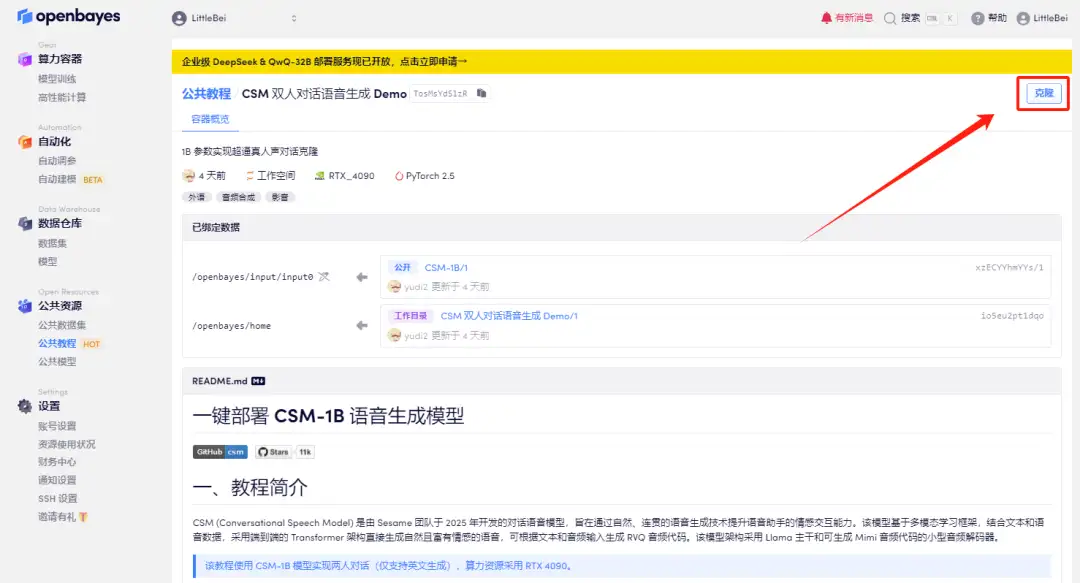
3. Wählen Sie die Bilder „NVIDIA RTX 4090“ und „PyTorch“ aus. Die OpenBayes-Plattform hat eine neue Abrechnungsmethode eingeführt. Sie können je nach Bedarf zwischen „Pay as you go“ oder „Tages-/Wochen-/Monatspaket“ wählen. Klicken Sie auf „Weiter“. Neue Benutzer können sich über den unten stehenden Einladungslink registrieren, um 4 Stunden RTX 4090 + 5 Stunden CPU-freie Zeit zu erhalten!
Exklusiver Einladungslink von HyperAI (kopieren und im Browser öffnen):
https://go.openbayes.com/9S6Dr
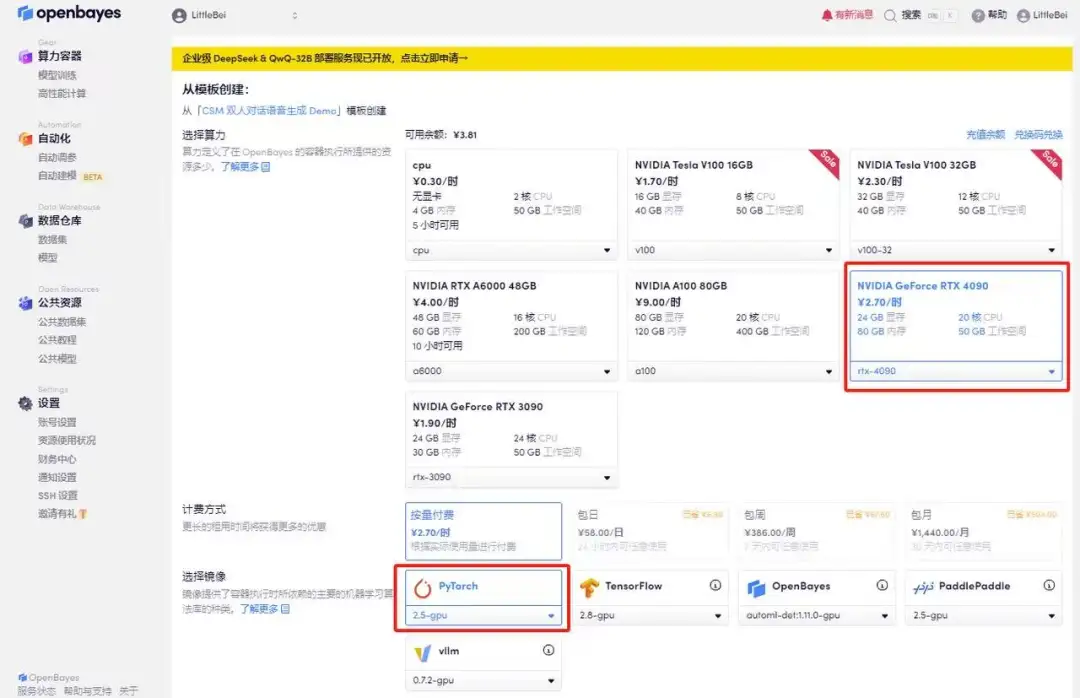
4. Warten Sie, bis die Ressourcen zugewiesen wurden. Der erste Klonvorgang dauert etwa 2 Minuten. Wenn sich der Status in „Läuft“ ändert, klicken Sie auf den Sprungpfeil neben „API-Adresse“, um zur Demoseite zu springen. Da das Modell groß ist, dauert es etwa 3 Minuten, bis die WebUI-Schnittstelle angezeigt wird, andernfalls wird „Bad Gateway“ angezeigt. Bitte beachten Sie, dass Benutzer vor der Verwendung der API-Adresszugriffsfunktion eine Echtnamenauthentifizierung durchführen müssen.
