Command Palette
Search for a command to run...
Die Top-Open-Source-Player Kommen Zusammen! QwQ-32B Schaltet Mehrere Spielmodi Frei, OpenManus Erstellt Kostengünstige KI-Agenten! vLLM v1 Ermöglicht Effizientes Modellschlussfolgern

Inmitten der Welle kontinuierlicher Durchbrüche auf dem Gebiet der künstlichen Intelligenz hat das neueste Modell des Qwen-Teams, QwQ-32B, mit seinen 32 Milliarden Parametern das Verständnis der Branche für große Open-Source-Modelle erneut aufgefrischt. Das Modell hat bei Aufgaben wie Codegenerierung und mehrstufigen Dialogen eine hervorragende Leistung gezeigt und seine Denkfähigkeit ist mit der Vollversion von DeepSeek-R1 vergleichbar.
Vor nicht allzu langer Zeit,Die vLLM-Kernarchitektur, die speziell für die Beschleunigung des Denkens bei großen Modellen entwickelt wurde, wurde umfassend aktualisiert.Durch die Optimierung von Ausführungsschleifen, einheitlichen Schedulern und Präfix-Caches ohne Overhead wird eine bis zu 1,7-fache Leistungssteigerung bei Durchsatz und Latenz erreicht, sodass QwQ-32B effizient auf A6000-Grafikkarten mit zwei Karten eingesetzt werden kann.
Im Bereich der KI-Agenten hat OpenManus seit seiner Einführung an Dynamik gewonnen. Dieses Open-Source-Projekt, bekannt als „Manus-Alternative“,Es begegnet nicht nur externen Zweifeln am geschlossenen Ökosystem durch Technologiereproduktion, sondern bietet Entwicklern auch einen „Generalschlüssel“, um durch modulares Design und Toolchain-Integration kostengünstig intelligente Einheiten zu erstellen.
