Command Palette
Search for a command to run...
Dem Tsinghua-Team Ist Es Erstmals Gelungen, Die Molekülerzeugung Und Die Eigenschaftsvorhersage Zu vereinen. Es Wurde Ein Zweistufiger Diffusionserzeugungsmechanismus Vorgeschlagen Und Für ICLR 2025 ausgewählt.

Die Technologie der künstlichen Intelligenz verändert den Prozess der Arzneimittelentwicklung grundlegend.Dabei haben sich die Vorhersage molekularer Eigenschaften und die Molekülerzeugung als zwei Kernaufgaben seit langem auf unabhängigen technischen Wegen entwickelt.Der Zweck der Vorhersage molekularer Eigenschaften besteht darin, anhand von Informationen zur Molekülstruktur die verschiedenen chemischen und biologischen Eigenschaften von Molekülen vorherzusagen und das Arzneimittelscreening zu beschleunigen. Ziel der Molekülgenerierung ist es, die Verteilung molekularer Daten abzuschätzen, möglicherweise atomare Wechselwirkungen und Konformationsinformationen zu erlernen und in der Lage zu sein, von Grund auf neue chemisch rationale Moleküle zu erzeugen und so die Grenzen der Möglichkeiten für das Arzneimitteldesign zu erweitern. Obwohl in diesen Bereichen in den letzten Jahren viel geforscht wurde, haben sie sich weitgehend unabhängig voneinander entwickelt.Die Kanäle für die Zusammenarbeit zwischen diesen beiden wichtigen Bindegliedern wurden nie wirklich geöffnet.
In Anbetracht dessenDie Tsinghua-Universität und das Team der Chinesischen Akademie der Wissenschaften haben das UniGEM-Modell vorgeschlagen, mit dem erstmals eine gemeinsame Verbesserung zweier Aufgaben auf der Grundlage eines Diffusionsmodells erreicht wurde.Das Forschungsteam wies darauf hin, dass die Vorhersage von Erzeugung und Eigenschaften stark korreliert und auf einer effektiven molekularen Darstellung beruht. Das Team schlug einen innovativen zweistufigen Generierungsprozess vor, der die Inkonsistenzen beim herkömmlichen Gelenktraining überwand und einen neuen Weg im Bereich der Molekülgenerierung und Eigenschaftsvorhersage eröffnete. Diese Leistung wurde für ICLR 2025 unter dem Titel „UniGEM: Ein einheitlicher Ansatz zur Erzeugung und Eigenschaftsvorhersage von Molekülen“ ausgewählt.

Papieradresse:
https://openreview.net/pdf?id=Lb91pXwZMR
QM9-Quantenchemie-Datensatz:
GEOM-Drugs 3D-Datensatz zur Molekülkonformation:
Das Open-Source-Projekt „awesome-ai4s“ vereint mehr als 200 AI4S-Papierinterpretationen und stellt umfangreiche Datensätze und Tools bereit:
https://github.com/hyperai/awesome-ai4s
Motivation für die Vereinheitlichung von Generierungs- und Vorhersageaufgaben
Das Forschungsteam ist davon überzeugt, dass die Essenz sowohl der Generierungs- als auch der Vorhersageaufgaben im Erlernen molekularer Darstellungen liegt.Einerseits zeigt die Wirksamkeit verschiedener molekularer Vortrainingsmethoden, dass die Vorhersage molekularer Eigenschaften auf einer robusten molekularen Darstellung als Grundlage beruht. Andererseits erfordert die Molekülgenerierung ein tiefes Verständnis der Molekülstruktur, um während des Generierungsprozesses gute Darstellungen erstellen zu können.
Aktuelle Forschungsergebnisse stützen diese Ansicht. Beispielsweise hat die Arbeit im Bereich der Computervision gezeigt, dass Diffusionsmodelle selbst die Fähigkeit besitzen, effektive Bilddarstellungen zu erlernen. Im molekularen Bereich haben Studien gezeigt, dass generatives Vortraining Aufgaben zur Vorhersage molekularer Eigenschaften verbessern kann, obwohl diese Methoden oft eine zusätzliche Feinabstimmung erfordern, um eine optimale Vorhersageleistung zu erzielen. Obwohl Prädiktoren die Molekülgenerierung über Klassifikator-Leitungsmethoden steuern können, bleibt unklar, ob das Training von Prädiktoren die Generierungsleistung direkt verbessern kann.
