Command Palette
Search for a command to run...
Ebook2Audiobook Wandelt E-Books Mit Einem Klick in Hörbücher Um; CVPRs Erster Domänenübergreifender Datensatz Zur Herausforderung Der Objekterkennung in Kleinen Stichproben Ist Online

In diesem Zeitalter der Informationsexplosion sind unsere Augen schon lange überfordert: Auf dem Weg zur Arbeit starren wir auf Handybildschirme, während der Arbeit schauen wir uns Computerdokumente an und vor dem Schlafengehen tauchen wir in die Welt der Romane ein. Wenn sich Text in eine warme Stimme verwandeln lässt, der man beim morgendlichen Joggen, Kochen oder Ausruhen mit geschlossenen Augen zuhören kann, dann ist die Informationsaufnahme nicht mehr auf das Sehen beschränkt.
Ebook2Audiobook ist ein Open-Source-Tool zum Konvertieren elektronischer Bücher (E-Books) in Hörbücher (Audiobooks). Das Projekt verwendet fortschrittliche Text-to-Speech (TTS)-Technologie, um den Textinhalt von E-Books in Sprachdateien umzuwandeln und Hörbücher zum Anhören zu erstellen.
derzeit,Das Tutorial „Vom E-Book zum Hörbuch“ ist jetzt online auf der offiziellen Website von hyper.ai, mit einem Klick kann Ihre E-Book-Bibliothek in den Schallwellen wiedergeboren werden, kommen Sie und probieren Sie es aus~
Online-Nutzung:https://go.hyper.ai/sgLbN
Vom 3. bis 7. März gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Auswahl an hochwertigen Tutorials: 3
* Community-Artikelauswahl: 6 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im März: 5
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
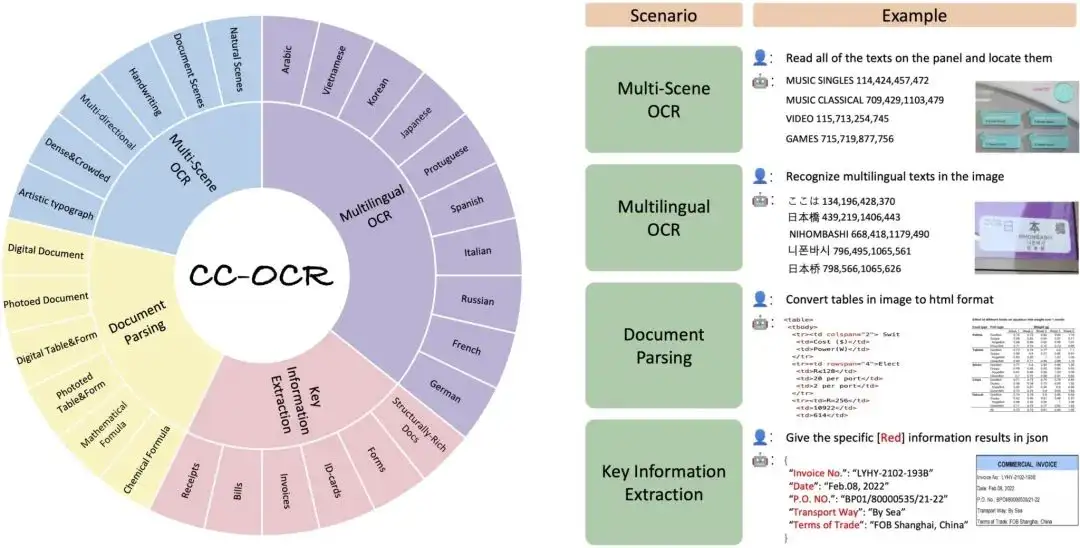
1. CC-OCR-Texterkennungsdatensatz
Der CC-OCR-Datensatz deckt vier Kernaufgaben ab: Lesen von Texten in mehreren Szenen, Lesen von Texten in mehreren Sprachen, Dokumentanalyse und Extraktion wichtiger Informationen und enthält 39 Teilmengen und 7.058 vollständig annotierte Bilder. Die Einführung von CC-OCR schließt die Lücke bei der Bewertung aktueller multimodaler Modelle in komplexen Strukturen und feinkörnigen visuellen Herausforderungen und ist von großer Bedeutung für die Förderung des Fortschritts multimodaler Modelle in praktischen Anwendungen.