Derzeit hat HyperAI zwei Tutorials veröffentlicht: „Verwenden von vLLM zum Bereitstellen von QwQ-32B“ und „OpenManus + QwQ-32B zum Implementieren von AI Agent“. Kommen Sie und probieren Sie es aus~
Stellen Sie QwQ-32B mit vLLM bereit
Online-Nutzung:https://go.hyper.ai/8nPfC
OpenManus + QwQ-32B implementiert AI Agent
Online-Nutzung:https://go.hyper.ai/GIX1H
Vom 10. bis 15. März wurde die offizielle Website von hyper.ai schnell aktualisiert:
* Hochwertige öffentliche Datensätze: 10
* Hochwertige Tutorial-Auswahl: 4
* Community-Artikelauswahl: 6 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im März: 4
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Big-Math Reinforcement Learning Mathematik-Datensatz
Big-Math ist ein umfangreicher, hochwertiger Mathematik-Datensatz, der für die Anwendung von Reinforcement Learning (RL) in Sprachmodellen entwickelt wurde. Der Datensatz enthält mehr als 250.000 hochwertige Mathematikaufgaben, jede mit einer überprüfbaren Antwort.
Direkte Verwendung:https://go.hyper.ai/qtlbQ
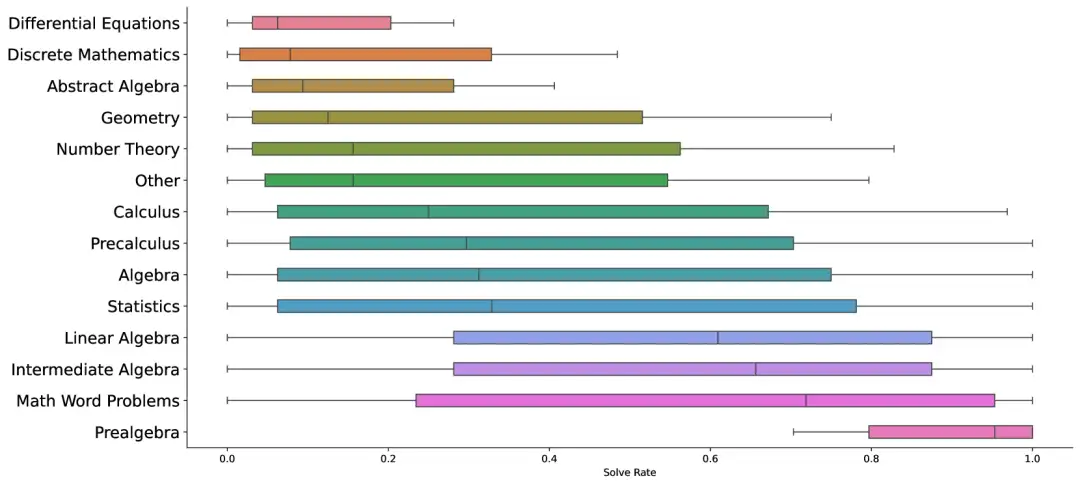
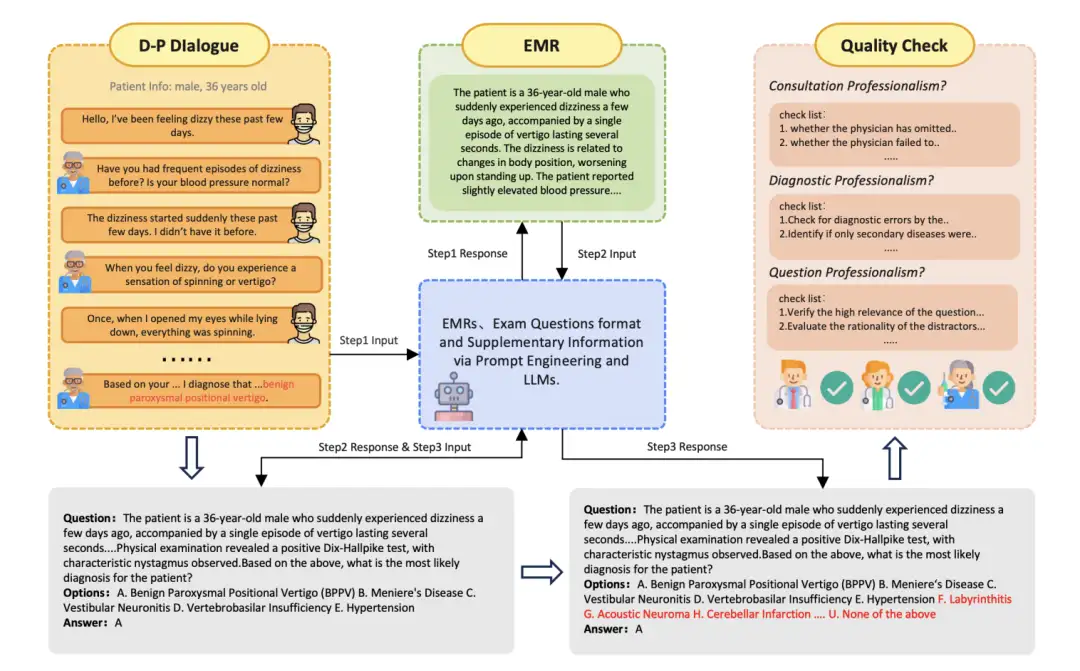
2. JMED Chinesischer echter medizinischer Datendatensatz
Der JMED-Datensatz ist ein neuer Datensatz, der auf der Verteilung realer medizinischer Daten basiert. Der Datensatz stammt aus anonymen Arzt-Patienten-Gesprächen im JD Health Internet Hospital und wird gefiltert, um Konsultationen beizubehalten, die einem standardisierten Diagnoseablauf folgen.
Direkte Verwendung:https://go.hyper.ai/FjZsa
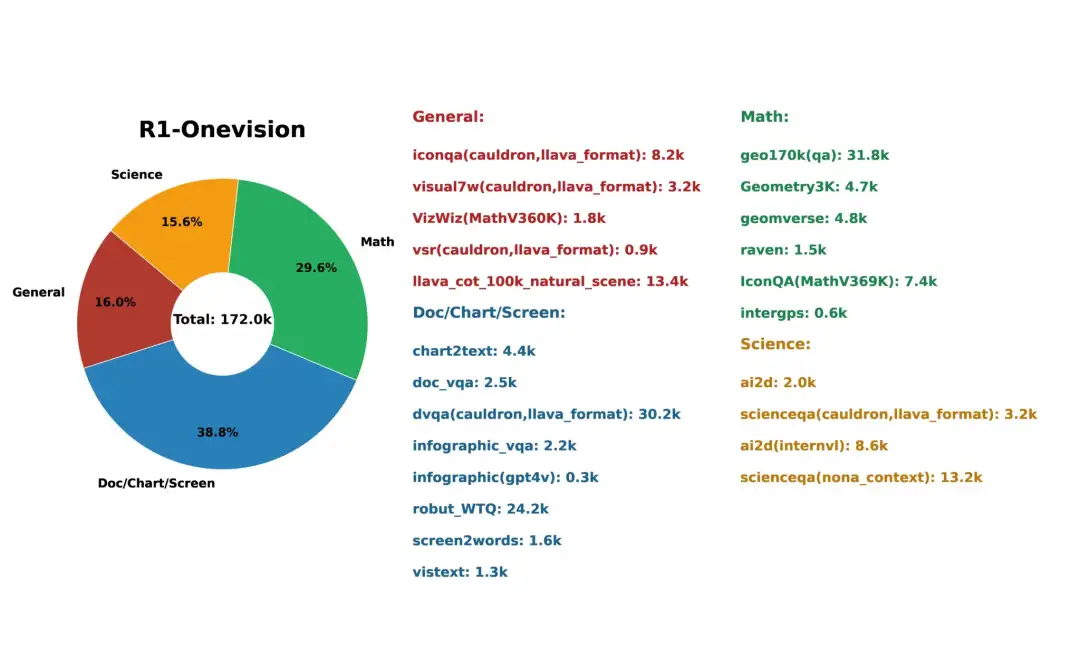
3. R1-Onevision Multimodal Reasoning-Datensatz