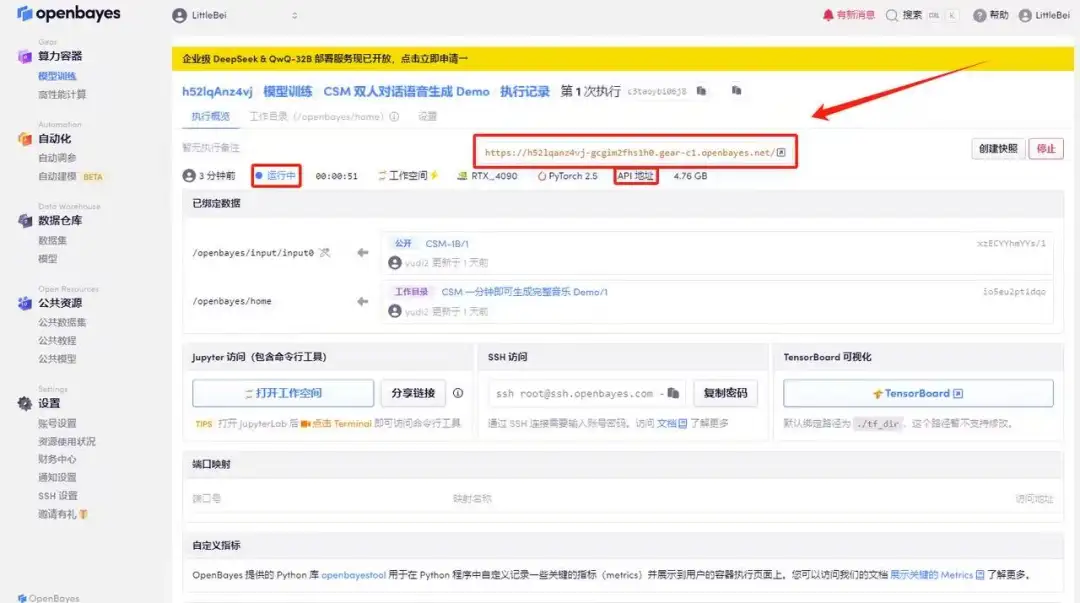
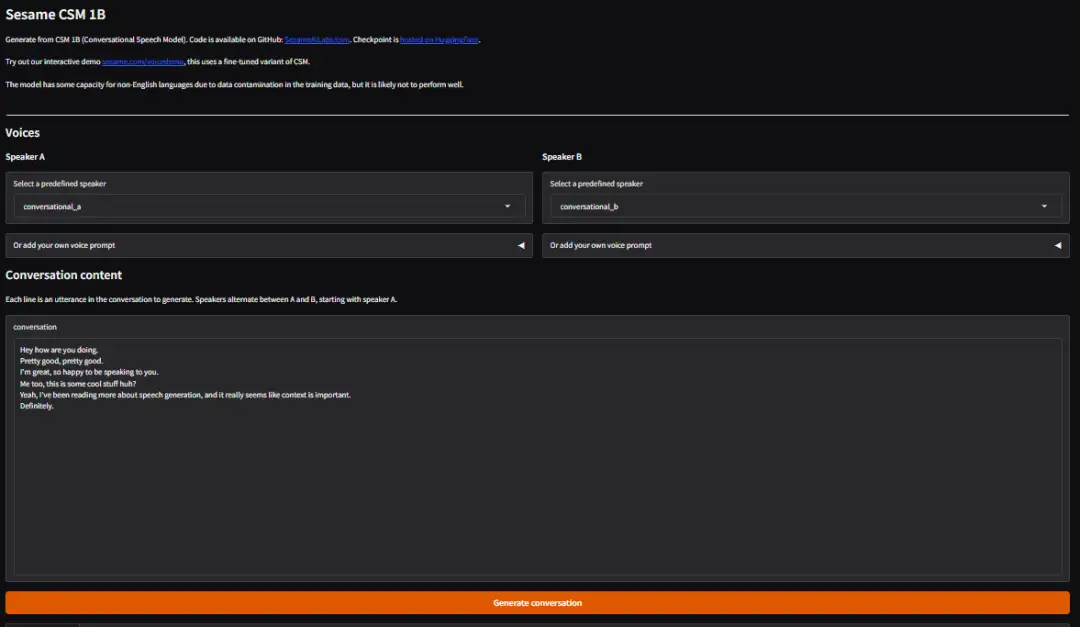
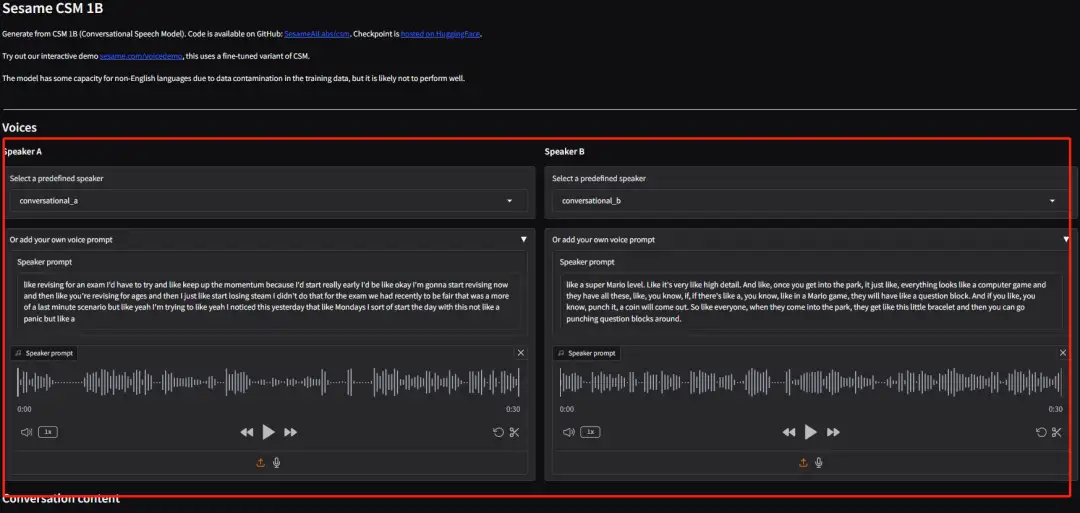
Effektanzeige
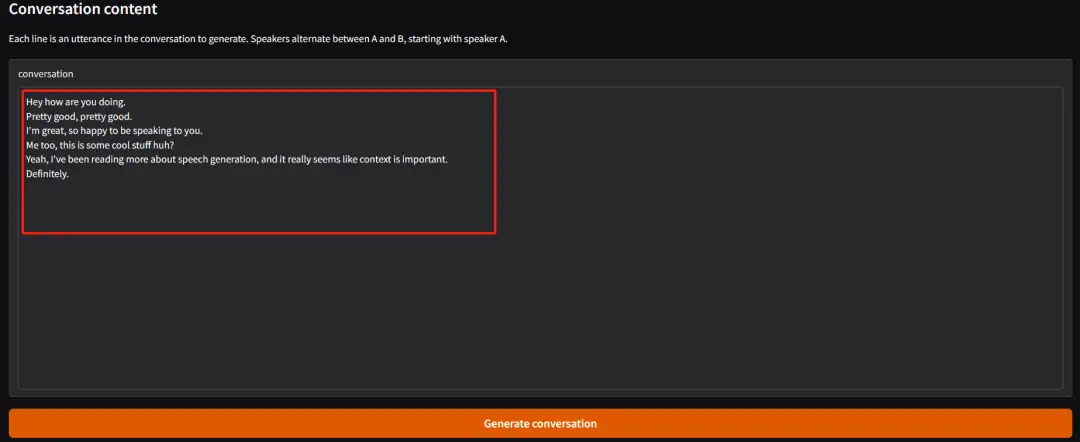
Wählen oder laden Sie persönliches Audio hoch, geben Sie den Konversationsinhalt ein und klicken Sie auf „Konversation generieren“, um die Konversation zu generieren.
*Standardmäßig beginnt Sprecher A die erste Rederunde, danach kommunizieren Sprecher A und Sprecher B abwechselnd (derzeit wird nur die Generierung englischer Inhalte unterstützt).