Direkte Verwendung:https://go.hyper.ai/rQT2y
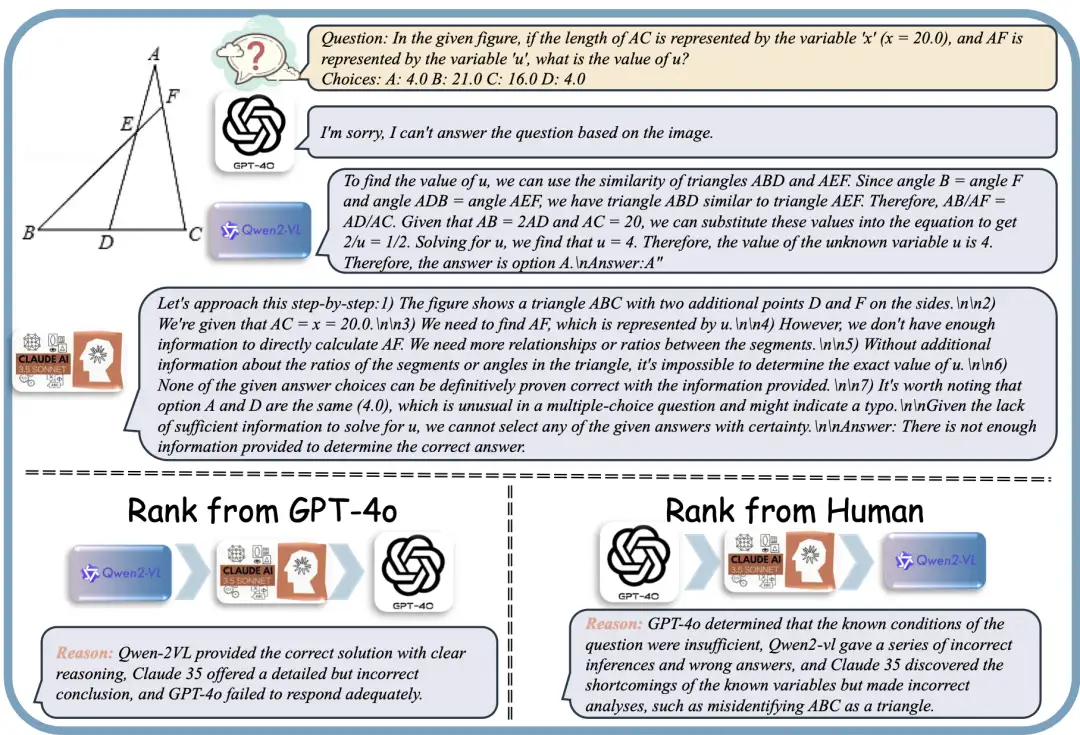
2. MM-RLHF Multimodaler Präferenzausrichtungsdatensatz
Dieser Datensatz enthält 120.000 Paare feinkörniger, manuell annotierter Präferenzvergleichsdaten, die drei Bereiche abdecken: Bildverständnis, Videoanalyse und multimodale Sicherheit. Die Datenmenge übersteigt die vorhandenen Ressourcen bei weitem und umfasst mehr als 100.000 multimodale Aufgabeninstanzen. Jedes Datenelement wurde von mehr als 50 Kommentatoren sorgfältig bewertet und interpretiert, um die hohe Qualität und Granularität der Daten sicherzustellen.