Der R1-Onevision-Datensatz wurde entwickelt, um Modelle mit erweiterten multimodalen Argumentationsfähigkeiten auszustatten. Es schließt die Lücke zwischen visuellem und textuellem Verständnis durch umfangreiche, kontextbezogene Denkaufgaben in mehreren Bereichen wie Naturszenen, Wissenschaft, mathematischen Problemen, OCR-basierten Inhalten und komplexen Diagrammen.
Direkte Verwendung:https://go.hyper.ai/jLbSI
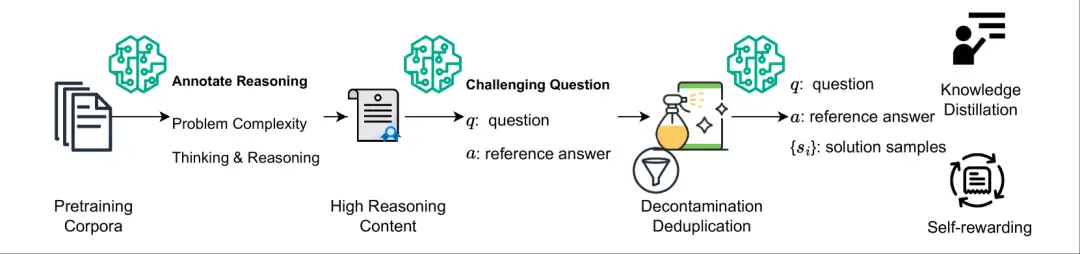
4. NaturalReasoning Natural Reasoning-Datensatz
Der NaturalReasoning-Datensatz ist ein umfangreicher, hochwertiger Datensatz zum folgerichtigen Denken, der 2,8 Millionen anspruchsvolle Fragen aus verschiedenen Bereichen enthält, beispielsweise aus den MINT-Fächern (z. B. Physik, Informatik), Wirtschaftswissenschaften, Sozialwissenschaften usw. Der Datensatz zielt darauf ab, vielfältige und anspruchsvolle Fragen zum folgerichtigen Denken und die dazugehörigen Referenzantworten zu generieren, indem vorab trainierte Korpora und große Sprachmodelle (LLMs) genutzt werden, ohne dass zusätzliche menschliche Anmerkungen erforderlich sind.
Direkte Verwendung:https://go.hyper.ai/Mb6Cd
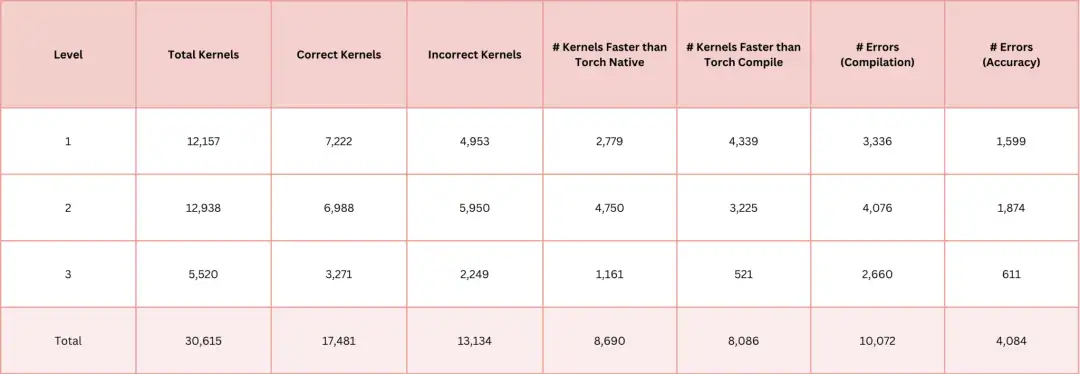
5. AI-CUDA-Engineer-Archive Kernel Collection Dataset
Der AI-CUDA-Engineer-Archive-Datensatz ist eine Sammlung von durch KI generierten CUDA-Kerneln, die das anschließende Training von Open-Source-Modellen und die Entwicklung besserer CUDA-Funktionsmodule erleichtern soll. Der Datensatz enthält mehr als 30.000 CUDA-Kernel, die alle von KI-gesteuerten CUDA-Ingenieuren generiert wurden. Bei mehr als 17.000 Kerneln wurde die Richtigkeit verifiziert, und etwa 50% der Kernel übertreffen die native Laufzeit von PyTorch.