Daher ist die Beziehung zwischen Generierungsaufgaben und Vorhersageaufgaben durch die bestehende Forschung noch nicht vollständig geklärt.Dies wirft eine wichtige Frage auf: Können wir ein einheitliches Modell erstellen, das eine synergetische Verbesserung der Generierungs- und Vorhersageaufgaben erreicht?
Analyse der Gründe für das Versagen traditioneller Methoden
Eine einfache Möglichkeit, diese beiden Aufgaben zu kombinieren, besteht in der Verwendung eines herkömmlichen Multitasking-Lernframeworks, bei dem das Modell sowohl den Generierungsverlust als auch den Vorhersageverlust optimiert. Allerdings zeigten die vom Forschungsteam durchgeführten Experimente, dass dieser Ansatz die Leistung bei Generierungs- und Eigenschaftsvorhersageaufgaben erheblich reduzierte (die Generierungsstabilität sank um 6% und der Vorhersagefehler erhöhte sich um mehr als das 1-fache). Selbst nachdem die Gewichte des generativen Modells eingefroren und ein separater Kopf für die Eigenschaftsvorhersageaufgabe hinzugefügt wurden, um die Generierungsleistung aufrechtzuerhalten, beobachteten die Forscher keine Verbesserung der Eigenschaftsvorhersageleistung im Vergleich zum Training von Grund auf.
Die Forscher führen die schlechten Ergebnisse traditioneller Methoden auf die inhärente Inkonsistenz zwischen Generierungs- und Vorhersageaufgaben zurück.Während des Diffusionserzeugungsprozesses muss die Molekülstruktur eine schrittweise Rekonstruktion vom ungeordneten Rauschen zur Feinstruktur durchlaufen. Bei Vorhersageaufgaben können aussagekräftige Moleküleigenschaften jedoch erst definiert werden, nachdem die Molekülstruktur im Wesentlichen feststeht. Daher führt die bloße Anwendung eines einfachen Multitasking-Optimierungsansatzes dazu, dass in der frühen Diffusionsphase stark ungeordnete Molekülkonformationen fälschlicherweise mit Eigenschaftsbezeichnungen verknüpft werden, was sich negativ auf die Molekülerzeugung und die Eigenschaftsvorhersage auswirkt.
Um diesen Punkt weiter zu veranschaulichen, führten die Forscher eine theoretische Analyse der gegenseitigen Information zwischen den Zwischendarstellungen innerhalb des Rauschunterdrückungsnetzwerks und den Zielmolekülen während des Diffusionstrainings durch.Darüber hinaus ist theoretisch bewiesen, dass das Diffusionsmodell implizit die Untergrenze der gegenseitigen Information zwischen der Zwischendarstellung und dem Zielmolekül maximiert, was auf die Fähigkeit des Diffusionsmodells hinweist, Darstellungen zu lernen. Die gegenseitige Information zwischen der Zwischendarstellung und dem Zielmolekül zeigt jedoch einen monoton abnehmenden Trend und nähert sich bei größeren Zeitschritten Null an, was bedeutet, dass die Zwischendarstellung im ungeordneten Stadium keine effektive Vorhersage unterstützen kann. Daher legen sowohl Intuition als auch Theorie nahe, dass die Generierungs- und Vorhersageaufgaben nur in kleineren Zeitschritten ausgerichtet werden können, wenn die Moleküle relativ geordnet bleiben.
Zweistufiger Diffusionserzeugungsmechanismus
Basierend auf der obigen Analyse,Das Forschungsteam schlug eine neuartige zweistufige Generierungsmethode vor, die darauf abzielt, die Vorhersage und Generierung molekularer Eigenschaften zu vereinheitlichen, wie in der folgenden Abbildung dargestellt.