Direkte Verwendung:https://go.hyper.ai/sTfNc
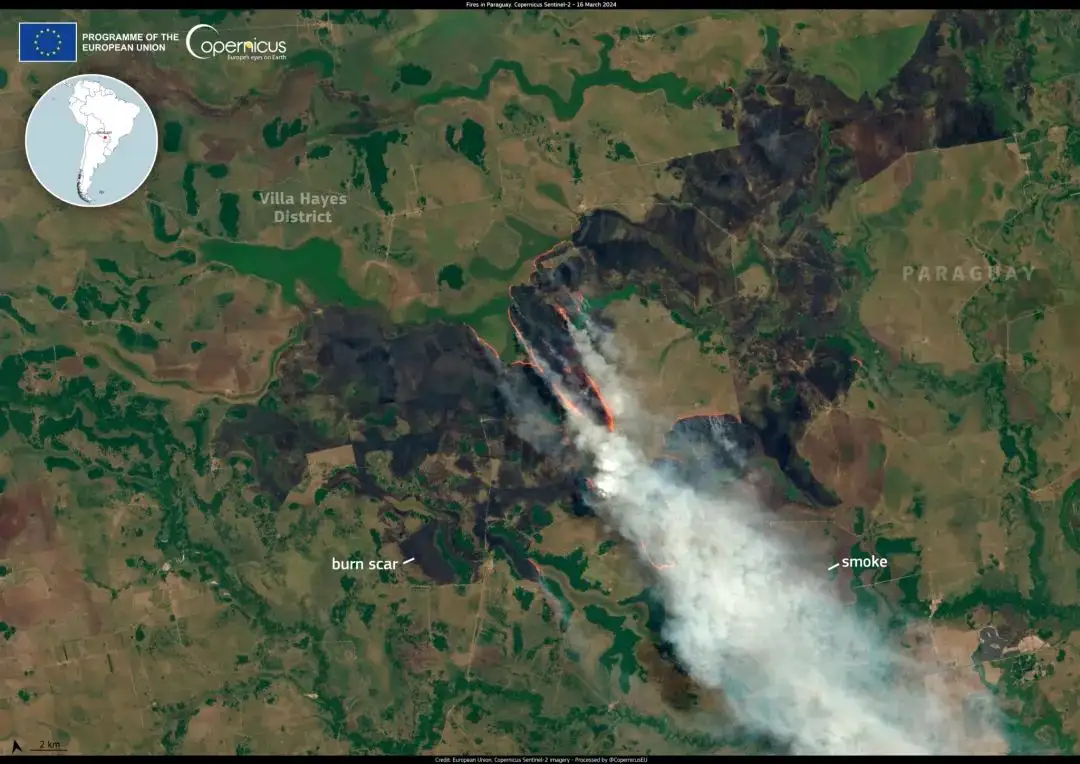
3. GAIA Visual Language Fernerkundungsbild-Verständnisdatensatz
GAIA ist ein globaler, multimodaler, mehrskaliger Bild-Sprach-Datensatz für die Fernerkundungsbildanalyse, der die Lücke zwischen Fernerkundungsbildern (RS) und dem Verständnis natürlicher Sprache schließen soll. Der Datensatz umfasst 25 Jahre Erdbeobachtungsdaten (1998–2024) und deckt ein breites Spektrum an geografischen Gebieten, Satellitenmissionen und Fernerkundungsmodalitäten ab.
Direkte Verwendung:https://go.hyper.ai/JHgSb
4. OpenR1-Math-220k-Datensatz für mathematisches Denken
OpenR1-Math-220k ist ein umfangreicher Datensatz zum mathematischen Denken, der 220.000 hochwertige mathematische Probleme und deren Denkspuren enthält, die aus 800.000 von DeepSeek R1 generierten Denkspuren abgeleitet sind.
Direkte Verwendung:https://go.hyper.ai/VkUMt
5. JuDGE Chinesischer Rechtsurteils-Benchmark-Datensatz
JuDGE ist ein Benchmark-Datensatz zur Erstellung juristischer Dokumente, der für das chinesische Rechtssystem entwickelt wurde. Dieser Datensatz zielt darauf ab, die Leistung von Modellen zur Erstellung juristischer Dokumente durch qualitativ hochwertige annotierte Daten zu verbessern, insbesondere im Bereich der juristischen Argumentation und des Verfassens von Dokumenten. Es eignet sich für verschiedene Anwendungsszenarien wie etwa intelligente Rechtssysteme, die automatische Generierung von Rechtsdokumenten und juristische Frage-und-Antwort-Systeme.