Direkte Verwendung:https://go.hyper.ai/3lPrI
6. QM9-Quantenchemie-Datensatz
Der QM9-Datensatz ist ein weit verbreiteter Datensatz der Quantenchemie, der quantenchemische Berechnungsergebnisse von etwa 134.000 organischen kleinen Molekülen enthält. Diese Moleküle bestehen aus den Elementen Kohlenstoff, Wasserstoff, Stickstoff, Sauerstoff und Fluor und haben ein Molekulargewicht von maximal 900 Dalton.
Direkte Verwendung:https://go.hyper.ai/PZdz7
7. GEOM-Drugs 3D-Datensatz zur molekularen Konformation
Der GEOM-Drugs-Datensatz ist ein großer 3D-Datensatz zur Molekülkonformation, der 430.000 Moleküle enthält, von denen jedes durchschnittlich 44 Atome aufweist. Nach der Datenverarbeitung kann jedes Molekül bis zu 181 Atome enthalten. Im Experiment sammelten die Forscher die 30 Konformationen mit der niedrigsten Energie jedes Moleküls und baten jede Basismethode, die 3D-Positionen und Arten der Atome zu generieren, aus denen diese Moleküle bestehen.
Direkte Verwendung:https://go.hyper.ai/5B3U8
8. Wahrsagender chinesischer Feng-Shui-Wahrsagungsdatensatz
Der Datensatz enthält 207 Fragen zu Feng Shui, Bazi usw. und jede Frage hat eine eindeutige entsprechende Antwort.
Direkte Verwendung:https://go.hyper.ai/31k1P
9.SuperGPQA-Benchmark-Datensatz zur Themenbereichsbewertung
SuperGPQA ist ein Benchmark-Datensatz zur Bewertung der Leistung fortschrittlicher Frage-Antwort-Systeme. Der Schwerpunkt liegt auf den Bereichen der Verarbeitung natürlicher Sprache und der Bewertung maschinellen Lernens und zielt darauf ab, die Argumentationsfähigkeit und den Wissensstand des Modells anhand komplexer, fachübergreifender Fragen zu testen. Der Datensatz umfasst 285 Themenbereiche auf Hochschulniveau mit unterschiedlichen Fragetypen, darunter Biologie, Physik, Chemie und andere wissenschaftliche Bereiche.
Direkte Verwendung:https://go.hyper.ai/oP1pb
10. olmOCR-mix-0225 Großer PDF-Dokumentendatensatz
olmOCR-mix-0225 ist ein umfangreicher, hochwertiger PDF-Dokumentendatensatz, der zum Trainieren und Optimieren von OCR-Modellen (Optical Character Recognition) entwickelt wurde. Der Datensatz enthält etwa 250.000 Seiten PDF-Inhalte und deckt verschiedene Typen ab, beispielsweise wissenschaftliche Arbeiten, juristische Dokumente und Handbücher. Der Datensatz enthält nicht nur Textinhalte, sondern extrahiert auch die Koordinateninformationen hervorstechender Elemente (wie Textblöcke und Bilder) auf jeder Seite. Diese Informationen werden dynamisch in die Modelleingabeaufforderung eingefügt, wodurch die Halluzinationen des Modells erheblich reduziert werden.