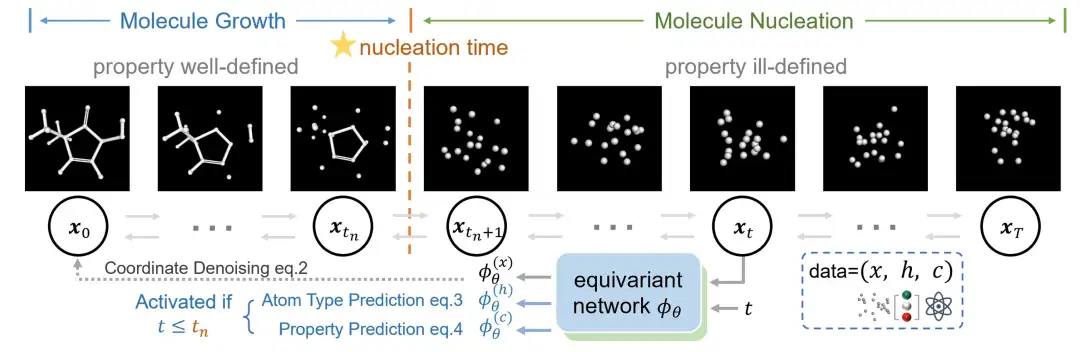
Forscher unterteilen den Molekülerzeugungsprozess in zwei Phasen, nämlich die "molekulare Keimbildungsphase" und die "molekulare Wachstumsphase",Diese Einteilung ist vom Kristallbildungsprozess in der Physik inspiriert.
Während der Molekülkeimbildungsphase bildet das Molekül sein Skelett aus einem völlig ungeordneten Zustand, und dann wächst das vollständige Molekül auf der Grundlage dieses Skeletts. Diese beiden Phasen sind durch die „Keimbildungszeit“ getrennt. Die Forscher führten eine neue Methode zur Generierung von Molekülen ein, um diese beiden Phasen zu beschreiben. Unter diesen erzeugt das Diffusionsmodell vor der „Keimbildungszeit“ allmählich molekulare Koordinaten; Nach der Keimbildung passt das Modell die Molekülkoordinaten weiter an und optimiert gleichzeitig die Eigenschaften und Verluste bei der Vorhersage des Atomtyps.
Anders als herkömmliche generative Modelle, die normalerweise eine gemeinsame Diffusion von Atomtypen und Koordinaten durchführen, konzentriert sich diese innovative Methode nur auf die Diffusion von Koordinaten und behandelt Atomtypen als separate Vorhersageaufgabe.Denn die Forscher stellten fest, dass sich aus den Koordinaten der gebildeten Moleküle oft auf die Atomtypen schließen ließen. Insbesondere zielt der Diffusionsprozess vor der Keimbildung darauf ab, die Koordinaten zu rekonstruieren. Nach der Keimbildung integriert es die Vorhersageverluste von Atomtypen und -eigenschaften in ein einheitliches Lernframework.