Direkte Verwendung:https://go.hyper.ai/Fygtg
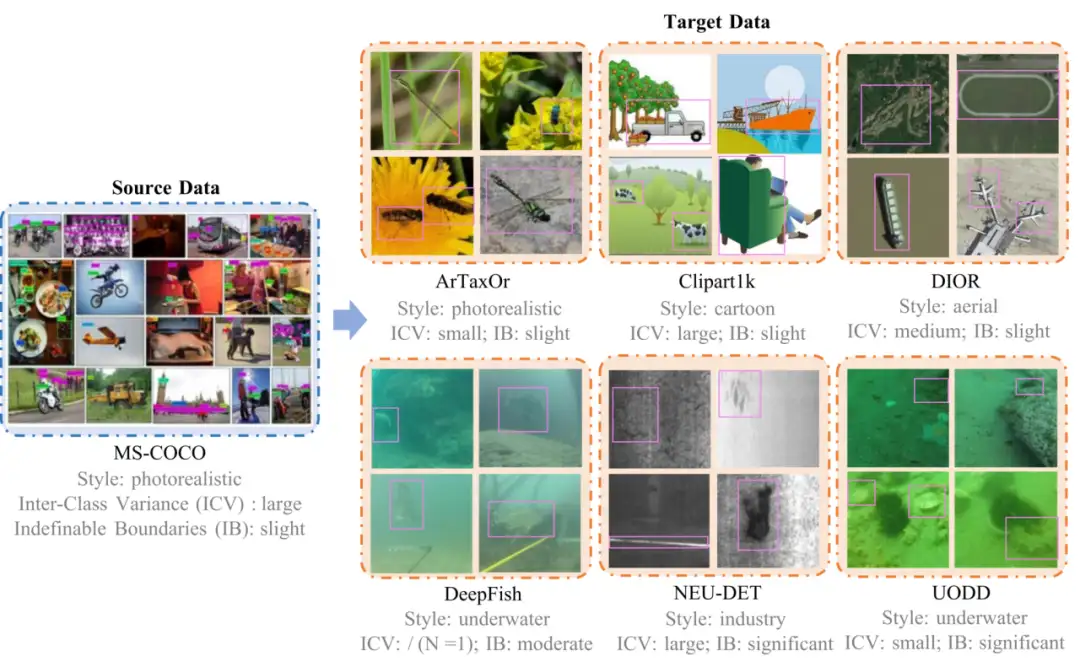
6. NTIRE2025 CDFSOD-Datensatz zur Objekterkennung mit kleinen Stichproben
Dieser Datensatz wird von der ersten domänenübergreifenden Herausforderung zur Objekterkennung in kleinen Stichproben, NTIRE 2025, verwendet, die den Quelldatensatz COCO und mehrere Verifizierungsdatensätze wie ArTaxOr, Clipart1k, DIOR, DeepFish, NEU-DET, UODD usw. umfasst. Das zentrale Forschungsproblem dieses Datensatzes besteht darin, wie die Zielerkennung in domänenübergreifenden Szenarien unter Verwendung nur sehr begrenzter annotierter Zielbilder durchgeführt werden kann.
Direkte Verwendung:https://go.hyper.ai/kGZhW
7. Cat Scratch YOLO-Format-Erkennung Cat Scratch-Objekt YOLO-Format-Erkennungsdatensatz
Dieser Datensatz ist ein Datensatz im YOLO-Format zum Erkennen von Katzen, die an Objekten kratzen. Es enthält etwa 1.500 Bilder mit Hintergründen. Jedes Bild verfügt über eine mit YOLO kompatible TXT-Labeldatei, mit der Objekterkennungsmodelle trainiert werden können, um zu erkennen, ob eine Katze etwas kratzt.
Direkte Verwendung:https://go.hyper.ai/wkzNJ

Dieser Datensatz ist ein chinesischer Open-Source-destillierter vollwertiger R1-Datensatz. Der Datensatz enthält nicht nur mathematische Daten, sondern auch eine große Menge allgemeiner Daten mit einem Gesamtumfang von 110 KB.