Direkte Verwendung:https://go.hyper.ai/dXNkk
Ausgewählte öffentliche Tutorials
1. Bereitstellung von QwQ-32B-AWQ mit einem Klick
QwQ-32B ist das Inferenzmodell der Qwen-Reihe. Im Vergleich zu herkömmlichen Modellen zur Befehlsoptimierung verfügt QwQ über Denk- und Argumentationsfähigkeiten und kann bei nachgelagerten Aufgaben, insbesondere bei schwierigen Problemen, erhebliche Leistungsverbesserungen erzielen. Es ist vergleichbar mit fortgeschrittenen Inferenzmodellen wie DeepSeek-R1 und o1-mini.
Die relevanten Modelle und Abhängigkeiten dieses Projekts wurden bereitgestellt. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen.
Online ausführen:https://go.hyper.ai/Q8HmJ

2. Stellen Sie QwQ-32B mit vLLM bereit
vLLM ist ein Open-Source-Reasoning-Framework, das für die effiziente Bereitstellung großer Sprachmodelle entwickelt wurde. Seine Kerntechnologie reduziert die Hardwareschwelle für die Modellbegründung erheblich, indem sie die Speicherverwaltung und die Rechenleistung optimiert. In diesem Tutorial wird vLLM zum Bereitstellen des QwQ-32B-Modells verwendet, um die Bereitstellungskosten weiter zu senken und den Anforderungen interaktiverer Szenarien gerecht zu werden.
Die relevanten Modelle und Abhängigkeiten dieses Projekts wurden bereitgestellt. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen.
Online ausführen:https://go.hyper.ai/8nPfC
3.OpenManus + QwQ-32B implementiert Al Agent
OpenManus ist ein Open-Source-Projekt, das vom MetaGPT-Team gestartet wurde. Ziel ist es, die Kernfunktionen von Manus zu replizieren und Benutzern eine intelligente Agentenlösung bereitzustellen, die ohne Einladungscode lokal bereitgestellt werden kann.
Gehen Sie zur offiziellen Website, um den Container zu klonen und zu starten, rufen Sie den Arbeitsbereich auf und geben Sie die entsprechenden Befehle ein, um das Modell zu erleben.
Online ausführen:https://go.hyper.ai/GIX1H
4. Step-Audio-TTS-3B Modell zur Dialektsprachgenerierung auf Produktionsebene
Step-Audio ist das erste Open-Source-Sprachdialogsystem der Branche auf Produktebene in Echtzeit, das Sprachverständnis und Generierungssteuerung integriert. Es wurde 2025 vom Stepfun-AI-Team als Open Source veröffentlicht. Es unterstützt die Generierung mehrerer Sprachen (wie Chinesisch, Englisch und Japanisch), Stimmemotionen (wie Glück und Traurigkeit) und Dialekte (wie Kantonesisch und Sichuan-Dialekt). Es kann die Sprechgeschwindigkeit und den Rhythmusstil steuern und unterstützt RAP und Summen usw.
Gehen Sie zur offiziellen Website, um den Container zu klonen und zu starten, kopieren Sie die API-Adresse direkt und führen Sie eine multifunktionale Sprachsynthese durch.
Online ausführen:https://go.hyper.ai/WiyVK
Community-Artikel
Ein Team der University of Western Australia und anderer Institutionen schlug die Verwendung eines automatisierten Frameworks auf Basis von Deep Learning vor. Für die Studie wurden 200 Schädel-CT-Scans aus einem Krankenhaus in Indonesien verwendet, um drei auf Deep Learning basierende Netzwerkkonfigurationen zu trainieren und zu testen. Das genaueste Deep-Learning-Framework konnte zur Beurteilung Geschlecht und Schädelmerkmale kombinieren und erreichte dabei eine Klassifizierungsgenauigkeit von 97%, die deutlich höher war als die 82% menschlicher Beobachter. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe des Dokuments.
Den vollständigen Bericht ansehen:https://go.hyper.ai/0rfjM
Forscher des GIS Key Laboratory der Provinz Zhejiang haben ein Deep-Learning-Modell CatGWR vorgeschlagen, das auf einem Aufmerksamkeitsmechanismus basiert. Das Modell führt einen Aufmerksamkeitsmechanismus ein, um die räumliche Distanz und die kontextuelle Ähnlichkeit zwischen Proben zu kombinieren und so die räumliche Nichtstationarität genauer zu schätzen. Dies bietet neue Perspektiven für die Geodatenmodellierung, insbesondere bei der Behandlung komplexer geografischer Phänomene, und kann räumliche Heterogenität und Kontexteffekte besser erfassen. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe der Forschungsergebnisse.