UniGEM-Ausbildungsstrategie
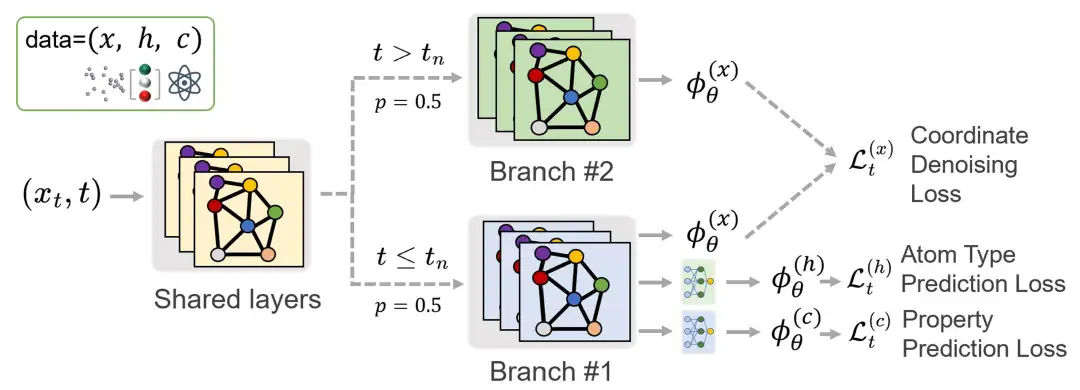
Um den Vergleich mit der herkömmlichen Methode der gemeinsamen Diffusion zu erleichtern, übernahmen die Forscher das E(3)-äquivariante Diffusionsmodell (EDM) unter Verwendung von EGNN als Netzwerkstrukturgerüst. Davon macht die Wachstumsphase nur etwa 1% des gesamten Trainingsprozesses aus. Wenn wir dem Standardverfahren für das Diffusionstraining folgen und die Zeitschritte gleichmäßig abtasten, beträgt die Anzahl der Iterationen für die Vorhersageaufgabe nur 1% des gesamten Trainingsprozesses, was die Leistung des Modells bei dieser Aufgabe erheblich reduziert.Um ein angemessenes Training für die Vorhersageaufgabe sicherzustellen, haben die Forscher daher die Zeitschritte während der Wachstumsphase überabgetastet.
Die Forscher stellten jedoch fest, dass eine Überabtastung zu einem unausgewogenen Training über die verschiedenen Zeitschritte hinweg führen kann, was wiederum die Qualität des Generierungsprozesses beeinträchtigt. Zur Lösung dieses Problems wird eine Netzwerkarchitektur mit mehreren Zweigstellen vorgeschlagen. Das Netzwerk teilt Parameter auf flachen Ebenen, teilt sich jedoch auf tieferen Ebenen in zwei Zweige auf, von denen jeder über einen unabhängigen Parametersatz verfügt.Diese Zweige werden in verschiedenen Phasen des Trainings aktiviert: Ein Zweig konzentriert sich auf die Keimbildungsphase, ein anderer auf die Wachstumsphase,Wie in der Abbildung unten gezeigt. Dieses Design stellt sicher, dass die Vorhersageaufgabe und die Generierungsaufgabe effektiv trainiert werden können, ohne sich gegenseitig zu beeinflussen.
UniGEMs Denkprozess
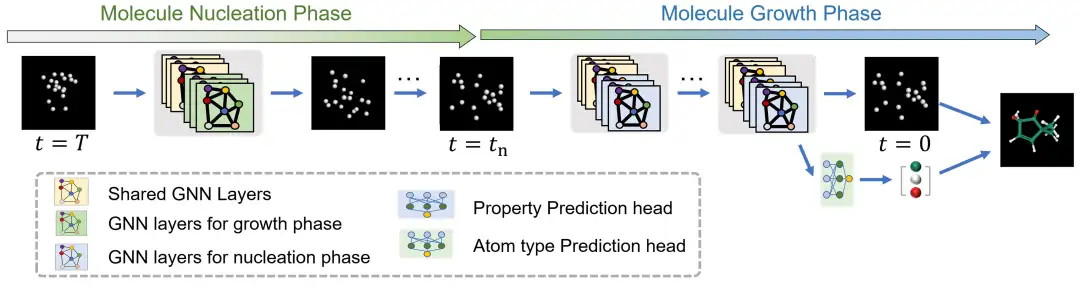
In UniGEM,Die Molekülgenerierung erfolgt durch die Rekonstruktion atomarer Koordinaten durch einen Rückdiffusionsprozess und die anschließende Vorhersage des Atomtyps auf Grundlage der generierten Koordinaten.Wie auf dem Bild zu sehen. Zur Eigenschaftsvorhersage wird der Netzwerk-Eingangszeitschritt auf Null festgelegt und der Eigenschaftsvorhersagekopf verwendet. Es ist erwähnenswert, dass dieser Ansatz weder für die Generierungsaufgabe noch für die Vorhersageaufgabe zusätzlichen Rechenaufwand verursacht und dass die gesamte Inferenzzeit dieselbe ist wie die Basislinie.