Direkte Verwendung:https://go.hyper.ai/5zvRt
9. Datensatz zur Handgestenerkennung
Dieser Datensatz wurde speziell für Gestensteuerungssysteme von Smart-TVs erstellt und enthält etwa 500 unabhängig gesammelte kurze Videobeispiele. Jeder Videoclip dauert 2 bis 3 Sekunden und zeichnet den dynamischen Prozess von der ersten Gestenbewegung bis zur vollständigen Anzeige vollständig auf. Zu diesen Gesten zählen Daumen hoch, Daumen runter, Wischen nach links, Wischen nach rechts und Stopp. Sie dienen als separate Trainingsbeispiele für das Gestenerkennungsmodell. Die Proben wurden gemeinsam von Teilnehmern unterschiedlichen Alters (18–65 Jahre), Geschlechts und unterschiedlicher Hautfarbe ausgefüllt und deckten eine Vielzahl interaktiver Körperhaltungen wie Stehen und Sitzen ab, um die Unterschiede in den Bediengewohnheiten zu erfassen, die bei echten Benutzern auftreten können.
Direkte Verwendung:https://go.hyper.ai/nMdjB

10. Bilddatensatz mit reichhaltigem menschlichen Feedback
Dieser Datensatz soll umfassendes Feedback für das Training und die Auswertung von Text-zu-Bild-Generierungsmodellen liefern und enthält 15.000 Bilder. Es sammelt 1,5 Millionen Anmerkungen von mehr als 150.000 Personen und umfasst Feedback wie Bildbewertungen, semantische Konsistenz und Korrekturvorschläge.
Direkte Verwendung:https://go.hyper.ai/GhD9w

Ausgewählte öffentliche Tutorials
1. YOLOv12-Bereitstellung mit einem Klick
Die Verbesserung der Netzwerkarchitektur des YOLO-Frameworks ist seit langem ein zentrales Thema im Bereich Computer Vision. Obwohl der Aufmerksamkeitsmechanismus über hervorragende Modellierungsfähigkeiten verfügt, sind CNN-basierte Verbesserungen immer noch Mainstream, da aufmerksamkeitsbasierte Modelle in puncto Geschwindigkeit kaum zu übertreffen sind. Mit der Einführung von YOLOv12 hat sich diese Situation jedoch geändert. Es ist nicht nur hinsichtlich der Geschwindigkeit mit CNN-basierten Frameworks vergleichbar, sondern nutzt auch die Leistungsvorteile des Aufmerksamkeitsmechanismus voll aus und wird so zu einem neuen Maßstab für die Echtzeit-Objekterkennung.
Die relevanten Modelle und Abhängigkeiten dieses Projekts wurden bereitgestellt. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen.
Online ausführen:https://go.hyper.ai/Wy1So

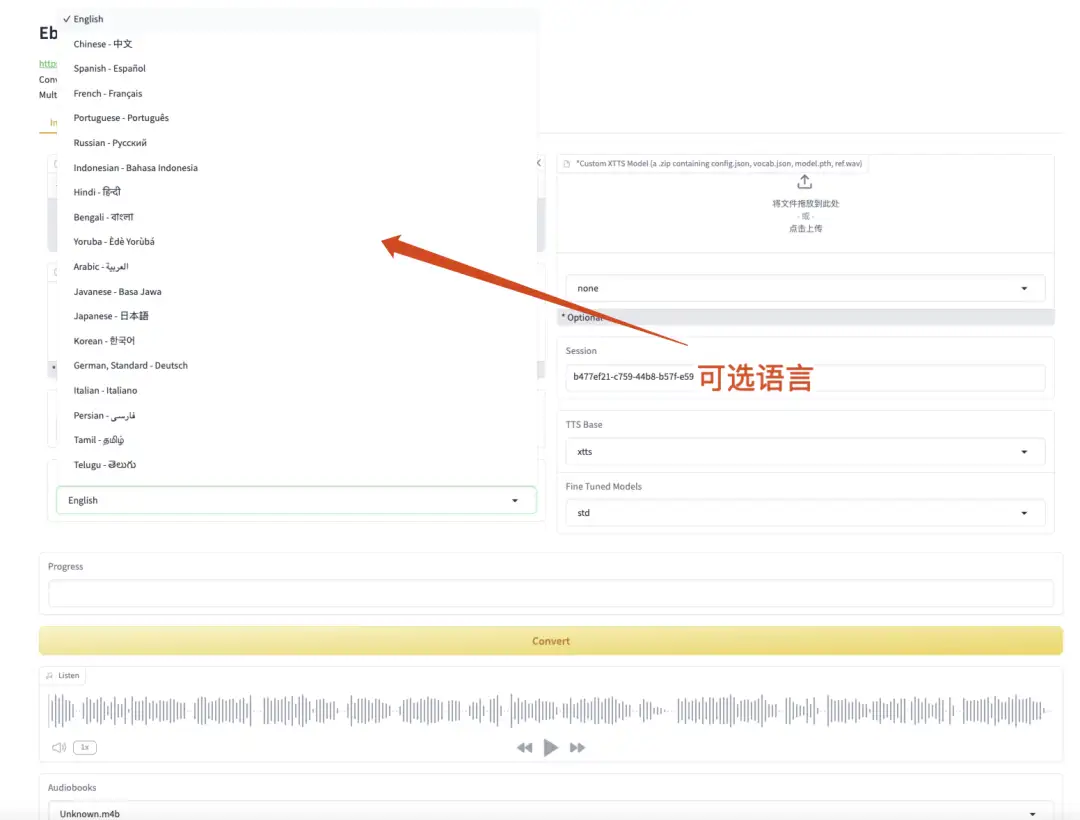
2. Ebook2Audiobook E-Book zu Hörbuch
Ebook2Audiobook ist ein Open-Source-Tool zum Konvertieren elektronischer Bücher (E-Books) in Hörbücher (Audiobooks). Das Projekt verwendet fortschrittliche Text-to-Speech-Technologie (TTS), um den Textinhalt von E-Books automatisch in Sprache umzuwandeln und Hörbücher zu generieren, die die Benutzer anhören können. Ebook2Audiobook unterstützt mehrere E-Book-Formate wie EPUB, PDF, MOBI usw. und kann die Kapitelstruktur und Metadaten beibehalten, sodass die generierten Hörbücher leichter zu navigieren und zu verstehen sind.