Den vollständigen Bericht ansehen:https://go.hyper.ai/irDAo
HyperAI hat sorgfältig die gängigsten Reasoning-Datensätze zusammengestellt, die mehrere Bereiche wie Mathematik, Code, Wissenschaft, Rätsel usw. abdecken. Für Praktiker und Forscher, die die Reasoning-Fähigkeiten großer Modelle erheblich verbessern möchten, sind diese Datensätze zweifellos ein hervorragender Ausgangspunkt. Dieser Artikel ist die Downloadadresse für den Datensatz.
Den vollständigen Bericht ansehen:https://go.hyper.ai/XGIi8
Die Zhejiang-Universität und andere schlugen eine Technik namens Boltzmann-Ausrichtung vor, die Erkenntnisse aus dem vorab trainierten inversen Faltungsmodell auf die Vorhersage der Bindungsfreien Energie übertrug. Diese Methode zeigte eine überragende Leistung und wurde in die ICLR 2025 aufgenommen, die wichtigste internationale akademische Konferenz im Bereich der künstlichen Intelligenz. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe des Dokuments.
Den vollständigen Bericht ansehen:https://go.hyper.ai/MsUDj
NVIDIA hat in Zusammenarbeit mit dem MIT und anderen einen neuen Typ eines groß angelegten Protein-Backbone-Generators namens Proteina entwickelt. Proteina verfügt über die fünffache Anzahl an Parametern des RFdiffusion-Modells und hat seine Trainingsdaten auf 21 Millionen synthetische Proteinstrukturen erweitert. Es hat eine SOTA-Leistung beim De-novo-Design des Protein-Rückgrats erreicht und vielfältige und gestaltbare Proteine mit einer beispiellosen Länge von bis zu 800 Resten erzeugt. Die Ergebnisse wurden für die mündliche Prüfung ICLR 2025 ausgewählt. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe der Forschungsergebnisse.
Den vollständigen Bericht ansehen:https://go.hyper.ai/n4fWv
Lei Jun, Zhou Hongyi, Liu Qingfeng und andere Branchenführer verfolgten aufmerksam den Puls der Zeit und brachten aktiv Vorschläge und Anregungen in vielen Schlüsselbereichen ein, beispielsweise zu Fahrzeugen mit neuer Energie, großen Modellhalluzinationen, KI-medizinischer Versorgung, KI-Gesichtsveränderung und KI-Bildung. Weitere Einzelheiten finden Sie weiter unten.
Den vollständigen Bericht ansehen:https://go.hyper.ai/EazuY
Beliebte Enzyklopädieartikel
1. DALL-E
2. Reziproke Sortierfusion RRF
3. Pareto-Front
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kontrastives Lernen
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
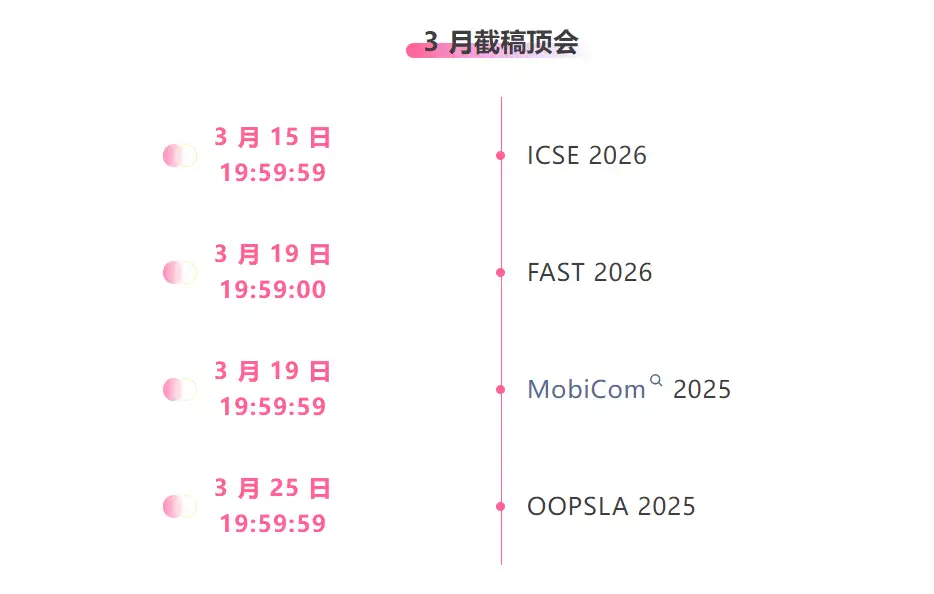
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