Für die Aufgabe der molekularen Generierung analysierten die Forscher auch die Unterschiede bei den Generierungsfehlern zwischen UniGEM und herkömmlichen gemeinsamen Generierungsmethoden.Zunächst wird beobachtet, dass der Fehler des Atomtypvorhersageverlusts in UniGEM kleiner ist als der Verlust durch die Atomtyp-Rauschunterdrückung bei der gemeinsamen Generierung. Zweitens wird die Koordinatengenerierung während des gemeinsamen Generierungsprozesses durch die Schwingung der Ergebnisse der Atomtypvorhersage beeinflusst, was zu erhöhten Fehlern führt. Schließlich führt die Methode der gemeinsamen Generierung auch zu größeren anfänglichen Verteilungsfehlern und Diskretisierungsfehlern. Zusammen erklären diese Faktoren, wie UniGEM überlegene Generationsergebnisse erzielt.
Experimentelle Ergebnisse: Übertreffen Sie das Basismodell sowohl bei der Molekülgenerierung als auch bei der Eigenschaftsvorhersage
Molekulare Generation: UniGEM übertrifft Benchmark-Modelle
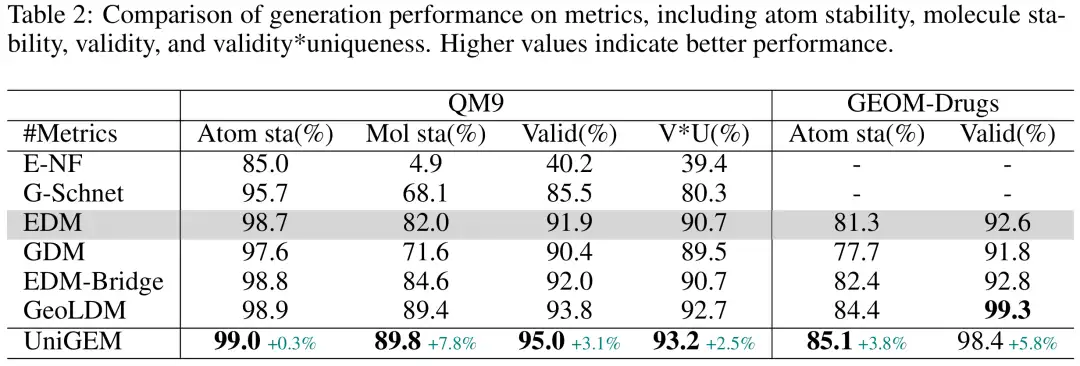
Die Forscher verglichen zunächst das EDM-basierte UniGEM mit EDM-Varianten der QM9- und GEOM-Drugs-Datensätze. UniGEM übertraf das Basismodell bei fast allen Bewertungsindikatoren, wie in der folgenden Abbildung dargestellt. Es ist erwähnenswert, dass im Vergleich zu anderen EDM-Varianten,UniGEM ist wesentlich einfacher, da es weder auf Vorkenntnissen beruht noch ein zusätzliches Autoencoder-Training erfordert. Dennoch übertrifft es EDM-Bridge und GeoLDM, was die Vorteile von UniGEM hervorhebt.
Um die Flexibilität von UniGEM bei der Anpassung an verschiedene Generierungsalgorithmen zu demonstrieren, wandten die Forscher UniGEM auf Bayesianische Flussnetzwerke (BFNs) an und übertrafen dabei GeoBFN, das gemeinsam Koordinaten und Atomtypen generierte, auf dem QM9-Datensatz, wodurch SOTA-Ergebnisse erzielt wurden.
Darüber hinaus testeten die Forscher die Leistung von UniGEM bei Aufgaben zur bedingten Generierung. Sie vermieden die Notwendigkeit, das Modell zur bedingten Generierung neu zu trainieren, indem sie das modelleigene Eigenschaftsvorhersagemodul während des Sampling-Prozesses als Leitfaden verwendeten.