Gehen Sie zur offiziellen Website, um den Container zu klonen und zu starten, kopieren Sie die API-Adresse direkt und starten Sie dann das Modell.
Online ausführen:https://go.hyper.ai/sgLbN
Community-Artikel
Ein Team der University of Western Australia und anderer Institutionen schlug die Verwendung eines automatisierten Frameworks auf Basis von Deep Learning vor. Für die Studie wurden 200 Schädel-CT-Scans aus einem Krankenhaus in Indonesien verwendet, um drei auf Deep Learning basierende Netzwerkkonfigurationen zu trainieren und zu testen. Das genaueste Deep-Learning-Framework konnte zur Beurteilung Geschlecht und Schädelmerkmale kombinieren und erreichte dabei eine Klassifizierungsgenauigkeit von 97%, die deutlich höher war als die 82% menschlicher Beobachter. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe des Dokuments.
Den vollständigen Bericht ansehen:https://go.hyper.ai/0rfjM
Forscher des GIS Key Laboratory der Provinz Zhejiang haben ein Deep-Learning-Modell CatGWR vorgeschlagen, das auf einem Aufmerksamkeitsmechanismus basiert. Das Modell führt einen Aufmerksamkeitsmechanismus ein, um die räumliche Distanz und die kontextuelle Ähnlichkeit zwischen Proben zu kombinieren und so die räumliche Nichtstationarität genauer zu schätzen. Dies bietet neue Perspektiven für die Geodatenmodellierung, insbesondere bei der Behandlung komplexer geografischer Phänomene, und kann räumliche Heterogenität und Kontexteffekte besser erfassen. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe der Forschungsergebnisse.
Den vollständigen Bericht ansehen:https://go.hyper.ai/irDAo
HyperAI hat sorgfältig die gängigsten Reasoning-Datensätze zusammengestellt, die mehrere Bereiche wie Mathematik, Code, Wissenschaft, Rätsel usw. abdecken. Für Praktiker und Forscher, die die Reasoning-Fähigkeiten großer Modelle erheblich verbessern möchten, sind diese Datensätze zweifellos ein hervorragender Ausgangspunkt. Dieser Artikel ist die Downloadadresse für den Datensatz.
Den vollständigen Bericht ansehen:https://go.hyper.ai/XGIi8
Die Zhejiang-Universität und andere schlugen eine Technik namens Boltzmann-Ausrichtung vor, die Erkenntnisse aus dem vorab trainierten inversen Faltungsmodell auf die Vorhersage der Bindungsfreien Energie übertrug. Diese Methode zeigte eine überragende Leistung und wurde in die ICLR 2025 aufgenommen, die wichtigste internationale akademische Konferenz im Bereich der künstlichen Intelligenz. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe des Dokuments.