Vorhersage molekularer Eigenschaften: UniGEM übertrifft die meisten Vortrainingsmethoden
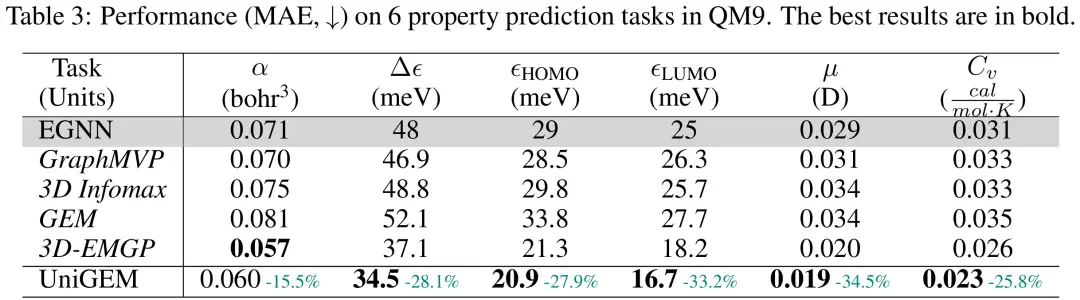
Die Forscher bewerteten die Leistung der UniGEM-Eigenschaftsvorhersage anhand des QM9-Datensatzes und verwendeten dabei den mittleren absoluten Fehler (MAE) des Testsatzes als Bewertungsmaß. Wie in der Abbildung gezeigt,UniGEM übertrifft von Grund auf trainiertes EGNN deutlich und demonstriert damit die Effektivität der einheitlichen Modellierung.Überraschenderweise übertrifft UniGEM die meisten dieser hochmodernen Vortrainingsmethoden immer noch, obwohl es zusätzliche groß angelegte Vortrainingsdatensätze nutzt. Dies unterstreicht den Vorteil seines einheitlichen Modells für die Generierung und Vorhersage, das die Leistungsfähigkeit des molekularen Repräsentationslernens während des Generierungsprozesses effektiv nutzen kann, ohne dass zusätzliche Daten und Vortrainingsschritte erforderlich sind.
Abschluss
Das UniGEM-Modell vereint die Aufgaben der Molekülerzeugung und der Eigenschaftsvorhersage und verbessert die Leistung beider Verfahren erheblich. Die verbesserte Leistung von UniGEM wird durch solide theoretische Analysen und umfassende experimentelle Studien unterstützt. Wir sind davon überzeugt, dass der innovative zweistufige Generierungsprozess und das dazugehörige Modell ein neues Paradigma für die Entwicklung molekularer Generierungsgerüste darstellen und die Entwicklung fortschrittlicherer molekularer Generierungsgerüste inspirieren können, wodurch die molekulare Generierung in spezifischeren Anwendungsfeldern von Nutzen sein wird.
Diese Forschung wird vom ATOM Lab geleitet. Das Team verfügt über weitere Forschungsergebnisse in den Bereichen molekulares Vortraining, molekulare Generierung, Vorhersage von Proteinstrukturen, virtuelles Screening usw., also bitte aufgepasst!
Willkommen auf der ATOM Lab-Homepage:
https://atomlab.yanyanlan.com/
Über den Autor:
* Lan Yanyan ist Professor am Institute of Intelligent Industries (AIR) der Tsinghua-Universität. Ihre Forschungsinteressen umfassen AI4Science, maschinelles Lernen und natürliche Sprachverarbeitung.
* Shikun Feng ist Doktorand am Institute of Intelligent Industries (AIR) der Tsinghua-Universität. Zu seinen Forschungsinteressen zählen Repräsentationslernen, generative Modelle und AI4Science.
* Yuyan Ni ist Doktorand an der Academy of Mathematics and Systems Science (AMSS) der Chinesischen Akademie der Wissenschaften. Ihre Forschungsinteressen umfassen generative Modelle, Repräsentationslernen, AI4Science und Deep-Learning-Theorie.
Die Hauptautoren dieses Artikels, Dr. Shikun Feng und Dr. Yuyan Ni, sind derzeit auf der Suche nach Arbeitsmöglichkeiten. Interessierte Freunde können sich gerne an sie wenden.
* E-Mail von Feng Shikun: [email protected]
* E-Mail-Adresse von Ni Yuyan: [email protected]