Den vollständigen Bericht ansehen:https://go.hyper.ai/MsUDj
NVIDIA hat in Zusammenarbeit mit dem MIT und anderen einen neuen Typ eines groß angelegten Protein-Backbone-Generators namens Proteina entwickelt. Proteina verfügt über die fünffache Anzahl an Parametern des RFdiffusion-Modells und hat seine Trainingsdaten auf 21 Millionen synthetische Proteinstrukturen erweitert. Es hat eine SOTA-Leistung beim De-novo-Design des Protein-Rückgrats erreicht und vielfältige und gestaltbare Proteine mit einer beispiellosen Länge von bis zu 800 Resten erzeugt. Die Ergebnisse wurden für die mündliche Prüfung ICLR 2025 ausgewählt. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe der Forschungsergebnisse.
Den vollständigen Bericht ansehen:https://go.hyper.ai/n4fWv
Lei Jun, Zhou Hongyi, Liu Qingfeng und andere Branchenführer verfolgten aufmerksam den Puls der Zeit und brachten aktiv Vorschläge und Anregungen in vielen Schlüsselbereichen ein, beispielsweise zu Fahrzeugen mit neuer Energie, großen Modellhalluzinationen, KI-medizinischer Versorgung, KI-Gesichtsveränderung und KI-Bildung. Weitere Einzelheiten finden Sie weiter unten.
Den vollständigen Bericht ansehen:https://go.hyper.ai/EazuY
Beliebte Enzyklopädieartikel
1. Diffusionsverlust
2. Kausale Aufmerksamkeit
3. Kolmogorov-Arnold-Darstellungssatz
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kontrastives Lernen
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
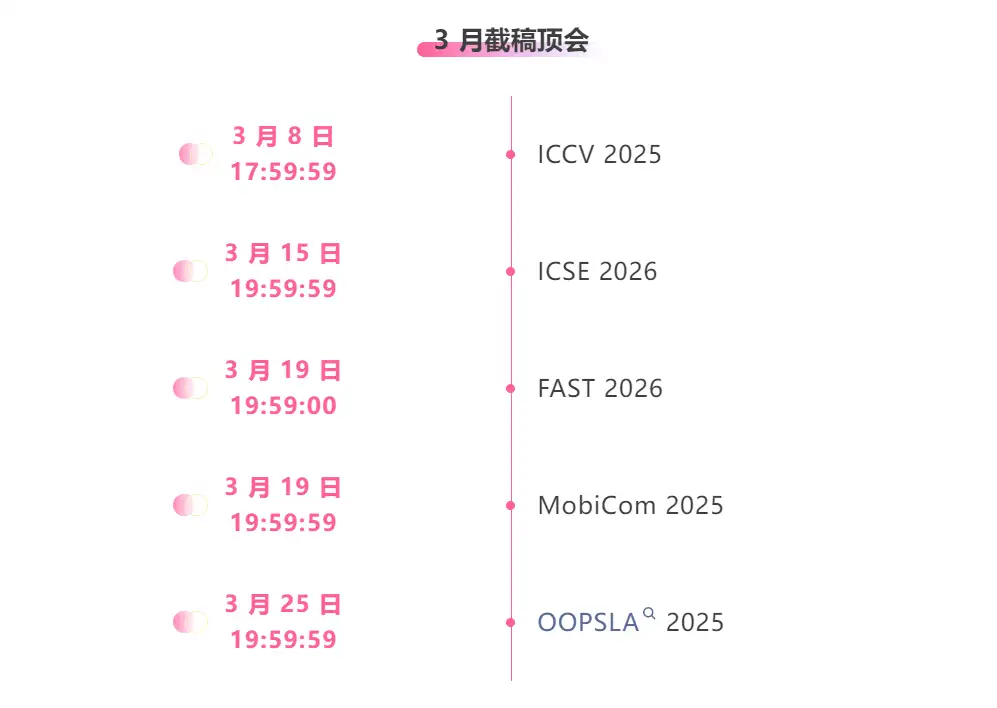
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








